Robust Algorithms for Object Localization
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Fast Quartic Solver Peter Strobach AST-Consulting Inc., Bahnsteig 6, 94133 Röhrnbach, Germany Article Info a B S T R a C T
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Elsevier - Publisher Connector Journal of Computational and Applied Mathematics 234 (2010) 3007–3024 Contents lists available at ScienceDirect Journal of Computational and Applied Mathematics journal homepage: www.elsevier.com/locate/cam The fast quartic solver Peter Strobach AST-Consulting Inc., Bahnsteig 6, 94133 Röhrnbach, Germany article info a b s t r a c t Article history: A fast and highly accurate algorithm for solving quartic equations is introduced. This Received 27 February 2010 new algorithm is more than six times as fast and several times more accurate than the Received in revised form 14 April 2010 quasi-standard Companion matrix eigenvalue quartic solver. Moreover, the method is exceptionally robust in cases of extreme root spread. The new algorithm is based on MSC: a factorization of the quartic in two quadratics, which are solved in closed form. The 65E05 performance key at this point is a fixed-point iteration based fitting algorithm for backward Keywords: optimization of the underlying quartic-to-quadratic polynomial decomposition. Detailed Quartic function experimental results confirm our claims. Polynomial factorization ' 2010 Elsevier B.V. All rights reserved. Polynomial rooting Companion matrix Eigenvalues 1. Introduction Consider the practical rooting of quartic polynomials or functions of the type f .x/ D x4 C ax3 C bx2 C cx C d D x2 C αx C β x2 C γ x C δ D .x − x1/.x − x2/.x − x3/.x − x4/ : (1) A quartic solver is an algorithm that relates a set of real or complex conjugate or mixed real/complex conjugate roots fx1; x2; x3; x4g to a given set of real quartic coefficients fa; b; c; dg. -

Fundamental Units and Regulators of an Infinite Family of Cyclic Quartic Function Fields
J. Korean Math. Soc. 54 (2017), No. 2, pp. 417–426 https://doi.org/10.4134/JKMS.j160002 pISSN: 0304-9914 / eISSN: 2234-3008 FUNDAMENTAL UNITS AND REGULATORS OF AN INFINITE FAMILY OF CYCLIC QUARTIC FUNCTION FIELDS Jungyun Lee and Yoonjin Lee Abstract. We explicitly determine fundamental units and regulators of an infinite family of cyclic quartic function fields Lh of unit rank 3 with a parameter h in a polynomial ring Fq[t], where Fq is the finite field of order q with characteristic not equal to 2. This result resolves the second part of Lehmer’s project for the function field case. 1. Introduction Lecacheux [9, 10] and Darmon [3] obtain a family of cyclic quintic fields over Q, and Washington [22] obtains a family of cyclic quartic fields over Q by using coverings of modular curves. Lehmer’s project [13, 14] consists of two parts; one is finding families of cyclic extension fields, and the other is computing a system of fundamental units of the families. Washington [17, 22] computes a system of fundamental units and the regulators of cyclic quartic fields and cyclic quintic fields, which is the second part of Lehmer’s project. We are interested in working on the second part of Lehmer’s project for the families of function fields which are analogous to the type of the number field families produced by using modular curves given in [22]: that is, finding a system of fundamental units and regulators of families of cyclic extension fields over the rational function field Fq(t). In [11], we obtain the results for the quintic extension case. -

