An Introductory Guide to Advanced Hockey Stats
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Head Coach, Tampa Bay Lightning
Table of Contents ADMINISTRATION Team History 270 - 271 All-Time Individual Record 272 - 274 Company Directory 4 - 5 All-Time Team Records 274 - 279 Executives 6 - 11 Scouting Staff 11 - 12 Coaching Staff 13 - 16 PLAYOFF HISTORY & RECORDS Hockey Operations 17 - 20 All-Time Playoff Scoring 282 Broadcast 21 - 22 Playoff Firsts 283 All-Time Playoff Results 284 - 285 2013-14 PLAYER ROSTER Team Playoff Records 286 - 287 Individual Playoff Records 288 - 289 2013-14 Player Roster 23 - 98 Minor League Affiliates 99 - 100 MISCELLANEOUS NHL OPPONENTS In the Community 292 NHL Executives 293 NHL Opponents 109 - 160 NHL Officials and Referees 294 Terms Glossary 295 2013-14 SEASON IN REVIEW Medical Glossary 296 - 298 Broadcast Schedule 299 Final Standings, Individual Leaders, Award Winners 170 - 172 Media Regulations and Policies 300 - 301 Team Statistics, Game-by-Game Results 174 - 175 Frequently Asked Questions 302 - 303 Home and Away Results 190 - 191 Season Summary, Special Teams, Overtime/Shootout 176 - 178 Highs and Lows, Injuries 179 Win / Loss Record 180 HISTORY & RECORDS Season Records 182 - 183 Special Teams 184 Season Leaders 185 All-Time Records 186 - 187 Last Trade With 188 Records vs. Opponents 189 Overtime/Shootout Register 190 - 191 Overtime History 192 Year by Year Streaks 193 All-Time Hat Tricks 194 All-Time Attendance 195 All-Time Shootouts & Penalty Shots 196-197 Best and Worst Record 198 Season Openers and Closers 199 - 201 Year by Year Individual Statistics and Game Results 202 - 243 All-Time Lightning Preseason Results 244 All-Time -

20 0124 Bridgeport Bios
BRIDGEPORT SOUND TIGERS: COACHES BIOS BRENT THOMPSON - HEAD COACH Brent Thompson is in his seventh season as head coach of the Bridgeport Sound Tigers, which also marks his ninth year in the New York Islanders organization. Thompson was originally hired to coach the Sound Tigers on June 28, 2011 and led the team to a division title in 2011-12 before being named assistant South Division coach of the Islanders for two seasons (2012-14). On May 2, 2014, the Islanders announced Thompson would return to his role as head coach of the Sound Tigers. He is 246-203-50 in 499 career regular-season games as Bridgeport's head coach. Thompson became the Sound Tigers' all-time winningest head coach on Jan. 28, 2017, passing Jack Capuano with his 134th career victory. Prior to his time in Bridgeport, Thompson served as head coach of the Alaska Aces (ECHL) for two years (2009-11), winning the Kelly Cup Championship in 2011. During his two seasons as head coach in Alaska, Thompson amassed a record of 83- 50-11 and won the John Brophy Award as ECHL Coach of the Year in 2011 after leading the team to a record of 47-22-3. Thompson also served as a player/coach with the CHL’s Colorado Eagles in 2003-04 and was an assistant with the AHL’s Peoria Rivermen from 2005-09. Before joining the coaching ranks, Thompson enjoyed a 14-year professional playing career from 1991-2005, which included 121 NHL games and more than 900 professional contests. The Calgary, AB native was originally drafted by the Los Angeles Kings in the second round (39th overall) of the 1989 NHL Entry Draft. -
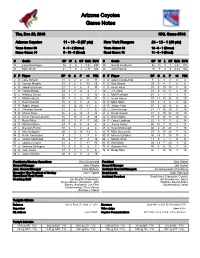
Arizona Coyotes Game Notes
