Processor Pipeline
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

PIPELINING and ASSOCIATED TIMING ISSUES Introduction: While
PIPELINING AND ASSOCIATED TIMING ISSUES Introduction: While studying sequential circuits, we studied about Latches and Flip Flops. While Latches formed the heart of a Flip Flop, we have explored the use of Flip Flops in applications like counters, shift registers, sequence detectors, sequence generators and design of Finite State machines. Another important application of latches and flip flops is in pipelining combinational/algebraic operation. To understand what is pipelining consider the following example. Let us take a simple calculation which has three operations to be performed viz. 1. add a and b to get (a+b), 2. get magnitude of (a+b) and 3. evaluate log |(a + b)|. Each operation would consume a finite period of time. Let us assume that each operation consumes 40 nsec., 35 nsec. and 60 nsec. respectively. The process can be represented pictorially as in Fig. 1. Consider a situation when we need to carry this out for a set of 100 such pairs. In a normal course when we do it one by one it would take a total of 100 * 135 = 13,500 nsec. We can however reduce this time by the realization that the whole process is a sequential process. Let the values to be evaluated be a1 to a100 and the corresponding values to be added be b1 to b100. Since the operations are sequential, we can first evaluate (a1 + b1) while the value |(a1 + b1)| is being evaluated the unit evaluating the sum is dormant and we can use it to evaluate (a2 + b2) giving us both |(a1 + b1)| and (a2 + b2) at the end of another evaluation period. -

2.5 Classification of Parallel Computers
52 // Architectures 2.5 Classification of Parallel Computers 2.5 Classification of Parallel Computers 2.5.1 Granularity In parallel computing, granularity means the amount of computation in relation to communication or synchronisation Periods of computation are typically separated from periods of communication by synchronization events. • fine level (same operations with different data) ◦ vector processors ◦ instruction level parallelism ◦ fine-grain parallelism: – Relatively small amounts of computational work are done between communication events – Low computation to communication ratio – Facilitates load balancing 53 // Architectures 2.5 Classification of Parallel Computers – Implies high communication overhead and less opportunity for per- formance enhancement – If granularity is too fine it is possible that the overhead required for communications and synchronization between tasks takes longer than the computation. • operation level (different operations simultaneously) • problem level (independent subtasks) ◦ coarse-grain parallelism: – Relatively large amounts of computational work are done between communication/synchronization events – High computation to communication ratio – Implies more opportunity for performance increase – Harder to load balance efficiently 54 // Architectures 2.5 Classification of Parallel Computers 2.5.2 Hardware: Pipelining (was used in supercomputers, e.g. Cray-1) In N elements in pipeline and for 8 element L clock cycles =) for calculation it would take L + N cycles; without pipeline L ∗ N cycles Example of good code for pipelineing: §doi =1 ,k ¤ z ( i ) =x ( i ) +y ( i ) end do ¦ 55 // Architectures 2.5 Classification of Parallel Computers Vector processors, fast vector operations (operations on arrays). Previous example good also for vector processor (vector addition) , but, e.g. recursion – hard to optimise for vector processors Example: IntelMMX – simple vector processor. -

Microprocessor Architecture
EECE416 Microcomputer Fundamentals Microprocessor Architecture Dr. Charles Kim Howard University 1 Computer Architecture Computer System CPU (with PC, Register, SR) + Memory 2 Computer Architecture •ALU (Arithmetic Logic Unit) •Binary Full Adder 3 Microprocessor Bus 4 Architecture by CPU+MEM organization Princeton (or von Neumann) Architecture MEM contains both Instruction and Data Harvard Architecture Data MEM and Instruction MEM Higher Performance Better for DSP Higher MEM Bandwidth 5 Princeton Architecture 1.Step (A): The address for the instruction to be next executed is applied (Step (B): The controller "decodes" the instruction 3.Step (C): Following completion of the instruction, the controller provides the address, to the memory unit, at which the data result generated by the operation will be stored. 6 Harvard Architecture 7 Internal Memory (“register”) External memory access is Very slow For quicker retrieval and storage Internal registers 8 Architecture by Instructions and their Executions CISC (Complex Instruction Set Computer) Variety of instructions for complex tasks Instructions of varying length RISC (Reduced Instruction Set Computer) Fewer and simpler instructions High performance microprocessors Pipelined instruction execution (several instructions are executed in parallel) 9 CISC Architecture of prior to mid-1980’s IBM390, Motorola 680x0, Intel80x86 Basic Fetch-Execute sequence to support a large number of complex instructions Complex decoding procedures Complex control unit One instruction achieves a complex task 10 -

