Par4sim – Adaptive Paraphrasing for Text Simplification
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Measuring Text Simplification with the Crowd
Measuring Text Simplification with the Crowd Walter S. Lasecki Luz Rello Jeffrey P. Bigham ROC HCI HCI Institute HCI and LT Institutes Dept. of Computer Science School of Computer Science School of Computer Science University of Rochester Carnegie Mellon University Carnegie Mellon University [email protected] [email protected] [email protected] ABSTRACT the U.S. [41]1 and the European Guidelines for the Production of Text can often be complex and difficult to read, especially for peo Easy-to-Read Information in Europe [23]. ple with cognitive impairments or low literacy skills. Text simplifi Text simplification is an area of Natural Language Processing cation is a process that reduces the complexity of both wording and (NLP) that attempts to solve this problem automatically by reduc structure in a sentence, while retaining its meaning. However, this ing the complexity of both wording (lexicon) and structure (syn is currently a challenging task for machines, and thus, providing tax) in a sentence [46]. Previous efforts on automatic text simpli effective on-demand text simplification to those who need it re fication have focused on people with autism [20, 39], people with mains an unsolved problem. Even evaluating the simplicity of text Down syndrome [48], people with dyslexia [42, 43], and people remains a challenging problem for both computers, which cannot with aphasia [11, 18]. understand the meaning of text, and humans, who often struggle to However, automatic text simplification is in an early stage and agree on what constitutes a good simplification. still is not useful for the target users [20, 43, 48]. -

Proceedings of the 1St Workshop on Tools and Resources to Empower
LREC 2020 Workshop Language Resources and Evaluation Conference 11–16 May 2020 1st Workshop on Tools and Resources to Empower People with REAding DIfficulties (READI) PROCEEDINGS Edited by Nuria´ Gala and Rodrigo Wilkens Proceedings of the LREC 2020 first workshop on Tools and Resources to Empower People with REAding DIfficulties (READI) Edited by: Núria Gala and Rodrigo Wilkens ISBN: 979-10-95546-44-3 EAN: 9791095546443 For more information: European Language Resources Association (ELRA) 9 rue des Cordelières 75013, Paris France http://www.elra.info Email: [email protected] c European Language Resources Association (ELRA) These workshop proceedings are licensed under a Creative Commons Attribution-NonCommercial 4.0 International License ii Preface Recent studies show that the number of children and adults facing difficulties in reading and understanding written texts is steadily growing. Reading challenges can show up early on and may include reading accuracy, speed, or comprehension to the extent that the impairment interferes with academic achievement or activities of daily life. Various technologies (text customization, text simplification, text to speech devices, screening for readers through games and web applications, to name a few) have been developed to help poor readers to get better access to information as well as to support reading development. Among those technologies, text simplification is a powerful way to leverage document accessibility by using NLP techniques. The “First Workshop on Tools and Resources to Empower People with REAding DIfficulties” (READI), collocated with the “International Conference on Language Resources and Evaluation” (LREC 2020), aims at presenting current state-of-the-art techniques and achievements for text simplification together with existing reading aids and resources for lifelong learning, addressing a variety of domains and languages, including natural language processing, linguistics, psycholinguistics, psychophysics of vision and education. -