Arizona Coyotes Game Notes Thu, Dec 29, 2016 NHL Game #543 Arizona Coyotes 11 - 19 - 5 (27 pts) New York Rangers 24 - 12 - 1 (49 pts) Team Game: 36 6 - 9 - 2 (Home) Team Game: 38 13 - 6 - 1 (Home) Home Game: 18 5 - 10 - 3 (Road) Road Game: 18 11 - 6 - 0 (Road) # Goalie GP W L OT GAA SV% # Goalie GP W L OT GAA SV% 35 Louis Domingue 16 4 9 1 3.37 .898 30 Henrik Lundqvist 25 15 8 1 2.47 .915 41 Mike Smith 21 7 9 4 2.71 .924 32 Antti Raanta 16 9 4 0 2.23 .925 # P Player GP G A P +/- PIM # P Player GP G A P +/- PIM 2 D Luke Schenn 31 0 2 2 0 37 4 D Adam Clendening 9 0 3 3 4 4 5 D Connor Murphy 31 0 6 6 -12 25 5 D Dan Girardi 33 3 4 7 6 6 6 D Jakob Chychrun 27 1 5 6 -3 33 8 D Kevin Klein 33 0 10 10 5 13 8 R Tobias Rieder 33 7 7 14 -4 2 10 L J.T. Miller 37 9 13 22 5 10 10 L Anthony Duclair 32 2 4 6 -2 10 12 L Matt Puempel 24 2 1 3 -7 9 11 C Martin Hanzal 30 7 5 12 -15 31 13 C Kevin Hayes 37 11 13 24 12 10 13 C Peter Holland 15 0 4 4 -4 6 18 D Marc Staal 37 3 3 6 9 22 17 R Radim Vrbata 35 9 14 23 -11 8 19 R Jesper Fast 37 3 10 13 6 16 18 C Christian Dvorak 31 3 8 11 3 6 20 L Chris Kreider 31 11 14 25 5 19 19 R Shane Doan 35 4 6 10 -4 28 21 C Derek Stepan 37 9 19 28 12 10 23 D Oliver Ekman-Larsson 35 7 10 17 -9 24 22 D Nick Holden 37 6 12 18 14 10 25 C Ryan White 30 2 3 5 -7 60 24 C Oscar Lindberg 22 0 3 3 -2 14 26 D Michael Stone 24 0 6 6 -9 4 26 L Jimmy Vesey 36 10 7 17 1 11 29 L Brendan Perlini 10 2 1 3 -2 4 27 D Ryan McDonagh 36 2 21 23 8 15 33 D Alex Goligoski 35 1 12 13 -13 8 36 R Mats Zuccarello 37 8 18 26 7 12 44 D Kevin Connauton 9 0 1 1 -1 6 40 R Michael Grabner 36 14 5 19 15 8 48 L Jordan Martinook 35 6 7 13 -3 14 46 L Marek Hrivik 11 0 1 1 0 0 67 L Lawson Crouse 31 2 1 3 -11 30 61 R Rick Nash 30 13 7 20 -1 12 77 D Anthony DeAngelo 18 3 6 9 -2 4 73 R Brandon Pirri 35 6 6 12 1 15 86 R Josh Jooris 17 1 2 3 2 6 76 D Brady Skjei 36 1 15 16 2 16 88 L Jamie McGinn 30 6 3 9 -4 19 President of Hockey Operations Gary Drummond President Glen Sather General Manager John Chayka General Manager Jeff Gorton Asst. -

Turnbull Hockey Pool For
Turnbull Hockey Pool for Each year, Turnbull students participate in several fundraising initiatives, which we promote as a way to develop a sense of community, leadership and social responsibility within the students. Last year's grade 7 and 8 students put forth a great deal of effort campaigning friends and family members to join Turnbull's annual NHL hockey pool, raising a total of $1750 for a charity of their choice (the United Way). This year's group has decided to run the hockey pool for the benefit of Help Lesotho, an international development organization working in the AIDS-ravaged country of Lesotho in southern Africa. From www.helplesotho.org "Help Lesotho’s programs foster hope and motivation in those who are most in need: orphans, vulnerable children, at-risk youth and grandmothers. Our work targets root causes and community priorities, including literacy, youth leadership training, school twinning, child sponsorship and gender programming. Help Lesotho is an effective, sustainable organization that is working at the grass-roots level to support the next generation of leaders in Lesotho." Your participation in this year's NHL hockey pool is very much appreciated. We believe it will provide students and their friends and families an opportunity to have fun together while giving back to their community by raising awareness and funds for a great cause. Prizes: > Grand Prize awarded to contestant whose team accumulates the most points over the regular NHL season = 10" Samsung Galaxy Tablet > Monthly Prizes awarded to the contestants whose teams accumulate the most points over each designated period (see website) = Two Movie Passes How it Works: > Everyone in the community is welcome to join in on the fun. -