Keshas Final Report
Copyright by LaKesha Rochelle Whitfield 2009 Understanding Complex Numbers and Identifying Complex Roots Graphically by LaKesha Rochelle Whitfield, B.A. Report Presented to the Faculty of the Graduate School of The University of Texas at Austin in Partial Fulfillment of the Requirements for the Degree of Masters of Arts The University of Texas at Austin August 2009 Understanding Complex Numbers and Identifying Complex Roots Graphically Approved by Supervising Committee: Efraim P. Armendariz Mark L. Daniels Dedication I would like to dedicate this master’s report to two very important men in my life – my father and my son. My father, the late John Henry Whitfield, Sr., who showed me daily what it means to work hard to achieve something. And to my son, Byshup Kourtland Rhodes, who continuously encourages and believes in me. To you both, I love and thank you! Acknowledgements I would like to acknowledge my friends and family members. Thank you for always supporting, encouraging, and believing in me. You all are the wind beneath my wings. Also, thank you to the 2007 UTeach Mathematics Masters Cohort. You all are a uniquely dynamic group of individuals whom I am honored to have met and worked with. 2009 v Abstract Understanding Complex Numbers and Identifying Complex Roots Graphically LaKesha Rochelle Whitfield, M.A. The University of Texas at Austin, 2009 Supervisor: Efraim Pacillas Armendariz This master’s report seeks to increase knowledge of complex numbers and how to identify complex roots graphically. The reader will obtain a greater understanding of the history of complex numbers, the definition of a complex number and a few of the field properties of complex numbers. -

Low-Degree Polynomial Roots
Low-Degree Polynomial Roots David Eberly, Geometric Tools, Redmond WA 98052 https://www.geometrictools.com/ This work is licensed under the Creative Commons Attribution 4.0 International License. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/ or send a letter to Creative Commons, PO Box 1866, Mountain View, CA 94042, USA. Created: July 15, 1999 Last Modified: September 10, 2019 Contents 1 Introduction 3 2 Discriminants 3 3 Preprocessing the Polynomials5 4 Quadratic Polynomials 6 4.1 A Floating-Point Implementation..................................6 4.2 A Mixed-Type Implementation...................................7 5 Cubic Polynomials 8 5.1 Real Roots of Multiplicity Larger Than One............................8 5.2 One Simple Real Root........................................9 5.3 Three Simple Real Roots......................................9 5.4 A Mixed-Type Implementation................................... 10 6 Quartic Polynomials 12 6.1 Processing the Root Zero...................................... 14 6.2 The Biquadratic Case........................................ 14 6.3 Multiplicity Vector (3; 1; 0; 0).................................... 15 6.4 Multiplicity Vector (2; 2; 0; 0).................................... 15 6.5 Multiplicity Vector (2; 1; 1; 0).................................... 15 6.6 Multiplicity Vector (1; 1; 1; 1).................................... 16 1 6.7 A Mixed-Type Implementation................................... 17 2 1 Introduction Consider a polynomial of degree d of the form d X i p(y) = piy (1) i=0 where the pi are real numbers and where pd 6= 0. A root of the polynomial is a number r, real or non-real (complex-valued with nonzero imaginary part) such that p(r) = 0. The polynomial can be factored as p(y) = (y − r)mf(y), where m is a positive integer and f(r) 6= 0. -

An Explicit Treatment of Biquadratic Function Fields
Volume 2, Number 1, Pages 44–61 ISSN 1715-0868 AN EXPLICIT TREATMENT OF BIQUADRATIC FUNCTION FIELDS QINGQUAN WU AND RENATE SCHEIDLER Abstract. We provide a comprehensive description of biquadratic func- tion fields and their properties, including a characterization of the cyclic and radical cases as well as the constant field. For the cyclic scenario, we provide simple explicit formulas for the ramification index of any rational place, the field discriminant, the genus, and an algorithmically suitable integral basis. In terms of computation, we only require square and fourth power testing of constants, extended gcd computations of polynomials, and the squarefree factorization of polynomials over the base field. 1. Introduction Efficient computation in algebraic function fields can be quite challenging. While there exist theoretical results for finding quantities such as signatures and constant fields, these methods can be complicated or do not lend them- selves well to explicit computation. With the exception of quadratic and, to some extent, certain other types of fields (such as cubic, superelliptic, and Artin-Schreier extensions), there are very few effective descriptions or explicit formulas available. In this paper, we provide a comprehensive description of biquadratic func- tion fields, including explicit formulas and characterizations. These fields are degree 4 extensions of a rational function field (of characteristic differ- ent from 2) that have an intermediate quadratic subfield; they include all quartic Galois extensions. We first give a method for finding a computa- tionally suitable minimal polynomial of a biquadratic extension. From this so-called standard form, it is possible to determine the constant field and characterize cyclic and radical extensions completely and explicitly. -

