180323-Tidyverse II
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
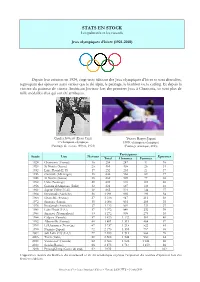
STATS EN STOCK Les Palmarès Et Les Records
STATS EN STOCK Les palmarès et les records Jeux olympiques d’hiver (1924-2018) Depuis leur création en 1924, vingt-trois éditions des Jeux olympiques d’hiver se sont déroulées, regroupant des épreuves aussi variées que le ski alpin, le patinage, le biathlon ou le curling. Et depuis la victoire du patineur de vitesse Américain Jewtraw lors des premiers Jeux à Chamonix, ce sont plus de mille médailles d’or qui ont été attribuées. Charles Jewtraw (Etats-Unis) Yuzuru Hanyu (Japon) 1er champion olympique 1000e champion olympique (Patinage de vitesse, 500 m, 1924) (Patinage artistique, 2018) Participants Année Lieu Nations Epreuves Total Hommes Femmes 1924 Chamonix (France) 16 258 247 11 16 1928 St Moritz (Suisse) 25 464 438 26 14 1932 Lake-Placid (E-U) 17 252 231 21 17 1936 Garmish (Allemagne) 28 646 566 80 17 1948 St Moritz (Suisse) 28 669 592 77 22 1952 Oslo (Norvège) 30 694 585 109 22 1956 Cortina d’Ampezzo (Italie) 32 821 687 134 24 1960 Squaw Valley (E-U) 30 665 521 144 27 1964 Innsbruck (Autriche) 36 1 091 892 199 34 1968 Grenoble (France) 37 1 158 947 211 35 1972 Sapporo (Japon) 35 1 006 801 205 35 1976 Innsbruck (Autriche) 37 1 123 892 231 37 1980 Lake Placid (E-U) 37 1 072 840 232 38 1984 Sarajevo (Yougoslavie) 49 1 272 998 274 39 1988 Calgary (Canada) 57 1 423 1 122 301 46 1992 Albertville (France) 64 1 801 1 313 488 57 1994 Lillehammer (Norvège) 67 1 737 1 215 522 61 1998 Nagano (Japon) 72 2 176 1 389 787 68 2002 Salt Lake City (E-U) 77 2 399 1 513 886 78 2006 Turin (Italie) 80 2 508 1 548 960 84 2010 Vancouver (Canada) 82 2 566 -

Marja-Liisa Kirvesniemi, Omaa Sukua Hämäläinen on Syntynyt Vuonna 1955 Simpeleellä
Marja-Liisa Kirvesniemi, omaa sukua Hämäläinen on syntynyt vuonna 1955 Simpeleellä. Marja-Liisa Kirvesniemen ura hiihdon huipulle oli pitkä ja tuskallinen. Hän oli jo 28-vuotias, kun kova työ hiihdon eteen sai palkkansa. Hän voitti Sarajevon olympialaisissa vuonna 1984 kaikki naisten henkilökohtaiset matkat eli 5, 10 ja 20 kilometrin hiihdot. Lisäksi hän sai viestistä pronssia. Sen jälkeen hän saavutti useita palkintosijoja erityisesti MM-hiihdoissa. Marja-Liisa Kirvesniemen ura huippu-urheilijana oli pitkä. Se alkoi MM-kisoissa Lahdessa vuonna 1978 ja päättyi Falunissa Ruotsissa 1993. Ari Sainio SUOMALAISIA URHEILIJOITA © 2000 Kehitysvammaliitto ry www.opike.fi ISBN 978-951-580-652-9 Elämän perusarvot Paikallislehti Kuhmolainen kirjoitti maaliskuussa 1999 lasten Hopeasompa-hiihtojen loppukilpailuista. Lehti oli huomannut kilpailupaikalla myös Marja-Liisa Kirvesniemen, jonka tytär Elisa hiihti kilpailuissa. Äiti oli kannustamassa tytärtään. Tällä kertaa Elisa ei ollut hiihtänyt lähellekään kärkipäätä. – Tärkeintä on, että lapset oppivat pärjäämään elämässä ja kunnioittamaan