Instruction Pipelining (1 of 7)
Chapter 5 A Closer Look at Instruction Set Architectures Objectives • Understand the factors involved in instruction set architecture design. • Gain familiarity with memory addressing modes. • Understand the concepts of instruction- level pipelining and its affect upon execution performance. 5.1 Introduction • This chapter builds upon the ideas in Chapter 4. • We present a detailed look at different instruction formats, operand types, and memory access methods. • We will see the interrelation between machine organization and instruction formats. • This leads to a deeper understanding of computer architecture in general. 5.2 Instruction Formats (1 of 31) • Instruction sets are differentiated by the following: – Number of bits per instruction. – Stack-based or register-based. – Number of explicit operands per instruction. – Operand location. – Types of operations. – Type and size of operands. 5.2 Instruction Formats (2 of 31) • Instruction set architectures are measured according to: – Main memory space occupied by a program. – Instruction complexity. – Instruction length (in bits). – Total number of instructions in the instruction set. 5.2 Instruction Formats (3 of 31) • In designing an instruction set, consideration is given to: – Instruction length. • Whether short, long, or variable. – Number of operands. – Number of addressable registers. – Memory organization. • Whether byte- or word addressable. – Addressing modes. • Choose any or all: direct, indirect or indexed. 5.2 Instruction Formats (4 of 31) • Byte ordering, or endianness, is another major architectural consideration. • If we have a two-byte integer, the integer may be stored so that the least significant byte is followed by the most significant byte or vice versa. – In little endian machines, the least significant byte is followed by the most significant byte. -

Review of Computer Architecture
Basic Computer Architecture CSCE 496/896: Embedded Systems Witawas Srisa-an Review of Computer Architecture Credit: Most of the slides are made by Prof. Wayne Wolf who is the author of the textbook. I made some modifications to the note for clarity. Assume some background information from CSCE 430 or equivalent von Neumann architecture Memory holds data and instructions. Central processing unit (CPU) fetches instructions from memory. Separate CPU and memory distinguishes programmable computer. CPU registers help out: program counter (PC), instruction register (IR), general- purpose registers, etc. von Neumann Architecture Memory Unit Input CPU Output Unit Control + ALU Unit CPU + memory address 200PC memory data CPU 200 ADD r5,r1,r3 ADD IRr5,r1,r3 Recalling Pipelining Recalling Pipelining What is a potential Problem with von Neumann Architecture? Harvard architecture address data memory data PC CPU address program memory data von Neumann vs. Harvard Harvard can’t use self-modifying code. Harvard allows two simultaneous memory fetches. Most DSPs (e.g Blackfin from ADI) use Harvard architecture for streaming data: greater memory bandwidth. different memory bit depths between instruction and data. more predictable bandwidth. Today’s Processors Harvard or von Neumann? RISC vs. CISC Complex instruction set computer (CISC): many addressing modes; many operations. Reduced instruction set computer (RISC): load/store; pipelinable instructions. Instruction set characteristics Fixed vs. variable length. Addressing modes. Number of operands. Types of operands. Tensilica Xtensa RISC based variable length But not CISC Programming model Programming model: registers visible to the programmer. Some registers are not visible (IR). Multiple implementations Successful architectures have several implementations: varying clock speeds; different bus widths; different cache sizes, associativities, configurations; local memory, etc. -