Data-Driven Text Simplification
Data-Driven Text Simplification Sanja Štajner and Horacio Saggion [email protected] http://web.informatik.uni-mannheim.de/sstajner/index.html University of Mannheim, Germany [email protected] #TextSimplification2018 https://www.upf.edu/web/horacio-saggion University Pompeu Fabra, Spain COLING 2018 Tutorial Presenters • Sanja Stajner • Horacio Saggion • http://web.informatik.uni- • http://www.dtic.upf.edu/~hsaggion mannheim.de/sstajner • https://www.linkedin.com/pub/horacio- • https://www.linkedin.com/in/sanja- saggion/16/9b9/174 stajner-a6904738 • https://twitter.com/h_saggion • Data and Web Science Group • Large Scale Text Understanding • https://dws.informatik.uni - Systems Lab / TALN group mannheim.de/en/home/ • http://www.taln.upf.edu • University of Mannheim, Germany • Department of Information & Communication Technologies • Universitat Pompeu Fabra, Barcelona, Spain © 2018 by S. Štajner & H. Saggion 2 Tutorial antecedents • Previous tutorials on the topic given at: • IJCNLP 2013 and RANLP 2015 (H. Saggion) • RANLP 2017 (S. Štajner) • Automatic Text Simplification. H. Saggion. 2017. Morgan & Claypool. Synthesis Lectures on Human Language Technologies Series. https://www.morganclaypool.com/doi/abs/10.2200/S00700ED1V01Y201602 HLT032 © 2018 by S. Štajner & H. Saggion 3 Outline • Motivation for ATS • Automatic text simplification • TS projects • TS resources • Neural text simplification © 2018 by S. Štajner & H. Saggion 4 PART 1 Motivation for Text Simplification © 2018 by S. Štajner & H. Saggion 5 Text Simplification (TS) The process of transforming a text into an equivalent which is more readable and/or understandable by a target audience • During simplification, complex sentences are split into simple ones and uncommon vocabulary is replaced by more common expressions • TS is a complex task which encompasses a number of operations applied at different linguistic levels: • Lexical • Syntactic • Discourse • Started to attract the attention of natural language processing some years ago (1996) mainly as a pre-processing step © 2018 by S. -

Classifier-Based Text Simplification for Improved Machine Translation
Classifier-Based Text Simplification for Improved Machine Translation Shruti Tyagi Deepti Chopra Iti Mathur Nisheeth Joshi Department of Computer Department of Computer Department of Computer Department of Computer Science Science Science Science Banasthali University Banasthali University Banasthali University Banasthali University Rajasthan, India Rajasthan, India Rajasthan, India Rajasthan, India [email protected] [email protected] [email protected] [email protected] Abstract— Machine Translation is one of the research fields E. Text Summarization: Splitting of sentence or conversion of of Computational Linguistics. The objective of many MT long sentence into smaller ones helps in text summarization. Researchers is to develop an MT System that produce good quality and high accuracy output translations and which also There are also different approaches through which we can covers maximum language pairs. As internet and Globalization is apply text simplification. These are: increasing day by day, we need a way that improves the quality of translation. For this reason, we have developed a Classifier based Text Simplification Model for English-Hindi Machine A. Lexical Simplification: In this approach, identification of Translation Systems. We have used support vector machines and complex words takes place and generation of Naïve Bayes Classifier to develop this model. We have also evaluated the performance of these classifiers. substitutes/synonyms takes place accordingly. For example, in the example below, we have highlighted the complex words Keywords— Machine Translation, Text Simplification, Naïve and their respective substitutes. Bayes Classifier, Support Vector Machine Classifier Original Sentence: Audible word was originally named audire in Latin. I. INTRODUCTION Simplified Sentence: Audible word was first called audire in Text Simplification is the process that reduces the Latin. -

Natural Language Processing Tools for Reading Level Assessment and Text Simplification for Bilingual Education
Natural Language Processing Tools for Reading Level Assessment and Text Simplification for Bilingual Education Sarah E. Petersen A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy University of Washington 2007 Program Authorized to Offer Degree: Computer Science & Engineering University of Washington Graduate School This is to certify that I have examined this copy of a doctoral dissertation by Sarah E. Petersen and have found that it is complete and satisfactory in all respects, and that any and all revisions required by the final examining committee have been made. Chair of the Supervisory Committee: Mari Ostendorf Reading Committee: Mari Ostendorf Oren Etzioni Henry Kautz Date: In presenting this dissertation in partial fulfillment of the requirements for the doctoral degree at the University of Washington, I agree that the Library shall make its copies freely available for inspection. I further agree that extensive copying of this dissertation is allowable only for scholarly purposes, consistent with “fair use” as prescribed in the U.S. Copyright Law. Requests for copying or reproduction of this dissertation may be referred to Proquest Information and Learning, 300 North Zeeb Road, Ann Arbor, MI 48106-1346, 1-800-521-0600, to whom the author has granted “the right to reproduce and sell (a) copies of the manuscript in microform and/or (b) printed copies of the manuscript made from microform.” Signature Date University of Washington Abstract Natural Language Processing Tools for Reading Level Assessment and Text Simplification for Bilingual Education Sarah E. Petersen Chair of the Supervisory Committee: Professor Mari Ostendorf Electrical Engineering Reading proficiency is a fundamental component of language competency. -