Characteristics of Polynomial Functions in Factored Form
3.3 Characteristics of Polynomial Functions in Factored Form GOAL YOU WILL NEED • graphing calculator Determine the equation of a polynomial function that describes or graphing software a particular graph or situation, and vice versa. y INVESTIGATE the Math 8 The graphs of the functions f (x) 5 x 2 2 4x 2 12 and g(x) 5 2x 2 12 4 g(x) = 2x – 12 x are shown. –2 0 246 –4 ? What is the relationship between the real roots of a polynomial –8 equation and the x-intercepts of the corresponding polynomial function? –12 –16 f(x) = x2 – 4x – 12 A. Solve the equations f (x) 5 0 and g(x) 5 0 using the given functions. Compare your solutions with the graphs of the functions. family of polynomial functions What do you notice? a set of polynomial functions whose equations have the same B. family of polynomial functions Create a cubic function from the degree and whose graphs have of the form h(x) 5 a(x 2 p)(x 2 q)(x 2 r). common characteristics; for example, one type of quadratic C. Graph y 5 h (x) on a graphing calculator. Describe the shape of the family has the same zeros or graph near each zero, and compare the shape to the order of each x-intercepts factor in the equation of the function. f(x) = k(x– 2) (x+ 3) D. Solve h(x) 5 0, and compare your solutions with the zeros of the y 40 graph of the corresponding function. What do you notice? k = 3 20 k = 5 E. -

Quartic Polynomials and the Golden Ratio
NOTES Quartic Polynomials and the Golden Ratio HARALD TOTLAND Royal Norwegian Naval Academy P.O. Box 83 Haakonsvern N-5886 Bergen, Norway [email protected] Suppose we have a pentagram in the xy-plane, oriented as in FIGURE 1a, and want to find a quartic polynomial whose graph passes through the three vertices indicated. Out of infinitely many possibilities, there is exactly one quartic polynomial that attains its minimum value at both of the two lower vertices. This graph—shaped like a smooth W with its local maximum at the upper vertex—is shown in FIGURE 1b. Now, how does the graph continue? Will it touch the pentagram again on its way up to infinity? As it turns out, the graph passes through two more vertices, as shown in FIGURE 1c. Furthermore, the two points where the graph crosses the interior of a pentagram edge lie exactly below two other vertices, as shown in FIGURE 1d. ? ? (a) (b) (c) (d) Figure 1 A pentagram and a quartic polynomial Knowing that length ratios within the pentagram are determined by the golden ratio, we realize that this quartic polynomial has some regularities governed by the same ratio. As we will see, there are many more such regularities. Furthermore, they apply to all quartic polynomials with inflection points. This will be clear once we realize that the different quartics are all related by an affine transformation. Symmetric quartic We investigate graphs of quartic polynomials with inflection points by means of certain naturally defined points and length ratios. As an example, we consider the function f (x) = x 4 − 2x 2,showninFIGURE 2. -

