Chapter 2 Conditional Probability and Independence
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Descriptive Statistics (Part 2): Interpreting Study Results
Statistical Notes II Descriptive statistics (Part 2): Interpreting study results A Cook and A Sheikh he previous paper in this series looked at ‘baseline’. Investigations of treatment effects can be descriptive statistics, showing how to use and made in similar fashion by comparisons of disease T interpret fundamental measures such as the probability in treated and untreated patients. mean and standard deviation. Here we continue with descriptive statistics, looking at measures more The relative risk (RR), also sometimes known as specific to medical research. We start by defining the risk ratio, compares the risk of exposed and risk and odds, the two basic measures of disease unexposed subjects, while the odds ratio (OR) probability. Then we show how the effect of a disease compares odds. A relative risk or odds ratio greater risk factor, or a treatment, can be measured using the than one indicates an exposure to be harmful, while relative risk or the odds ratio. Finally we discuss the a value less than one indicates a protective effect. ‘number needed to treat’, a measure derived from the RR = 1.2 means exposed people are 20% more likely relative risk, which has gained popularity because of to be diseased, RR = 1.4 means 40% more likely. its clinical usefulness. Examples from the literature OR = 1.2 means that the odds of disease is 20% higher are used to illustrate important concepts. in exposed people. RISK AND ODDS Among workers at factory two (‘exposed’ workers) The probability of an individual becoming diseased the risk is 13 / 116 = 0.11, compared to an ‘unexposed’ is the risk. -

Teacher Guide 12.1 Gambling Page 1
TEACHER GUIDE 12.1 GAMBLING PAGE 1 Standard 12: The student will explain and evaluate the financial impact and consequences of gambling. Risky Business Priority Academic Student Skills Personal Financial Literacy Objective 12.1: Analyze the probabilities involved in winning at games of chance. Objective 12.2: Evaluate costs and benefits of gambling to Simone, Paula, and individuals and society (e.g., family budget; addictive behaviors; Randy meet in the library and the local and state economy). every afternoon to work on their homework. Here is what is going on. Ryan is flipping a coin, and he is not cheating. He has just flipped seven heads in a row. Is Ryan’s next flip more likely to be: Heads; Tails; or Heads and tails are equally likely. Paula says heads because the first seven were heads, so the next one will probably be heads too. Randy says tails. The first seven were heads, so the next one must be tails. Lesson Objectives Simone says that it could be either heads or tails Recognize gambling as a form of risk. because both are equally Calculate the probabilities of winning in games of chance. likely. Who is correct? Explore the potential benefits of gambling for society. Explore the potential costs of gambling for society. Evaluate the personal costs and benefits of gambling. © 2008. Oklahoma State Department of Education. All rights reserved. Teacher Guide 12.1 2 Personal Financial Literacy Vocabulary Dependent event: The outcome of one event affects the outcome of another, changing the TEACHING TIP probability of the second event. This lesson is based on risk. -

Bayes and the Law
Bayes and the Law Norman Fenton, Martin Neil and Daniel Berger [email protected] January 2016 This is a pre-publication version of the following article: Fenton N.E, Neil M, Berger D, “Bayes and the Law”, Annual Review of Statistics and Its Application, Volume 3, 2016, doi: 10.1146/annurev-statistics-041715-033428 Posted with permission from the Annual Review of Statistics and Its Application, Volume 3 (c) 2016 by Annual Reviews, http://www.annualreviews.org. Abstract Although the last forty years has seen considerable growth in the use of statistics in legal proceedings, it is primarily classical statistical methods rather than Bayesian methods that have been used. Yet the Bayesian approach avoids many of the problems of classical statistics and is also well suited to a broader range of problems. This paper reviews the potential and actual use of Bayes in the law and explains the main reasons for its lack of impact on legal practice. These include misconceptions by the legal community about Bayes’ theorem, over-reliance on the use of the likelihood ratio and the lack of adoption of modern computational methods. We argue that Bayesian Networks (BNs), which automatically produce the necessary Bayesian calculations, provide an opportunity to address most concerns about using Bayes in the law. Keywords: Bayes, Bayesian networks, statistics in court, legal arguments 1 1 Introduction The use of statistics in legal proceedings (both criminal and civil) has a long, but not terribly well distinguished, history that has been very well documented in (Finkelstein, 2009; Gastwirth, 2000; Kadane, 2008; Koehler, 1992; Vosk and Emery, 2014). -