Experimenting Sentence Split-And-Rephrase Using Part-Of-Speech Labels
Experimenting Sentence Split-and-Rephrase Using Part-of-Speech Labels P. Berlanga Neto and E. Y. Okano and E. E. S. Ruiz Departamento de Computação e Matemática, FFCLRP Universidade de São Paulo (USP). Av. Bandeirantes, 3900, Monte Alegre. 14040-901, Ribeirão Preto, SP – Brazil [pauloberlanga, okano700, evandro]@usp.br Abstract. Text simplification (TS) is a natural language transformation process that reduces linguistic complexity while preserving semantics and retaining its original meaning. This work aims to present a research proposal for automatic simplification of texts, precisely a split-and-rephrase approach based on an encoder-decoder neural network model. The proposed method was trained against the WikiSplit English corpus with the help of a part-of-speech tagger and obtained a BLEU score validation of 74.72%. We also experimented with this trained model to split-and-rephrase sentences written in Portuguese with relative success, showing the method’s potential. CCS Concepts: • Computing methodologies → Natural language processing. Keywords: natural language processing, neural networks, sentence simplification 1. INTRODUCTION Text Simplification (TS) is the process of modifying natural language to reduce complexity and im- prove both readability and understandability [Shardlow 2014]. A simplified vocabulary or a simplified text structure can benefit different publics, such as people with low education levels, children, non- native individuals, people who have learning disorders (such as autism, dyslexia, and aphasia), among others [Štajner et al. 2015]. Although the simplicity of a text seems intuitively obvious, it does not have a precise definition in technical terms. Traditional assessment metrics consider factors such as sentence length, syllable count, and other linguistic features of the text to identify it as elaborate or not [Shardlow 2014]. -
![Arxiv:2005.00352V2 [Cs.CL] 16 Apr 2021](https://docslib.b-cdn.net/cover/8452/arxiv-2005-00352v2-cs-cl-16-apr-2021-1788452.webp)
Arxiv:2005.00352V2 [Cs.CL] 16 Apr 2021
MUSS: Multilingual Unsupervised Sentence Simplification by Mining Paraphrases Louis Martin1;2 Angela Fan1;3 Éric de la Clergerie2 Antoine Bordes1 Benoît Sagot2 1Facebook AI Research, Paris, France 2Inria, Paris, France 3LORIA, Nancy, France {louismartin, angelafan, abordes}@fb.com {eric.de_la_clergerie, benoit.sagot}@inria.fr Abstract in multiple ways, and depend on the target audi- Progress in sentence simplification has been ence. Simplification guidelines are not uniquely hindered by a lack of labeled parallel simpli- defined, outlined by the stark differences in English fication data, particularly in languages other simplification benchmarks (Alva-Manchego et al., than English. We introduce MUSS, a Multi- 2020a). This highlights the need for more general lingual Unsupervised Sentence Simplification models that can adjust to different simplification system that does not require labeled simplifica- contexts and scenarios. tion data. MUSS uses a novel approach to sen- In this paper, we propose to train controllable tence simplification that trains strong models using sentence-level paraphrase data instead models using sentence-level paraphrase data only, of proper simplification data. These models i.e. parallel sentences that have the same meaning leverage unsupervised pretraining and control- but phrased differently. In order to generate sim- lable generation mechanisms to flexibly adjust plifications and not paraphrases, we use ACCESS attributes such as length and lexical complex- (Martin et al., 2020) to control attributes such as ity at inference time. We further present a length, lexical and syntactic complexity. Para- method to mine such paraphrase data in any phrase data is more readily available, and opens the language from Common Crawl using semantic sentence embeddings, thus removing the need door to training flexible models that can adjust to for labeled data. -