Anaheim Ducks Game Notes
Anaheim Ducks Game Notes Fri, Nov 4, 2016 NHL Game #160 Anaheim Ducks 4 - 5 - 2 (10 pts) Arizona Coyotes 4 - 6 - 0 (8 pts) Team Game: 12 2 - 2 - 0 (Home) Team Game: 11 3 - 1 - 0 (Home) Home Game: 5 2 - 3 - 2 (Road) Road Game: 7 1 - 5 - 0 (Road) # Goalie GP W L OT GAA SV% # Goalie GP W L OT GAA SV% 1 Jonathan Bernier 3 0 1 0 2.73 .929 35 Louis Domingue 8 3 5 0 3.61 .896 36 John Gibson 10 4 4 2 2.58 .911 40 Justin Peters 2 0 1 0 3.23 .914 # P Player GP G A P +/- PIM # P Player GP G A P +/- PIM 2 D Kevin Bieksa 11 0 0 0 -2 15 2 D Luke Schenn 10 0 1 1 0 0 3 D Clayton Stoner 8 0 2 2 -1 26 5 D Connor Murphy 10 0 3 3 1 10 4 D Cam Fowler 11 4 4 8 0 2 6 D Jakob Chychrun 9 1 2 3 2 21 5 D Korbinian Holzer 3 0 1 1 1 2 8 R Tobias Rieder 9 2 3 5 1 0 7 L Andrew Cogliano 11 4 0 4 2 4 10 L Anthony Duclair 10 1 1 2 0 0 10 R Corey Perry 11 4 4 8 -3 14 11 C Martin Hanzal 9 2 2 4 -2 2 15 C Ryan Getzlaf 9 1 8 9 -1 8 15 R Brad Richardson 10 4 4 8 1 6 16 C Ryan Garbutt 11 1 1 2 -1 4 16 L Max Domi 10 0 7 7 -1 6 17 C Ryan Kesler 11 2 5 7 3 13 17 R Radim Vrbata 10 4 2 6 2 4 21 C Chris Wagner 11 2 0 2 -2 4 18 C Christian Dvorak 8 1 3 4 2 2 33 R Jakob Silfverberg 11 2 1 3 2 2 19 R Shane Doan 10 1 2 3 -4 2 37 L Nick Ritchie 10 2 1 3 1 8 20 C Dylan Strome 5 0 1 1 -3 0 40 R Jared Boll 10 0 1 1 -3 16 23 D Oliver Ekman-Larsson 10 5 2 7 0 6 42 D Josh Manson 11 0 1 1 1 13 25 C Ryan White 9 1 2 3 -1 15 45 D Sami Vatanen 11 1 6 7 -1 2 26 D Michael Stone 4 0 3 3 -1 0 48 C Michael Sgarbossa 5 0 1 1 -2 0 33 D Alex Goligoski 10 0 6 6 -7 2 50 C Antoine Vermette 11 1 4 5 0 6 44 D Kevin Connauton 4 0 1 1 0 6 67 C Rickard Rakell 2 1 2 3 0 0 48 L Jordan Martinook 10 3 2 5 0 6 74 L Joseph Cramarossa 6 1 0 1 -1 15 67 L Lawson Crouse 7 1 0 1 -3 2 86 R Ondrej Kase 1 0 0 0 -1 0 76 C Laurent Dauphin 8 1 1 2 -1 4 88 L Jamie McGinn 5 2 1 3 0 6 Executive VP & General Manager Bob Murray President of Hockey Operations Gary Drummond Senior VP of Hockey Operations David McNab General Manager John Chayka Head Coach Randy Carlyle Asst. -

Expect the Expected: Approximating the Caliber of Possession Using Shot Quality
Expect the Expected: Approximating the Caliber of Possession Using Shot Quality James McCorriston Connor Reed [email protected] [email protected] Abstract The NHL has experienced rapid growth in analytical metrics and advanced statistics in recent years. While popular statistics like Fenwick and Corsi act as good approximations for puck possession, they are limited in what they tell about scoring opportunities as they do not consider shot quality. In this study, we consider shot distance as an approximation of shot quality, and we combine Fenwick and NHL play-by-play shot distance data to develop a series of new statistics: Expected Goals (xGoals), Expected Differential (xDiff), and Goals-Above-Expected (GAE) for skaters, as well as Expected Save Percentage (xSv%) and Adjusted Save Percentage for goaltenders. As a basis for these new metrics, we first show that shot distance serves as a good approximation for shot quality, and that we can reverse-engineer scoring probabilities for each shot taken by a player. The concept of approximating shot quality is extended to analyze the performance of players, teams, and