Processor Hardware Counter Statistics As a First-Class System Resource
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Binary Counter
Systems I: Computer Organization and Architecture Lecture 8: Registers and Counters Registers • A register is a group of flip-flops. – Each flip-flop stores one bit of data; n flip-flops are required to store n bits of data. – There are several different types of registers available commercially. – The simplest design is a register consisting only of flip- flops, with no other gates in the circuit. • Loading the register – transfer of new data into the register. • The flip-flops share a common clock pulse (frequently using a buffer to reduce power requirements). • Output could be sampled at any time. • Clearing the flip-flop (placing zeroes in all its bit) can be done through a special terminal on the flip-flop. 1 4-bit Register I0 D Q A0 Clock C I1 D Q A1 C I D Q 2 A2 C D Q A I3 3 C Clear Registers With Parallel Load • The clock usually provides a steady stream of pulses which are applied to all flip-flops in the system. • A separate control system is needed to determine when to load a particular register. • The Register with Parallel Load has a separate load input. – When it is cleared, the register receives it output as input. – When it is set, it received the load input. 2 4-bit Register With Parallel Load Load D Q A0 I0 C D Q A1 C I1 D Q A2 I2 C D Q A3 I3 C Clock Shift Registers • A shift register is a register which can shift its data in one or both directions. -

Cross Architectural Power Modelling
Cross Architectural Power Modelling Kai Chen1, Peter Kilpatrick1, Dimitrios S. Nikolopoulos2, and Blesson Varghese1 1Queen’s University Belfast, UK; 2Virginia Tech, USA E-mail: [email protected]; [email protected]; [email protected]; [email protected] Abstract—Existing power modelling research focuses on the processor are extensively explored using a cumbersome trial model rather than the process for developing models. An auto- and error approach after which a suitable few are selected [7]. mated power modelling process that can be deployed on different Such an approach does not easily scale for various processor processors for developing power models with high accuracy is developed. For this, (i) an automated hardware performance architectures since a different set of hardware counters will be counter selection method that selects counters best correlated to required to model power for each processor. power on both ARM and Intel processors, (ii) a noise filter based Currently, there is little research that develops automated on clustering that can reduce the mean error in power models, and (iii) a two stage power model that surmounts challenges in methods for selecting hardware counters to capture proces- using existing power models across multiple architectures are sor power over multiple processor architectures. Automated proposed and developed. The key results are: (i) the automated methods are required for easily building power models for a hardware performance counter selection method achieves compa- collection of heterogeneous processors as seen in traditional rable selection to the manual method reported in the literature, data centers that host multiple generations of server proces- (ii) the noise filter reduces the mean error in power models by up to 55%, and (iii) the two stage power model can predict sors, or in emerging distributed computing environments like dynamic power with less than 8% error on both ARM and Intel fog/edge computing [8] and mobile cloud computing (in these processors, which is an improvement over classic models. -