Text Simplification Using Typed Dependencies
Text Simplification using Typed Dependencies: A Comparison of the Robustness of Different Generation Strategies Advaith Siddharthan University of Aberdeen Department of Computing Science [email protected] Abstract The original police inquiry, which led to Mulcaire being jailed in 2007, also dis- We present a framework for text simplification covered evidence that he has successfully based on applying transformation rules to a intercepted voicemail messages belonging typed dependency representation produced by to Rebekah Brooks, who was editor of the the Stanford parser. We test two approaches Sun when Mulcaire was working exclu- to regeneration from typed dependencies: (a) sively for its Sunday stablemate. gen-light, where the transformed dependency graphs are linearised using the word order and to: morphology of the original sentence, with any changes coded into the transformation rules, The original police inquiry led to Mulcaire and (b) gen-heavy, where the Stanford depen- being jailed in 2007. The police inquiry dencies are reduced to a DSyntS representa- also discovered evidence that he has suc- tion and sentences are generating formally us- ing the RealPro surface realiser. The main cessfully intercepted voicemail messages contribution of this paper is to compare the belonging to Rebekah Brooks. Rebekah robustness of these approaches in the presence Brooks was editor of the Sun. This was of parsing errors, using both a single parse and when Mulcaire was working exclusively an n-best parse setting in an overgenerate and for its Sunday stablemate. rank approach. We find that the gen-light ap- proach is robust to parser error, particularly in The main aim of this paper is to describe and com- the n-best parse setting. -

Workshopabstracts
TENTH INTERNATIONAL CONFERENCE ON LANGUAGE RESOURCES AND EVALUATION MAY 23 – 28, 2016 GRAND HOTEL BERNARDIN CONFERENCE CENTRE Portorož , SLOVENIA WORKSHOP ABSTRACTS Editors: Please refer to each single workshop list of editors. Assistant Editors: Sara Goggi, Hélène Mazo The LREC 2016 Proceedings are licensed under a Creative Commons Attribution- NonCommercial 4.0 International License LREC 2016, TENTH INTERNATIONAL CONFERENCE ON LANGUAGE RESOURCES AND EVALUATION Title: LREC 2016 Workshop Abstracts Distributed by: ELRA – European Language Resources Association 9, rue des Cordelières 75013 Paris France Tel.: +33 1 43 13 33 33 Fax: +33 1 43 13 33 30 www.elra.info and www.elda.org Email: [email protected] and [email protected] ISBN 978-2-9517408-9-1 EAN 9782951740891 ii TABLE OF CONTENTS W12 Joint 2nd Workshop on Language & Ontology (LangOnto2) & Terminology & Knowledge Structures (TermiKS) …………………………………………………………………………….. 1 W5 Cross -Platform Text Mining & Natural Language Processing Interoperability ……. 12 W39 9th Workshop on Building & Using Comparable Corpora (BUCC 2016)…….…….. 23 W19 Collaboration & Computing for Under-Resourced Languages (CCURL 2016).….. 31 W31 Improving Social Inclusion using NLP: Tools & Resources ……………………………….. 43 W9 Resources & ProcessIng of linguistic & extra-linguistic Data from people with various forms of cognitive / psychiatric impairments (RaPID)………………………………….. 49 W25 Emotion & Sentiment Analysis (ESA 2016)…………..………………………………………….. 58 W28 2nd Workshop on Visualization as added value in the development, use & evaluation of LRs (VisLR II)……….……………………………………………………………………………… 68 W15 Text Analytics for Cybersecurity & Online Safety (TA-COS)……………………………… 75 W13 5th Workshop on Linked Data in Linguistics (LDL-2016)………………………………….. 83 W10 Lexicographic Resources for Human Language Technology (GLOBALEX 2016)… 93 W18 Translation Evaluation: From Fragmented Tools & Data Sets to an Integrated Ecosystem?.................................................................................................................. -

