Pythagoras at the Bat 3 to Be 2, Which Is the Source of the Name As the Formula Is Reminiscent of the Sum of Squares from the Pythagorean Theorem
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
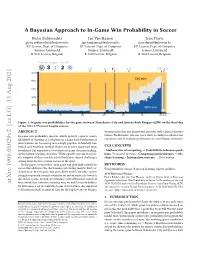
A Bayesian Approach to In-Game Win Probability in Soccer
A Bayesian Approach to In-Game Win Probability in Soccer Pieter Robberechts Jan Van Haaren Jesse Davis [email protected] [email protected] [email protected] KU Leuven, Dept. of Computer KU Leuven, Dept. of Computer KU Leuven, Dept. of Computer Science; Leuven.AI Science; Leuven.AI Science; Leuven.AI B-3000 Leuven, Belgium B-3000 Leuven, Belgium B-3000 Leuven, Belgium Premier League - 2011/12 3 : 2 1:0 1:1 QPR 1:2 2:2 3:2 100% City wins 80% 60% Draw 40% 20% QPR wins 15 30 HT 60 75 90 min Figure 1: In-game win probabilities for the game between Manchester City and Queens Park Rangers (QPR) on the final day of the 2011/12 Premier League season. ABSTRACT demonstrates that our framework provides well-calibrated proba- In-game win probability models, which provide a sports team’s bilities. Furthermore, two use cases show its ability to enhance fan likelihood of winning at each point in a game based on historical experience and to evaluate performance in crucial game situations. observations, are becoming increasingly popular. In baseball, bas- ketball and American football, they have become important tools CCS CONCEPTS to enhance fan experience, to evaluate in-game decision-making, • Mathematics of computing ! Probabilistic inference prob- and to inform coaching decisions. While equally relevant in soccer, lems; Variational methods; • Computing methodologies ! Ma- the adoption of these models is held back by technical challenges chine learning; • Information systems ! Data mining. arising from the low-scoring nature of the sport. In this paper, we introduce an in-game win probability model for KEYWORDS soccer that addresses the shortcomings of existing models. -

Incorporating the Effects of Designated Hitters in the Pythagorean Expectation
Abstract The Pythagorean Expectation is widely used in the field of sabermetrics to estimate a baseball team’s overall season winning percentage based on the number of runs scored and allowed in its games thus far. Bill James devised the simplest version RS 2 p q of the formula through empirical observation as W inning P ercentage RS 2 RA 2 “ p q `p q where RS and RA are runs scored and allowed, respectively. Statisticians later found 1.83 to be a more accurate exponent, estimating overall season wins within 3-4 games per season. Steven Miller provided a theoretical justification for the Pythagorean Expectation by modeling runs scored and allowed as independent continuous random variables drawn from Weibull distributions. This paper aims to first explain Miller’s methodology using recent data and then build upon Miller’s work by incorporating the e↵ects of designated hitters, specifically on the distribution of runs scored by a team. Past studies have attempted to include other e↵ects on run production such as ballpark factor, game state, and pitching power. The results indicate that incorporating information on designated hitters does not improve the error of the Pythagorean Expectation to better than 3-4 games per season. ii Contents Abstract ii Acknowledgements vi 1 Background 1 1.1 Empirical Derivation ........................... 2 1.2 Weibull Distribution ........................... 2 1.3 Application to Other Sports ....................... 4 2 Miller’s Model 5 2.1 Model Assumptions ............................ 5 2.1.1 Continuity of the Data ...................... 6 2.1.2 Independence of Runs Scored and Allowed ........... 7 2.2 Pythagorean Won-Loss Formula .................... -

