Network Working Group T. Berners-Lee Request for Comments: 3986 W3C/MIT STD: 66 R
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Framework for Auto-ID Enabled Business
A Framework for Auto-ID Enabled Business by Timothy Porter Milne M.S. Mechanical Engineering, 1995 Brigham Young University B.S. Mechanical Engineering, 1992 Brigham Young University Submitted to the Department of Mechanical Engineering in partial fulfillment of the requirements for the degree of MASTER OF SCIENCE at the MASSACHUSETTS INSTITUTE OF TECHNOLOGY MASSACHUSETTS INSTITUTEINSTITUTE August 8, 2003 OF TECHNOL OGY OCT 0 6 ©2003 Massachusetts Institute of Technology All Rights Reserved. LIBRAR IES Signature of Author:................................ ....... .. ............. Departm of Mechanic Engineering (V August 8, 2003 C ertified by:............................................... Sanjay E. Sarma Associat e Professor of Mechanical Engineering Thesis Supervisor A ccepted by:......................................... Ain A. Sonin Chairman, Department Committee on Graduate Students BARKER A Framework for Auto-ID Enabled Business by Timothy Porter Milne Submitted to the Department of Mechanical Engineering August 8, 2003 In partial fulfillment of the requirements for the degree of Master of Science ABSTRACT Modern commerce is as much about trading information as it is about exchanging goods and money. With an Auto-ID enabled future, the expeditious exchange of information will be even more critical. The fundamental problem with e-commerce today is the soft connection between goods and their related information, which frequently results in breakdowns between the physical and information worlds. The Auto-ID Center at MIT has proposed a system using Radio Frequency Identification (RFID) tags on objects, coupled with a distributed information system using the Internet, that will allow the tracking of physical objects and the automatic association of relevant data about those objects. This thesis outlines a framework for a new method of using Auto-ID to connect the physical world to the information world using an example from commerce: Shipping and Receiving Verification. -

FAA-STD-075, Creating Service Identifiers
FAA-STD-075 June 29, 2021 SUPERSEDING FAA-STD-063 May 1, 2009 U.S. Department of Transportation Federal Aviation Administration U.S. Department of Transportation Federal Aviation Administration Standard Practice CREATING SERVICE IDENTIFIERS FAA-STD-075 June 29, 2021 FOREWORD This standard is approved for use by all Departments of the Federal Aviation Administration (FAA). This standard sets forth requirements for creating globally-unique identifiers for FAA service-oriented architecture (SOA)-based services. This standard has been prepared in accordance with FAA-STD-068, Department of Transportation Federal Aviation Administration, Preparation of Standards [STD068]. Comments, suggestions, or questions on this document shall be addressed to: Federal Aviation Administration System Wide Information Management (SWIM) Program Office, AJM-316 800 Independence Avenue, SW Washington, DC 20591 https://www.faa.gov/air_traffic/technology/swim/contacts/ i FAA-STD-075 June 29, 2021 Table of Contents 1 SCOPE ..................................................................................................................................................1 1.1 INTRODUCTION ...........................................................................................................................................1 1.2 INTENDED AUDIENCE ....................................................................................................................................1 1.3 BASIC CONCEPTS .........................................................................................................................................2 -

Globally Unique Flight Identifier (GUFI) Format and Content
Globally Unique Flight Identifier (GUFI) Format and Content A collaborative effort to establish the Flight Information Exchange Model (FIXM) has been underway for several years. A key component of the flight model is a Globally Unique Flight Identifier (GUFI) that is included on every Air Traffic Management (ATM) flight data transaction to unambiguously identify the flight to which the data applies. The June 23, purpose of the GUFI is to eliminate problems that have occurred in the past when 2014 systems try to accurately correlate data that is received from many other systems. This paper discusses the format and content of the GUFI. Version: 2.1 GUFI Format Version 2.1 Table of Contents Document History ........................................................................................................................................ 3 1 Introduction .......................................................................................................................................... 4 2 Background/Discussion ......................................................................................................................... 4 2.1 Purpose ..................................................................................................................................... 4 2.2 General Concept ....................................................................................................................... 4 2.3 General Approaches ................................................................................................................. -

