Content Based Access Control in Social Network Sites
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Pinchbet / Spreadsheet 2015 - 2017 (24 March '15 - 31 January '17) ROI TOT.: 5.9 % B TOT.: 6,520 TOT
ROI October '16: 9.27% (398 bets), ROI November '16: -4.22% (688 bets), ROI December '16: 2.11% (381bets), ROI January 2.11% (565bets) '16: -1.05% (688bets), ROI December (398bets),-4.22% '17: ROI November 9.27% '16: '16: ROI October (283bets) -3.0% '16: (262bets), ROI September (347bets), 3.10% ROI August 6.39% (405bets), ROI July'16: 6.9% (366bets),'16: ROI JuneROI May 0.5% '16: '16: (219bets), ROI January 4.9% (642bets), ROI February '15: 7.8% (460bets) ROI December (512bets), ROI March (325bets), 0.9% ROI April-6.1% 1.4% '16: '16: '16: (323bets) (269bets), 8.5% ROI November 9.6% '15: '15: (386bets), ROI October 4.1% '15: (337bets), ROI September ROI August7.5% '15: (334bets) 24% (72 bets), ROI July 2.7% (304bets), '15: (227bets), ROI June (49ROI MayROI March9.9% bets), ROI April0.4% '15: 20.3% '15: '15: '15: ROI TOT.: 5.9 % BROI DAY:TOT.: 5.9 % EUR / 11.1 AVG. B 6,153 TOT.: 6,520 TOT.RETURN: PinchBet / SpreadSheet 2015 - 2017 PinchBet - 2017 / SpreadSheet 2015 1000 2000 3000 4000 5000 6000 7000 0 1 228 455 682 909 1136 1363 1590 1817 2044 2271 '17) January - 31 March'15 (24 2498 2725 2952 3179 3406 3633 3860 Return (EUR) Return 4087 4314 4541 4768 4995 5222 5449 5676 5903 6130 6357 6584 6811 7038 7265 7492 7719 7946 Trend line Return (EUR) No. Bets Return (EUR) January '17 January '17 December '16 December '16 November '16 November '16 October '16 October '16 September '16 September '16 August '16 August '16 July '16 July '16 June '16 June '16 May '16 May '16 April '16 April '16 March '16 March'16 February '16 February '16 No. -

Regular Coupon
REGULAR COUPON BOTH TEAMS Information 3-WAY ODDS (1X2) DOUBLE CHANCE TOTALS 2.5 TO SCORE Game Code 1 / 2 1/ 12 /2 3- 3+ ++ -- No CAT TIME DET NS 1 HOME TEAM X AWAY TEAM 2 1X 12 X2 U O YES NO Saturday, 10 April, 2021 7282 CRC 01:00 3L 2.28 LIMON FC 8 2.74 10 SPORTING SAN JOSE 2.89 1.24 1.27 1.41 1.49 2.34 1.97 1.69 7329 PAUA1 02:00 3 8.48 SAO BENTO SP 4 3.86 2 BRAGANTINO SP 1.36 2.65 1.17 1.01 1.51 2.19 2.70 1.39 7101 ARGC 03:00 3L 2.99 RACING CLUB 2.89 CA INDEPEND. 