Crowdsourcing Techniques for Affective Computing (Handbook Of
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Crowdsourcing: Today and Tomorrow
Crowdsourcing: Today and Tomorrow An Interactive Qualifying Project Submitted to the Faculty of the WORCESTER POLYTECHNIC INSTITUTE in partial fulfillment of the requirements for the Degree of Bachelor of Science by Fangwen Yuan Jun Liang Zhaokun Xue Approved Professor Sonia Chernova Advisor 1 Abstract This project focuses on crowdsourcing, the practice of outsourcing activities that are traditionally performed by a small group of professionals to an unknown, large community of individuals. Our study examines how crowdsourcing has become an important form of labor organization, what major forms of crowdsourcing exist currently, and which trends of crowdsourcing will have potential impacts on the society in the future. The study is conducted through literature study on the derivation and development of crowdsourcing, through examination on current major crowdsourcing platforms, and through surveys and interviews with crowdsourcing participants on their experiences and motivations. 2 Table of Contents Chapter 1 Introduction ................................................................................................................................. 8 1.1 Definition of Crowdsourcing ............................................................................................................... 8 1.2 Research Motivation ........................................................................................................................... 8 1.3 Research Objectives ........................................................................................................................... -

Crowdsourcing Database Systems: Overview and Challenges
Crowdsourcing Database Systems: Overview and Challenges Chengliang Chai∗, Ju Fany, Guoliang Li∗, Jiannan Wang#, Yudian Zhengz ∗Tsinghua University yRenmin University #Simon Fraser University zTwitter [email protected], [email protected], [email protected], [email protected], [email protected] Abstract—Many data management and analytics tasks, such inside database only; while crowdsourcing databases use as entity resolution, cannot be solely addressed by automated the “open-world” model, which can utilize the crowd to processes. Crowdsourcing is an effective way to harness the human cognitive ability to process these computer-hard tasks. crowdsource data, i.e., collecting a tuple/table or filling an Thanks to public crowdsourcing platforms, e.g., Amazon Me- attribute. Secondly, crowdsourcing databases can utilize the chanical Turk and CrowdFlower, we can easily involve hundreds crowd to support operations, e.g., comparing two objects, of thousands of ordinary workers (i.e., the crowd) to address these computer-hard tasks. However it is rather inconvenient to ranking multiple objects, and rating an object. These two main interact with the crowdsourcing platforms, because the platforms differences are attributed to involving the crowd to process require one to set parameters and even write codes. Inspired by database operations. In this paper, we review existing works traditional DBMS, crowdsourcing database systems have been proposed and widely studied to encapsulate the complexities of on crowdsourcing database system from the following aspects. interacting with the crowd. In this tutorial, we will survey and Crowdsourcing Overview. Suppose a requester (e.g., Ama- synthesize a wide spectrum of existing studies on crowdsourcing zon) has a set of computer-hard tasks (e.g., entity resolution database systems. -

A Blockchain-Based Decentralized Framework for Crowdsourcing
© 2020 JETIR February 2020, Volume 7, Issue 2 www.jetir.org (ISSN-2349-5162) A Blockchain-based Decentralized Framework for Crowdsourcing Priyanka Patil Department of Computer Science and Engineering, Sandip University, Nashik, Umakant Mandawkar Assistant Professor Department of Computer Science and Engineering. Sandip University, Nashik. Abstract- Crowdsourcing empowers open collaboration over the Internet. Crowdsourcing is a method in which an man or woman or an employer makes use of the understanding pool gift over the Internet to perform their task. These platforms provide numerous benefits quality, and lower assignment completion time. To execute tasks efficiently, with the employee pool to be had on the platform, task posters rely on the reputation managed and maintained by the platform. Usually, reputation management machine works on ratings supplied by means of the task posters. Such reputation systems are susceptible to several attacks as users or the platform owners, with malicious intents, can jeopardize the reputation device with fake reputations. A blockchain based approach for managing various crowdsourcing steps provides a promising route to manage reputation machine. We propose a crowdsourcing platform where in every step of crowdsourcing system is managed as transaction in Blockchain. This allows in establishing better trust inside the platform customers and addresses various attacks which are possible on a centralized crowdsourcing platform. Keywords- Block-chain, Crowdsourcing, centralized. I.INTRODUCTION A block-chain is a decentralized, distributed and public digital ledger this is used to record transactions across many computer systems so that any involved record cannot be altered retroactively, without the alteration of all next blocks. Crowdsourcing is a sourcing model in which people Or companies gain goods and services, including ideas and finances, from a large, exceedingly open and frequently rapid-evolving organization of internet users; it divides work among individuals to reap a cumulative result. -

