Use of Linear Discriminant Analysis in Song Classification: Modeling Based on Wilco Albums
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Wilco-Songs Minimalistisch
Folkdays … Wilco-Songs minimalistisch Musik | Jeff Tweedy: Together At Last Jeff Tweedy, das ist einerseits ein Singer-Songwriter, andererseits ist er der Macher von Wilco in Zusammenarbeit mit John Stirratt, Glenn Kotche, Mikael Jorgensen, Nels Cline und Pat Sansone. Er war auch einmal mit dem Band-Projekt Golden Smog zu hören und es gibt neue Bands von ihm genannt Loose Fur und Tweedy. Das zuerst kurz als Fakten. Von TINA KAROLINA STAUNER Das neue Album von Jeff Tweedy ›Together At Last‹ ist wie ein Überbleibsel aus einer Zeit, in der die Freude Americana, Alternative Country und Neofolk zu hören manchmal fast ungetrübt war. Kein Mainstream laberte irgendeinen Klimbim dazwischen und neben Befindlichkeits- und Beziehungstexten war Sozial- und Gesellschaftskritik in Lyrics ein Zeichen für Anspruch und Niveau. Die Chicagoer Independent-Band Wilco hatte sich mit den ersten Alben in den 1990er Jahren mit Leib und Seele in den Spirit einer ganzen Independent-Generation gespielt. Entstanden aus Uncle Tupelo war Wilco immer wichtig im Diskurs. Bezogen auf traditionelles Wissen über Country und Folk hatte die Band einen ureigenen Sound und integrierte manchmal auch neue und elektronische Klänge in den Kontext. Mittlerweile scheint Jeff Tweedy teils zynisch bis zum geht-nicht-mehr und nach ›Star Wars‹ und ›Schmilco‹ mit Cover-Artwork wie ein Cartoon kam ein ›Together At Last‹. Vergangenheit ist das Woody Guthrie Project, das er mit Nora Guthrie und Billy Bragg vor Jahren veröffentlichte. Vergangenheit sind die frühen Independent-Jahre, wenn es überhaupt noch Leute gibt, die sich daran erinnern. Vergangenheit ist die Band-Dokumentation ›Man in the Sand‹. Vergangenheit sind Songs wie ›In A Future Age‹. -

SOUL ASYLUM Biography by Arthur Levy
SOUL ASYLUM biography by Arthur Levy “It’s a crazy mixed up world out there, Someone’s always got a gun and it’s all about money You live with loneliness, or you live with somebody who’s crazy It’s just a crazy mixed up world …” (“Crazy Mixed Up World”) Chapter 1. Every Cloud Has One Renewed and revitalized, Soul Asylum founders Dave Pirner and Dan Murphy return to rock’s front line with THE SILVER LINING, their first new studio release since 1998’s Candy From a Stranger. That album inadvertently kicked off a seven-year sabbatical for the group, which telescoped into the death of bassist Karl Mueller in June 2005, the other founding member of the triumvirate that has steered Soul Asylum through rock’s white water for the past two decades plus. The re-emergence of the group on THE SILVER LINING is as much a reaffirmation of Soul Asylum’s commitment to the music as it is a dedication to Karl, who worked and played on the album right up until the end. They were joined in the studio by not-so-new heavyweight Minneapolis drummer Michael Bland (who has played with everyone from Paul Westerberg to Prince). The band is now complemented by Tommy Stinson on bass, a member of fellow Twin Cities band the Replacements since age 13, and a pal of Dan’s since he was in high school and Tommy in junior high. Tommy was the only friend that Karl could endorse to replace himself in the band. This hard-driving lineup was introduced for the first time in October 2005, when they played sold-out showcase dates at First Avenue in Minneapolis and the Bowery Ballroom in New York – within three days. -

