Optimally Sound Sigma Protocols Under DCRA
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Week 1: an Overview of Circuit Complexity 1 Welcome 2
Topics in Circuit Complexity (CS354, Fall’11) Week 1: An Overview of Circuit Complexity Lecture Notes for 9/27 and 9/29 Ryan Williams 1 Welcome The area of circuit complexity has a long history, starting in the 1940’s. It is full of open problems and frontiers that seem insurmountable, yet the literature on circuit complexity is fairly large. There is much that we do know, although it is scattered across several textbooks and academic papers. I think now is a good time to look again at circuit complexity with fresh eyes, and try to see what can be done. 2 Preliminaries An n-bit Boolean function has domain f0; 1gn and co-domain f0; 1g. At a high level, the basic question asked in circuit complexity is: given a collection of “simple functions” and a target Boolean function f, how efficiently can f be computed (on all inputs) using the simple functions? Of course, efficiency can be measured in many ways. The most natural measure is that of the “size” of computation: how many copies of these simple functions are necessary to compute f? Let B be a set of Boolean functions, which we call a basis set. The fan-in of a function g 2 B is the number of inputs that g takes. (Typical choices are fan-in 2, or unbounded fan-in, meaning that g can take any number of inputs.) We define a circuit C with n inputs and size s over a basis B, as follows. C consists of a directed acyclic graph (DAG) of s + n + 2 nodes, with n sources and one sink (the sth node in some fixed topological order on the nodes). -

The Complexity Zoo
The Complexity Zoo Scott Aaronson www.ScottAaronson.com LATEX Translation by Chris Bourke [email protected] 417 classes and counting 1 Contents 1 About This Document 3 2 Introductory Essay 4 2.1 Recommended Further Reading ......................... 4 2.2 Other Theory Compendia ............................ 5 2.3 Errors? ....................................... 5 3 Pronunciation Guide 6 4 Complexity Classes 10 5 Special Zoo Exhibit: Classes of Quantum States and Probability Distribu- tions 110 6 Acknowledgements 116 7 Bibliography 117 2 1 About This Document What is this? Well its a PDF version of the website www.ComplexityZoo.com typeset in LATEX using the complexity package. Well, what’s that? The original Complexity Zoo is a website created by Scott Aaronson which contains a (more or less) comprehensive list of Complexity Classes studied in the area of theoretical computer science known as Computa- tional Complexity. I took on the (mostly painless, thank god for regular expressions) task of translating the Zoo’s HTML code to LATEX for two reasons. First, as a regular Zoo patron, I thought, “what better way to honor such an endeavor than to spruce up the cages a bit and typeset them all in beautiful LATEX.” Second, I thought it would be a perfect project to develop complexity, a LATEX pack- age I’ve created that defines commands to typeset (almost) all of the complexity classes you’ll find here (along with some handy options that allow you to conveniently change the fonts with a single option parameters). To get the package, visit my own home page at http://www.cse.unl.edu/~cbourke/. -

Lower Bounds from Learning Algorithms
Circuit Lower Bounds from Nontrivial Learning Algorithms Igor C. Oliveira Rahul Santhanam Charles University in Prague University of Oxford Motivation and Background Previous Work Lemma 1 [Speedup Phenomenon in Learning Theory]. From PSPACE BPTIME[exp(no(1))], simple padding argument implies: DSPACE[nω(1)] BPEXP. Some connections between algorithms and circuit lower bounds: Assume C[poly(n)] can be (weakly) learned in time 2n/nω(1). Lower bounds Lemma [Diagonalization] (3) (the proof is sketched later). “Fast SAT implies lower bounds” [KL’80] against C ? Let k N and ε > 0 be arbitrary constants. There is L DSPACE[nω(1)] that is not in C[poly]. “Nontrivial” If Circuit-SAT can be solved efficiently then EXP ⊈ P/poly. learning algorithm Then C-circuits of size nk can be learned to accuracy n-k in Since DSPACE[nω(1)] BPEXP, we get BPEXP C[poly], which for a circuit class C “Derandomization implies lower bounds” [KI’03] time at most exp(nε). completes the proof of Theorem 1. If PIT NSUBEXP then either (i) NEXP ⊈ P/poly; or 0 0 Improved algorithmic ACC -SAT ACC -Learning It remains to prove the following lemmas. upper bounds ? (ii) Permanent is not computed by poly-size arithmetic circuits. (1) Speedup Lemma (relies on recent work [CIKK’16]). “Nontrivial SAT implies lower bounds” [Wil’10] Nontrivial: 2n/nω(1) ? (Non-uniform) Circuit Classes: If Circuit-SAT for poly-size circuits can be solved in time (2) PSPACE Simulation Lemma (follows [KKO’13]). 2n/nω(1) then NEXP ⊈ P/poly. SETH: 2(1-ε)n ? ? (3) Diagonalization Lemma [Folklore]. -