Probability and Statistics Lecture Notes
Probability and Statistics Lecture Notes Antonio Jiménez-Martínez Chapter 1 Probability spaces In this chapter we introduce the theoretical structures that will allow us to assign proba- bilities in a wide range of probability problems. 1.1. Examples of random phenomena Science attempts to formulate general laws on the basis of observation and experiment. The simplest and most used scheme of such laws is: if a set of conditions B is satisfied =) event A occurs. Examples of such laws are the law of gravity, the law of conservation of mass, and many other instances in chemistry, physics, biology... If event A occurs inevitably whenever the set of conditions B is satisfied, we say that A is certain or sure (under the set of conditions B). If A can never occur whenever B is satisfied, we say that A is impossible (under the set of conditions B). If A may or may not occur whenever B is satisfied, then A is said to be a random phenomenon. Random phenomena is our subject matter. Unlike certain and impossible events, the presence of randomness implies that the set of conditions B do not reflect all the necessary and sufficient conditions for the event A to occur. It might seem them impossible to make any worthwhile statements about random phenomena. However, experience has shown that many random phenomena exhibit a statistical regularity that makes them subject to study. For such random phenomena it is possible to estimate the chance of occurrence of the random event. This estimate can be obtained from laws, called probabilistic or stochastic, with the form: if a set of conditions B is satisfied event A occurs m times =) repeatedly n times out of the n repetitions. -

Estimating the Accuracy of Jury Verdicts
Institute for Policy Research Northwestern University Working Paper Series WP-06-05 Estimating the Accuracy of Jury Verdicts Bruce D. Spencer Faculty Fellow, Institute for Policy Research Professor of Statistics Northwestern University Version date: April 17, 2006; rev. May 4, 2007 Forthcoming in Journal of Empirical Legal Studies 2040 Sheridan Rd. ! Evanston, IL 60208-4100 ! Tel: 847-491-3395 Fax: 847-491-9916 www.northwestern.edu/ipr, ! [email protected] Abstract Average accuracy of jury verdicts for a set of cases can be studied empirically and systematically even when the correct verdict cannot be known. The key is to obtain a second rating of the verdict, for example the judge’s, as in the recent study of criminal cases in the U.S. by the National Center for State Courts (NCSC). That study, like the famous Kalven-Zeisel study, showed only modest judge-jury agreement. Simple estimates of jury accuracy can be developed from the judge-jury agreement rate; the judge’s verdict is not taken as the gold standard. Although the estimates of accuracy are subject to error, under plausible conditions they tend to overestimate the average accuracy of jury verdicts. The jury verdict was estimated to be accurate in no more than 87% of the NCSC cases (which, however, should not be regarded as a representative sample with respect to jury accuracy). More refined estimates, including false conviction and false acquittal rates, are developed with models using stronger assumptions. For example, the conditional probability that the jury incorrectly convicts given that the defendant truly was not guilty (a “type I error”) was estimated at 0.25, with an estimated standard error (s.e.) of 0.07, the conditional probability that a jury incorrectly acquits given that the defendant truly was guilty (“type II error”) was estimated at 0.14 (s.e. -

General Probability, II: Independence and Conditional Proba- Bility
Math 408, Actuarial Statistics I A.J. Hildebrand General Probability, II: Independence and conditional proba- bility Definitions and properties 1. Independence: A and B are called independent if they satisfy the product formula P (A ∩ B) = P (A)P (B). 2. Conditional probability: The conditional probability of A given B is denoted by P (A|B) and defined by the formula P (A ∩ B) P (A|B) = , P (B) provided P (B) > 0. (If P (B) = 0, the conditional probability is not defined.) 3. Independence of complements: If A and B are independent, then so are A and B0, A0 and B, and A0 and B0. 4. Connection between independence and conditional probability: If the con- ditional probability P (A|B) is equal to the ordinary (“unconditional”) probability P (A), then A and B are independent. Conversely, if A and B are independent, then P (A|B) = P (A) (assuming P (B) > 0). 5. Complement rule for conditional probabilities: P (A0|B) = 1 − P (A|B). That is, with respect to the first argument, A, the conditional probability P (A|B) satisfies the ordinary complement rule. 6. Multiplication rule: P (A ∩ B) = P (A|B)P (B) Some special cases • If P (A) = 0 or P (B) = 0 then A and B are independent. The same holds when P (A) = 1 or P (B) = 1. • If B = A or B = A0, A and B are not independent except in the above trivial case when P (A) or P (B) is 0 or 1. In other words, an event A which has probability strictly between 0 and 1 is not independent of itself or of its complement. -