CS152: Computer Systems Architecture Pipelining
CS152: Computer Systems Architecture Pipelining Sang-Woo Jun Winter 2021 Large amount of material adapted from MIT 6.004, “Computation Structures”, Morgan Kaufmann “Computer Organization and Design: The Hardware/Software Interface: RISC-V Edition”, and CS 152 Slides by Isaac Scherson Eight great ideas ❑ Design for Moore’s Law ❑ Use abstraction to simplify design ❑ Make the common case fast ❑ Performance via parallelism ❑ Performance via pipelining ❑ Performance via prediction ❑ Hierarchy of memories ❑ Dependability via redundancy But before we start… Performance Measures ❑ Two metrics when designing a system 1. Latency: The delay from when an input enters the system until its associated output is produced 2. Throughput: The rate at which inputs or outputs are processed ❑ The metric to prioritize depends on the application o Embedded system for airbag deployment? Latency o General-purpose processor? Throughput Performance of Combinational Circuits ❑ For combinational logic o latency = tPD o throughput = 1/t F and G not doing work! PD Just holding output data X F(X) X Y G(X) H(X) Is this an efficient way of using hardware? Source: MIT 6.004 2019 L12 Pipelined Circuits ❑ Pipelining by adding registers to hold F and G’s output o Now F & G can be working on input Xi+1 while H is performing computation on Xi o A 2-stage pipeline! o For input X during clock cycle j, corresponding output is emitted during clock j+2. Assuming ideal registers Assuming latencies of 15, 20, 25… 15 Y F(X) G(X) 20 H(X) 25 Source: MIT 6.004 2019 L12 Pipelined Circuits 20+25=45 25+25=50 Latency Throughput Unpipelined 45 1/45 2-stage pipelined 50 (Worse!) 1/25 (Better!) Source: MIT 6.004 2019 L12 Pipeline conventions ❑ Definition: o A well-formed K-Stage Pipeline (“K-pipeline”) is an acyclic circuit having exactly K registers on every path from an input to an output. -

Threading SIMD and MIMD in the Multicore Context the Ultrasparc T2
Overview SIMD and MIMD in the Multicore Context Single Instruction Multiple Instruction ● (note: Tute 02 this Weds - handouts) ● Flynn’s Taxonomy Single Data SISD MISD ● multicore architecture concepts Multiple Data SIMD MIMD ● for SIMD, the control unit and processor state (registers) can be shared ■ hardware threading ■ SIMD vs MIMD in the multicore context ● however, SIMD is limited to data parallelism (through multiple ALUs) ■ ● T2: design features for multicore algorithms need a regular structure, e.g. dense linear algebra, graphics ■ SSE2, Altivec, Cell SPE (128-bit registers); e.g. 4×32-bit add ■ system on a chip Rx: x x x x ■ 3 2 1 0 execution: (in-order) pipeline, instruction latency + ■ thread scheduling Ry: y3 y2 y1 y0 ■ caches: associativity, coherence, prefetch = ■ memory system: crossbar, memory controller Rz: z3 z2 z1 z0 (zi = xi + yi) ■ intermission ■ design requires massive effort; requires support from a commodity environment ■ speculation; power savings ■ massive parallelism (e.g. nVidia GPGPU) but memory is still a bottleneck ■ OpenSPARC ● multicore (CMT) is MIMD; hardware threading can be regarded as MIMD ● T2 performance (why the T2 is designed as it is) ■ higher hardware costs also includes larger shared resources (caches, TLBs) ● the Rock processor (slides by Andrew Over; ref: Tremblay, IEEE Micro 2009 ) needed ⇒ less parallelism than for SIMD COMP8320 Lecture 2: Multicore Architecture and the T2 2011 ◭◭◭ • ◮◮◮ × 1 COMP8320 Lecture 2: Multicore Architecture and the T2 2011 ◭◭◭ • ◮◮◮ × 3 Hardware (Multi)threading The UltraSPARC T2: System on a Chip ● recall concurrent execution on a single CPU: switch between threads (or ● OpenSparc Slide Cast Ch 5: p79–81,89 processes) requires the saving (in memory) of thread state (register values) ● aggressively multicore: 8 cores, each with 8-way hardware threading (64 virtual ■ motivation: utilize CPU better when thread stalled for I/O (6300 Lect O1, p9–10) CPUs) ■ what are the costs? do the same for smaller stalls? (e.g. -