Introduction to the Course
Introduction to the course 1 Introduzione alla programmazione web – Marco Ronchetti 2021 – Università di Trento Prerequirements § OOP + Java: essential! (Must have passed Linguaggi di Programmazione!) § Network fundamentals § Database § No need to already know HTML/HTTP etc. 2 Introduzione alla programmazione web – Marco Ronchetti 2021 – Università di Trento Topics § HTTP + HTML + CSS § Server side programming: PHP – Java, parameter passing, state problem… § Data access (DB) § Javascript – EcmaScript – Typescript § Patterns: MV* + … § AJAX/XML/JSON § JS frameworks/libraries: JQuery, (brief remarks on React, Angular…) § General considerations (accessibility, security…) 3 Introduzione alla programmazione web – Marco Ronchetti 2021 – Università di Trento We’ll use Piazza As soon as the dept Buys the licence For now we go with moodle (sigh) 4 Introduzione alla programmazione web – Marco Ronchetti 2021 – Università di Trento Exam § Similar to “Linguaggi di Programmazione – mod.1” § 1st part: output prediction of 8 brief code fragments + 8 true/fase questions (40 minutes) § 2nd part: small project development (4 hours) If possiBle, in presence. Else, Responsus+Moodle+VDI 5 Introduzione alla programmazione web – Marco Ronchetti 2021 – Università di Trento 6 Introduzione alla programmazione web – Marco Ronchetti 2021 – Università di Trento What is the difference between the Web and the Internet? 7 Introduzione alla programmazione web – Marco Ronchetti 2021 – Università di Trento What is the difference between the Web and the Internet? § "The -
UK Research Data Registry Mapping Schemes
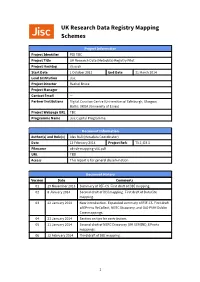
UK Research Data Registry Mapping Schemes Project Information Project Identifier PID TBC Project Title UK Research Data (Metadata) Registry Pilot Project Hashtag #jiscrdr Start Date 1 October 2013 End Date 31 March 2014 Lead Institution Jisc Project Director Rachel Bruce Project Manager — Contact Email — Partner Institutions Digital Curation Centre (Universities of Edinburgh, Glasgow, Bath); UKDA (University of Essex) Project Webpage URL TBC Programme Name Jisc Capital Programme Document Information Author(s) and Role(s) Alex Ball (Metadata Coordinator) Date 12 February 2014 Project Refs T3.1; D3.1 Filename uk-rdr-mapping-v06.pdf URL TBD Access This report is for general dissemination Document History Version Date Comments 01 29 November 2013 Summary of RIF-CS. First draft of DDI mapping. 02 8 January 2014 Second draft of DDI mapping. First draft of DataCite mapping. 03 22 January 2014 New introduction. Expanded summary of RIF-CS. First draft of EPrints ReCollect, NERC Discovery, and OAI-PMH Dublin Core mappings. 04 23 January 2014 Section on tips for contributors. 05 31 January 2014 Second draft of NERC Discovery (UK GEMINI), EPrints mappings. 06 12 February 2014 Third draft of DDI mapping. 1 Contents 1 Introduction 3 1.1 Typographical conventions . 3 2 RIF-CS 4 2.1 Elements . 4 2.2 Controlled vocabularies . 8 3 Internally managed RIF-CS elements 20 4 Mapping from DDI to RIF-CS 21 4.1 Related Objects . 22 5 Mapping from UK GEMINI 2 to RIF-CS 24 5.1 Related Objects . 26 6 Mapping from DataCite to RIF-CS 27 6.1 Related Objects . -

Technical Standards Catalogue VERSION 6.2
e-Government Technical Standards Catalogue VERSION 6.2 FINAL September 2005 Technical Standards Catalogue / version 6.2 final / September 2005 1 CONTENTS 1 INTRODUCTION ...........................................................................................................................3 2 CHANGES FROM PREVIOUS VERSION..................................................................................4 3 ISSUES UNDER CONSIDERATION............................................................................................5 4 INTERCONNECTION ...................................................................................................................7 TABLE 1 SPECIFICATIONS FOR INTERCONNECTIVITY.......................................................................7 TABLE 2 SPECIFICATIONS FOR WEB SERVICES ..............................................................................10 5 DATA INTEGRATION ................................................................................................................16 TABLE 3 SPECIFICATIONS FOR DATA INTEGRATION ...........................................................................16 6 CONTENT MANAGEMENT METADATA ...............................................................................19 TABLE 4 SPECIFICATIONS FOR CONTENT MANAGEMENT METADATA .................................................19 TABLE 5 SPECIFICATIONS FOR IDENTIFIERS .......................................................................................20 7 E-SERVICES ACCESS.................................................................................................................23 -