elämän perusarvoja, Marja-Liisa kertoi lehden haastattelussa. Sanat sopivat erityisen hyvin myös Marja-Liisa Kirvesniemeen itseensä. Hän on kokenut urallaan niin pettymyksiä kuin menestystä. Hän on esimerkki siitä, että menestys huippu-urheilussa ei riipu vain urheilijan lahjakkuudesta ja kovasta harjoittelusta. Siihen vaikuttaa koko hänen elämänsä. Kun elämässä kaikki on kohdallaan ja tasapainossa, voi syntyä suuria tekoja. Monet muut naishiihtäjät ovat menestyneet urallaan yhtä hyvin ja ehkä jopa paremmin. Marja-Liisan urassa on kuitenkin jotakin erityisen koskettavaa. Hänen vaikeuksia täynnä ollut uransa on jäänyt ihmisten mieliin. Ari Sainio SUOMALAISIA URHEILIJOITA © 2000 Kehitysvammaliitto ry www.opike.fi 2 Tie koko kansan sydämiin ei ole ollut sileä ja suora. Marja-Liisa ei ole aina ollut ihailtu, koko kansan rakastama hiihtäjä. -

JOHTOKUNTA 1980 KANSAINVÄLINEN 2.NUORTEN MM-KILPAILUT Puheenjohtaja: QUEBEC 15.-18
nen, 225,6. - Yhdistetty: 1. Karl Lustenberger, SUI (214,1/208,345) 422,445, 2. Rauno Miettinen (207,8/ 208,840) 416,640, 3. Jouko Karjalainen (197,2/ 219,100) 416,300, 6. Jukka Kuvaja (211.58/192,10) 403,68. FALUN 22.-25.02.1979 30 km: 1. Sven-Åke Lundbäck, SWE, 1.31.53,47, 9. Ar to Koivisto, 1.34.47.11. - 20 km: 1. Galina Kulakova, SOV, 1.02.42,77, 21. Päivi Renkola, 1.08.57,89. - 4x10 km: 1. Norja 1,1.59.13.15, 7. Suomi (Juha Mieto, Veli-Matti Pellinen, Jukka Kuvaja, Arto Koivisto) 2.01.41,36. - 4x5 km: 1. Neuvostoliitto, 1.04.26,72, 7. Suomi (Anne Piispanen, Eija Ruusunen, Päivi Renkola, Marja Auroma) 1.11 ,16,06. - Mäki P 70 m: 1. Roger Ruud, NOR, 251.5 2. Pentti Kokkonen, 245,9 5. Kari Ylianttila i 232.1. - Mäki P 90 m: 1. Johan Sätre, NOR, 239,7 2. Pentti Kokkonen, 231.2, 5. Kari Ylianttila, 222,0. - Yhdistetty: 1. Ulrich Wehling, DDR (208,40/229,50) 437,90, 5. Rauno Miettinen (204,14/ 200,00) 404,14, 6. Jukka Kuvaja (211.58/192,10) 403,68. JOHTOKUNTA 1980 KANSAINVÄLINEN 2.NUORTEN MM-KILPAILUT Puheenjohtaja: QUEBEC 15.-18. 02.1979 MENESTYS 1979 Hannu Koskivuori, Veikkaus Oy, 70009 Kuopio 9, pt. Poj~t 1.5 ~~: 1. Thomas Ericksson, SWE, 43.51.76, 5. 971 - 126677. LAHTI 01.-04.03.1979 Kan Harkonen, 44.48,22. - Tytöt 5 km : 1. Marlis Ros HANNU KOSKIVUORI Miehet. 15 km: 1. Anders Bakken, NOR, 49.10,76, 3. -

Sarajevo 1984
SARAJEVO 1984 The Games of the XIV Winter Olympiad. February 8-19, 1984. Sarajevo, Yugoslavia. 1 ALPINE SKIING MEN Downhill 1.Bill Johnson (USA) 2.Peter Muller (Switzerland) 2 Giant slalom 1.Max Julen (Switzerland) 3 2.Jure Franko (Yugoslavia) 4 3.Andreas Wenzel (Liechtenstein) 5 Slalom 1.Phil Mahre (USA) 2.Steve Mahre (USA) 6 WOMEN Downhill 1.Michela Figini (Switzerland) 2.Maria Walliser (Switzerland) 7 Giant slalom 1.Debbie Armstrong (USA) Slalom 1.Paola Magoni (Italy) 8 BIATHLON 20 km individual 1.Peter Angerer (West Germany) 2.Frank-Peter Roetsch (East Germany) 9 20 km individual: 3.Eirik Kvalfoss (Norway) 4 x 