Pipelined Computations
Pipelined Computations 1 Functional Decomposition car manufacturing with three plants speedup for n inputs in a p-stage pipeline 2 Pipeline Implementations processors in a ring topology pipelined addition pipelined addition with MPI MCS 572 Lecture 27 Introduction to Supercomputing Jan Verschelde, 15 March 2021 Introduction to Supercomputing (MCS 572) Pipelined Computations L-27 15 March 2021 1 / 27 Pipelined Computations 1 Functional Decomposition car manufacturing with three plants speedup for n inputs in a p-stage pipeline 2 Pipeline Implementations processors in a ring topology pipelined addition pipelined addition with MPI Introduction to Supercomputing (MCS 572) Pipelined Computations L-27 15 March 2021 2 / 27 car manufacturing Consider a simplified car manufacturing process in three stages: (1) assemble exterior, (2) fix interior, and (3) paint and finish: input sequence - - - - c5 c4 c3 c2 c1 P1 P2 P3 The corresponding space-time diagram is below: space 6 P3 c1 c2 c3 c4 c5 P2 c1 c2 c3 c4 c5 P1 c1 c2 c3 c4 c5 - time After 3 time units, one car per time unit is completed. Introduction to Supercomputing (MCS 572) Pipelined Computations L-27 15 March 2021 3 / 27 p-stage pipelines A pipeline with p processors is a p-stage pipeline. Suppose every process takes one time unit to complete. How long till a p-stage pipeline completes n inputs? A p-stage pipeline on n inputs: After p time units the first input is done. Then, for the remaining n − 1 items, the pipeline completes at a rate of one item per time unit. ) p + n − 1 time units for the p-stage pipeline to complete n inputs. -

Trends in Processor Architecture
A. González Trends in Processor Architecture Trends in Processor Architecture Antonio González Universitat Politècnica de Catalunya, Barcelona, Spain 1. Past Trends Processors have undergone a tremendous evolution throughout their history. A key milestone in this evolution was the introduction of the microprocessor, term that refers to a processor that is implemented in a single chip. The first microprocessor was introduced by Intel under the name of Intel 4004 in 1971. It contained about 2,300 transistors, was clocked at 740 KHz and delivered 92,000 instructions per second while dissipating around 0.5 watts. Since then, practically every year we have witnessed the launch of a new microprocessor, delivering significant performance improvements over previous ones. Some studies have estimated this growth to be exponential, in the order of about 50% per year, which results in a cumulative growth of over three orders of magnitude in a time span of two decades [12]. These improvements have been fueled by advances in the manufacturing process and innovations in processor architecture. According to several studies [4][6], both aspects contributed in a similar amount to the global gains. The manufacturing process technology has tried to follow the scaling recipe laid down by Robert N. Dennard in the early 1970s [7]. The basics of this technology scaling consists of reducing transistor dimensions by a factor of 30% every generation (typically 2 years) while keeping electric fields constant. The 30% scaling in the dimensions results in doubling the transistor density (doubling transistor density every two years was predicted in 1975 by Gordon Moore and is normally referred to as Moore’s Law [21][22]). -