goaltenders. Using NHL play-by-play data from the 2007-08 season to the 2014-15 season, we show that xGoals are the best indicator of how many goals a player should be scoring, and we show that it stays more consistent for an individual from year-to-year than other comparable statistics. Finally, we show that on a single-game resolution, xGoals are the best indicator for which team should have won a particular game. The novel set of metrics introduced in this paper offer a more reliable and indicative tool for assessing the ability of skaters, goaltenders, and teams and provides a new basis for analyzing the game of professional hockey. -

Boston Bruins Playoff Game Notes
Boston Bruins Playoff Game Notes Wed, Aug 26, 2020 Round 2 Game 3 Boston Bruins 5 - 5 - 0 Tampa Bay Lightning 7 - 3 - 0 Team Game: 11 2 - 3 - 0 (Home) Team Game: 11 4 - 3 - 0 (Home) Home Game: 6 3 - 2 - 0 (Road) Road Game: 4 3 - 0 - 0 (Road) # Goalie GP W L OT GAA SV% # Goalie GP W L OT GAA SV% 35 Maxime Lagace - - - - - - 29 Scott Wedgewood - - - - - - 41 Jaroslav Halak 6 4 2 0 2.50 .916 35 Curtis McElhinney - - - - - - 80 Dan Vladar - - - - - - 88 Andrei Vasilevskiy 10 7 3 0 2.15 .921 # P Player GP G A P +/- PIM # P Player GP G A P +/- PIM 10 L Anders Bjork 9 0 1 1 -4 6 2 D Luke Schenn 1 0 0 0 1 0 13 C Charlie Coyle 10 3 1 4 -3 2 7 R Mathieu Joseph - - - - - - 14 R Chris Wagner 10 2 1 3 -2 4 9 C Tyler Johnson 10 3 2 5 -3 4 19 R Zach Senyshyn - - - - - - 13 C Cedric Paquette 10 0 1 1 -1 4 20 C Joakim Nordstrom 10 0 2 2 -3 2 14 L Pat Maroon 10 0 2 2 2 4 21 L Nick Ritchie 6 1 0 1 -1 2 17 L Alex Killorn 10 2 2 4 -4 12 25 D Brandon Carlo 10 0 1 1 2 4 18 L Ondrej Palat 10 1 3 4 3 2 26 C Par Lindholm 3 0 0 0 0 2 19 C Barclay Goodrow 10 1 2 3 5 2 27 D John Moore - - - - - - 20 C Blake Coleman 10 3 2 5 4 17 28 R Ondrej Kase 8 0 4 4 0 2 21 C Brayden Point 10 5 7 12 2 8 33 D Zdeno Chara 10 0 1 1 -5 4 22 D Kevin Shattenkirk 10 1 3 4 2 2 37 C Patrice Bergeron 10 2 5 7 2 2 23 C Carter Verhaeghe 3 0 1 1 1 0 46 C David Krejci 10 3 7 10 -1 2 24 D Zach Bogosian 9 0 3 3 3 8 47 D Torey Krug 10 0 5 5 -1 7 27 D Ryan McDonagh 9 0 3 3 -1 0 48 D Matt Grzelcyk 9 0 0 0 -1 2 37 C Yanni Gourde 10 2 3 5 5 9 52 C Sean Kuraly 10 1 2 3 -4 4 44 D Jan Rutta 1 0 0 0 0 -

Product Recall Notice for 'Shot Quality'
Product Recall Notice for ‘Shot Quality’ Data quality problems with the measurement of the quality of a hockey team’s shots taken and allowed Copyright Alan Ryder, 2007 Hockey Analytics www.HockeyAnalytics.com Product Recall Notice for Shot Quality 2 Introduction In 2004 I outlined a method for the measurement of “Shot Quality” 1. This paper presents a cautionary note on the calculation of shot quality. Several individuals have enhanced my approach, or expressed the outcome differently, but the fundamental method to determine shot quality remains unchanged: 1. For each shot taken/allowed, collect the data concerning circumstances (e.g. shot distance, shot type, situation, rebound, etc) and outcome (goal, save). 2. Build a model of goal probabilities that relies on the circumstance. Current best practice is that of Ken Krzywicki involving binary logistic regression techniques 2. I now use a slight variation on that theme that ensures that the model reproduces the actual number of goals for each shot type and situation. 3. For each shot apply the model to the shot data to determine its goal probability. 4. Expected Goals: EG = the sum of the goal probabilities for each shot for a given team. 5. Neutralize the variation in shots on goal by calculating Normalized Expected Goals: NEG = EG x Shots< / Shots (Shots< = League Average Shots For/Against). 6. Shot Quality: SQ = NEG / GA< (GA< = League Average Goals For/Against). I have called the result SQA for shots against and SQF for shots for . I normally talk about a team’s shot overall quality but one can determine shot quality any subset of its total shots (e.g. -