7.5 km: 2.Norway (Eirik Kvalfoss) 10 km sprint 1.Eirik Kvalfoss (Norway) 2.Peter Angerer (West Germany) 10 4 x 7.5 km 1.USSR 3.West Germany (Peter Angerer) 11 BOBSLEIGH Two-man 1.Wolfgang Hoppe / Dietmar Schauerhammer (East Germany) Two-man: 2.Bernhard Lehmann / Bogdan Musiol (East Germany) Four-man: 2.East Germany (Bernhard Lehmann, Bogdan Musiol) 12 Four-man 1.East Germany (Wolfgang Hoppe, Roland Wetzig, Dietmar Schauerhammer, Andreas Kirchner) 13 CROSS-COUNTRY SKIING MEN 15 km: 1.Gunde Svan (Sweden) 50 km: 2.Gunde Svan (Sweden) 30 km: 3.Gunde Svan (Sweden) 4 x 10 km: 1.Sweden (Gunde Svan) 15 km: 3.Harri Kirvesniemi (Finland) 4 x 10 km: 3.Finland (Juha Mieto, Harri Kirvesniemi) 14 30 km 1.Nikolai Zimyatov (USSR) 30 km: 2.Alexander Zavyalov (USSR) 4 x 10 km: 2.USSR (Alexander Zavyalov) 15 50 km 1.Thomas Wassberg (Sweden) 16 4 x 10 km 1.Sweden (Thomas Wassberg) 2.USSR (Nikolai Zimyatov) 17 WOMEN 5 km 1.Marja-Liisa Hamalainen -

Prior Winter Olympic Nations That No Longer Exist CZECHOSLOVAKIA
Prior Winter Olympic Nations that No Longer Exist CZECHOSLOVAKIA (TCH) Olympic History: Athletes from what later became Czechoslovakia first competed at the 1900 Olympics, representing Bohemia. Bohemian athletes also competed in 1906, 1908, and 1912. In 1920, Czechoslovakia sent its first true Olympic team to Antwerp. From 1920-1992 the only Olympic Games not attended by Czechoslovakia, including the Olympic Winter Games, was the 1984 Los Angeles Olympics. Czechoslovakia excelled in many different sports at the Olympics. The country’s most noteworthy athletes were distance runner Emil Zátopek and female gymnast Věra Čáslavská. Czechoslovakia peacefully split into the Czech Republic and Slovakia on 1 January 1993. Czechoslovakia competed at 16 Olympic Winter Games, as follows: 1924, 1928, 1932, 1936, 1948, 1952, 1956, 1960, 1964, 1968, 1972, 1976, 1980, 1984, 1988, and 1992. Czechoslovakia also competed in ice hockey at the 1920 Olympic Games. Czechoslovakia competed in the following sports/disciplines at the Olympic Winter Games – Men: Alpine Skiing, Biathlon, Bobsledding, Cross-Country Skiing, Figure Skating, Ice Hockey, Luge, Military Ski Patrol, Nordic Combined, Nordic Combined, Ski Jumping, Speedskating; Women: Alpine Skiing, Biathlon, Cross-Country Skiing, Figure Skating, Luge, Speedskating. Olympic Candidate Cities Prague (Praha) – 1924 Olympic Games. International Olympic Committee Members Dr. Jiří Guth-Jarkovský (1894-1943) (Bohemia/Czechoslovakia) Josef Gruss (1946-1965) František Kroutil (1965-1981) Vladimir Cernušak (1981-2002) -

Protesters Take Kiev, President Slams Coup Morsi Slams ‘Void’ Trial Continued from Page 1 Pages by Its Supporters