Experiment No
1 LIST OF EXPERIMENTS 1. Study of logic gates. 2. Design and implementation of adders and subtractors using logic gates. 3. Design and implementation of code converters using logic gates. 4. Design and implementation of 4-bit binary adder/subtractor and BCD adder using IC 7483. 5. Design and implementation of 2-bit magnitude comparator using logic gates, 8- bit magnitude comparator using IC 7485. 6. Design and implementation of 16-bit odd/even parity checker/ generator using IC 74180. 7. Design and implementation of multiplexer and demultiplexer using logic gates and study of IC 74150 and IC 74154. 8. Design and implementation of encoder and decoder using logic gates and study of IC 7445 and IC 74147. 9. Construction and verification of 4-bit ripple counter and Mod-10/Mod-12 ripple counter. 10. Design and implementation of 3-bit synchronous up/down counter. 11. Implementation of SISO, SIPO, PISO and PIPO shift registers using flip-flops. KCTCET/2016-17/Odd/3rd/ETE/CSE/LM 2 EXPERIMENT NO. 01 STUDY OF LOGIC GATES AIM: To study about logic gates and verify their truth tables. APPARATUS REQUIRED: SL No. COMPONENT SPECIFICATION QTY 1. AND GATE IC 7408 1 2. OR GATE IC 7432 1 3. NOT GATE IC 7404 1 4. NAND GATE 2 I/P IC 7400 1 5. NOR GATE IC 7402 1 6. X-OR GATE IC 7486 1 7. NAND GATE 3 I/P IC 7410 1 8. IC TRAINER KIT - 1 9. PATCH CORD - 14 THEORY: Circuit that takes the logical decision and the process are called logic gates. -
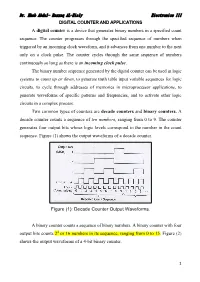
1 DIGITAL COUNTER and APPLICATIONS a Digital Counter Is
Dr. Ehab Abdul- Razzaq AL-Hialy Electronics III DIGITAL COUNTER AND APPLICATIONS A digital counter is a device that generates binary numbers in a specified count sequence. The counter progresses through the specified sequence of numbers when triggered by an incoming clock waveform, and it advances from one number to the next only on a clock pulse. The counter cycles through the same sequence of numbers continuously so long as there is an incoming clock pulse. The binary number sequence generated by the digital counter can be used in logic systems to count up or down, to generate truth table input variable sequences for logic circuits, to cycle through addresses of memories in microprocessor applications, to generate waveforms of specific patterns and frequencies, and to activate other logic circuits in a complex process. Two common types of counters are decade counters and binary counters. A decade counter counts a sequence of ten numbers, ranging from 0 to 9. The counter generates four output bits whose logic levels correspond to the number in the count sequence. Figure (1) shows the output waveforms of a decade counter. Figure (1): Decade Counter Output Waveforms. A binary counter counts a sequence of binary numbers. A binary counter with four output bits counts 24 or 16 numbers in its sequence, ranging from 0 to 15. Figure (2) shows-the output waveforms of a 4-bit binary counter. 1 Dr. Ehab Abdul- Razzaq AL-Hialy Electronics III Figure (2): Binary Counter Output Waveforms. EXAMPLE (1): Decade Counter. Problem: Determine the 4-bit decade counter output that corresponds to the waveforms shown in Figure (1). -

Isolation, Resource Management, and Sharing in Java
Processes in KaffeOS: Isolation, Resource Management, and Sharing in Java Godmar Back, Wilson C. Hsieh, Jay Lepreau School of Computing University of Utah Abstract many environments for executing untrusted code: for example, applets, servlets, active packets [41], database Single-language runtime systems, in the form of Java queries [15], and kernel extensions [6]. Current systems virtual machines, are widely deployed platforms for ex- (such as Java) provide memory protection through the ecuting untrusted mobile code. These runtimes pro- enforcement of type safety and secure system services vide some of the features that operating systems pro- through a number of mechanisms, including namespace vide: inter-application memory protection and basic sys- and access control. Unfortunately, malicious or buggy tem services. They do not, however, provide the ability applications can deny service to other applications. For to isolate applications from each other, or limit their re- example, a Java applet can generate excessive amounts source consumption. This paper describes KaffeOS, a of garbage and cause a Web browser to spend all of its Java runtime system that provides these features. The time collecting it. KaffeOS architecture takes many lessons from operating To support the execution of untrusted code, type-safe system design, such as the use of a user/kernel bound- language runtimes need to provide a mechanism to iso- ary, and employs garbage collection techniques, such as late and manage the resources of applications, analogous write barriers. to that provided by operating systems. Although other re- The KaffeOS architecture supports the OS abstraction source management abstractions exist [4], the classic OS of a process in a Java virtual machine. -

Libresource - Getting System Resource Information with Standard Apis Tuesday, 13 November 2018 14:55 (15 Minutes)
Linux Plumbers Conference 2018 Contribution ID: 255 Type: not specified libresource - Getting system resource information with standard APIs Tuesday, 13 November 2018 14:55 (15 minutes) System resource information, like memory, network and device statistics, are crucial for system administrators to understand the inner workings of their systems, and are increasingly being used by applications to fine tune performance in different environments. Getting system resource information on Linux is not a straightforward affair. The best way is tocollectthe information from procfs or sysfs, but getting such information from procfs or sysfs presents many challenges. Each time an application wants to get a system resource information, it has to open a file, read the content and then parse the content to get actual information. If application is running in a container then even reading from procfs directly may give information about resources on whole system instead of just the container. Libresource tries to fix few of these problems by providing a standard library with set of APIs through which we can get system resource information e.g. memory, CPU, stat, networking, security related information. Libresource provides/may provide following benefits: • Virtualization: In cases where application is running in a virtualized environment using cgroup or namespaces, reading from /proc and /sys file-systems might not give correct information as these are not cgroup aware. Library API will take care of this e.g. if a process is running in a cgroup then library should provide information which is local to that cgroup. • Ease of use: Currently applications needs to read this info mostly from /proc and /sys file-systems. -