UPCOMING SCHEDULE and PROBABLE STARTING PITCHERS DATE OPPONENT TIME TV ORIOLES STARTER OPPONENT STARTER June 12 at Tampa Bay 4:10 P.M
FRIDAY, JUNE 11, 2021 • GAME #62 • ROAD GAME #30 BALTIMORE ORIOLES (22-39) at TAMPA BAY RAYS (39-24) LHP Keegan Akin (0-0, 3.60) vs. LHP Ryan Yarbrough (3-3, 3.95) O’s SEASON BREAKDOWN KING OF THE CASTLE: INF/OF Ryan Mountcastle has driven in at least one run in eight- HITTING IT OFF Overall 22-39 straight games, the longest streak in the majors this season and the longest streak by a rookie American League Hit Leaders: Home 11-21 in club history (since 1954)...He is the first Oriole with an eight-game RBI streak since Anthony No. 1) CEDRIC MULLINS, BAL 76 hits Road 11-18 Santander did so from August 6-14, 2020; club record is 11-straight by Doug DeCinces (Sep- No. 2) Xander Bogaerts, BOS 73 hits Day 9-18 tember 22, 1978 - April 6, 1979) and the club record for a single-season is 10-straight by Reggie Isiah Kiner-Falefa, TEX 73 hits Night 13-21 Jackson (July 11-23, 1976)...The MLB record for consecutive games with an RBI by a rookie is No. 4) Vladimir Guerrero, Jr., TOR 70 hits Current Streak L1 10...Mountcastle has hit safely in each of these eight games, slashing .394/.412/.848 (13-for-33) Yuli Gurriel, HOU 70 hits Last 5 Games 3-2 with three doubles, four home runs, seven runs scored, and 12 RBI. Marcus Semien, TOR 70 hits Last 10 Games 5-5 Mountcastle’s eight-game hitting streak is the longest of his career and tied for the April 12-14 fourth-longest active hitting streak in the American League. -

Machine Learning Applications in Baseball: a Systematic Literature Review
This is an Accepted Manuscript of an article published by Taylor & Francis in Applied Artificial Intelligence on February 26 2018, available online: https://doi.org/10.1080/08839514.2018.1442991 Machine Learning Applications in Baseball: A Systematic Literature Review Kaan Koseler ([email protected]) and Matthew Stephan* ([email protected]) Miami University Department of Computer Science and Software Engineering 205 Benton Hall 510 E. High St. Oxford, OH 45056 Abstract Statistical analysis of baseball has long been popular, albeit only in limited capacity until relatively recently. In particular, analysts can now apply machine learning algorithms to large baseball data sets to derive meaningful insights into player and team performance. In the interest of stimulating new research and serving as a go-to resource for academic and industrial analysts, we perform a systematic literature review of machine learning applications in baseball analytics. The approaches employed in literature fall mainly under three problem class umbrellas: Regression, Binary Classification, and Multiclass Classification. We categorize these approaches, provide our insights on possible future ap- plications, and conclude with a summary our findings. We find two algorithms dominate the literature: 1) Support Vector Machines for classification problems and 2) k-Nearest Neighbors for both classification and Regression problems. We postulate that recent pro- liferation of neural networks in general machine learning research will soon carry over into baseball analytics. keywords: baseball, machine learning, systematic literature review, classification, regres- sion 1 Introduction Baseball analytics has experienced tremendous growth in the past two decades. Often referred to as \sabermetrics", a term popularized by Bill James, it has become a critical part of professional baseball leagues worldwide (Costa, Huber, and Saccoman 2007; James 1987). -

SUNDAY, MAY 2, 2021 • GAME #28 • ROAD GAME #14 BALTIMORE ORIOLES (13-14) at OAKLAND ATHLETICS (16-13) LHP Bruce Zimmermann (1-3, 5.33) Vs
SUNDAY, MAY 2, 2021 • GAME #28 • ROAD GAME #14 BALTIMORE ORIOLES (13-14) at OAKLAND ATHLETICS (16-13) LHP Bruce Zimmermann (1-3, 5.33) vs. LHP Sean Manaea (3-1, 2.83) O’s SEASON BREAKDOWN LIFE ON THE ROAD: The O’s defeated the A’s for the second-straight day, capturing their third road HITTING IT OFF Overall 13-14 series win of the season; the O’s have yet to win a series at home...The O’s have gone 9-4 on the Major League Hit Leaders: Home 4-10 road for a .692 winning percentage, the second-highest in the AL and tied for third-best in the majors. No. 1) CEDRIC MULLINS, BAL 35 hits Road 9-4 The O’s have posted a team ERA of 2.93 (38 ER/116.2 IP) in their 13 road games, the J.D. Martinez, BOS 35 hits Day 6-6 lowest road ERA in the majors. No. 3) Xander Bogaerts, BOS 34 hits Night 7-8 The O’s have averaged 4.1 runs per game on the road and 3.5 at home; they have a Yermin Mercedes, CWS 34 hits Current Streak W3 +13 run differential on the road and a -22 run differential at home. No. 5) Tommy Edman, STL 33 hits Last 5 Games 3-2 The O’s are looking for their second road sweep of the season (4/2-4 at BOS). Mike Trout, LAA 33 hits Last 10 Games 5-5 With a win today, the O’s would reach the .500 mark for the first time since being 4-4.. -