Reverse Engineering X86 Processor Microcode
Reverse Engineering x86 Processor Microcode Philipp Koppe, Benjamin Kollenda, Marc Fyrbiak, Christian Kison, Robert Gawlik, Christof Paar, and Thorsten Holz, Ruhr-University Bochum https://www.usenix.org/conference/usenixsecurity17/technical-sessions/presentation/koppe This paper is included in the Proceedings of the 26th USENIX Security Symposium August 16–18, 2017 • Vancouver, BC, Canada ISBN 978-1-931971-40-9 Open access to the Proceedings of the 26th USENIX Security Symposium is sponsored by USENIX Reverse Engineering x86 Processor Microcode Philipp Koppe, Benjamin Kollenda, Marc Fyrbiak, Christian Kison, Robert Gawlik, Christof Paar, and Thorsten Holz Ruhr-Universitat¨ Bochum Abstract hardware modifications [48]. Dedicated hardware units to counter bugs are imperfect [36, 49] and involve non- Microcode is an abstraction layer on top of the phys- negligible hardware costs [8]. The infamous Pentium fdiv ical components of a CPU and present in most general- bug [62] illustrated a clear economic need for field up- purpose CPUs today. In addition to facilitate complex and dates after deployment in order to turn off defective parts vast instruction sets, it also provides an update mechanism and patch erroneous behavior. Note that the implementa- that allows CPUs to be patched in-place without requiring tion of a modern processor involves millions of lines of any special hardware. While it is well-known that CPUs HDL code [55] and verification of functional correctness are regularly updated with this mechanism, very little is for such processors is still an unsolved problem [4, 29]. known about its inner workings given that microcode and the update mechanism are proprietary and have not been Since the 1970s, x86 processor manufacturers have throughly analyzed yet. -
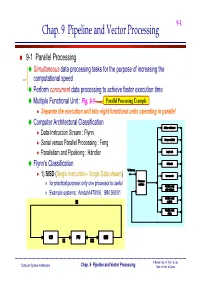
Chap. 9 Pipeline and Vector Processing
9-1 Chap. 9 Pipeline and Vector Processing 9-1 Parallel Processing Simultaneous data processing tasks for the purpose of increasing the = computational speed Perform concurrent data processing to achieve faster execution time Multiple Functional Unit : Fig. 9-1 Parallel Processing Example Separate the execution unit into eight functional units operating in parallel Computer Architectural Classification Adder-subtractor Data-Instruction Stream : Flynn Integer multiply Serial versus Parallel Processing : Feng Parallelism and Pipelining : Händler Logic unit Flynn’s Classification Shift unit To Memory 1) SISD (Single Instruction - Single Data stream) Incrementer Processor registers » for practical purpose: only one processor is useful Floatint-point add-subtract » Example systems : Amdahl 470V/6, IBM 360/91 Floatint-point IS multiply Floatint-point divide CU PU MM IS DS © Korea Univ. of Tech. & Edu. Computer System Architecture Chap. 9 Pipeline and Vector Processing Dept. of Info. & Comm. 9-2 2) SIMD Shared memmory (Single Instruction - Multiple Data stream) DS1 PU1 MM1 » vector or array operations 에 적합한 형태 one vector operation includes many DS2 operations on a data stream PU2 MM2 IS » Example systems : CRAY -1, ILLIAC-IV CU DSn PUn MMn IS 3) MISD (Multiple Instruction - Single Data stream) » Data Stream에 Bottle neck으로 인해 DS IS1 IS1 실제로 사용되지 않음 CU1 PU1 Shared memory IS2 IS2 CU2 PU2 MMn MM2 MM1 ISn ISn CUn PUn DS © Korea Univ. of Tech. & Edu. Computer System Architecture Chap. 9 Pipeline and Vector Processing Dept. of Info. & Comm. 9-3 4) MIMD (Multiple Instruction - Multiple Data stream) » 대부분의 Multiprocessor Shared memory IS1 IS1 DS System에서 사용됨 CU1 PU1 MM1 » Shared memory or IS2 IS2 Message passing : Chap. -

Chapter 4 Data-Level Parallelism in Vector, SIMD, and GPU Architectures
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 4 Data-Level Parallelism in Vector, SIMD, and GPU Architectures Copyright © 2012, Elsevier Inc. All rights reserved. 1 Contents 1. SIMD architecture 2. Vector architectures optimizations: Multiple Lanes, Vector Length Registers, Vector Mask Registers, Memory Banks, Stride, Scatter-Gather, 3. Programming Vector Architectures 4. SIMD extensions for media apps 5. GPUs – Graphical Processing Units 6. Fermi architecture innovations 7. Examples of loop-level parallelism 8. Fallacies Copyright © 2012, Elsevier Inc. All rights reserved. 2 Classes of Computers Classes Flynn’s Taxonomy SISD - Single instruction stream, single data stream SIMD - Single instruction stream, multiple data streams New: SIMT – Single Instruction Multiple Threads (for GPUs) MISD - Multiple instruction streams, single data stream No commercial implementation MIMD - Multiple instruction streams, multiple data streams Tightly-coupled MIMD Loosely-coupled MIMD Copyright © 2012, Elsevier Inc. All rights reserved. 3 Introduction Advantages of SIMD architectures 1. Can exploit significant data-level parallelism for: 1. matrix-oriented scientific computing 2. media-oriented image and sound processors 2. More energy efficient than MIMD 1. Only needs to fetch one instruction per multiple data operations, rather than one instr. per data op. 2. Makes SIMD attractive for personal mobile devices 3. Allows programmers to continue thinking sequentially SIMD/MIMD comparison. Potential speedup for SIMD twice that from MIMID! x86 processors expect two additional cores per chip per year SIMD width to double every four years Copyright © 2012, Elsevier Inc. All rights reserved. 4 Introduction SIMD parallelism SIMD architectures A. Vector architectures B. SIMD extensions for mobile systems and multimedia applications C.