2.33 1.47 1.31 1.29 1.52 2.25 1.95 1.73 7293 CAR 03:05 3L 3.02 VOLTA REDONDA RJ 2 2.97 5 BOTAFOGO RJ 2.26 1.50 1.29 1.28 1.51 2.18 1.95 1.73 7229 PAUA1 04:00 3 1.57 SANTOS FC 3 3.55 4 BOTAFOGO SP 5.17 1.09 1.20 2.10 1.63 1.98 2.06 1.65 Sunday, 11 April, 2021 7599 JAP3 07:00 1L 2.59 FUKUSHIMA UNITED .. 9 3.14 7 KUMAMOTO 2.59 1.42 1.30 1.42 1.79 1.88 1.68 2.00 7607 JAP3 07:00 1L 5.60 YOKOHAMA SCC 14 4.00 10 KAGOSHIMA UNITED 1.51 2.33 1.19 1.10 1.91 1.76 1.87 1.79 7618 JAP3 07:00 1 2.42 VANRAURE HACHNO. -
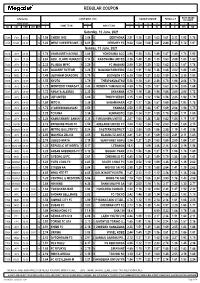
Regular Coupon
REGULAR COUPON BOTH TEAMS Information 3-WAY ODDS (1X2) DOUBLE CHANCE TOTALS 2.5 TO SCORE Game Code 1 / 2 1/ 12 /2 3- 3+ ++ -- No CAT TIME DET NS 1 HOME TEAM X AWAY TEAM 2 1X 12 X2 U O YES NO Saturday, 12 June, 2021 7298 IT4A 17:00 3L 1.94 CHIERI 1955 13 3.04 16 DERTHONA 3.51 1.18 1.25 1.63 1.61 2.13 1.92 1.76 7028 USA3 03:00 1L 1.23 WEST CHESTER UNIT.. 2 6.01 8 HERSHEY FC 9.02 1.02 1.08 3.61 2.88 1.35 1.72 1.97 Sunday, 13 June, 2021 7020 JAP3 07:00 1L 1.78 VANRAURE HACHNO.. 7 3.64 11 YOKOHAMA SCC 3.94 1.20 1.23 1.89 1.87 1.80 1.74 1.92 7021 JAP3 07:00 1L 2.84 AZUL CLARO NUMAZU10 3.14 8 KAGOSHIMA UNITED 2.38 1.49 1.29 1.35 1.63 2.09 1.83 1.82 7022 JAP3 07:00 1L 2.32 FUJIEDA MYFC 9 3.20 15 FC IMABARI 2.90 1.34 1.29 1.52 1.62 2.12 1.87 1.78 7024 JAP3 07:00 1L 2.81 GAINARE TOTTORI 14 3.26 12 NAGANO PARCEIRO 2.34 1.51 1.28 1.36 1.68 2.02 1.80 1.85 7056 SKO2 07:00 1 1.49 JEONNAM DRAGONS 1 3.70 10 BUCHEON FC 6.30 1.06 1.21 2.33 1.59 2.16 2.30 1.53 7009 JAP2 08:00 1L 1.55 KYOTO 2 3.79 19 THESPAKUSATSU 5.58 1.10 1.21 2.26 1.76 1.96 2.04 1.70 7010 JAP2 08:00 1L 1.72 MONTEDIO YAMAGAT. -

Weekend Football Results Weekend Football
Issued Date Page WEEKEND FOOTBALL RESULTS 22/04/2019 09:17 1 / 4 INFORMATION INFORMATION INFORMATION RESULTS RESULTS RESULTS GAME CODE HOME TEAM AWAY TEAM GAME CODE HOME TEAM AWAY TEAM GAME CODE HOME TEAM AWAY TEAM No CAT TIME HT FT No CAT TIME HT FT No CAT TIME HT FT Saturday, 20 April, 2019 Sunday, 21 April, 2019 Sunday, 21 April, 2019 7226 SAFR2 16:00 : 3:0 FC CAPE TOWN WITBANK SPURS 7044 CHN 12:30 3:1 5:1 JIANGSU GUOXIN-SAIN.. GUANGZHOU R&F FC 7089 GD3 14:00 0:0 0:2 1. FC KAISERSLAUTERN HANSA ROSTOCK 7045 HONG 12:30 0:1 2:2 BC GLORY SKY EASTERN SPORTS CLUB 7090 RUS3 14:00 : 0:0 FC ZVEZDA