Marketing Package
MARKETING PACKAGE 2021-2022 SEASON MARKETING PACKAGE TABLE OF CONTENTS ABOUT THE SAINTS .................................................... 1-2 WHY CHOOSE THE SAINTS? ...........................................3 YOUR OPPORTUNITY ......................................................4 COMMUNITY INVOLVEMENT .........................................5 PARTNERSHIP OPPORTUNITIES ................................. 6-9 CONTACT ......................................................................10 SPRUCE GROVE SAINTS ABOUT THE SAINTS The Spruce Grove Saints have been proud members of the Alberta Junior Hockey League since 2005 and are one of Canada’s most storied Junior “A” franchises. Over 50 Saints, including the likes of Mark Messier, Rob Brown, Brian Benning, Stu Barnes, Mike Comrie, Steve Reinprecht and Fernando Pisani have played for the Saints on their way to the National Hockey League. The aforementioned Saints legends paved the way for the likes of Ben Scrivens, Matt Benning, Carson Soucey, Kodi Curran and Ian Mitchell to reach their hockey dreams of playing in the NHL. With the growing list of NHL players, they are joined by an unparalleled list of Saints alumni that have advanced to all levels of professional hockey in North America and Europe as well as the many Canadian College, University, and NCAA committed players both current and past. The alumni are a testament to the winning culture and reputation of this renowned franchise. The Saints are the only remaining franchise to survive from the original inception of the Alberta Junior Hockey League (AJHL) in 1963. In 1972 the Edmonton Movers and Edmonton Maple Leafs combined to become the Edmonton Mets who, in turn became the Spruce Grove Mets in 1974. Under the direction of Doug Messier, the 1974-75 Spruce Grove Mets won the Centennial Cup Championship, the symbol of supremacy for Junior “A” hockey in Canada. -

2021 Nhl Awards Presented by Bridgestone Information Guide
2021 NHL AWARDS PRESENTED BY BRIDGESTONE INFORMATION GUIDE TABLE OF CONTENTS 2021 NHL Award Winners and Finalists ................................................................................................................................. 3 Regular-Season Awards Art Ross Trophy ......................................................................................................................................................... 4 Bill Masterton Memorial Trophy ................................................................................................................................. 6 Calder Memorial Trophy ............................................................................................................................................. 8 Frank J. Selke Trophy .............................................................................................................................................. 14 Hart Memorial Trophy .............................................................................................................................................. 18 Jack Adams Award .................................................................................................................................................. 24 James Norris Memorial Trophy ................................................................................................................................ 28 Jim Gregory General Manager of the Year Award ................................................................................................. -