Crowdfunding, Crowdsourcing and Digital Fundraising
Fundraising for Archives Crowdsourcing, Crowdfunding and Online Fundraising Crowdfunding, Crowdsourcing & Digital Fundraising Aim of Today This session will help to demystify the landscape surrounding crowdsourcing, crowdfunding, and online fundraising providing you with information and tools essential when considering these different platforms. Plan for today • Understand the digital fundraising techniques • Evaluate what components are required for an online campaign to be successful • What does a good online case for support look like • Reflect on examples of good practice • Build a crowdfunder plan 4 5 Apples…….oranges……or pears? Digital isn’t complicated – change is! 7 DO YOU HAVE THE RIGHT TOOLS FOR THE JOB TO NAVIGATE THE MAZE 8 Your Crowd… • Internal Stakeholders • External Stakeholders Databases: Which one do you choose? Microsoft Dynamics 10 Who’s Online ONS 2015 ONLINE DONATION METHOD Blackbaud 2014 12 DO YOU HAVE THE RIGHT TOOLS FOR THE JOB TO NAVIGATE THE MAZE • Email • Website / online platform • Social Media • CRM System / Database • Any others…… You need to be able to engage with your online audience on multiple platforms! 13 Email "Correo." by Itzel402 - Own work. Licensed under CC BY-SA 3.0 via Wikimedia Commons - 14 https://commons.wikimedia.org/wiki/File:Correo..jpg#/media/File:Correo..jpg http://uk.pcmag.com/e-mail-products/3708/guide/the-best-email-marketing-services-of-2015 15 Social Media 16 Social Media Channel Quick Guide •Facebook - Needs little explanation. Growing a little older in terms of demographics. Visual and video content working well. Tends to get higher engagement than Twitter. •Twitter - The other main channel. Especially useful for networking and news distribution. -

Perspectives on the Sharing Economy
Perspectives on the Sharing Economy Perspectives on the Sharing Economy Edited by Dominika Wruk, Achim Oberg and Indre Maurer Perspectives on the Sharing Economy Edited by Dominika Wruk, Achim Oberg and Indre Maurer This book first published 2019 Cambridge Scholars Publishing Lady Stephenson Library, Newcastle upon Tyne, NE6 2PA, UK British Library Cataloguing in Publication Data A catalogue record for this book is available from the British Library Copyright © 2019 by Dominika Wruk, Achim Oberg, Indre Maurer and contributors All rights for this book reserved. No part of this book may be reproduced, stored in a retrieval system, or transmitted, in any form or by any means, electronic, mechanical, photocopying, recording or otherwise, without the prior permission of the copyright owner. ISBN (10): 1-5275-3512-6 ISBN (13): 978-1-5275-3512-1 TABLE OF CONTENTS Introduction ................................................................................................. 1 Perspectives on the Sharing Economy Dominika Wruk, Achim Oberg and Indre Maurer 1. Business and Economic History Perspective 1.1 .............................................................................................................. 30 Renaissance of Shared Resource Use? The Historical Honeycomb of the Sharing Economy Philipp C. Mosmann 1.2 .............................................................................................................. 39 Can the Sharing Economy Regulate Itself? A Comparison of How Uber and Machinery Rings Link their Economic and Social -