PERM NEFTEK. NIZHNEKAMSK Sunday, 21 April, 2019 7046 SIN 12:30 1:1 2:1 ALBIREX NIIGATA FC YOUNG LIONS 7091 SP1W 14:00 : 1:0 UD GRANADILLA TENER.. FUNDACION ALBACETE 7001 JAP2 07:00 0:0 1:0 KAGOSHIMA UNITED FC RYUKYU 7047 SIN 12:30 0:0 1:1 BALESTIER CENTRAL TAMPINES ROV. 7092 THAI 14:00 : 2:3 AIR FORCE UNITED FC SAMUT SAKHON FC 7002 JAP2 08:00 0:0 0:1 FC GIFU MITO H. 7048 SP3D 12:30 1:0 1:2 SEVILLA ATLETICO RECREATIVO DE HUELVA 7093 THAI 14:00 : 1:1 BEC TERO SASANA KASETSART UNIVERSIT.. 7003 JAP2 08:00 0:0 0:1 MONTEDIO Y. RENOFA YAMAGUCHI 7049 SPR13 12:30 : 2:0 LORCA DEPORTIVA CF UCAM MURCIA II 7094 THPR 14:00 0:0 1:1 PRACHUAP FC SUKHOTHAI FC 7004 JAP2 08:00 0:1 3:1 YOKOHAMA FC JEF UNITED 7050 SPR5 12:45 : 0:0 FUNDACIO ESPORTIVA . -

Regular Coupon
REGULAR COUPON BOTH TEAMS Information 3-WAY ODDS (1X2) DOUBLE CHANCE TOTALS 2.5 TO SCORE Game Code 1 / 2 1/ 12 /2 3- 3+ ++ -- No CAT TIME DET NS 1 HOME TEAM X AWAY TEAM 2 1X 12 X2 U O YES NO Saturday, 08 May, 2021 7095 ARGC 19:00 3L 3.46 GODOY CRUZ A.T. 10 3.10 7 CA BANFIELD 2.01 1.64 1.27 1.22 1.63 2.05 1.87 1.80 7132 ARGC 21:30 3L 2.34 GIMNASIA Y ESGRIMA 7 3.01 1 VELEZ 2.86 1.32 1.29 1.47 1.62 2.08 1.84 1.84 7183 ARGC 21:30 3L 1.15 ATLETICO TUCUMAN 8 6.15 10 DEFENSA Y JUSTICIA 12.8 - 1.06 4.15 2.38 1.47 2.26 1.54 7137 ARGC 00:00 3L 4.63 PATRONATO 13 3.33 2 BOCA JUNIORS 1.68 1.94 1.23 1.12 1.59 2.13 2.07 1.65 Sunday, 09 May, 2021 7020 JAP 07:00 1 1.74 YOKOHAMA MAR. 4 3.66 5 VISSEL KOBE 4.11 1.18 1.22 1.94 2.44 1.47 1.47 2.44 7106 JAP2 07:00 1L 3.55 BLAUBLITZ AKITA 8 3.20 4 JUBILO IWATA 2.02 1.68 1.29 1.24 1.67 2.03 1.84 1.83 7198 JAP2 07:00 1L 4.28 SAGAMIHARA 20 3.24 5 MACHIDA ZELVIA 1.83 1.84 1.28 1.17 1.54 2.27 2.08 1.64 7496 JAPW 07:00 Women 3 3.70 ANGE VIOLET HIROS. -

Weekend Football Results Weekend Football
Issued Date Page WEEKEND FOOTBALL RESULTS 30/09/2019 09:38 1 / 8 INFORMATION INFORMATION INFORMATION RESULTS RESULTS RESULTS GAME CODE HOME TEAM AWAY TEAM GAME CODE HOME TEAM AWAY TEAM GAME CODE HOME TEAM AWAY TEAM No CAT TIME HT FT No CAT TIME HT FT No CAT TIME HT FT Saturday, 28 September, 2019 Sunday, 29 September, 2019 Sunday, 29 September, 2019 7423 KOS 16:00 : : DARDANA KF VLLAZNIA 7040 CZEMS 11:30 1:1 1:2 FC FASTAV ZLIN B SLAVIA KROMERIZ 7077 EST1 13:00 0:0 0:1 JK NARVA TRANS