Improving Latency for Interactive, Thin-Stream Applications Over Reliable Transport
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Hacker Public Radio
hpr0001 :: Introduction to HPR hpr0002 :: Customization the Lost Reason hpr0003 :: Lost Haycon Audio Aired on 2007-12-31 and hosted by StankDawg Aired on 2008-01-01 and hosted by deepgeek Aired on 2008-01-02 and hosted by Morgellon StankDawg and Enigma talk about what HPR is and how someone can contribute deepgeek talks about Customization being the lost reason in switching from Morgellon and others traipse around in the woods geocaching at midnight windows to linux Customization docdroppers article hpr0004 :: Firefox Profiles hpr0005 :: Database 101 Part 1 hpr0006 :: Part 15 Broadcasting Aired on 2008-01-03 and hosted by Peter Aired on 2008-01-06 and hosted by StankDawg as part of the Database 101 series. Aired on 2008-01-08 and hosted by dosman Peter explains how to move firefox profiles from machine to machine 1st part of the Database 101 series with Stankdawg dosman and zach from the packetsniffers talk about Part 15 Broadcasting Part 15 broadcasting resources SSTRAN AMT3000 part 15 transmitter hpr0007 :: Orwell Rolled over in his grave hpr0009 :: This old Hack 4 hpr0008 :: Asus EePC Aired on 2008-01-09 and hosted by deepgeek Aired on 2008-01-10 and hosted by fawkesfyre as part of the This Old Hack series. Aired on 2008-01-10 and hosted by Mubix deepgeek reviews a film Part 4 of the series this old hack Mubix and Redanthrax discuss the EEpc hpr0010 :: The Linux Boot Process Part 1 hpr0011 :: dd_rhelp hpr0012 :: Xen Aired on 2008-01-13 and hosted by Dann as part of the The Linux Boot Process series. -

Copyrighted Material
23_579959 bindex.qxd 9/27/05 10:05 PM Page 373 Index Symbols alias command, 200, 331 - (dash), 109 Anaconda installer feature, 19 $ (dollar sign), 330 analog channel changing, 66–67 ! (exclamation mark), 332 Analog RBG/xVGA output, 69 # (pound sign), 330 analog SVideo output, 69 ~ (tilde), 330 analog television output, 69 antiword conversion application, 173 A Appearance settings, Web Photo Gallery New aa boot label, eMoviX boot prompt, 136 Albums page, 45 abiword word processing application, 173 appliance modules, X10 protocol, 188 abuse application, 176 applications ace application, 176 for pen drives ACL (Access Control List), 259 downloading, 171–172 acm application, 176 gaming applications, 176–177 ActiveHome project, 185 general applications, 173–174 admin directory checks, Internet radio, 287 multimedia applications, 175 Admin email address option, Web Photo running from workstations, 316–317 Gallery Email and Registration apt-get install lirc command, 92 tab, 43 ASF (Advanced Systems Format), 128 administration tools, desktop features, a_steroid application, 176 342–343 atrpms-kickstart package, 79–80 administrative settings, Heyu project, 203–204 audacity application, 175 Advanced Systems Format (ASF), 128 audio players, Internet radio, 269–270 albums authentication parameters, Icecast server, 274 adding photos to, 48, 55 Autodesk automation files, eMoviX recording bookmarking, 54 COPYRIGHTED MATERIALcontent, 129 browsing, 51 AVI (Audio Video Interleaf ) format, 128 comments, adding, 54–55 creating, 47 B naming, 47 backend setup and startup, MythTV project slideshow settings, 46 configuration, 62, 110–113 summary additions, 48 backups, 29, 291 thumbnail images, 51 bad flag options, BZFlag project, 229 title creation, 48 bad words, managing, BZFlag project, 233 23_579959 bindex.qxd 9/27/05 10:05 PM Page 374 374 Index ■ B bandwidth consumption, Internet radio, 273 burning barrage application, 176 CDs Basic option, Devil-Linux firewall Main eMoviX project, 134–135 Menu, 253 MoviX2 project, 142–143 Battle Zone capture the Flag. -