SUBSCRIPTION SUNDAY, FEBRUARY 23, 2014 RABI ALTHANI 23, 1435 AH www.kuwaittimes.net Joint efforts Chelsea to identify, stretch lead prosecute visa with last-gasp traffickers winner 2 20 INSIDE Protesters take Kiev, Max 24º Min 09º president slams coup High Tide 02:42 & 14:58 Low Tide Opposition icon Tymoshenko walks free 09:05 & 21:39 40 PAGES NO: 16086 150 FILS KIEV: Protesters took control of Ukraine’s that assertion. capital yesterday, seizing the president’s But Yanukovych vowed flatly to fight office as parliament voted to remove him any attempt to topple him. “They are try- and hold new elections. President Viktor ing to scare me. I have no intention to Yanukovych described the events as a leave the country. I am not going to coup and insisted he would not step resign; I’m the legitimately elected presi- down. After a tumultuous week that left dent,” Yanukovych said in a televised scores dead and Ukraine’s political des- statement, clearly shaken and with long tiny in flux, fears mounted that the coun- pauses in his speaking. “Everything that try could split in two - a Europe-leaning is happening today is, to a greater west and a Russian-leaning east and degree, vandalism and banditry and a south. Parliament arranged the release of coup d’etat,” he said. “I will do everything Yanukovych’s arch-rival, former Prime to protect my country from breakup, to Minister Yulia Tymoshenko, who was on stop bloodshed.” her way to Kiev to join the protesters. Ukraine, a nation of 46 million, has She promised to run for president, and huge strategic importance to Russia, said she will “make it so that no drop of Europe and the United States. -

Bedingte Strafen Gefordert KOMMENTAR Herrlich Verantwortliche Des Lawinenunglücks Von Evolène Vor Gericht Dämlich
AZ 3900 Brig Dienstag, 22. Februar 2005 Auflage: 27 354 Ex. 165. Jahrgang Nr. 44 Fr. 2.— CSP Bezirk Visp ...ein starker Partner 5 2 /8 3 Jahre fest M-Start-Hypo: Die ideale Starthilfe bei Ihrem Eigenheimkauf. Liste Nr. 3 Liste Nr. Bernhard Bittel, Stalden www.walliserbote.ch Redaktion: Tel. 027 922 99 88 Abonnentendienst: Tel. 027 948 30 50 Mengis Annoncen: Tel. 027 948 30 40 Bedingte Strafen gefordert KOMMENTAR Herrlich Verantwortliche des Lawinenunglücks von Evolène vor Gericht dämlich... S i t t e n. – (AP) Sechs Jahre Die Frauennamen Laura, nach dem Lawinenunglück von Aude und Sandrine hielten Evolène im Unterwallis mit Einzug in die März-Wahl- zwölf Toten ist am Montag der broschüre des Kantons Prozess gegen zwei Angeklagte Wallis. über die Verantwortlichkeit ge- Sie befinden sich auf Seite führt worden. Der Staatsanwalt vier des Büchleins, wo das forderte sechs Monate bedingt. richtige Ausfüllen des Die Verteidigung plädierte da- Wahlzettels für den Gros- gegen auf Freispruch, weil eine sen Rat erläutert wird. Was Gemeinde Leuk: Der Steuer- derartige Lawine nicht voraus- Laura, Aude und Sandrine koeffizient sinkt von 1,4 auf sehbar gewesen sei. Auf den zusätzlich verbindet: Diese 1,35. Foto wb Tag genau sechs Jahre nach ei- drei Frauennamen sind alle nem der grössten Lawinenun- durchgestrichen. «Strich- Steuern