PAIDE LINNAMEESKOND 7863 SP1W 20:00 : 1:0 RAYO VALLECANO SPORTING DE HUELVA 7041 IND 11:30 1:1 2:2 PSS SLEMAN PERSEPAM MU 7078 GRU19 13:00 0:2 3:2 ARIS U19 LARISA AEL U19 7042 ITW1 11:30 3:0 3:0 PESCARA AM SAMPDORIA GENOA U19 7079 JAP 13:00 0:4 0:6 SHONAN BELLMARE SHIMIZU S-PULSE Sunday, 29 September, 2019 7043 RUS 11:30 0:1 0:3 URAL CSKA MOSCOW 7080 KAZ 13:00 2:1 2:2 FK ATYRAU FC OKZHETPES 7001 JAP3 07:00 : 2:1 FUKUSHIMA UNITED FC GRULLA MORIOKA 7044 SLK2 11:30 3:2 4:3 FC PETRZALKA 1898 MFK TATRAN LIPTOVSK.. 7081 KOS 13:00 : 0:2 KF ULPIANA KF RAMIZ SADIKU 7002 JAP3 07:00 1:1 2:2 KAMATAMARE SANUKI KUMAMOTO 7045 SLK2 11:30 2:0 3:0 FC STK 1914 SAMORIN SLOVAN BRATISLAVA B 7082 POL4G1 13:00 1:0 2:2 LEGIA II WARSZAWA POGON GRODZISK MAZ. -
Weekend Football Results Weekend Football
Issued Date Page WEEKEND FOOTBALL RESULTS 03/02/2020 08:42 1 / 5 INFORMATION INFORMATION INFORMATION RESULTS RESULTS RESULTS GAME CODE HOME TEAM AWAY TEAM GAME CODE HOME TEAM AWAY TEAM GAME CODE HOME TEAM AWAY TEAM No CAT TIME HT FT No CAT TIME HT FT No CAT TIME HT FT Sunday, 02 February, 2020 Sunday, 02 February, 2020 Sunday, 02 February, 2020 7001 AU 07:00 0:1 1:3 CENTRAL COAST MARIN.. WESTERN SYDNEY 7043 SPR7 12:30 : 1:2 TRIVAL VALDERAS A. AD TORREJON CF 7088 SPR9 13:00 2:2 2:2 CLUB POLIDEPORTIVO .. ATL MANCHA REAL 7002 HONG1 07:30 C Canc. BC GLORY SKY SOUTH CHINA FC 7044 TUR1 12:30 0:1 1:1 ANKARAGUCU KASIMPASA 7089 TUR2 13:00 0:0 1:1 HATAYSPOR GIRESUNSPOR 7003 HONG1 07:30 C Canc. CENTRAL & WESTERN GOLIK NORTH DISTRICT 7444 SPR14 12:30 : 2:0 EXTREMADURA UD B OLIVENZA FC 7108 SP3A 13:00 1:0 1:0 UD LAS PALMAS B ATH. MADRID B 7004 HONG1 07:30 C Canc. WING YEE FT WONG TAI SIN 7466 SPR4 12:30 0:0 3:0 CLUB DEPORTIVO BASC.. SANTUTXU FC 7425 SPR10 13:00 : 3:1 CORDOBA CF B UB LEBRIJANA 7008 HONG1 09:30 C Canc. DREAMS METRO GALLE.. CITIZEN AA 7045 AND 13:00 : 1:1 UE ENGORDANY FC SANTA COLOMA 7426 SPR10 13:00 0:0 2:1 CORIA CF CD GERENA 7009 HONG1 09:30 C Canc. EASTERN DISTRICT TAI CHUNG 7046 AZE 13:00 0:2 1:2 FK GABALA KESHLA FK 7437 SPR14 13:00 : 0:1 CALAMONTE EMD ACEUCHAL 7010 HONG1 09:30 C Canc. -
Weekend Football Results Weekend Football