(At) Miracosta
The Creative Music Recording Magazine Jeff Tweedy Wilco, The Loft, Producing, creating w/ Tom Schick Engineer at The Loft, Sear Sound Spencer Tweedy Playing drums with Mavis Staples & Tweedy Low at The Loft Alan Sparhawk on Jeff’s Production Holly Herndon AI + Choir + Process Ryan Bingham Crazy Heart, Acting, Singing Avedis Kifedjian of Avedis Audio in Behind the Gear Dave Cook King Crimson, Amy Helm, Ravi Shankar Mitch Dane Sputnik Sound, Jars of Clay, Nashville Gear Reviews $5.99 No. 132 Aug/Sept 2019 christy (at) miracosta (dot) edu christy (at) miracosta (dot) edu christy (at) miracosta (dot) edu christy (at) miracosta (dot) edu christy (at) miracosta (dot) edu christy (at) miracosta (dot) edu Hello and welcome to Tape Op 10 Letters 14 Holly Herndon 20 Jeff Tweedy 32 Tom Schick # 40 Spencer Tweedy 44 Gear Reviews ! 66 Larry’s End Rant 132 70 Behind the Gear with Avedis Kifedjian 74 Mitch Dane 77 Dave Cook Extra special thanks to Zoran Orlic for providing more 80 Ryan Bingham amazing photos from The Loft than we could possibly run. Here’s one more of Jeff Tweedy and Nels Cline talking shop. 83 page Bonus Gear Reviews Interview with Jeff starts on page 20. <www.zoranorlic.com> “How do we stay interested in the art of recording?” It’s a question I was considering recently, and I feel fortunate that I remain excited about mixing songs, producing records, running a studio, interviewing recordists, and editing this magazine after twenty-plus years. But how do I keep a positive outlook on something that has consumed a fair chunk of my life, and continues to take up so much of my time? I believe my brain loves the intersection of art, craft, and technology. -

“The Dream Girl; Classic American Illustration”
419 Main Street Red Wing, MN 55066 1-651-385-0500 www.RedWingFraming.com [email protected] News Release- For immediate release August 1st, 2007 Contact Valerie Becker, Red Wing Framing Gallery “The Dream Girl; Classic American Illustration” Red Wing Framing Gallery exhibits original illustration art from Dan Murphy’s Grapefruit Moon Gallery collection An exhibit of classic original American pin-up and glamour art -Sample images on page 2- Red Wing, Minnesota—Dan Murphy is in a constant pursuit of creativity. A founding member of the successful alternative rock bands Soul Asylum and Golden Smog, Murphy is known as a passionate musician. His time touring the U.S. afforded him the chance to explore his other passion, American illustration art. Over the past 25 years, Murphy has become a leading collector of original American illustration art. Murphy opened Grapefruit Moon Gallery in 2002, offering his collection for sale to the public. From September 13th through October 22, 2007 Red Wing Framing Gallery will exhibit and offer for sale 30 artworks from the Grapefruit Moon Gallery collection. Entitled “The Dream Girl; Classic American Illustration” the exhibit will display a variety of stunning and rare pieces of 20th century original illustration art. The Dream Girl exhibit offers a singular chance to see the artistry behind the sexy, enduring, and historic genre of pin-up and glamour art in America. The one-of-a-kind paintings and pastels on display at Red Wing Framing Gallery showcase the sophisticated and visionary commercial artists working from the 1920s through the 1950s. Through magazines, calendars, and advertising, these images of flappers, WWII Victory girls, Hollywood bombshells, and the girl next door became iconic. -

Chuck Klosterman on Pop
Chuck Klosterman on Pop A Collection of Previously Published Essays Scribner New York London Toronto Sydney SCRIBNER A Division of Simon & Schuster, Inc. 1230 Avenue of the Americas New York, NY 10020 www.SimonandSchuster.com Essays in this work were previously published in Fargo Rock City copyright © 2001 by Chuck Klosterman, Sex, Drugs, and Cocoa Puffs copyright © 2003, 2004 by Chuck Klosterman, Chuck Klosterman IV copyright © 2006, 2007 by Chuck Klosterman, and Eating the Dinosaur copyright © 2009 by Chuck Klosterman. All rights reserved, including the right to reproduce this book or portions thereof in any form whatsoever. For information address Scribner Subsidiary Rights Department, 1230 Avenue of the Americas, New York, NY 10020. First Scribner ebook edition September 2010 SCRIBNER and design are registered trademarks of The Gale Group, Inc., used under license by Simon & Schuster, Inc., the publisher of this work. For information about special discounts for bulk purchases, please contact Simon & Schuster Special Sales at 1- 866-506-1949 or [email protected]. The Simon & Schuster Speakers Bureau can bring authors to your live event. For more information or to book an event contact the Simon & Schuster Speakers Bureau at 1-866-248-3049 or visit our website at www.simonspeakers.com. Manufactured in the United States of America ISBN 978-1-4516-2477-9 Portions of this work originally appeared in The New York Times Magazine, SPIN magazine, and Esquire. Contents From Sex, Drugs, and Cocoa Puffs and Chuck Klosterman IV The -