Polynomial Functions
Polynomial Functions 6A Operations with Polynomials 6-1 Polynomials 6-2 Multiplying Polynomials 6-3 Dividing Polynomials Lab Explore the Sum and Difference of Two Cubes 6-4 Factoring Polynomials 6B Applying Polynomial Functions 6-5 Finding Real Roots of Polynomial Equations 6-6 Fundamental Theorem of A207SE-C06-opn-001P Algebra FPO Lab Explore Power Functions 6-7 Investigating Graphs of Polynomial Functions 6-8 Transforming Polynomial Functions 6-9 Curve Fitting with Polynomial Models • Solve problems with polynomials. • Identify characteristics of polynomial functions. You can use polynomials to predict the shape of containers. KEYWORD: MB7 ChProj 402 Chapter 6 a211se_c06opn_0402_0403.indd 402 7/22/09 8:05:50 PM A207SE-C06-opn-001PA207SE-C06-opn-001P FPO Vocabulary Match each term on the left with a definition on the right. 1. coefficient A. the y-value of the highest point on the graph of the function 2. like terms B. the horizontal number line that divides the coordinate plane 3. root of an equation C. the numerical factor in a term 4. x-intercept D. a value of the variable that makes the equation true 5. maximum of a function E. terms that contain the same variables raised to the same powers F. the x-coordinate of a point where a graph intersects the x-axis Evaluate Powers Evaluate each expression. 2 6. 6 4 7. - 5 4 8. (-1) 5 9. - _2 ( 3) Evaluate Expressions Evaluate each expression for the given value of the variable. 10. x 4 - 5 x 2 - 6x - 8 for x = 3 11. -

Chapter 2- Factor Theorem and Inequalities
Chapter 2- Factor Theorem and Inequalities Lesson Package MHF4U Chapter 2 Outline Unit Goal: By the end of this unit, you will be able to factor and solve polynomials up to degree 4 using the factor theorem, long division, and synthetic division. You will also learn how to solve factorable polynomial inequalities. Curriculum Section Subject Learning Goals Expectations - divide polynomial expressions using long division L1 Long Division C3.1 - understand the remainder theorem L2 Synthetic Division - divide polynomial expressions using synthetic division 3.1 - be able to determine factors of polynomial expressions by testing L3 Factor Theorem values C3.2 - solve polynomial equations up to degree 4 by factoring Solving Polynomial C3.2, C3.3, L4 - make connections between solutions and x-intercepts of the graph Equations C3.4, C3.7 - determine the equation of a family of polynomial functions given Families of Polynomial L5 the x-intercepts C1.8 Functions Solving Polynomial - Solve factorable polynomial inequalities L5 C4.1, C4.2, C4.3 Inequalities Assessments F/A/O Ministry Code P/O/C KTAC Note Completion A P Practice Worksheet F/A P Completion Quiz – Factor Theorem F P PreTest Review F/A P Test – Factor Theorem and C1.8 K(21%), T(34%), A(10%), Inequalities O C3.1, 3.2, 3.3, 3.3, 3.7 P C(34%) C4.1, 4.2, 4.3 L1 – 2.1 – Long Division of Polynomials and The Remainder Theorem Lesson MHF4U Jensen In this section you will apply the method of long division to divide a polynomial by a binomial. -

Precalculus TN Ready Performance Standards by Unit Precalculus – Curriculum Overview
Precalculus TN Ready Performance Standards by Unit Precalculus – Curriculum Overview The following Practice Standards and Literacy Skills will be used throughout the course: Standards for Mathematical Practice Literacy Skills for Mathematical Proficiency 1. Make sense of problems and persevere in solving them. 1. Use multiple reading strategies. 2. Reason abstractly and quantitatively. 2. Understand and use correct mathematical vocabulary. 3. Construct viable arguments and critique the reasoning of others. 3. Discuss and articulate mathematical ideas. 4. Model with mathematics. 4. Write mathematical arguments. 5. Use appropriate tools strategically. 6. Attend to precision. 7. Look for and make use of structure. 8. Look for and express regularity in repeated reasoning. *Unless otherwise noted, all resources are from Glencoe Precalculus. Maury County Public Schools 5/8/18 Office of Instruction Pk-12 Precalculus TN Ready Performance Standards by Unit Precalculus – Curriculum Overview Quarter 1 Quarter 2 Quarter 3 Quarter 4 Unit 1 Unit 2 Unit 3 Unit 4 Unit 5 Unit 6 Unit 7 Unit 8 Unit 9 Unit 10 14 Days 16 Days 12 Days 16 Days 13 Days 12 Days 7 Days 16 Days 6 Days 14 Days Functions, Power, Exponential Trigonometric Trigonometric Matrices Conic Polar Parametric Sequences, Limits, & Polynomial, & Functions Identities & Sections Graphing & Equations Series, & End & Rational Logarithmic Equations Vectors Sigma Behavior Functions Functions Notation Standards (By number) P.F.BF.A.2 P.F.IF.A.5 P.F.IF.A.2 P.F.TF.A.1 P.G.TI.A.1 P.N.VM.C.7 P.A.C.A.1 -