Crowdsourcing As a Model for Problem Solving
CROWDSOURCING AS A MODEL FOR PROBLEM SOLVING: LEVERAGING THE COLLECTIVE INTELLIGENCE OF ONLINE COMMUNITIES FOR PUBLIC GOOD by Daren Carroll Brabham A dissertation submitted to the faculty of The University of Utah in partial fulfillment of the requirements for the degree of Doctor of Philosophy Department of Communication The University of Utah December 2010 Copyright © Daren Carroll Brabham 2010 All Rights Reserved The University of Utah Graduate School STATEMENT OF DISSERTATION APPROVAL The dissertation of Daren Carroll Brabham has been approved by the following supervisory committee members: Joy Pierce , Chair May 6, 2010 bate Approved Karim R. Lakhani , Member May 6, 2010 Date Approved Timothy Larson , Member May 6, 2010 Date Approved Thomas W. Sanchez , Member May 6, 2010 bate Approved Cassandra Van Buren , Member May 6, 2010 Date Approved and by Ann L Dar lin _ ' Chair of _________....:.; :.::.::...=o... .= "' :.: .=:.::"'g '--________ the Department of Communication and by Charles A. Wight, Dean of The Graduate School. ABSTRACT As an application of deliberative democratic theory in practice, traditional public participation programs in urban planning seek to cultivate citizen input and produce public decisions agreeable to all stakeholders. However, the deliberative democratic ideals of these traditional public participation programs, consisting of town hall meetings, hearings, workshops, and design charrettes, are often stymied by interpersonal dynamics, special interest groups, and an absence of key stakeholder demographics due to logistical issues of meetings or lack of interest and awareness. This dissertation project proposes crowdsourcing as an online public participation alternative that may ameliorate some of the hindrances of traditional public participation methods. Crowdsourcing is an online, distributed problem solving and production model largely in use for business. -

Crowdsourcing, Citizen Science Or Volunteered Geographic Information? the Current State of Crowdsourced Geographic Information
International Journal of Geo-Information Article Crowdsourcing, Citizen Science or Volunteered Geographic Information? The Current State of Crowdsourced Geographic Information Linda See 1,*, Peter Mooney 2, Giles Foody 3, Lucy Bastin 4, Alexis Comber 5, Jacinto Estima 6, Steffen Fritz 1, Norman Kerle 7, Bin Jiang 8, Mari Laakso 9, Hai-Ying Liu 10, Grega Milˇcinski 11, Matej Nikšiˇc 12, Marco Painho 6, Andrea P˝odör 13, Ana-Maria Olteanu-Raimond 14 and Martin Rutzinger 15 1 International Institute for Applied Systems Analysis (IIASA), Schlossplatz 1, Laxenburg A2361, Austria; [email protected] 2 Department of Computer Science, Maynooth University, Maynooth W23 F2H6, Ireland; [email protected] 3 School of Geography, University of Nottingham, Nottingham NG7 2RD, UK; [email protected] 4 School of Engineering and Applied Science, Aston University, Birmingham B4 7ET, UK; [email protected] 5 School of Geography, University of Leeds, Leeds LS2 9JT, UK; [email protected] 6 NOVA IMS, Universidade Nova de Lisboa (UNL), 1070-312 Lisboa, Portugal; [email protected] (J.E.); [email protected] (M.P.) 7 Department of Earth Systems Analysis, ITC/University of Twente, Enschede 7500 AE, The Netherlands; [email protected] 8 Faculty of Engineering and Sustainable Development, Division of GIScience, University of Gävle, Gävle 80176, Sweden; [email protected] 9 Finnish Geospatial Research Institute, Kirkkonummi 02430, Finland; mari.laakso@nls.fi 10 Norwegian Institute for Air Research (NILU), Kjeller 2027, Norway; [email protected] -