A Doom-Based AI Research Platform for Visual Reinforcement Learning
ViZDoom: A Doom-based AI Research Platform for Visual Reinforcement Learning Michał Kempka, Marek Wydmuch, Grzegorz Runc, Jakub Toczek & Wojciech Jaskowski´ Institute of Computing Science, Poznan University of Technology, Poznan,´ Poland [email protected] Abstract—The recent advances in deep neural networks have are third-person perspective games, which does not match a led to effective vision-based reinforcement learning methods that real-world mobile-robot scenario. Last but not least, although, have been employed to obtain human-level controllers in Atari for some Atari 2600 games, human players are still ahead of 2600 games from pixel data. Atari 2600 games, however, do not resemble real-world tasks since they involve non-realistic bots trained from scratch, the best deep reinforcement learning 2D environments and the third-person perspective. Here, we algorithms are already ahead on average. Therefore, there is propose a novel test-bed platform for reinforcement learning a need for more challenging reinforcement learning problems research from raw visual information which employs the first- involving first-person-perspective and realistic 3D worlds. person perspective in a semi-realistic 3D world. The software, In this paper, we propose a software platform, ViZDoom1, called ViZDoom, is based on the classical first-person shooter video game, Doom. It allows developing bots that play the game for the machine (reinforcement) learning research from raw using the screen buffer. ViZDoom is lightweight, fast, and highly visual information. The environment is based on Doom, the customizable via a convenient mechanism of user scenarios. In famous first-person shooter (FPS) video game. It allows de- the experimental part, we test the environment by trying to veloping bots that play Doom using only the screen buffer. -

List of TCP and UDP Port Numbers from Wikipedia, the Free Encyclopedia
List of TCP and UDP port numbers From Wikipedia, the free encyclopedia This is a list of Internet socket port numbers used by protocols of the transport layer of the Internet Protocol Suite for the establishment of host-to-host connectivity. Originally, port numbers were used by the Network Control Program (NCP) in the ARPANET for which two ports were required for half- duplex transmission. Later, the Transmission Control Protocol (TCP) and the User Datagram Protocol (UDP) needed only one port for full- duplex, bidirectional traffic. The even-numbered ports were not used, and this resulted in some even numbers in the well-known port number /etc/services, a service name range being unassigned. The Stream Control Transmission Protocol database file on Unix-like operating (SCTP) and the Datagram Congestion Control Protocol (DCCP) also systems.[1][2][3][4] use port numbers. They usually use port numbers that match the services of the corresponding TCP or UDP implementation, if they exist. The Internet Assigned Numbers Authority (IANA) is responsible for maintaining the official assignments of port numbers for specific uses.[5] However, many unofficial uses of both well-known and registered port numbers occur in practice. Contents 1 Table legend 2 Well-known ports 3 Registered ports 4 Dynamic, private or ephemeral ports 5 See also 6 References 7 External links Table legend Official: Port is registered with IANA for the application.[5] Unofficial: Port is not registered with IANA for the application. Multiple use: Multiple applications are known to use this port. Well-known ports The port numbers in the range from 0 to 1023 are the well-known ports or system ports.[6] They are used by system processes that provide widely used types of network services. -