Loss Aversion and the Contract Year Effect in The
Gaming the System: Loss Aversion and the Contract Year Effect in the NBA By Ezekiel Shields Wald, UCSB 2/20/2016 Advisor: Professor Peter Kuhn, Ph.D. Abstract The contract year effect, which involves professional athletes strategically adjusting their effort levels to perform more effectively during the final year of a guaranteed contract, has been well documented in professional sports. I examine two types of heterogeneity in the National Basketball Association, a player’s value on the court relative to their salary, and the presence of several contract options that can be included in an NBA contract. Loss aversion suggests that players who are being paid more than they are worth may use their current salaries as a reference point, and be motivated to improve their performance in order to avoid a “loss” of wealth. The presence of contract options impacts the return to effort that the players are facing in their contract season, and can eliminate the contract year effect. I use a linear regression with player, year and team fixed effects to evaluate the impact of a contract year on relevant performance metrics, and find compelling evidence for a general contract year effect. I also develop a general empirical model of the contract year effect given loss aversion, which is absent from previous literature. The results of this study support loss-aversion as a primary motivator of the contract year effect, as only players who are marginally overvalued show a significant contract year effect. The presence of a team option in a player’s contract entirely eliminates any contract year effects they may otherwise show. -

Exploring Chance in NCAA Basketball
Exploring chance in NCAA basketball Albrecht Zimmermann [email protected] INSA Lyon Abstract. There seems to be an upper limit to predicting the outcome of matches in (semi-)professional sports. Recent work has proposed that this is due to chance and attempts have been made to simulate the distribution of win percentages to identify the most likely proportion of matches decided by chance. We argue that the approach that has been chosen so far makes some simplifying assumptions that cause its result to be of limited practical value. Instead, we propose to use clustering of statistical team profiles and observed scheduling information to derive limits on the predictive accuracy for particular seasons, which can be used to assess the performance of predictive models on those seasons. We show that the resulting simulated distributions are much closer to the observed distributions and give higher assessments of chance and tighter limits on predictive accuracy. 1 Introduction In our last work on the topic of NCAA basketball [7], we speculated about the existence of a “glass ceiling” in (semi-)professional sports match outcome prediction, noting that season-long accuracies in the mid-seventies seemed to be the best that could be achieved for college basketball, with similar results for other sports. One possible explanation for this phenomenon is that we are lacking the attributes to properly describe sports teams, having difficulties to capture player experience or synergies, for instance. While we still intend to explore this direction in future work,1 we consider a different question in this paper: the influence of chance on match outcomes. -

Riding a Probabilistic Support Vector Machine to the Stanley Cup
J. Quant. Anal. Sports 2015; 11(4): 205–218 Simon Demers* Riding a probabilistic support vector machine to the Stanley Cup DOI 10.1515/jqas-2014-0093 elimination rounds. Although predicting post-season playoff outcomes and identifying factors that increase Abstract: The predictive performance of various team the likelihood of playoff success are central objectives of metrics is compared in the context of 105 best-of-seven sports analytics, few research results have been published national hockey league (NHL) playoff series that took place on team performance during NHL playoff series. This has between 2008 and 2014 inclusively. This analysis provides left an important knowledge gap, especially in the post- renewed support for traditional box score statistics such lockout, new-rules era of the NHL. This knowledge gap is as goal differential, especially in the form of Pythagorean especially deplorable because playoff success is pivotal expectations. A parsimonious relevance vector machine for fans, team members and team owners alike, often both (RVM) learning approach is compared with the more com- emotionally and economically (Vrooman 2012). A better mon support vector machine (SVM) algorithm. Despite the understanding of playoff success has the potential to potential of the RVM approach, the SVM algorithm proved deliver new insights for researchers studying sports eco- to be superior in the context of hockey playoffs. The proba- nomics, competitive balance, home ice advantage, home- bilistic SVM results are used to derive playoff performance away playoff series sequencing, clutch performances and expectations for NHL teams and identify playoff under- player talent. achievers and over-achievers. The results suggest that the In the NHL, the Stanley Cup is granted to the winner Arizona Coyotes and the Carolina Hurricanes can both of the championship after four playoff rounds, each con- be considered Round 2 over-achievers while the Nash- sisting of a best-of-seven series. -