Richard King Creates Harmony Through Musical Relationships
Richard King creates harmony through musical relationships By Jeremy Essig n 1982, Richard King booked a little-known band with a randomly chosen acronym to play at The Blue Note. Both the nightclub and the band, which had just recorded its first album, were 2 years old at the time. Following an appearance in support of their album Chronic Town, Michael Stipe and the other members of R.E.M. were about to leave The Blue Note, though known for building up on him. “I said, ‘No, it was Columbia when King’s partner Phil Costello noticed they were about bands, also holds a notorious place in alternative definitely (Costello).’” to loose a tire on their van, recalled Kevin Walsh – a longtime friend music history as the spot where an influential band Although The Blue Note of both King and Costello. self-destructed. might have missed out on Crow, When it came time to pay them, Costello provided extra money to Minnesota’s Husker Du, touring in support of King played an integral role in the purchase a new tire for the band, which would go on to become one 1987’s Warehouse: Songs and Stories, played their development of another regional of the most famous in rock and roll history. final show at The Blue Note. Drummer Grant Hart band — Uncle Tupelo from Belleville, Ill. “I can’t see myself at 30,” Stipe sang on “Little America,” the performed after missing the sound check and then Uncle Tupelo, whose members would band’s commentary on touring. On July 30, The Blue Note will do disappeared. -

January 20, 2006 | Section Three Chicago Reader | January 20, 2006 | Section Three 5
4CHICAGO READER | JANUARY 20, 2006 | SECTION THREE CHICAGO READER | JANUARY 20, 2006 | SECTION THREE 5 [email protected] The Meter www.chicagoreader.com/TheMeter The Treatment A day-by-day guide to our Critic’s Choices and other previews friday 20 Astronomer THE ASTRONOMER Multi-instrumentalist Charles Kim—the architect behind the deeply cinematic Pinetop Seven and Sinister Luck Ensemble—adds his vocals to the mix in his latest group, the Astronomer. But on the band’s eponymous self-released debut, his pedestrian singing lacks the supple, atmospheric quality of his guitar and pedal steel, NI diluting the effect of the spectral music: Kim played nearly TAT everything on the record, and the songs have a gentle, hovering beauty, but on the whole they sound lifeless. Hopefully he’ll get a spark from the musicians joining him here: Steve Dorocke (pedal steel), Jason Toth (drums), John TE MARIE DOS ET Abbey (upright bass), Jeff Frehling (accordion, guitar), and Emmett Kelly YV Tim Joyce (banjo). This show is a release party. The New Messengers of Happiness open. a 10 PM, Hideout, 1354 W. Wabansia, 773-227-4433, $8. —Peter Margasak BOUND STEMS These tuneful local indie rockers recently released their second EP, The Logic of Building the The Long Layover Body Plan (Flameshovel), a teaser for the forthcoming full- length Appreciation Night. Which label will release the LP is still up in the air: as Bob Mehr reported back in November, Guitarist Emmett Kelly liked Chicago so much he never finished his trip. the Bound Stems have attracted the interest of major indies like Domino and Barsuk. -

Central Florida Future, February 17, 1999
University of Central Florida STARS Central Florida Future University Archives 2-17-1999 Central Florida Future, February 17, 1999 Part of the Mass Communication Commons, Organizational Communication Commons, Publishing Commons, and the Social Influence and oliticalP Communication Commons Find similar works at: https://stars.library.ucf.edu/centralfloridafuture University of Central Florida Libraries http://library.ucf.edu This Newspaper is brought to you for free and open access by the University Archives at STARS. It has been accepted for inclusion in Central Florida Future by an authorized administrator of STARS. For more information, please contact [email protected]. Recommended Citation "Central Florida Future, February 17, 1999" (1999). Central Florida Future. 1480. https://stars.library.ucf.edu/centralfloridafuture/1480 Jasketball tea1tts re1ttaitt perfect at ho1tte agaitttt f AAC - See Sports A D I G I T A L C I T Y 0 R L A N D O C O M M U N I T Y P. A R T N E R (AOL Keyword: Orlando) www.orlando.digitalcity.com State requests budget documents on expenses SHELLEY WILSON $750,000. The Senate passed this amount STAFF WRITER 1998 Budget Proposal - the only on Oct. 8 of last year. James Smith, Jr., director of This week the State University University Budgets, requested the System is expected to receive the docu~ one questioned in UCF history increase in spending for Activity and mentation it requested from UCF's Service Fees in a memo sent to Ron Student Government on budget alloca the ones who said we don't need this In the pas! 20 years, 14 addendum Stubbs, director of Budgets for the State tions. -