Application: Unity 3D Web Player
unity3d_1-adv.txt 1 of 2 Application: Unity 3D web player http://unity3d.com/webplayer/ Versions: <= 3.2.0.61061 Platforms: Windows Bug: heap corruption Exploitation: remote Date: 21 Feb 2012 Unity 3d is a game engine used in various games and it’s web player allows to play these games (unity3d extension) also directly from the web browser. # Vulnerabilities # Heap corruption caused by a negative 32bit size value which allows to execute malicious code. The problem is caused by the modification of the 64bit uncompressed size (handled as 32bit by the plugin) of the lzma header which is just composed by the following fields (from lzma86.h): Offset Size Description 0 1 = 0 - no filter, pure LZMA = 1 - x86 filter + LZMA 1 1 lc, lp and pb in encoded form 2 4 dictSize (little endian) 6 8 uncompressed size (little endian) Reading of the 64bit field as 32bit one (CMP EAX,4) and some of the subsequent operations: 070BEDA3 33C0 XOR EAX,EAX 070BEDA5 895D 08 MOV DWORD PTR SS:[EBP+8],EBX 070BEDA8 83F8 04 CMP EAX,4 070BEDAB 73 10 JNB SHORT webplaye.070BEDBD 070BEDAD 0FB65438 05 MOVZX EDX,BYTE PTR DS:[EAX+EDI+5] 070BEDB2 8B4D 08 MOV ECX,DWORD PTR SS:[EBP+8] 070BEDB5 D3E2 SHL EDX,CL 070BEDB7 0196 A4000000 ADD DWORD PTR DS:[ESI+A4],EDX 070BEDBD 8345 08 08 ADD DWORD PTR SS:[EBP+8],8 070BEDC1 40 INC EAX 070BEDC2 837D 08 40 CMP DWORD PTR SS:[EBP+8],40 070BEDC6 ^72 E0 JB SHORT webplaye.070BEDA8 070BEDC8 6A 4A PUSH 4A 070BEDCA 68 280A4B07 PUSH webplaye.074B0A28 ; ASCII "C:/BuildAgen t/work/b0bcff80449a48aa/PlatformDependent/CommonWebPlugin/CompressedFileStream.cp p" 070BEDCF 53 PUSH EBX 070BEDD0 FF35 84635407 PUSH DWORD PTR DS:[7546384] 070BEDD6 6A 04 PUSH 4 070BEDD8 68 00000400 PUSH 40000 070BEDDD E8 BA29E4FF CALL webplaye.06F0179C .. -

1. Why POCS.Key
Symptoms of Complexity Prof. George Candea School of Computer & Communication Sciences Building Bridges A RTlClES A COMPUTER SCIENCE PERSPECTIVE OF BRIDGE DESIGN What kinds of lessonsdoes a classical engineering discipline like bridge design have for an emerging engineering discipline like computer systems Observation design?Case-study editors Alfred Spector and David Gifford consider the • insight and experienceof bridge designer Gerard Fox to find out how strong the parallels are. • bridges are normally on-time, on-budget, and don’t fall ALFRED SPECTORand DAVID GIFFORD • software projects rarely ship on-time, are often over- AS Gerry, let’s begin with an overview of THE DESIGN PROCESS bridges. AS What is the procedure for designing and con- GF In the United States, most highway bridges are budget, and rarely work exactly as specified structing a bridge? mandated by a government agency. The great major- GF It breaks down into three phases: the prelimi- ity are small bridges (with spans of less than 150 nay design phase, the main design phase, and the feet) and are part of the public highway system. construction phase. For larger bridges, several alter- There are fewer large bridges, having spans of 600 native designs are usually considered during the Blueprints for bridges must be approved... feet or more, that carry roads over bodies of water, preliminary design phase, whereas simple calcula- • gorges, or other large obstacles. There are also a tions or experience usually suffices in determining small number of superlarge bridges with spans ap- the appropriate design for small bridges. There are a proaching a mile, like the Verrazzano Narrows lot more factors to take into account with a large Bridge in New Yor:k. -
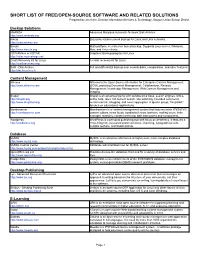
SHORT LIST of FREE/OPEN-SOURCE SOFTWARE and RELATED SOLUTIONS Prepared by Jim Klein, Director Information Services & Technology, Saugus Union School District
SHORT LIST OF FREE/OPEN-SOURCE SOFTWARE AND RELATED SOLUTIONS Prepared by Jim Klein, Director Information Services & Technology, Saugus Union School District Backup Solutions AMANDA Advanced Maryland Automatic Network Disk Archiver http://www.amanda.org Arkeia Enterprise-class network backup for Linux and Unix networks. http://www.arkeia.com Bacula Multi-platform, client/server based backup. Supports Linux server, Windows, http://www.bacula.org Mac, and Linux clients. CDTARchive or CDTAR Graphical Backup program for Linux http://cdtar.sourceforge.net Crash Recovery Kit for Linux A crash recovery kit for Linux http://crashrecovery.org DAR - Disk Archive Full and differential backup over several disks, compression, and other features http://dar.linux.free.fr Content Management Alfresco Alfresco is the Open Source Alternative for Enterprise Content Management http://www.alfresco.com (ECM), providing Document Management, Collaboration, Records Management, Knowledge Management, Web Content Management and Imaging. Drupal Drupal is an advanced portal with collaborative book, search engines, URLs, http://drupal.org online help, roles, full content search, site watching, threaded comments, http://www.drupaled.org version control, blogging, and news aggregator. A special group, “Drupaled,” focuses on educational applications. Mamboserver Mamboserver is a content management system that features inline WYSIWYG http://mamboserver.com content editors, news feeds, syndicated news, banners, mailing users, links manager, statistics, content archiving, date bamodules and components. Wordpress WordPress is a personal publishing tool with focus on aesthetics. It features a http://wordpress.org cross-blog tool, password protected posts, importing, typographical aids, multiple authors, and bookmarklets. Database MySQL MySQL is an attractive alternative to higher-cost, more complex database http://www.mysql.com technology. -