Issue Date Page WEEKEND FOOTBALL RESULTS 14/06/2021 09:12 1 / 4 INFORMATION INFORMATION INFORMATION RESULTS RESULTS RESULTS GAME CODE HOME TEAM AWAY TEAM GAME CODE HOME TEAM AWAY TEAM GAME CODE HOME TEAM AWAY TEAM No CAT TIME HT FT No CAT TIME HT FT No CAT TIME HT FT Sunday, 13 June, 2021 Sunday, 13 June, 2021 Sunday, 13 June, 2021 7127 AUWS1W 06:00 : : STIRLING MACEDONIA F.. SORRENTO FC (W) 7319 HONG1 10:30 0:0 1:1 HOI KING SHAM SHUI PO SA 7160 LIT2 13:00 0:2 0:3 FK KAUNO ZALGIRIS B FK SUDUVA MARIJAMPO.. 7128 SOL 06:00 : : WANEAGU UTD KOSSA FC 7320 HONG1 10:30 1:1 1:3 WING YEE FT GOLIK NORTH DISTRICT 7161 LIT2 13:00 0:0 3:0 FK SILAS RITERIAI B 7001 JAP3 07:00 0:1 0:2 AZUL CLARO NUMAZU KAGOSHIMA UNITED 7023 JAPC 11:00 1:3 1:4 SHONAN BELLMARE FC TOKYO 7162 RWACHG 13:00 1:1 1:1 MARINES FC GISENYI RAYON SPORTS FC 7002 JAP3 07:00 1:1 1:1 FUJIEDA MYFC FC IMABARI 7024 JAPC 11:00 0:1 1:3 YOKOHAMA MAR. HOKKAIDO CONSADOLE.. 7163 SPR17R 13:00 1:1 1:2 UD FRAGA VILLANUEVA CF 7003 JAP3 07:00 0:3 1:8 GAINARE TOTTORI NAGANO PARCEIRO 7098 AST4 11:00 0:5 2:7 BRISBANE STRIKERS QUEENSLAND LIONS 7164 SPR8R 13:00 0:1 1:2 REAL BURGOS CD BECERRIL 7004 JAP3 07:00 3:0 3:0 VANRAURE HACHNOHE .. YOKOHAMA SCC 7141 GRU19 11:00 1:0 4:3 ATROMITOS ATHINON U. -

LIVE in Sportlife Page 1
LIVE in SportLife kickoff_time sport group_name competition_name home_name away_name 2017-03-04 08:30:00 FOOTBALL China China Super League Guangzhou R&F Tianjin Quanjian 2017-03-04 09:00:00 BASKETBALL South Korea South Korea WKBL KEB Hana Women Shinhan S'Birds Women 2017-03-04 09:00:00 TENNIS WTA WTA Kuala Lumpur Xinyun Han Ashleigh Barty 2017-03-04 09:00:00 FOOTBALL Australia Australia NPL Queensland Brisbane Strikers Moreton Bay United 2017-03-04 09:00:00 FOOTBALL Australia Australia Brisbane Capital League 1 Southside Eagles Taringa Rovers 2017-03-04 09:00:00 FOOTBALL Australia Australia Brisbane Premier League Mitchelton FC Logan Lightning 2017-03-04 09:15:00 FOOTBALL Australia Australia Brisbane Premier League Holland Park Hawks Rochedale Rovers 2017-03-04 09:30:00 FOOTBALL Australia Australia NPL Queensland Gold Coast City FC Brisbane City 2017-03-04 09:30:00 FOOTBALL Australia Australia NPL Victoria Heidelberg Utd South Melbourne 2017-03-04 09:30:00 FOOTBALL India India I-League Aizawl FC Mumbai FC 2017-03-04 09:45:00 FOOTBALL Malaysia Malaysia Super League PKNS FC Pulau Pinang 2017-03-04 09:50:00 FOOTBALL