The Probability Set-Up.Pdf
CHAPTER 2 The probability set-up 2.1. Basic theory of probability We will have a sample space, denoted by S (sometimes Ω) that consists of all possible outcomes. For example, if we roll two dice, the sample space would be all possible pairs made up of the numbers one through six. An event is a subset of S. Another example is to toss a coin 2 times, and let S = fHH;HT;TH;TT g; or to let S be the possible orders in which 5 horses nish in a horse race; or S the possible prices of some stock at closing time today; or S = [0; 1); the age at which someone dies; or S the points in a circle, the possible places a dart can hit. We should also keep in mind that the same setting can be described using dierent sample set. For example, in two solutions in Example 1.30 we used two dierent sample sets. 2.1.1. Sets. We start by describing elementary operations on sets. By a set we mean a collection of distinct objects called elements of the set, and we consider a set as an object in its own right. Set operations Suppose S is a set. We say that A ⊂ S, that is, A is a subset of S if every element in A is contained in S; A [ B is the union of sets A ⊂ S and B ⊂ S and denotes the points of S that are in A or B or both; A \ B is the intersection of sets A ⊂ S and B ⊂ S and is the set of points that are in both A and B; ; denotes the empty set; Ac is the complement of A, that is, the points in S that are not in A. -

Random Variable = a Real-Valued Function of an Outcome X = F(Outcome)
Random Variables (Chapter 2) Random variable = A real-valued function of an outcome X = f(outcome) Domain of X: Sample space of the experiment. Ex: Consider an experiment consisting of 3 Bernoulli trials. Bernoulli trial = Only two possible outcomes – success (S) or failure (F). • “IF” statement: if … then “S” else “F” • Examine each component. S = “acceptable”, F = “defective”. • Transmit binary digits through a communication channel. S = “digit received correctly”, F = “digit received incorrectly”. Suppose the trials are independent and each trial has a probability ½ of success. X = # successes observed in the experiment. Possible values: Outcome Value of X (SSS) (SSF) (SFS) … … (FFF) Random variable: • Assigns a real number to each outcome in S. • Denoted by X, Y, Z, etc., and its values by x, y, z, etc. • Its value depends on chance. • Its value becomes available once the experiment is completed and the outcome is known. • Probabilities of its values are determined by the probabilities of the outcomes in the sample space. Probability distribution of X = A table, formula or a graph that summarizes how the total probability of one is distributed over all the possible values of X. In the Bernoulli trials example, what is the distribution of X? 1 Two types of random variables: Discrete rv = Takes finite or countable number of values • Number of jobs in a queue • Number of errors • Number of successes, etc. Continuous rv = Takes all values in an interval – i.e., it has uncountable number of values. • Execution time • Waiting time • Miles per gallon • Distance traveled, etc. Discrete random variables X = A discrete rv. -

Introduction to Stochastic Processes - Lecture Notes (With 33 Illustrations)
Introduction to Stochastic Processes - Lecture Notes (with 33 illustrations) Gordan Žitković Department of Mathematics The University of Texas at Austin Contents 1 Probability review 4 1.1 Random variables . 4 1.2 Countable sets . 5 1.3 Discrete random variables . 5 1.4 Expectation . 7 1.5 Events and probability . 8 1.6 Dependence and independence . 9 1.7 Conditional probability . 10 1.8 Examples . 12 2 Mathematica in 15 min 15 2.1 Basic Syntax . 15 2.2 Numerical Approximation . 16 2.3 Expression Manipulation . 16 2.4 Lists and Functions . 17 2.5 Linear Algebra . 19 2.6 Predefined Constants . 20 2.7 Calculus . 20 2.8 Solving Equations . 22 2.9 Graphics . 22 2.10 Probability Distributions and Simulation . 23 2.11 Help Commands . 24 2.12 Common Mistakes . 25 3 Stochastic Processes 26 3.1 The canonical probability space . 27 3.2 Constructing the Random Walk . 28 3.3 Simulation . 29 3.3.1 Random number generation . 29 3.3.2 Simulation of Random Variables . 30 3.4 Monte Carlo Integration . 33 4 The Simple Random Walk 35 4.1 Construction . 35 4.2 The maximum . 36 1 CONTENTS 5 Generating functions 40 5.1 Definition and first properties . 40 5.2 Convolution and moments . 42 5.3 Random sums and Wald’s identity . 44 6 Random walks - advanced methods 48 6.1 Stopping times . 48 6.2 Wald’s identity II . 50 6.3 The distribution of the first hitting time T1 .......................... 52 6.3.1 A recursive formula . 52 6.3.2 Generating-function approach . -