Nhl Morning Skate – April 29, 2021 Three
NHL MORNING SKATE – APRIL 29, 2021 THREE HARD LAPS * Auston Matthews, who leads the Maurice “Rocket” Richard Trophy race with 35 goals this season, scored the game winner as the Maple Leafs clinched a berth in the 2021 Stanley Cup Playoffs. * Connor McDavid recorded his fourth straight three-point game and is now on pace for 100 points in a shortened NHL season. * The Golden Knights moved into first place in the NHL standings as they earned their 10th straight win. MAPLE LEAFS CLINCH FIRST SCOTIA NORTH DIVISION PLAYOFF SPOT Auston Matthews scored his NHL-leading 35th goal of the season and 10th game winner to help the Maple Leafs clinch the first playoff spot in the Scotia North Division. This marks Toronto’s fifth consecutive postseason appearance and 70th in franchise history. * Matthews scored his 17th career goal against the Canadiens (17-11—28 in 21 GP), with five of those tallies coming across an active seven-game point streak this season against Montreal (5-6—11 in 7 GP). Matthews’ 1.33 points-per-game rate versus the Canadiens is tied with Babe Dye for the highest among all Maple Leafs to face the club at least 20 times, while his 0.81 goals-per-game average is fourth highest in NHL history against Montreal (min. 20 GP). * Toronto and Montreal have been trending toward a playoff meeting in 2021, holding the No. 1 and No. 4 seeds, respectively, since Feb. 19. It has been more than 42 years since the Maple Leafs and Canadiens met in the Stanley Cup Playoffs, with their last contest in the 1979 Quarterfinals taking place April 22, 1979 – about two months before Joe Thornton was born (July 2, 1979). -

PLAYOFF HISTORY and RECORDS RANGERS PLAYOFF Results YEAR-BY-YEAR RANGERS PLAYOFF Results YEAR-BY-YEAR
PLAYOFF HISTORY AnD RECORDS RANGERS PLAYOFF RESuLTS YEAR-BY-YEAR RANGERS PLAYOFF RESuLTS YEAR-BY-YEAR SERIES RECORDS VERSUS OTHER CLUBS Year Series Opponent W-L-T GF/GA Year Series Opponent W-L-T GF/GA YEAR SERIES WINNER W L T GF GA YEAR SERIES WINNER W L T GF GA 1926-27 SF Boston 0-1-1 1/3 1974-75 PRE Islanders 1-2 13/10 1927-28 QF Pittsburgh 1-1-0 6/4 1977-78 PRE Buffalo 1-2 6/11 VS. ATLANTA THRASHERS VS. NEW YORK ISLANDERS 2007 Conf. Qtrfinals RANGERS 4 0 0 17 6 1975 Preliminaries Islanders 1 2 0 13 10 SF Boston 1-0-1 5/2 1978-79 PRE Los Angeles 2-0 9/2 Series Record: 1-0 Total 4 0 0 17 6 1979 Semifinals RANGERS 4 2 0 18 13 1981 Semifinals Islanders 0 4 0 8 22 F Maroons 3-2-0 5/6 QF Philadelphia 4-1 28/8 VS. Boston BRUINS 1982 Division Finals Islanders 2 4 0 20 27 1928-29 QF Americans 1-0-1 1/0 SF Islanders 4-2 18/13 1927 Semifinals Bruins 0 1 1 1 3 1983 Division Finals Islanders 2 4 0 15 28 SF Toronto 2-0-0 3/1 F Montreal 1-4 11/19 1928 Semifinals RANGERS 1 0 1 5 2 1984 Div. Semifinals Islanders 2 3 0 14 13 1929 Finals Bruins 0 2 0 1 4 1990 Div. Semifinals RANGERS 4 1 0 22 13 F Boston 0-2-0 1/4 1979-80 PRE Atlanta 3-1 14/8 1939 Semifinals Bruins 3 4 0 12 14 1994 Conf.