und glücke der Schweiz hat am Beispiele» mit Männerna- Montag in Sitten der Prozess men gibts keine. Schulden senken gegen die beiden Verantwortli- Mit Absicht ausschliesslich S u s t e n. – (wb) Die Schul- chen stattgefunden. Der dama- Frauennamen genommen, den Schritt für Schritt abbau- lige Gemeindepräsident und der um dem Wahlvolk das rich- en und die Steuern senken Bergsteiger André Georges als tige Streichen und Pana- sind die Ziele, welche sich damaliger Sicherheitsverant- schieren klar zu machen? die Gemeinde Leuk setzt. -
10 Kilometres, Women Times Contested 13 Total Competitors 421 Total Nations 50 Year Event Competitors N
Cross-Country Skiing – 10 kilometres, Women Times Contested 13 Total Competitors 421 Total Nations 50 Year Event Competitors Nations 1952 10 kilometres, Women 20 8 1956 10 kilometres, Women 40 11 1960 10 kilometres, Women 24 7 1964 10 kilometres, Women 35 12 1968 10 kilometres, Women 34 11 1972 10 kilometres, Women 42 12 1976 10 kilometres, Women 44 14 1980 10 kilometres, Women 38 12 1984 10 kilometres, Women 52 15 1988 10 kilometres, Classical, Women 52 17 2002 10 kilometres, Classical, Women 61 23 2006 10 kilometres, Classical, Women 72 29 2010 10 kilometres, Freestyle, Women 78 36 Medals Won by Nations RankUS RankEuro NOC Gold Silver Bronze Totals 1 1 Soviet Union 6 6 3 15 2 2 Finland 2 3 4 9 3 4 Norway 1 2 4 7 4 3 Sweden 2 - 1 3 5 5 Estonia 1 1 - 2 6 6 German Demo. Rep. 1 - - 1 7 7 Russia - 1 - 1 8 8 Italy - - 1 1 Totals (13 events) 13 13 13 39 Most Gold Medals 1 13 athletes tied with one. Most Medals 3 Raisa Smetanina (URS/RUS/120) 2 Lyubov Kozyreva-Baranova (URS/110) 2 Kristina Šmigun-Vähi (EST/110) 2 Mariya Gusakova (URS/101) 2 Galina Kulakova (URS/101) 2 Marit Bjørgen (NOR/011) 2 Helena Kivioja-Takalo (FIN/011) 2 Radiya Yeroshina (URS/011) Youngest Competitors 16-100 Gertrud Gasteiger (AUT-1976, *2 November 1959) 16-194 Andreja Smrekar (YUG-1984, *30 July 1967) 16-217 Amalija Belaj (YUG-1956, *25 June 1939) 17-037 Sylvia Schweiger (AUT-1976, *4 January 1959) 17-103 Fides Romanin (ITA-1952, *12 November 1934) 17-199 Li Xin (CHN-2010, *31 July 1992) 17-238 Ildegarda Taffra (ITA-1952, *30 June 1934) 17-287 Hellen Sander (CAN-1972, -

Calgary 1988
CALGARY 1988 The Games of the XV Winter Olympiad. February 13-28, 1988. Calgary, Canada. 1 ALPINE SKIING MEN Downhill 1.Pirmin Zurbriggen (Switzerland) 2 2.Peter Muller (Switzerland) 3.Franck Piccard (France) 3 Super-G 1.Franck Piccard (France) 3.Lars-Borje Eriksson (Sweden) 4 Giant slalom 1.Alberto Tomba (Italy) 3.Pirmin Zurbriggen (Switzerland) 5 Slalom 1.Alberto Tomba (Italy) 6 2.Frank Worndl (West Germany) 7 Combined 1.Hubert Strolz (Austria) 3.Paul Accola (Switzerland) 8 4.Luc Alphand (France) Giant slalom: 2.Hubert Strolz (Austria) 9 WOMEN Super-G 1.Sigrid Wolf (Austria) 2.Michela Figini (Switzerland) 3.Karen Percy (Canada) Downhill: 3.Karen Percy (Canada) 10 