A Superpolynomial Lower Bound on the Size of Uniform Non-Constant-Depth Threshold Circuits for the Permanent
A Superpolynomial Lower Bound on the Size of Uniform Non-constant-depth Threshold Circuits for the Permanent Pascal Koiran Sylvain Perifel LIP LIAFA Ecole´ Normale Superieure´ de Lyon Universite´ Paris Diderot – Paris 7 Lyon, France Paris, France [email protected] [email protected] Abstract—We show that the permanent cannot be computed speak of DLOGTIME-uniformity), Allender [1] (see also by DLOGTIME-uniform threshold or arithmetic circuits of similar results on circuits with modulo gates in [2]) has depth o(log log n) and polynomial size. shown that the permanent does not have threshold circuits of Keywords-permanent; lower bound; threshold circuits; uni- constant depth and “sub-subexponential” size. In this paper, form circuits; non-constant depth circuits; arithmetic circuits we obtain a tradeoff between size and depth: instead of sub-subexponential size, we only prove a superpolynomial lower bound on the size of the circuits, but now the depth I. INTRODUCTION is no more constant. More precisely, we show the following Both in Boolean and algebraic complexity, the permanent theorem. has proven to be a central problem and showing lower Theorem 1: The permanent does not have DLOGTIME- bounds on its complexity has become a major challenge. uniform polynomial-size threshold circuits of depth This central position certainly comes, among others, from its o(log log n). ]P-completeness [15], its VNP-completeness [14], and from It seems to be the first superpolynomial lower bound on Toda’s theorem stating that the permanent is as powerful the size of non-constant-depth threshold circuits for the as the whole polynomial hierarchy [13]. -

ECC 2015 English
© Springer-Verlag 2015 SpringerMedizin.at/memo_inoncology SpringerMedizin.at 2/15 /memo_inoncology memo – inOncology SPECIAL ISSUE Congress Report ECC 2015 A GLOBAL CONGRESS DIGEST ON NSCLC Report from the 18th ECCO- 40th ESMO European Cancer Congress, Vienna 25th–29th September 2015 Editorial Board: Alex A. Adjei, MD, PhD, FACP, Roswell Park, Cancer Institute, New York, USA Wolfgang Hilbe, MD, Departement of Oncology, Hematology and Palliative Care, Wilhelminenspital, Vienna, Austria Massimo Di Maio, MD, National Institute of Tumor Research and Th erapy, Foundation G. Pascale, Napoli, Italy Barbara Melosky, MD, FRCPC, University of British Columbia and British Columbia Cancer Agency, Vancouver, Canada Robert Pirker, MD, Medical University of Vienna, Vienna, Austria Yu Shyr, PhD, Department of Biostatistics, Biomedical Informatics, Cancer Biology, and Health Policy, Nashville, TN, USA Yi-Long Wu, MD, FACS, Guangdong Lung Cancer Institute, Guangzhou, PR China Riyaz Shah, PhD, FRCP, Kent Oncology Centre, Maidstone Hospital, Maidstone, UK Filippo de Marinis, MD, PhD, Director of the Th oracic Oncology Division at the European Institute of Oncology (IEO), Milan, Italy Supported by Boehringer Ingelheim in the form of an unrestricted grant IMPRESSUM/PUBLISHER Medieninhaber und Verleger: Springer-Verlag GmbH, Professional Media, Prinz-Eugen-Straße 8–10, 1040 Wien, Austria, Tel.: 01/330 24 15-0, Fax: 01/330 24 26-260, Internet: www.springer.at, www.SpringerMedizin.at. Eigentümer und Copyright: © 2015 Springer-Verlag/Wien. Springer ist Teil von Springer Science + Business Media, springer.at. Leitung Professional Media: Dr. Alois Sillaber. Fachredaktion Medizin: Dr. Judith Moser. Corporate Publishing: Elise Haidenthaller. Layout: Katharina Bruckner. Erscheinungsort: Wien. Verlagsort: Wien. Herstellungsort: Linz. Druck: Friedrich VDV, Vereinigte Druckereien- und Verlags-GmbH & CO KG, 4020 Linz; Die Herausgeber der memo, magazine of european medical oncology, übernehmen keine Verantwortung für diese Beilage. -