Order Form Full
JAZZ ARTIST TITLE LABEL RETAIL ADDERLEY, CANNONBALL SOMETHIN' ELSE BLUE NOTE RM112.00 ARMSTRONG, LOUIS LOUIS ARMSTRONG PLAYS W.C. HANDY PURE PLEASURE RM188.00 ARMSTRONG, LOUIS & DUKE ELLINGTON THE GREAT REUNION (180 GR) PARLOPHONE RM124.00 AYLER, ALBERT LIVE IN FRANCE JULY 25, 1970 B13 RM136.00 BAKER, CHET DAYBREAK (180 GR) STEEPLECHASE RM139.00 BAKER, CHET IT COULD HAPPEN TO YOU RIVERSIDE RM119.00 BAKER, CHET SINGS & STRINGS VINYL PASSION RM146.00 BAKER, CHET THE LYRICAL TRUMPET OF CHET JAZZ WAX RM134.00 BAKER, CHET WITH STRINGS (180 GR) MUSIC ON VINYL RM155.00 BERRY, OVERTON T.O.B.E. + LIVE AT THE DOUBLET LIGHT 1/T ATTIC RM124.00 BIG BAD VOODOO DADDY BIG BAD VOODOO DADDY (PURPLE VINYL) LONESTAR RECORDS RM115.00 BLAKEY, ART 3 BLIND MICE UNITED ARTISTS RM95.00 BROETZMANN, PETER FULL BLAST JAZZWERKSTATT RM95.00 BRUBECK, DAVE THE ESSENTIAL DAVE BRUBECK COLUMBIA RM146.00 BRUBECK, DAVE - OCTET DAVE BRUBECK OCTET FANTASY RM119.00 BRUBECK, DAVE - QUARTET BRUBECK TIME DOXY RM125.00 BRUUT! MAD PACK (180 GR WHITE) MUSIC ON VINYL RM149.00 BUCKSHOT LEFONQUE MUSIC EVOLUTION MUSIC ON VINYL RM147.00 BURRELL, KENNY MIDNIGHT BLUE (MONO) (200 GR) CLASSIC RECORDS RM147.00 BURRELL, KENNY WEAVER OF DREAMS (180 GR) WAX TIME RM138.00 BYRD, DONALD BLACK BYRD BLUE NOTE RM112.00 CHERRY, DON MU (FIRST PART) (180 GR) BYG ACTUEL RM95.00 CLAYTON, BUCK HOW HI THE FI PURE PLEASURE RM188.00 COLE, NAT KING PENTHOUSE SERENADE PURE PLEASURE RM157.00 COLEMAN, ORNETTE AT THE TOWN HALL, DECEMBER 1962 WAX LOVE RM107.00 COLTRANE, ALICE JOURNEY IN SATCHIDANANDA (180 GR) IMPULSE -
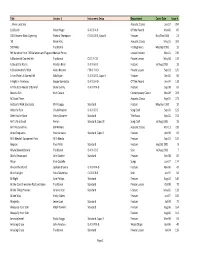
Public Song List 06.01.18.Xlsx
Title Creator 1 Instrument Setup Department Cover Date Issue # ... River unto Sea Acoustic Classic Jun‐17 294 101 South Peter Finger D A E G A D Off the Record Mar‐00 87 1952 Vincent Black Lightning Richard Thompson C G D G B E, Capo III Feature Nov/Dec 1993 21 '39 Brian May Acoustic Classic May‐15 269 500 Miles Traditional For Beginners Mar/Apr 1992 11 9th Variaon from "20 Variaons and Fugue onManuel Ponce Lesson Feature Nov‐10 215 A Blacksmith Courted Me Traditional C G C F C D Private Lesson May‐04 137 A Day at the Races Preston Reed D A D G B E Feature Jul/Aug 1992 13 A Grandmother's Wish Keola Beamer F Bb C F A D Private Lesson Sep‐01 105 A Hard Rain's A‐Gonna Fall Bob Dylan D A D G B E, Capo II Feature Dec‐00 96 A Night in Frontenac Beppe Gambetta D A D G A D Off the Record Jun‐04 138 A Tribute to Peador O'Donnell Donal Lunny D A D F# A D Feature Sep‐98 69 About a Girl Kurt Cobain Contemporary Classic Nov‐09 203 AC Good Times Acoustic Classic Aug‐15 272 Addison's Walk (excerpts) Phil Keaggy Standard Feature May/Jun 1992 12 After the Rain Chuck Prophet D A D G B E Song Craft Sep‐03 129 After You've Gone Henry Creamer Standard The Basics Sep‐05 153 Ain't Life a Brook Ferron Standard, Capo VII Song Craft Jul/Aug 1993 19 Ain't No Sunshine Bill Withers Acoustic Classic Mar‐11 219 Aires Choqueros Paco de Lucia Standard, Capo II Feature Apr‐98 64 Al Di Meola's Equipment Picks Al Di Meola Feature Sep‐01 105 Alegrias Paco Peña Standard Feature Sep/Oct 1991 8 Alhyia Bilawal (Dawn) Traditional D A D G B E Solo Jul/Aug 1991 7 Alice's Restaurant -