Automatic Text Simplification
Book Review Automatic Text Simplification Horacio Saggion (Universitat Pompeu Fabra) Morgan & Claypool (Synthesis Lectures on Human Language Technologies, edited by Graeme Hirst, volume 37), 2017, xvi+121 pp; paperback, ISBN 978-1-62705-868-1; hardcover, ISBN 9781681732145, $69.95; ebook, ISBN 978-1-62705-869-8, $39.96; doi:10.2200/S00700ED1V01Y201602HLT032 Reviewed by Xiaojun Wan Peking University Automatic text simplification is a special task of text-to-text generation, and it converts a text into another text that is easier to read and understand, while the underlying meaning and information remains the same. A text simplification system usually re- places difficult or unknown phrases with simpler equivalents and transforms long and syntactically complex sentences into shorter and less complex ones. Here is an example from Siddharthan (2006). The first sentence contains two relative clauses and one conjoined verb phrase, and the text below is the simplified version. • Also contributing to the firmness in copper, the analyst noted, was a report by Chicago purchasing agents, which precedes the full purchasing agents report that is due out today and gives an indication of what the full report might hold. • Also contributing to the firmness in copper, the analyst noted, was a report by Chicago purchasing agents. The Chicago report precedes the full purchasing agents report. The Chicago report gives an indication of what the full report might hold. The full report is due out today. Research on automatic text simplification started 20 years ago, and it has become a very important area in natural language processing (NLP) and attracted much attention in recent years. -

Discourse Level Factors for Sentence Deletion in Text Simplification
Discourse Level Factors for Sentence Deletion in Text Simplification Yang Zhong,*1 Chao Jiang,1 Wei Xu,1 Junyi Jessy Li2 1 Department of Computer Science and Engineering, The Ohio State University 2 Department of Linguistics, The University of Texas at Austin fzhong.536, jiang.1530, [email protected] [email protected] Abstract most prevalent, as simplified texts tend to be shorter (Pe- tersen and Ostendorf 2007; Drndarevic and Saggion 2012; This paper presents a data-driven study focusing on analyz- Woodsend and Lapata 2011). ing and predicting sentence deletion — a prevalent but under- This work aims to facilitate better understanding of sen- studied phenomenon in document simplification — on a large tence deletion in document-level text simplification. While English text simplification corpus. We inspect various docu- ment and discourse factors associated with sentence deletion, prior work analyzed sentence position and content in a cor- using a new manually annotated sentence alignment corpus pus study (Petersen and Ostendorf 2007), we hypothesize we collected. We reveal that professional editors utilize differ- and show that sentence deletion is driven partially by con- ent strategies to meet readability standards of elementary and textual, discourse-level information, in addition to the con- middle schools. To predict whether a sentence will be deleted tent within a sentence. during simplification to a certain level, we harness automat- We utilize the Newsela2 corpus (Xu, Callison-Burch, and ically aligned data to train a classification model. Evaluated Napoles 2015) which contains multiple versions of a docu- on our manually annotated data, our best models reached F1 ment rewritten by professional editors. -
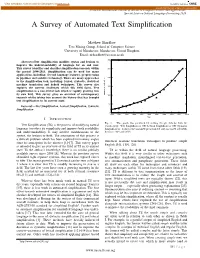
A Survey of Automated Text Simplification
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Directory of Open Access Journals (IJACSA) International Journal of Advanced Computer Science and Applications, Special Issue on Natural Language Processing 2014 A Survey of Automated Text Simplification Matthew Shardlow Text Mining Group, School of Computer Science University of Manchester, Manchester, United Kingdom Email: [email protected] 300 Abstract—Text simplification modifies syntax and lexicon to improve the understandability of language for an end user. This survey identifies and classifies simplification research within 250 the period 1998-2013. Simplification can be used for many applications, including: Second language learners, preprocessing in pipelines and assistive technology. There are many approaches 200 to the simplification task, including: lexical, syntactic, statistical machine translation and hybrid techniques. This survey also explores the current challenges which this field faces. Text 150 simplification is a non-trivial task which is rapidly growing into its own field. This survey gives an overview of contemporary Number of Publications 100 research whilst taking into account the history that has brought text simplification to its current state. 50 Keywords—Text Simplification, Lexical Simplification, Syntactic Simplification 0 1994 1996 1998 2000 2002 2004 2006 2008 2010 2012 2014 Year I. INTRODUCTION Fig. 1. This graph was produced by polling Google Scholar with the Text Simplification (TS) is the process of modifying natural search query: ‘Text Simplification’ OR ‘Lexical Simplification’ OR ‘Syntactic language to reduce its complexity and improve both readability Simplification’. It shows the sustained growth in TS and associated sub-fields and understandability.