Crowdsourcing Comes to Logistics
Crowdsourcing Comes to Logistics A collaborative approach leverages the wisdom of the crowd to enrich and accelerate network design. Crowdsourcing Comes to Logistics 1 After driving distribution costs to post-recession lows, traditional methods of designing logistics networks are nearing the end of the road. Our 2016 State of Logistics survey found US business logistics expenditures dipped to 7.5 percent of gross domestic product in 2016, the lowest level since 2009 and the third straight yearly decline (see figure 1). In total dollars, logistics outlays of $1.39 trillion were down 1.5 percent, the first drop in seven years. Figure In , US business logistics costs declined basis points to . percent of GDP US business logistics costs as a share of nominal GDP . . . . . 34 bp . . . . . . . . Note: bp is basis points. Sources: CSCMP’s th Annual State of Logistics Report; A.T. Kearney analysis Shippers delighted by the descending cost curve should control their glee, though, because additional distribution savings will be hard to come by. The tried-and-true methods that produced recent cost reductions are losing their edge. Typical network optimization programs unfold in two stages: a design phase conducted by shippers with little or no input from logistics providers, followed by extended price-focused negotiations with various carriers, warehouse operators, and third-party logistics providers (3PLs). Benchmark-driven price negotiations have squeezed big concessions out of providers, particularly in sectors where excess capacity has sapped their bargaining power. But falling prices also have pushed carriers’ profit margins to unsustainably low levels, leading to disruptions such as last year’s bankruptcy of Korean container shipping giant Hanjin. -

Chances and Risks in Crowdworking and Crowdsourcing Work Design
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Publications at Bielefeld University Gr Interakt Org (2020) 51:59–69 https://doi.org/10.1007/s11612-020-00503-3 HAUPTBEITRÄGE - THEMENTEIL Working everywhere and every time?—Chances and risks in crowdworking and crowdsourcing work design Julian Schulte1 · Katharina D. Schlicher1 ·GünterW.Maier1 Published online: 27 January 2020 © The Author(s) 2020 Abstract This article of the journal Gruppe. Interaktion. Organisation (GIO) deals with the question how work and organizational psychology can contribute to a better understanding of work design in crowdwork. Over the last decade, crowdsourcing (CS) has gained much momentum and attention, yet people who use CS as an additional or exclusive source of income are experiencing less consideration overall. Therefore, we define the term crowdwork (CW), and delimit it from related concepts, e.g., CS and gig economy. We then address how work and organizational psychology theory can contribute to the research of CW, with a focus on work design, and where new approaches are necessary. We give an overview of current research in this field, and derive suggestions and recommendations for both further research approaches and also practical application of work design in CW. Keywords Crowdworking · Crowdsourcing · Work design Überall und jederzeit arbeiten können? – Chancen und Risiken der Arbeitsgestaltung im Crowdworking und Crowdsourcing Zusammenfassung Dieser Beitrag der Zeitschrift Gruppe. Interaktion. Organisation. (GIO) befasst sich mit der Frage, wie die Arbeits- und Organisationspsychologie zu einem besseren Verständnis der Arbeitsgestaltung im Crowdwork beitragen kann. In den letzten Jahren hat das Thema Crowdsourcing (CS) viel Beachtung gefunden. -
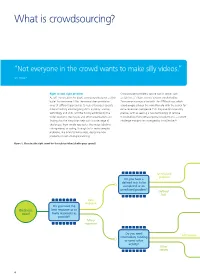
What Is Crowdsourcing?
To start a new section, hold down the apple+shift keys and click to release this object and type the section title in the box below. What is crowdsourcing? “Not everyone in the crowd wants to make silly videos.” Jeff Howe 37 Right crowd, right problem Crowdsourced problems can be vast in scope, such As Jeff Howe said in his book, crowdsourcing is not a silver as SETIlive, a ‘citizen science’ project conducted by bullet for commerce.38 But the crowd does provide an Zooniverse in conjunction with the SETI Institute, which array of different approaches to help enterprises operate asked people all over the world to help with the search for more efficiently amid ongoing shifts in policy, science, extra-terrestrial intelligence.39 Or they can be exquisitely technology and skills, and the fluidity exhibited by the precise, such as seeking a new technology to remove wider economy. Businesses and other organisations are microbubbles from extracorporeal bloodstreams, a current finding that the crowd can help with a wide range of challenge competition managed by InnoCentive.40 challenges, from simple rote tasks, like image labelling, raising money or voting, through to far more complex problems, like brainstorming ideas, designing new products or even strategic planning. Figure 1. Choosing the right crowd for the right problem [double-page spread] Collaborate Crowd collaboration e.g. openIDEO, Quirky Do you want respondents to Compete Crowd competition collaborate or e.g. TopCoder, Kaggle, InnoCentive compete to find a solution? Unresolved Crowd labour (microtask) problem e.g. openIDEO, Quirky Do you have a defined task to be Processing completed or an Crowd labour (mesotask) unresloved problem? Non– Do the tasks require e.g. -