Australia Australia A-League Western Sydney Wanderers Adelaide United 2017-03-04 10:00:00 FOOTBALL Australia Australia NPL Queensland North Queensland Fury FNQ FC Heat 2017-03-04 10:00:00 FOOTBALL Romania Romania Liga 2 Sepsi CS Afumati 2017-03-04 10:00:00 TENNIS ITF ITF Women Palmanova Katharina Hobgarski Isabelle Wallace 2017-03-04 10:00:00 FOOTBALL Vietnam Vietnam V-League Thanh Hoa XSKT Can Tho 2017-03-04 10:00:00 FOOTBALL -

SUN-13-JUN-Main-Games
Sunday, Jun 13, 21 Soccer / England / National League 1X2 Double Chance Under / Over GG/NG Code Hour Event 1 X 2 1X 12 X2 <2.5 >2.5 GG NG 17298 12:00 Stockport County FC - Hartlepool United FC 2.02 3.29 3.32 1.29 1.29 1.65 1.61 2.07 1.82 1.88 Soccer / Nigeria / Premier League 1X2 Double Chance Under / Over GG/NG Code Hour Event 1 X 2 1X 12 X2 <2.5 >2.5 GG NG 2249 16:00 Abia Warriors - Lobi Stars 1.61 3.25 5.17 1.05 1.10 1.36 1.39 2.16 2.27 1.47 13990 16:00 Katsina Utd - Enyimba 2.16 2.87 3.21 1.11 1.13 1.22 1.33 2.34 2.16 1.52 14057 16:00 Nasarawa Utd - Plateau Utd 1.54 3.32 5.85 1.04 1.09 1.39 1.39 2.16 2.36 1.44 46 16:00 Kwara United - MFM FC 1.42 3.59 7.03 1.03 1.07 1.44 1.40 2.15 2.55 1.37 69 16:00 Warri Wolves - Akwa Starlets 1.52 3.36 6.04 1.04 1.09 1.39 1.39 2.16 2.39 1.42 1749 16:00 Wikki Tourists - Ifeanyi Ubah 1.44 3.48 6.97 1.03 1.08 1.43 1941 16:00 Enugu Rangers - Sunshine Stars 1.30 3.93 10.29 1.02 1.05 1.51 2533 16:00 Heartland Owerri - Jigawa Golden Stars 1.41 3.59 7.40 1.03 1.07 1.45 2714 16:00 Adamawa United FC - Rivers Utd 3.60 2.83 2.04 1.24 1.13 1.09 Soccer / International / WC Qualification, AFC 1X2 Double Chance Under / Over GG/NG Code Hour Event 1 X 2 1X 12 X2 <2.5 >2.5 GG NG 10467 7:00 Republic of Korea - Lebanon 1.14 7.15 11.55 1.04 1.07 3.84 Soccer / International / Int. -

Regular Coupon
REGULAR COUPON BOTH TEAMS Information 3-WAY ODDS (1X2) DOUBLE CHANCE TOTALS 2.5 TO SCORE Game Code 1 / 2 1/ 12 /2 3- 3+ ++ -- No CAT TIME DET NS 1 HOME TEAM X AWAY TEAM 2 1X 12 X2 U O YES NO Saturday, 10 April, 2021 7342 SP3 18:00 1L 1.87 BURGOS CF 2.89 UNIONISTAS CF 4.79 1.14 1.34 1.80 1.36 2.85 2.46 1.46 7318 SP3 19:00 1L 3.20 CD DON BENITO 2.70 RAYO MAJADAHONDA 2.46 1.46 1.39 1.29 1.40 2.65 2.14 1.61 7317 SP3 19:45 1L 2.91 VILLARRUBIA CF 2.76 ATH. MADRID B 2.61 1.42 1.38 1.34 1.48 2.41 1.98 1.71 7286 CAR 21:30 3L 1.50 AA PORTUGUESA RJ 3 3.49 11 BANGU RJ 6.40 1.05 1.22 2.26 1.49 2.22 2.42 1.48 7282 CRC 01:00 3L 2.24 LIMON FC 8 2.80 10 SPORTING SAN JOSE 2.90 1.24 1.26 1.42 1.46 2.41 2.04 1.64 7101 ARGC 03:00 3L 2.85 RACING CLUB 2.95 CA INDEPEND. 