Lecture 10: Logspace Division and Its Consequences 1. Overview
IAS/PCMI Summer Session 2000 Clay Mathematics Undergraduate Program Advanced Course on Computational Complexity Lecture 10: Logspace Division and Its Consequences David Mix Barrington and Alexis Maciel July 28, 2000 1. Overview Building on the last two lectures, we complete the proof that DIVISION is in FOMP (first-order with majority quantifiers, BIT, and powering modulo short numbers) and thus in both L-uniform TC0 and L itself. We then examine the prospects for improving this result by putting DIVISION in FOM or truly uniform TC0, and look at some consequences of the L-uniform result for complexity classes with sublogarithmic space. We showed last time that we can divide a long number by a nice long number, • that is, a product of short powers of distinct primes. We also showed that given any Y , we can find a nice number D such that Y=2 D Y . We finish the proof by finding an approximation N=A for D=Y , where≤ A ≤is nice, that is good enough so that XN=AD is within one of X=Y . b c We review exactly how DIVISION, ITERATED MULTIPLICATION, and • POWERING of long integers (poly-many bits) are placed in FOMP by this argument. We review the complexity of powering modulo a short integer, and consider • how this affects the prospects of placing DIVISION and the related problems in FOM. Finally, we take a look at sublogarithmic space classes, in particular problems • solvable in space O(log log n). These classes are sensitive to the definition of the model. We argue that the more interesting classes are obtained by marking the space bound in the memory before the machine starts. -
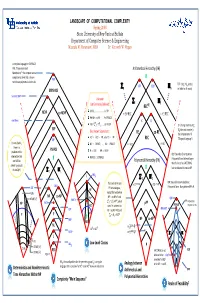
LANDSCAPE of COMPUTATIONAL COMPLEXITY Spring 2008 State University of New York at Buffalo Department of Computer Science & Engineering Mustafa M
LANDSCAPE OF COMPUTATIONAL COMPLEXITY Spring 2008 State University of New York at Buffalo Department of Computer Science & Engineering Mustafa M. Faramawi, MBA Dr. Kenneth W. Regan A complete language for EXPSPACE: PIM, “Polynomial Ideal Arithmetical Hierarchy (AH) Membership”—the simplest natural completeness level that is known PIM not to have polynomial‐size circuits. TOT = {M : M is total, K(2) TOT e e ∑n Πn i.e. halts for all inputs} EXPSPACE Succinct 3SAT Unknown ∑2 Π2 but Commonly Believed: RECRE L ≠ NL …………………….. L ≠ PH NEXP co‐NEXP = ∃∀.REC = ∀∃.REC P ≠ NP ∩ co‐NP ……… P ≠ PSPACE nxn Chess p p K D NP ≠ ∑ 2 ∩Π 2 ……… NP ≠ EXP D = {Turing machines M : EXP e Best Known Separations: Me does not accept e} = RE co‐RE the complement of K. AC0 ⊂ ACC0 ⊂ PP, also TC0 ⊂ PP QBF REC (“Diagonal Language”) For any fixed k, NC1 ⊂ PSPACE, …, NL ⊂ PSPACE = ∃.REC = ∀.REC there is a PSPACE problem in this P ⊂ EXP, NP ⊂ NEXP BQP: Bounded‐Error Quantum intersection that PSPACE ⊂ EXPSPACE Polynomial Time. Believed larger can NOT be Polynomial Hierarchy (PH) than P since it has FACTORING, solved by circuits p p k but not believed to contain NP. of size O(n ) ∑ 2 Π 2 L WS5 p p ∑ 2 Π 2 The levels of AH and poly. poly. BPP: Bounded‐Error Probabilistic TAUT = ∃∀ P = ∀∃ P SAT Polynomial Time. Many believe BPP = P. NC1 PH are analogous, NLIN except that we believe NP co‐NP 0 NP ∩ co‐NP ≠ P and NTIME [n2] TC QBF PARITY ∑p ∩Πp NP PP Probabilistic NP FACT 2 2 ≠ P , which NP ACC0 stand in contrast to P PSPACE Polynomial Time MAJ‐SAT CVP RE ∩ co‐RE = REC and 0 AC RE P P ∑2 ∩Π2 = REC GAP NP co‐NP REG NL poly 0 0 ∃ . -