Nflfastr: Functions to Efficiently Access NFL Play by Play Data
Package ‘nflfastR’ August 3, 2021 Type Package Title Functions to Efficiently Access NFL Play by Play Data Version 4.2.0 Description A set of functions to access National Football League play-by-play data from <https://www.nfl.com/>. License MIT + file LICENSE URL https://www.nflfastr.com/, https://github.com/nflverse/nflfastR BugReports https://github.com/nflverse/nflfastR/issues Depends R (>= 3.5.0) Imports cli (>= 3.0.0), curl, dplyr, fastrmodels (>= 1.0.1), furrr, future, glue, janitor, lubridate, lifecycle (>= 0.2.0), magrittr, mgcv, progressr (>= 0.6.0), rlang, stringr (>= 1.3.0), tibble (>= 3.0), tidyr (>= 1.0.0), tidyselect (>= 1.1.0), xgboost (>= 1.1) Suggests crayon (>= 1.3.4), DBI, DT, gsisdecoder, httr, jsonlite, purrr (>= 0.3.0), qs (>= 0.25.1), rmarkdown, RSQLite, testthat Encoding UTF-8 LazyData true RoxygenNote 7.1.1 NeedsCompilation no Author Sebastian Carl [aut], Ben Baldwin [cre, aut], Lee Sharpe [ctb], Maksim Horowitz [ctb], Ron Yurko [ctb], Samuel Ventura [ctb], Tan Ho [ctb] Maintainer Ben Baldwin <[email protected]> Repository CRAN Date/Publication 2021-08-03 15:10:02 UTC 1 2 nflfastR-package R topics documented: nflfastR-package . .2 add_qb_epa . .4 add_xpass . .5 add_xyac . .5 build_nflfastR_pbp . .6 calculate_expected_points . .7 calculate_player_stats . .9 calculate_win_probability . 11 clean_pbp . 13 decode_player_ids . 14 fast_scraper . 15 fast_scraper_roster . 27 fast_scraper_schedules . 29 field_descriptions . 30 load_pbp . 31 load_player_stats . 31 stat_ids . 32 teams_colors_logos . 33 update_db . 34 Index 36 nflfastR-package nflfastR: Functions to Efficiently Access NFL Play by Play Data Description A set of functions to access National Football League play-by-play data from <https://www.nfl.com/>. -

Max Scherzer National League All-Star National League Cy Young Candidate
MAX SCHERZER NATIONAL LEAGUE ALL-STAR NATIONAL LEAGUE CY YOUNG CANDIDATE MAD MAX IN RAREFIED AIR As Nationals RHP Max Scherzer puts the finishing touches on one of the best seasons in baseball, he has compiled a compelling case to become the sixth pitcher in Major League history to win the Cy Young Award in both leagues...The THE COMPETITION resume for Scherzer, who won the award in the American Here is a look at how Max Scherzer compares to the other National League Cy League in 2013 with the Detroit Tigers, is below: Young candidates: NAME W L ERA INN BB SO SO/9 SO/BB WHIP AVG STATISTIC NUMBER NL RANK M. Scherzer 19 7 2.82 223.1 54 277 11.16 5.13 0.94 .193 Strikeouts 277 1st J. Arrieta 18 8 3.10 197.1 76 190 8.67 2.50 1.08 .194 WHIP 0.94 1st M. Bumgarner 14 9 2.71 219.1 53 246 10.09 4.64 1.02 .209 Opponent On-Base Percentage .248 1st J. Cueto 17 5 2.79 212.2 44 187 7.91 4.25 1.08 .235 Strikeout-to-Walk Ratio 5.13 1st J. Fernandez 16 8 2.86 182.1 55 253 12.49 4.60 1.12 .224 Innings Pitched 223.1 1st K. Hendricks 16 8 1.99 185.0 43 166 8.08 3.86 0.97 .204 Hits allowed per nine innings 6.29 1st J. Lester 19 4 2.28 197.2 49 191 8.70 3.90 1.00 .208 Quality Starts 26 T1st AWARDS SEASON FanGraphs.com WAR 5.8 3rd NATIONAL LEAGUE ALL-STAR Win Probability Added 3.88 3rd Scherzer was named an All-Star for the fourth consecutive season, representing Strikeouts per nine innings 11.16 3rd the Nationals on the National League team in San Diego this past July...Scherzer, a Left on Base Percentage 82.1% 3rd manager’s selection to the NL squad, tossed -