Ubuntu: Powerful Hacks and Customizations
Hacks, tips, and tricks to Krawetz put your OS into overdrive ubuntu Whether it’s speed, glitz, sounds, or security, you want to get the most out of your Ubuntu Linux system. This book shows you how to do just that. You’ll fi nd out how to customize the user interface, implement networking tools, optimize video, and more. You’ll then be able to build on these hacks to further tune, tweak, and customize Ubuntu to meet all your needs. The basic Ubuntu system is good, but with a few modifi cations, it can be made great. This book is packed with techniques that will help you: • Choose the right options when installing Ubuntu onto a Netbook, server, or other system • Install fi les for interoperability and collaborate with non-Linux systems • Tune the operating system for optimal performance ® • Enhance your graphics to take them to the next level Powerful Hacks and Customizations Powerful • Navigate the desktop, manage windows, and multitask between applications • Check for vulnerabilities and prevent undesirable access • Learn tricks to safely opening up the system with external network services Neal Krawetz, PhD, is a computer security professional with experience in computer forensics, ® profi ling, cryptography and cryptanalysis, artifi cial intelligence, and software solutions. Dr. Krawetz’s company, Hacker Factor, specializes in uncommon forensic techniques and anti-anonymity technologies. He has confi gured Ubuntu on everything from personal workstations to mission-critical servers. ubuntu Visit our Web site at www.wiley.com/compbooks $39.99 US/$47.99 CAN Powerful Hacks and Customizations ISBN 978-0-470-58988-5 Neal Krawetz Operating Systems / Linux Ubuntu® Powerful Hacks and Customizations Dr. -