Rock the Block 2012
The LGBTTQ* Wab Kinew — page 7 Collective — page 2 Miss Q: Distractions U-Passes Across the Ahoy! — page 8 Brandon University’s Student Newspaper: giving up our free time sinceNation 1910 — page 7 Volume 103, Issue 3 — September 18th, 2012 Clockwise from top-left: Down With Webster, My Darkest Days’ Matt Walst, and April Wine. Photo credit Brady Knight. Arguably the most fun to be had on Rosser Avenue all year Richard Wong T of downtown Brandon Rock thewere Block once again 2012 shaken to the core as Rock The Web Editor Blockhe foundationswent off to rousing success. The 2012 edition of Brandon University’s annual fun-fest transformed the streets into a musical haven and gave students a chance to lose their minds be- fore school makes them really lose their minds. April Wine filled the air with nostalgia, send- to reach critical mass midway through the set and a particularly nerdtastic drum solo. The boys from ing iconic sounds off into the sky as the sun be- eventually everyone was doing a little “Porn Star Toronto were so good that they managed to steal gan to set. The legendary Canadian act surely Dancing”. the show at a concert which they were already brought back fond memories for anyone who has Down With Webster was greeted by hordes of headlining. ever listened to the radio. eager fans and immediately whipped the Rock The Block was once more an incredibly My Darkest Days wasted no time in throw- masses into a frenzy, injecting the crowd with fun and successful event and The Quill will see ing down with their unique brand of sleazy a new level of energy. -

The Prospector, September 19, 2017
University of Texas at El Paso DigitalCommons@UTEP The rP ospector Special Collections Department 9-19-2017 The rP ospector, September 19, 2017 UTEP Student Publications Follow this and additional works at: http://digitalcommons.utep.edu/prospector Part of the Journalism Studies Commons, and the Mass Communication Commons Comments: This file is rather large, with many images, so it may take a few minutes to download. Please be patient. Recommended Citation UTEP Student Publications, "The rP ospector, September 19, 2017" (2017). The Prospector. 293. http://digitalcommons.utep.edu/prospector/293 This Article is brought to you for free and open access by the Special Collections Department at DigitalCommons@UTEP. It has been accepted for inclusion in The rP ospector by an authorized administrator of DigitalCommons@UTEP. For more information, please contact [email protected]. CAREER ISSUE VOL. 103, NO. 4 THE UNIVERSITY OF TEXAS AT EL PASO SEPTEMBER 19, 2017 Embarking on new possibilities NEWS Career Expo returns to UTEP. pg. 4 ENTERTAINMENT Students make careers off lmmaking. pg. 11 SPORTS UTEP graduate assistants return to their alma mater. pg. 13 AYLIN CARDOZA/ BIOMEDICAL CONCENTRATION/JUNIOR GABY VELASQUEZ / THE PROSPECTOR PAGE 2 SEPTEMBER 19, 2017 EDITOR-IN-CHIEF OPINION ADRIAN BROADDUS , 747-7477 Social media is the next job resume Being a journalist sucks, but it’s what I want BY ADRIAN BROADDUS Then comes the seemingly easy solu- BY CHRISTIAN VASQUEZ and edit video on the fly, be a social rate story, complete with video and The Prospector tion to this—“when I’m ready to start media guru, be able to work with photos, two hours later? That’s just my career or get a job, I’ll just delete all The Prospector Imagine years mass amounts of data, memorize stupid.