Downhill 1.Marina Kiehl (West Germany) 11 Giant slalom 1.Vreni Schneider (Switzerland) 12 Slalom 1.Vreni Schneider (Switzerland) 7.Paola Magoni (Italy) 13 Combined 11.Petra Kronberger (Austria) DNF.Vreni Schneider (Switzerland) Slalom: 2.Mateja Svet (Yugoslavia) 14 Giant slalom: 2.Christa Kinshofer (West Germany) Slalom: 3.Christa Kinshofer (West Germany) Giant slalom: 3.Maria Walliser (Switzerland) Combined: 3.Maria Walliser (Switzerland) 15 BIATHLON 20 km individual 1.Frank-Peter Roetsch (East Germany) 3.Johann Passler (Italy) 16 10 km sprint 1.Frank-Peter Roetsch (East Germany) 27.Josh Thompson (USA) 4 x 7.5 km 2.West Germany (Peter Angerer) 3.Italy (Johann Passler) 17 BOBSLEIGH Two-man 1.Janis Kipurs / Vladimir Kozlov (USSR) 2.Wolfgang Hoppe / Bogdan Musiol (East Germany) 3. Bernhard Lehmann / Mario Hoyer (East Germany) 18 28.Borislav Vujadinovic / Miro Pandurevic (Yugoslavia) -

Cuenta Con 100 Medallas Christine Se Impone En 1000 Metros De Patinaje
18/02/2010 21:50 Cuerpo D Pagina 3 Cyan Magenta Amarillo Negro 3 EL SIGLO DE DURANGO | VIERNES 19 DE FEBRERO DE 2010 | Noruega ya cuenta con 100 medallas Christine se impone en 1000 metros de patinaje de velocidad; Queralt, EFE en la final de halfpipe de Compañerismo. El noruego Emil Hegle Svendsen (i) adelanta a su snowboard. compatriota Ole Einar Bjoerndalen. EFE Vancouver,Canadá Doblete noruego; La noruega Tora Berger se impuso en la prueba de 15 ki- lómetros de biatlón femenino Bjoerndalen con 10 de Vancouver 2010 y logró la medalla número 100 para su EFE Bjoerndalen, el biatleta país en su historia unos Jue- Vancouver,Canadá más laureado de la historia, gos Olímpicos de invierno. entró por fin en el ‘club de los Berger, que fue quinta en El noruego Emil Hegle dos dígitos’ en número de me- los 10 kilómetros persecu- Svendsen se impuso en la dallas, en el que sólo estaban ción, se colgó al cuello la me- prueba de 20 kilómetros de tres fondistas: su compatriota dalla de oro tras ganar en el biatlón masculino de Vancou- Bjorn Daehlie (12), la rusa Whistler Olympic Park por ver 2010 por delante de su Raisa Smetanina (10) y la ita- delante de la kazaja Elena compatriota Ole Einar liana Stefania Belmondo (10). Khrustaleva, plata, y la bielo- Bjoerndalen, que ganó su dé- Ole Einar Bjoerndalen, de rrusa Darya Domracheva. cima medalla, esta vez de pla- 36 años, reparte sus diez tro- El miércoles, Noruega su- ta y compartida con el bielo- feos entre cinco de oro, cuatro mó su medalla número 99 gra- rruso Sergey Novikov,en unos de plata y una de bronce. -

Relay, Women Times Contested 10 (15) Total Competitors 331 (415) Total Nations 28 (30)