Odds: Gambling, Law and Strategy in the European Union Anastasios Kaburakis* and Ryan M Rodenberg†
63 Odds: Gambling, Law and Strategy in the European Union Anastasios Kaburakis* and Ryan M Rodenberg† Contemporary business law contributions argue that legal knowledge or ‘legal astuteness’ can lead to a sustainable competitive advantage.1 Past theses and treatises have led more academic research to endeavour the confluence between law and strategy.2 European scholars have engaged in the Proactive Law Movement, recently adopted and incorporated into policy by the European Commission.3 As such, the ‘many futures of legal strategy’ provide * Dr Anastasios Kaburakis is an assistant professor at the John Cook School of Business, Saint Louis University, teaching courses in strategic management, sports business and international comparative gaming law. He holds MS and PhD degrees from Indiana University-Bloomington and a law degree from Aristotle University in Thessaloniki, Greece. Prior to academia, he practised law in Greece and coached basketball at the professional club and national team level. He currently consults international sport federations, as well as gaming operators on regulatory matters and policy compliance strategies. † Dr Ryan Rodenberg is an assistant professor at Florida State University where he teaches sports law analytics. He earned his JD from the University of Washington-Seattle and PhD from Indiana University-Bloomington. Prior to academia, he worked at Octagon, Nike and the ATP World Tour. 1 See C Bagley, ‘What’s Law Got to Do With It?: Integrating Law and Strategy’ (2010) 47 American Business Law Journal 587; C -

Propensities and Probabilities
ARTICLE IN PRESS Studies in History and Philosophy of Modern Physics 38 (2007) 593–625 www.elsevier.com/locate/shpsb Propensities and probabilities Nuel Belnap 1028-A Cathedral of Learning, University of Pittsburgh, Pittsburgh, PA 15260, USA Received 19 May 2006; accepted 6 September 2006 Abstract Popper’s introduction of ‘‘propensity’’ was intended to provide a solid conceptual foundation for objective single-case probabilities. By considering the partly opposed contributions of Humphreys and Miller and Salmon, it is argued that when properly understood, propensities can in fact be understood as objective single-case causal probabilities of transitions between concrete events. The chief claim is that propensities are well-explicated by describing how they fit into the existing formal theory of branching space-times, which is simultaneously indeterministic and causal. Several problematic examples, some commonsense and some quantum-mechanical, are used to make clear the advantages of invoking branching space-times theory in coming to understand propensities. r 2007 Elsevier Ltd. All rights reserved. Keywords: Propensities; Probabilities; Space-times; Originating causes; Indeterminism; Branching histories 1. Introduction You are flipping a fair coin fairly. You ascribe a probability to a single case by asserting The probability that heads will occur on this very next flip is about 50%. ð1Þ The rough idea of a single-case probability seems clear enough when one is told that the contrast is with either generalizations or frequencies attributed to populations asserted while you are flipping a fair coin fairly, such as In the long run; the probability of heads occurring among flips is about 50%. ð2Þ E-mail address: [email protected] 1355-2198/$ - see front matter r 2007 Elsevier Ltd. -
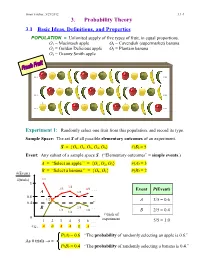
3. Probability Theory
Ismor Fischer, 5/29/2012 3.1-1 3. Probability Theory 3.1 Basic Ideas, Definitions, and Properties POPULATION = Unlimited supply of five types of fruit, in equal proportions. O1 = Macintosh apple O4 = Cavendish (supermarket) banana O2 = Golden Delicious apple O5 = Plantain banana O3 = Granny Smith apple … … … … … … Experiment 1: Randomly select one fruit from this population, and record its type. Sample Space: The set S of all possible elementary outcomes of an experiment. S = {O1, O2, O3, O4, O5} #(S) = 5 Event: Any subset of a sample space S. (“Elementary outcomes” = simple events.) A = “Select an apple.” = {O1, O2, O3} #(A) = 3 B = “Select a banana.” = {O , O } #(B) = 2 #(Event) 4 5 #(trials) 1/1 1 3/4 2/3 4/6 . Event P(Event) A 3/5 0.6 1/2 A 3/5 = 0.6 0.4 B 2/5 . 1/3 2/6 1/4 B 2/5 = 0.4 # trials of 0 experiment 1 2 3 4 5 6 . 5/5 = 1.0 e.g., A B A A B A . P(A) = 0.6 “The probability of randomly selecting an apple is 0.6.” As # trials → ∞ P(B) = 0.4 “The probability of randomly selecting a banana is 0.4.” Ismor Fischer, 5/29/2012 3.1-2 General formulation may be facilitated with the use of a Venn diagram: Experiment ⇒ Sample Space: S = {O1, O2, …, Ok} #(S) = k A Om+1 Om+2 O2 O1 O3 Om+3 O 4 . Om . Ok Event A = {O1, O2, …, Om} ⊆ S #(A) = m ≤ k Definition: The probability of event A, denoted P(A), is the long-run relative frequency with which A is expected to occur, as the experiment is repeated indefinitely.