Keshav Puranmalka
Modelling the NBA to Make Better Predictions ARCHpES by MASSACHU Keshav Puranmalka OCT 2 9 2 3 B.S., Massachusetts Institute of Technology(2012) Submitted to the Department of Electrical Engineering and Computer Science in partial fulfillment of the requirements for the degree of Master of Engineering in Computer Science and Engineering at the MASSACHUSETTS INSTITUTE OF TECHNOLOGY September 2013 © Massachusetts Institute of Technology 2013. All rights reserved. A uthor,....................... .............. Department of Electrical Engineering and Computer Science August 23, 2013 Certified by. ........... ..... .... cJ Prof. Leslie P. Kaelbling Panasonic Professor of Computer Science and Engineering Thesis Supervisor A ccepted by ......... ................... Prof. Albert R. Meyer Chairman, Masters of Engineering Thesis Committee 2 Modelling the NBA to Make Better Predictions by Keshav Puranmalka Submitted to the Department of Electrical Engineering and Computer Science on August 23, 2013, in partial fulfillment of the requirements for the degree of Master of Engineering in Computer Science and Engineering Abstract Unexpected events often occur in the world of sports. In my thesis, I present work that models the NBA. My goal was to build a model of the NBA Machine Learning and other statistical tools in order to better make predictions and quantify unexpected events. In my thesis, I first review other quantitative models of the NBA. Second, I present novel features extracted from NBA play-by-play data that I use in building my predictive models. Third, I propose predictive models that use team-level statistics. In the team models, I show that team strength relations might not be transitive in these models. Fourth, I propose predictive models that use player-level statistics. -

TUESDAY, MAY 4, 2021 • GAME #30 • ROAD GAME #16 BALTIMORE ORIOLES (14-15) at SEATTLE MARINERS (16-14) RHP Jorge López (1-3, 7.48) Vs
TUESDAY, MAY 4, 2021 • GAME #30 • ROAD GAME #16 BALTIMORE ORIOLES (14-15) at SEATTLE MARINERS (16-14) RHP Jorge López (1-3, 7.48) vs. RHP Justin Dunn (1-0, 3.98) O’s SEASON BREAKDOWN HAPPY OPENING DAY!: Today marks Opening Day for the 2021 Minor League Baseball season...All HITTING IT OFF Overall 14-15 four of the Orioles affiliates are scheduled to play today for the first time since 2019...The Orioles farm Major League Hit Leaders: Home 4-10 system is ranked as the No. 7 farm system by Baseball America and boasts five Top 100 prospects: No. 1) CEDRIC MULLINS, BAL 38 hits Road 10-5 C Adley Rutschman (No. 2), RHP Grayson Rodriguez (No. 18), LHP DL Hall (No. 52), OF Heston No. 2) Xander Bogaerts, BOS 37 hits Day 6-7 Kjerstad (No. 55), and INF Gunnar Henderson (No. 97). No. 3) Nick Castellanos, CIN 35 hits Night 8-8 The Norfolk Tides (Triple-A East) will open the season in Florida against the Jacksonville Tommy Edman, STL 35 hits Current Streak W1 Jumbo Shrimp at 7:05 p.m. ET...Marks their first game since Sept. 2, 2019 (610 days in J.D. Martinez, BOS 35 hits Last 5 Games 4-1 between)...The Tides went 60-79 in 2019 and featured International League MVP INF/OF Last 10 Games 6-4 Ryan Mountcastle. RUN PRODUCERS April 12-14 The Bowie Baysox (Double-A Northeast) will open the season in Pennsylvania against American League RBI Leaders: May 2-1 the Altoona Curve at 6:00 p.m.