Guest Perceptions of Homestays for Augmenting
GUEST PERCEPTIONS OF HOMESTAYS FOR AUGMENTING HOMESTAY-BRANDING STRATEGIES ESINAH RUTENDO MUTSETA AND RUFARO CYPRAIN NYARUVE Submitted in partial fulfilment of the requirements for the degree BACCALAREUS COMMERCII HONORES in the FACULTY OF BUSINESS AND ECONOMIC SCIENCES at the NELSON MANDELA UNIVERSITY DEPARTMENT OF BUSINESS MANAGEMENT Supervisor: Ms B Gray Date submitted: October 2018 Place: Port Elizabeth DECLARATION We, Esinah Rutendo Mutseta and Rufaro Cyprain Nyaruve, hereby declare that, • The content of this treatise, entitled “Guest perceptions of homestays for augmenting homestay-branding strategies”, is our original work; • All sources used or quoted have been acknowledged and documented by means of complete references; and • This treatise has not been previously submitted by us for a degree at any other tertiary institution. Esinah Rutendo Mutseta Rufaro Cyprain Nyaruve i ACKNOWLEDGEMENTS Esinah Rutendo Mutseta I would like to take this opportunity to express my immense gratitude and appreciation for the unwavering support, contribution, guidance and assistance received from the following individuals in the completion of this research: • To my supervisor, Ms Beverley Gray, thank you so much for your never-ending support, guidance and assistance throughout the year, it is greatly appreciated; • To my fellow student and friend Rufaro Nyaruve, for his hard work, assistance and tiresome efforts to ensure the completion of this research, it's been a long and hard road together and I wouldn’t have made it without you; • To my parents, siblings and friends, I cannot thank them enough for their support and encouragement for the duration of my studies. Thank you for always being there to encourage me when things got tough, having you as my support system gave me the strength to move forward. -

Crowdsourced Art and Collective Creativity
International Journal of Communication 6 (2012), 2962–2984 1932–8036/20120005 The Work of Art in the Age of Mediated Participation: Crowdsourced Art and Collective Creativity IOANA LITERAT University of Southern California Online crowdsourced art is the practice of using the Internet as a participatory platform to directly engage the public in the creation of visual, musical, literary, or dramatic artwork, with the goal of showcasing the relationship between the collective imagination and the individual artistic sensibilities of its participants. Discussing key examples and analyzing this artistic practice within multiple theoretical frameworks, this article fills a critical gap in the study of contemporary art and participatory culture by developing a typology of online crowdsourced art and exploring the levels of artistic participation. In view of its reliance on the artistic contribution of a large pool of geographically disperse participants, this type of art raises important questions about notions of collective creativity, authorship, and the aesthetic significance of digital participation. The Work of Art in the Age of Mediated Participation: Crowdsourced Art and Collective Creativity With the advent of digital participation and its alluring promise of widespread engagement and global interconnectedness, a cultural shift has taken place in traditional notions of authorship, creativity, and individual expression. This shift has been apparent in fields such as business, entrepreneurship, entertainment, journalism, but also in the arts. As companies realized the generative potential of networked online communities, the practice of crowdsourcing became a profitable and efficient strategy of harnessing these communities’ knowledge and creativity to create content, solve problems, and effectively perform corporate research and development tasks (Howe, 2006a).