Constructing Smoothing Functions in Smoothed Particle Hydrodynamics with Applications M.B
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Elsevier - Publisher Connector Journal of Computational and Applied Mathematics 155 (2003) 263–284 www.elsevier.com/locate/cam Constructing smoothing functions in smoothed particle hydrodynamics with applications M.B. Liua;∗, G.R. Liua, K.Y. Lamb aCenter for ACES, Department of Mechanical Engineering, National University of Singapore, 10 Kent Ridge Crescent, Singapore 119260, Singapore bInstitute of High Performance Computing, 1 Science Park Road, #01-01 The Capricorn, Singapore Science Park II, Singapore 117528, Singapore Received 1 February 2002; received in revised form 19 October 2002 Abstract This paper presents a general approach to construct analytical smoothing functions for the meshfree, La- grangian and particle method of smoothed particle hydrodynamics. The approach uses integral form of function representation and applies Taylor series expansion to the SPH function and derivative approximations. The constructing conditions are derived systematically, which not only interpret the consistency condition of the method, but also describe the compact supportness requirement of the smoothing function. Examples of SPH smoothing function are constructed including some existing ones. With this approach, a newquartic smoothing function with some advantages is constructed, and is applied to the one dimensional shock problem and a one dimensional TNT detonation problem. The good agreement between the SPH results and those from other sources shows the e=ectiveness of the approach and the newly constructed smoothing function in numerical simulations. c 2003 Elsevier Science B.V. All rights reserved. Keywords: Smoothed particle hydrodynamics; Smoothing function; Constructing condition; Hydrodynamic simulation 1. -
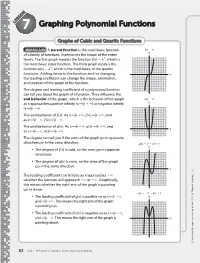
Graphing Polynomial Functions
LESSON7 Graphing Polynomial Functions Graphs of Cubic and Quartic Functions 3 UNDERSTAND A parent function is the most basic function f(x) ϭ x y of a family of functions . It preserves the shape of the entire 3 family . The first graph models the function f (x) 5 x , which is 6 the most basic cubic function . The third graph models the 4 4 function a(x) 5 x , which is the most basic of the quartic 2 functions . Adding terms to the function and/or changing –6 –4 –2 0 2 46 x the leading coefficient can change the shape, orientation, –2 and location of the graph of the function . –4 The degree and leading coefficient of a polynomial function –6 can tell you about the graph of a function . They influence the end behavior of the graph, which is the behavior of the graph a(x) ϭ x 4 y as x approaches positive infinity (x 1 `) or negative infinity (x 2`) . 8 6 The end behavior of f (x): As x 1`, f (x) 1`, and 4 as x 2`, f (x) 2` . 2 The end behavior of a(x): As x 1`, a(x) 1`, and –6 –4 –2 0 2 46 x as x 2`, a(x) 1` . –2 The degree can tell you if the arms of the graph go in opposite directions or in the same direction . g(x) ϭ x 3 Ϫ 4x ϩ 1 y • The degree of f (x) is odd, so the arms go in opposite directions . 6 4 • The degree of a(x) is even, so the arms of the graph 2 go in the same direction .