Cross-Country Skiing – Relay, Women Times Contested 10 (15) Total Competitors 331 (415) Total Nations 28 (30) Year Event Competitors Nations 1956 3 × 5 kilometres Relay, Women 30 10 1960 3 × 5 kilometres Relay, Women 15 5 1964 3 × 5 kilometres Relay, Women 24 8 1968 3 × 5 kilometres Relay, Women 24 8 1972 3 × 5 kilometres Relay, Women 33 11 1976 4 × 5 kilometres Relay, Women 36 9 1980 4 × 5 kilometres Relay, Women 32 8 1984 4 × 5 kilometres Relay, Women 48 12 1988 4 × 5 kilometres Relay, Women 48 12 1992 4 × 5 kilometres Relay, Women 52 13 1994 4 × 5 kilometres Relay, Women 56 14 1998 4 × 5 kilometres Relay, Women 64 16 2002 4 × 5 kilometres Relay, Women 52 13 2006 4 × 5 kilometres Relay, Women 68 17 2010 4 × 5 kilometres Relay, Women 64 16 Medals Won by Nations RankUS RankEuro NOC Gold Silver Bronze Totals 1 2 Norway 3 5 2 10 2 1 Soviet Union 4 3 1 8 3 4 Finland 1 2 5 8 4 5 Sweden 1 2 1 4 5 10 Italy - - 4 4 6 3 Russia 3 - - 3 7 6 Germany 1 2 - 3 8 7 German Demo. Rep. 1 - 1 2 9 8 Unified Team 1 - - 1 10 9 Czechoslovakia - 1 - 1 11 11 Switzerland - - 1 1 Totals (15 events) 15 15 15 45 Most Gold Medals 3 Larisa Lazutina (EUN/RUS) 3 Nina Gavrylyuk (URS) 3 Yelena Välbe (EUN/RUS) Most Medals 4 Galinka Kulakova (URS/211) 4 Gabriella Paruzzi (ITA/004) 3 14 athletes tied with 3. -

Donne E Coca?
SPORT T^^Z Ferrari FI Roma-Napoli Nuova clamorosa puntata nel caso Camevale-Peruzzi Nessuna sorpresa Dtie storie Trigona perquisita dalla polizia, avviso di garanzia inviato Prost iscritto dal 6 gennaio di droga al dottor Alicicco per «prescrizione di sostanze stimolanti » La Fisti ha reso noto ieri la lista dei 34 piloti iscritti al prossi La magistratura romana indaga, il club tace su tutta la linea mo mondiale. La Ferrari aveva registrato Jean Alesi e Alain Prost sin dal 6 gennaio nonostante il limite scadesse il 13 febbraio. Questo l'elenco: 1,2 Senna e Berger (McLaren): 3, 4 Naka)«ma e Modena (Tyrrell): 5, 6 Mansell. Patrese (Wil liams); 7, 8 Brundle, Blundcll (Brabham); 9. 10 Alboreto, Caffi (Porsche); 11, 12 Hakkincn, Donnelly (Lotus); 14 Grouillard (Fondmetal); 15,16Gugelmin,Capelli (Leyton); 17, 18 Tarquini, Johansson (Ags); 19. 20 Piquet, Moreno (Benetton): 21, 22 Pirro, Lento (Dallara): 23. 24 Martini, Morbidclli (Minardi); 25, 26 Boutsen, Comas (Ligier); 27, 28 Prost. Alesi (Ferrari): 29,30 Bernard, Suzuki (Lola); 31 Chaves (Coloni); 32, 33 Gachot, De Cesaris (Jordan); 34, Squadra narcotici 35 Larinl. Van De Poele (Lambo). Dopo Cane Al torneo di Filadelfia (pre La giustizia ordinaria ha compiuto i primi passi uffi- sua volta dal magistrato bare er,i intanto travestito nuova tratta del materiale abitual mi per un milione di dolla ì ' ciah relativi al «caso doping» di Peruzzi e Carnevale. se Antonio Capristo il 30 gen mente da fortino assediato: la mente adoperato dai nostri in Coppa Davis ri), il tennista Cristiano Ca naio scorso, «per accertare l'e •cittadella» ha fatto quadralo, massaggiatori e oggi (ieri, StìchinUsa ratti è stato eliminato al 2* -, Mercoledì pomeriggio sono stati ispezionati gli uffici ventuale violazione da parte come nei giorni caldi della ndr) pomerìggio ci è stata ri turno da Michael Stich (6-2.