Introduction to Performance Management
C HAPTER 1 Introduction to Performance Management Application developers and system administrators face similar challenges in managing the performance of a computer system. Performance manage- ment starts with application design and development and migrates to administration and tuning of the deployed production system or systems. It is necessary to keep performance in mind at all stages in the development and deployment of a system and application. There is a definite over- lap in the responsibilities of the developer and administrator. Sometimes determining where one ends and the other begins is more difficult when a single person or small group develops, admin- isters and uses the application. This chapter will look at: • Application developer’s perspective • System administrator’s perspective • Total system resource perspective • Rules of performance tuning 1.1 Application Developer’s Perspective The tasks of the application developer include: • Defining the application • Determining the specifications • Designing application components • Developing the application codes • Testing, tuning, and debugging • Deploying the system and application • Maintaining the system and application 3 4 Chapter 1 • Introduction to Performance Management 1.1.1 Defining the Application The first step is to determine what the application is going to be. Initially, management may need to define the priorities of the development group. Surveys of user organizations may also be carried out. 1.1.2 Determining Application Specifications Defining what the application will accomplish is necessary before any code is written. The users and developers should agree, in advance, on the particular features and/or functionality that the application will provide. Often, performance specifications are agreed upon at this time, and these are typically expressed in terms of user response time or system throughput measures. -

Linux® Resource Administration Guide
Linux® Resource Administration Guide 007–4413–004 CONTRIBUTORS Written by Terry Schultz Illustrated by Chris Wengelski Production by Karen Jacobson Engineering contributions by Jeremy Brown, Marlys Kohnke, Paul Jackson, John Hesterberg, Robin Holt, Kevin McMahon, Troy Miller, Dennis Parker, Sam Watters, and Todd Wyman COPYRIGHT © 2002–2004 Silicon Graphics, Inc. All rights reserved; provided portions may be copyright in third parties, as indicated elsewhere herein. No permission is granted to copy, distribute, or create derivative works from the contents of this electronic documentation in any manner, in whole or in part, without the prior written permission of Silicon Graphics, Inc. LIMITED RIGHTS LEGEND The electronic (software) version of this document was developed at private expense; if acquired under an agreement with the USA government or any contractor thereto, it is acquired as "commercial computer software" subject to the provisions of its applicable license agreement, as specified in (a) 48 CFR 12.212 of the FAR; or, if acquired for Department of Defense units, (b) 48 CFR 227-7202 of the DoD FAR Supplement; or sections succeeding thereto. Contractor/manufacturer is Silicon Graphics, Inc., 1600 Amphitheatre Pkwy 2E, Mountain View, CA 94043-1351. TRADEMARKS AND ATTRIBUTIONS Silicon Graphics, SGI, the SGI logo, and IRIX are registered trademarks and SGI Linux and SGI ProPack for Linux are trademarks of Silicon Graphics, Inc., in the United States and/or other countries worldwide. SGI Advanced Linux Environment 2.1 is based on Red Hat Linux Advanced Server 2.1 for the Itanium Processor, but is not sponsored by or endorsed by Red Hat, Inc. -

SUSE Linux Enterprise Server 11 SP4 System Analysis and Tuning Guide System Analysis and Tuning Guide SUSE Linux Enterprise Server 11 SP4
SUSE Linux Enterprise Server 11 SP4 System Analysis and Tuning Guide System Analysis and Tuning Guide SUSE Linux Enterprise Server 11 SP4 Publication Date: September 24, 2021 SUSE LLC 1800 South Novell Place Provo, UT 84606 USA https://documentation.suse.com Copyright © 2006– 2021 SUSE LLC and contributors. All rights reserved. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or (at your option) version 1.3; with the Invariant Section being this copyright notice and license. A copy of the license version 1.2 is included in the section entitled “GNU Free Documentation License”. For SUSE trademarks, see http://www.suse.com/company/legal/ . All other third party trademarks are the property of their respective owners. A trademark symbol (®, ™ etc.) denotes a SUSE or Novell trademark; an asterisk (*) denotes a third party trademark. All information found in this book has been compiled with utmost attention to detail. However, this does not guarantee complete accuracy. Neither SUSE LLC, its aliates, the authors nor the translators shall be held liable for possible errors or the consequences thereof. Contents About This Guide xi 1 Available Documentation xii 2 Feedback xiv 3 Documentation Conventions xv I BASICS 1 1 General Notes on System Tuning 2 1.1 Be Sure What Problem to Solve 2 1.2 Rule Out Common Problems 3 1.3 Finding the Bottleneck 3 1.4 Step-by-step Tuning 4 II SYSTEM MONITORING 5 2 System Monitoring Utilities 6 2.1 Multi-Purpose Tools 6 vmstat 7 -