Veritas Information Map User Guide
Veritas Information Map User Guide November 2017 Veritas Information Map User Guide Last updated: 2017-11-21 Legal Notice Copyright © 2017 Veritas Technologies LLC. All rights reserved. Veritas and the Veritas Logo are trademarks or registered trademarks of Veritas Technologies LLC or its affiliates in the U.S. and other countries. Other names may be trademarks of their respective owners. This product may contain third party software for which Veritas is required to provide attribution to the third party (“Third Party Programs”). Some of the Third Party Programs are available under open source or free software licenses. The License Agreement accompanying the Software does not alter any rights or obligations you may have under those open source or free software licenses. Refer to the third party legal notices document accompanying this Veritas product or available at: https://www.veritas.com/about/legal/license-agreements The product described in this document is distributed under licenses restricting its use, copying, distribution, and decompilation/reverse engineering. No part of this document may be reproduced in any form by any means without prior written authorization of Veritas Technologies LLC and its licensors, if any. THE DOCUMENTATION IS PROVIDED "AS IS" AND ALL EXPRESS OR IMPLIED CONDITIONS, REPRESENTATIONS AND WARRANTIES, INCLUDING ANY IMPLIED WARRANTY OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE OR NON-INFRINGEMENT, ARE DISCLAIMED, EXCEPT TO THE EXTENT THAT SUCH DISCLAIMERS ARE HELD TO BE LEGALLY INVALID. VERITAS TECHNOLOGIES LLC SHALL NOT BE LIABLE FOR INCIDENTAL OR CONSEQUENTIAL DAMAGES IN CONNECTION WITH THE FURNISHING, PERFORMANCE, OR USE OF THIS DOCUMENTATION. THE INFORMATION CONTAINED IN THIS DOCUMENTATION IS SUBJECT TO CHANGE WITHOUT NOTICE. -

Free Software for Schools
Free Software for Schools v8.12 A catalogue of open source computer programs for teaching and learning compiled by Con Zymaris Open Source Victoria revised by Bryant Patten The National Center for Open Source and Education This document was created in OpenOffice.org and uses Liberation fonts. Images by Darren Hester ● Green Apple - http://www.flickr.com/photos/ppdigital/2053320817 ● Green Apple on Books - http://www.flickr.com/photos/ppdigital/2327915966/ ● Stack of Old Books - http://www.flickr.com/photos/ppdigital/2329195889 ©2005-2008 Open Source Victoria – http://www.osv.org.au License: http://creativecommons.org/licenses/by-sa/2.5/au/ 2007 Modifications by Bryant Patten, NCOSE 2008 Modifications by Donna Benjamin, Open Source Victoria Table of Contents Table of Contents.................................................................................................................3 Why Consider Open Source Software.................................................................................4 How to Use this Catalog......................................................................................................5 Open Source Victoria ..........................................................................................................6 The National Center for Open Source and Education ........................................................7 Additional Software.............................................................................................................8 Three Paths of Open Source Software for Schools..............................................................9 -

Elenco Di Programmi Open Source
Elenco di programmi open source Da Wikipedia, l'enciclopedia libera. Vai a: Navigazione , cerca Questo è un elenco di programmi open source : software rilasciato sotto una licenza open source . Programmi che rispettano la definizione di open source possono essere chiamati anche Software Libero ; in particolare il progetto GNU è contrario all'uso di open source per indicare i suoi prodotti. Per ulteriori informazioni sul background filosofico del software open source, vedi movimento open source e movimento Software Libero . Tuttavia, quasi ogni programma che rispetti la Definizione di Open Source è anche Software Libero, e viceversa, e dunque è elencato qui. http://it.wikipedia.org/wiki/Elenco_di_programmi_open_source#CAD Campi applicati [modifica ] CAx [modifica ] CAD [modifica ] • o Computer aided design/drafting ( CAD : progettazione/disegno tecnico assistito dal computer) — o Computer-aided manufacturing ( CAM : fabbricazione/costruzione assistita dal computer) — o Computer numerical control ( CNC : macchine computerizzate a controllo numerico) — • A9CAD (sito) — CAD 2D e 3D (licenza freeware la versione 2D) per Windows • Alliance (sito) — set di tools e librerie CAD per GNU/Linux /Solaris • BlenderCAD (sito) — estensione CAD di Blender (versione alpha del 02/01/2004) • BRL-CAD (sito) — modellazione solida 3D computer-aided design (CAD) e molto altro • BabyaCAD (sito) — CAD 2D e 3D (licenza freeware) per Win e MacOSX • Collabcad (sito) — CAD/CAM 2D e 3D per Windows e GNU/Linux (.rpm) (free uso personale) • CNC-Suite (sito) — CAD/CAM