Propositional Proof Complexity� Past� Present� and Future
Prop ositional Pro of Complexity Past Present and Future Paul Beame and Toniann Pitassi Abstract Pro of complexity the study of the lengths of pro ofs in prop ositional logic is an area of study that is fundamentally connected b oth to ma jor op en questions of computational complexity theory and to practical prop erties of automated theorem provers In the last decade there have b een a number of signicant advances in pro of complexity lower b ounds Moreover new connections b etween pro of complexity and circuit complexity have b een uncovered and the interplay b etween these two areas has b ecome quite rich In addition attempts to extend existing lower b ounds to ever stronger systems of pro of have spurred the introduction of new and interesting pro of systems adding b oth to the practical asp ects of pro of complexity as well as to a rich theory This note attempts to survey these developments and to lay out some of the op en problems in the area Introduction One of the most basic questions of logic is the following Given a uni versally true statement tautology what is the length of the shortest pro of of the statement in some standard axiomatic pro of system The prop osi tional logic version of this question is particularly imp ortant in computer science for b oth theorem proving and complexity theory Imp ortant related algorithmic questions are Is there an ecient algorithm that will pro duce a pro of of any tautology Is there an ecient algorithm to pro duce the shortest pro of of any tautology Such questions of theorem proving and -

Cosmology and Complexity 325
more information - www.cambridge.org/9780521199568 http://youtu.be/f477FnTe1M0 http://youtu.be/4qAIPC7vG3Y Quantum Computing since Democritus Written by noted quantum computing theorist Scott Aaronson, this book takes readers on a tour through some of the deepest ideas of math, computer science, and physics. Full of insights, arguments, and philosophical perspectives, the book covers an amazing array of topics. Beginning in antiquity with Democritus, it progresses through logic and set theory, computability and complexity theory, quantum computing, cryptography, the information content of quantum states, and the interpretation of quantum mechanics. There are also extended discussions about time travel, Newcomb’s Paradox, the Anthropic Principle, and the views of Roger Penrose. Aaronson’s informal style makes this fascinating book accessible to readers with scientific backgrounds, as well as students and researchers working in physics, computer science, mathematics, and philosophy. scott aaronson is an Associate Professor of Electrical Engineering and Computer Science at the Massachusetts Institute of Technology. Considered one of the top quantum complexity theorists in the world, he is well known both for his research in quantum computing and computational complexity theory, and for his widely read blog Shtetl-Optimized. Professor Aaronson also created Complexity Zoo, an online encyclopedia of computational complexity theory, and has written popular articles for Scientific American and The New York Times. His research and popular writing -