Design and Implementation of High Speed Counters Using “MUX Based Full Adder (MFA)”
IOSR Journal of Electronics and Communication Engineering (IOSR-JECE) e-ISSN: 2278-2834,p- ISSN: 2278-8735.Volume 14, Issue 4, Ser. I (Jul.-Aug. 2019), PP 57-64 www.iosrjournals.org Design and Implementation of High speed counters using “MUX based Full Adder (MFA)” K.V.Jyothi1, G.P.S. Prashanti2, 1Student, 2Assistant Professor 1,2,(Department of Electronics and Communication Engineering, Gayatri Vidya Parishad College of Engineering For Women,Visakhapatnam, Andhra Pradesh, India) Corresponding Author: K.V.Jyothi Abstract: In this brief, a new binary counter design is proposed. Counters are used to determine how many number of inputs are active (in the logic ONE state) for multi input circuits. In the existing systems 6:3 and 7:3 Counters are designed with full and half adders, parallel counters, stacking circuits. It uses 3-bit stacking and 6-bit stacking circuits which group all the “1” bits together and then stacks are converted into binary counts. This leads to increase in delay and area. To overcome this problem “MUX based Full adder (MFA)” 6:3 and 7:3 counters are proposed. The backend counter simulations are achieved by using MENTOR GRAPHICS in 130nm technology and frontend simulations are done by using XILINX. This MFA counter is faster than existing stacking counters and also consumesless area. Additionally, using this counters in Wallace tree multiplier architectures reduces latency for 64 and 128-bit multipliers. Keywords: stacking circuits, parallel counters,High speed counters, MUX based full adder (MFA) counter,Mentor graphics,Xilinx,SPARTAN-6 FPGA. ----------------------------------------------------------------------------------------------------------------------------- ---------- Date of Submission: 28-07-2019 Date of acceptance: 13-08-2019 ----------------------------------------------------------------------------------------------------------------------------- ---------- I. -

IBM Power Systems Virtualization Operation Management for SAP Applications
Front cover IBM Power Systems Virtualization Operation Management for SAP Applications Dino Quintero Enrico Joedecke Katharina Probst Andreas Schauberer Redpaper IBM Redbooks IBM Power Systems Virtualization Operation Management for SAP Applications March 2020 REDP-5579-00 Note: Before using this information and the product it supports, read the information in “Notices” on page v. First Edition (March 2020) This edition applies to the following products: Red Hat Enterprise Linux 7.6 Red Hat Virtualization 4.2 SUSE Linux SLES 12 SP3 HMC V9 R1.920.0 Novalink 1.0.0.10 ipmitool V1.8.18 © Copyright International Business Machines Corporation 2020. All rights reserved. Note to U.S. Government Users Restricted Rights -- Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents Notices . .v Trademarks . vi Preface . vii Authors. vii Now you can become a published author, too! . viii Comments welcome. viii Stay connected to IBM Redbooks . ix Chapter 1. Introduction. 1 1.1 Preface . 2 Chapter 2. Server virtualization . 3 2.1 Introduction . 4 2.2 Server and hypervisor options . 4 2.2.1 Power Systems models that support PowerVM versus KVM . 4 2.2.2 Overview of POWER8 and POWER9 processor-based hardware models. 4 2.2.3 Comparison of PowerVM and KVM / RHV . 7 2.3 Hypervisors . 8 2.3.1 Introducing IBM PowerVM . 8 2.3.2 Kernel-based virtual machine introduction . 15 2.3.3 Resource overcommitment . 16 2.3.4 Red Hat Virtualization . 17 Chapter 3. IBM PowerVM management and operations . 19 3.1 Shared processor logical partitions . 20 3.1.1 Configuring a shared processor LPAR . -

REST API Specifications
IBM Hyper-Scale Manager Version 5.5.1 REST API Specifications IBM IBM Confidential SC27-6440-06 IBM Confidential Note Before using this information and the product it supports, read the information in “Notices” on page 73. Edition Notice Publication number: SC27-6440-06. This edition applies to IBM® Hyper-Scale Manager version 5.5.1 and to all subsequent releases and modifications, until otherwise indicated in a newer publication. © Copyright International Business Machines Corporation 2014, 2019. US Government Users Restricted Rights – Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. IBM Confidential Contents List of Tables........................................................................................................vii About this guide................................................................................................... ix Who should use this guide.......................................................................................................................... ix Conventions used in this guide................................................................................................................... ix Related information and publications.........................................................................................................ix Getting information, help, and service.........................................................................................................x IBM Publications Center.............................................................................................................................