2.38 1.45 1.30 1.32 1.53 2.23 1.94 1.74 7293 CAR 03:05 3L 2.95 VOLTA REDONDA RJ 2 3.05 5 BOTAFOGO RJ 2.25 1.50 1.28 1.29 1.58 2.06 1.87 1.80 Sunday, 11 April, 2021 7599 JAP3 07:00 1L 2.51 FUKUSHIMA UNITED . -

Weekend Regular Coupon 08/04/2020 09:41 1 / 1
Issued Date Page WEEKEND REGULAR COUPON 08/04/2020 09:41 1 / 1 BOTH TEAMS INFORMATION 3-WAY ODDS (1X2) DOUBLE CHANCE TOTALS 2.5 1ST HALF - 3-WAY HT/FT TO SCORE HANDICAP (1X2) GAME CODE HOME TEAM 1 / 2 AWAY TEAM 1/ 12 /2 2.5- 2.5+ 01 0/ 02 1-1 /-1 2-1 1-/ /-/ 2-/ 2-2 /-2 1-2 ++ -- No CAT TIME DET NS L 1 X 2 1X 12 X2 U O 1 X 2 1/1 X/1 2/1 1/X X/X 2/X 2/2 X/2 1/2 YES NO HC 1 X 2 Sunday, 12 April, 2020 7001 HONG1 08:30 CITIZEN AA 8 - - - 3 HONG KONG FC - - - - - - - - - - - - - - - - - - - - - - - 7002 HONG1 08:30 EASTERN DISTRICT 5 - - - 2 BC GLORY SKY - - - - - - - - - - - - - - - - - - - - - - - 7003 HONG1 08:30 SHAM SHUI PO SA 14 - - - 1 TAI CHUNG - - - - - - - - - - - - - - - - - - - - - - - 7004 HONG1 08:30 SHATIN 10 - - - 11 GOLIK NORTH DISTRICT - - - - - - - - - - - - - - - - - - - - - - - 7005 HONG1 10:30 DREAMS METRO GALLER.. 12 - - - 7 WING YEE FT - - - - - - - - - - - - - - - - - - - - - - - 7006 HONG1 10:30 HOI KING 9 - - - 6 CENTRAL & WESTERN - - - - - - - - - - - - - - - - - - - - - - - 7007 HONG1 10:30 SOUTH CHINA FC 4 - - - 13 WONG TAI SIN - - - - - - - - - - - - - - - - - - - - - - - 7008 TAJ 14:00 1 FK ISTIKLOL 1.21 5.60 10.3 CSKA PAMIR DUSHANBE - 1.08 3.62 2.50 1.50 - - - - - - - - - - - - 1.95 1.70 0:2 2.50 3.85 2.05 7009 TAJ 14:00 1 FK KHUJAND 1.40 4.50 6.10 FC KHATLON 1.07 1.14 2.59 2.35 1.55 - - - - - - - - - - - - 1.70 1.95 0:1 2.05 3.70 2.65 7010 INDI2 14:30 AIZAWL FC 10 - - - 2 EAST BENGAL FC - - - - - - - - - - - - - - - - - - - - - - - 7011 INDI2 14:30 CHENNAI CITY 7 - - - 4 REAL KASHMIR - - - - - - - - - - - - - - - - - - - - - - - 7012 INDI2 14:30 GOKULAM KERALA FC 6 - - - 1 MOHUN BAGAN AC - - - - - - - - - - - - - - - - - - - - - - - 7013 INDI2 14:30 MINERVA FC 3 - - - 5 ACIESTA TRAU FOOTBA.