Low-Depth Uniform Threshold Circuits and the Bit-Complexity of Straight Line Programs
Electronic Colloquium on Computational Complexity, Revision 1 of Report No. 177 (2013) Low-Depth Uniform Threshold Circuits and the Bit-Complexity of Straight Line Programs Eric Allender1, Nikhil Balaji2, and Samir Datta2 1 Department of Computer Science, Rutgers University, USA [email protected] 2 Chennai Mathematical Institute, India {nikhil,sdatta}@cmi.ac.in Abstract. We present improved uniform TC0 circuits for division, matrix powering, and related prob- lems, where the improvement is in terms of “majority depth” (initially studied by Maciel and Th´erien). As a corollary, we obtain improved bounds on the complexity of certain problems involving arithmetic circuits, which are known to lie in the counting hierarchy. 1 Introduction √ How hard is it to compute the 10100-th bit of the binary expansion of 2? Datta and Pratap [DP12], and Jeˇr´abek [Jeˇr12] considered the question of computing the m-th bit of an algebraic number. Jeˇr´abek [Jeˇr12] showed that this problem has uniform TC0 circuits3 of size polynomial in m (which is not so useful when m = 10100). Earlier, Datta and Pratap showed a related result: when m is expressed in binary, this problem lies in the counting hierarchy. More precisely, Datta and Pratap showed that this problem is reducible to the problem of computing certain bits of the quotient of two numbers represented by arithmetic circuits of polynomial size.4 Thus, we are led to the problem of evaluating arithmetic circuits. In this paper, we focus on arithmetic circuits without input variables. Thus an arithmetic circuit is a (possibly very compact) representation of a number. -

Some Estimated Likelihoods for Computational Complexity
Some Estimated Likelihoods For Computational Complexity R. Ryan Williams MIT CSAIL & EECS, Cambridge MA 02139, USA Abstract. The editors of this LNCS volume asked me to speculate on open problems: out of the prominent conjectures in computational com- plexity, which of them might be true, and why? I hope the reader is entertained. 1 Introduction Computational complexity is considered to be a notoriously difficult subject. To its practitioners, there is a clear sense of annoying difficulty in complexity. Complexity theorists generally have many intuitions about what is \obviously" true. Everywhere we look, for every new complexity class that turns up, there's another conjectured lower bound separation, another evidently intractable prob- lem, another apparent hardness with which we must learn to cope. We are sur- rounded by spectacular consequences of all these obviously true things, a sharp coherent world-view with a wonderfully broad theory of hardness and cryptogra- phy available to us, but | gosh, it's so annoying! | we don't have a clue about how we might prove any of these obviously true things. But we try anyway. Much of the present cluelessness can be blamed on well-known \barriers" in complexity theory, such as relativization [BGS75], natural properties [RR97], and algebrization [AW09]. Informally, these are collections of theorems which demonstrate strongly how the popular and intuitive ways that many theorems were proved in the past are fundamentally too weak to prove the lower bounds of the future. { Relativization and algebrization show that proof methods in complexity theory which are \invariant" under certain high-level modifications to the computational model (access to arbitrary oracles, or low-degree extensions thereof) are not “fine-grained enough" to distinguish (even) pairs of classes that seem to be obviously different, such as NEXP and BPP. -

Three Puzzles on Mathematics, Computation, and Games
THREE PUZZLES ON MATHEMATICS, COMPUTATION, AND GAMES GIL KALAI HEBREW UNIVERSITY OF JERUSALEM AND YALE UNIVERSITY ABSTRACT. In this lecture I will talk about three mathematical puzzles involving mathematics and computation that have preoccupied me over the years. The first puzzle is to understand the amazing success of the simplex algorithm for linear programming. The second puzzle is about errors made when votes are counted during elections. The third puzzle is: are quantum computers possible? 1. INTRODUCTION The theory of computing and computer science as a whole are precious resources for mathematicians. They bring new questions, new profound ideas, and new perspectives on classical mathematical ob- jects, and serve as new areas for applications of mathematics and of mathematical reasoning. In my lecture I will talk about three mathematical puzzles involving mathematics and computation (and, at times, other fields) that have preoccupied me over the years. The connection between mathematics and computing is especially strong in my field of combinatorics, and I believe that being able to per- sonally experience the scientific developments described here over the last three decades may give my description some added value. For all three puzzles I will try to describe with some detail both the large picture at hand, and zoom in on topics related to my own work. Puzzle 1: What can explain the success of the simplex algorithm? Linear programming is the problem of maximizing a linear function φ subject to a system of linear inequalities. The set of solutions for the linear inequalities is a convex polyhedron P . The simplex algorithm was developed by George Dantzig.