ECE 435 – Network Engineering Lecture 3
ECE 435 { Network Engineering Lecture 3 Vince Weaver http://web.eece.maine.edu/~vweaver [email protected] 4 February 2021 Announcements • Homework #1 was posted/due Friday now (extension) • Last class cancelled due to snow. I guess they're going to be cancelling remote/hyrbid classes. • Sorry if that last class was a bit overwhelming with the C • Yes, HW#1 and #2 lots of coding. Know non-computer engineers not like this. Amount of coding drops off a lot after HW#2. 1 HW #1 notes • strace can be useful when tracking down issues. • Finding the \struct sockaddr" can be difficult. even if you find in under /usr/include it's tricky as it's a struct that is multiplexed via casting (to handle all possible socket types). Horrible thing about C. • How read() and write() work. ◦ Some people are having issues where they are writing 256 bytes (write will write as many bytes as you said, even if they are trailing zeros), but only reading 255. 2 This means the next read is going to get the last 0 rather than the following write. ◦ When reading, read(fd,buffer,size); What happens if you read 10 bytes but other side only has 4? Only read 4 (result). ◦ What happens read 10 bytes and other size has 12? You read 10 (result) but to get the rest you need to read again, otherwise it's there the next time you read. You can do a while loop. ◦ Also note that when you write, you should specify how many bytes you are writing or your whole buffer gets 3 sent even if empty. -

Hypertext Transfer Protocol
Hypertext Transfer Protocol Ing. Pierluigi Gallo HTTP Hypertext Transfer Protocol used in the WWW protocol used for communication between web browsers and web servers client-server paradigm TCP port 80 RFC 1945 Ing. Pierluigi Gallo Introduction to HTTP 80% of Internet flows are HTTP connections Early protocol is HTTP 0.9 read only Today we use HTTP 1.0 read, input, delete, ... New version: HTTP 1.1 performance optimizations Ing. Pierluigi Gallo HTTP Overview Client (browser) sends HTTP request to server Request specifies affected URL Request specifies desired operation Server performs operation on URL Server sends response Request and reply headers are in pure text Ing. Pierluigi Gallo Static Content and HTML Most static web content is written in HTML HTML allows Text formatting commands Embedded objects Links to other objects Server need not understand or interpret HTML Ing. Pierluigi Gallo URI,URN,URL RFC 3305 Uniform Resource Identifier Identifies a resource Uniform Resource Name The name of the resource with in a namespace like a person’s name Uniform Resource Locator How to find the resource, a URI that says how to find the resource like a person street address URI concept is more general than its use in web pages (XML, …) Ing. Pierluigi Gallo HTTP - URLs URL Uniform Resource Locator protocol (http, ftp, news) host name (name.domain name) port (80, 8080, …) directory path to the resource resource name absolute relative http://www.tti.unipa.it/~pg/pg/Teaching.html http://xxx.myplace.com:80/cgi-bin/t.exe Ing. Pierluigi Gallo URI examples http://example.org/absolute/URI/with/absolute/ path/to/resource.txt ftp://example.org/resource.txt urn:issn:1535-3613 /relative/URI/with/absolute/path/to/resource.txt relative/path/to/resource.txt ../../../resource.txt ./resource.txt#frag01 Ing. -

Network Working Group T. Berners-Lee Request for Comments: 1630 CERN Category: Informational June 1994
Network Working Group T. Berners-Lee Request for Comments: 1630 CERN Category: Informational June 1994 Universal Resource Identifiers in WWW A Unifying Syntax for the Expression of Names and Addresses of Objects on the Network as used in the World-Wide Web Status of this Memo This memo provides information for the Internet community. This memo does not specify an Internet standard of any kind. Distribution of this memo is unlimited. IESG Note: Note that the work contained in this memo does not describe an Internet standard. An Internet standard for general Resource Identifiers is under development within the IETF. Introduction This document defines the syntax used by the World-Wide Web initiative to encode the names and addresses of objects on the Internet. The web is considered to include objects accessed using an extendable number of protocols, existing, invented for the web itself, or to be invented in the future. Access instructions for an individual object under a given protocol are encoded into forms of address string. Other protocols allow the use of object names of various forms. In order to abstract the idea of a generic object, the web needs the concepts of the universal set of objects, and of the universal set of names or addresses of objects. A Universal Resource Identifier (URI) is a member of this universal set of names in registered name spaces and addresses referring to registered protocols or name spaces. A Uniform Resource Locator (URL), defined elsewhere, is a form of URI which expresses an address which maps onto an access algorithm using network protocols. -

An Evaluation of the Webdav Extensions to the HTTP Protocol
2000:138 MASTER'S THESIS An evaluation of the WebDAV extensions to the HTTP protocol Björn Nilsson Civilingenjörsprogrammet Institutionen för Systemteknik Avdelningen för Datorkommunikation 2000:138 • ISSN: 1402-1617 • ISRN: LTU-EX--00/138--SE An evaluation of the WebDAV extensions to the HTTP protocol Master’s Thesis in Computer Science Björn Nilsson January 2000 An evaluation of the WebDAV extensions to the HTTP protocol Abstract Abstract The HyperText Transfer Protocol (HTTP) is used for the most popular service on the Internet today – World Wide Web. WebDAV is a new extension to the HTTP protocol, which makes it possible to write, edit and share information across intranets and the Internet. In this Master’s Thesis, the WebDAV extensions are examined. A comparison between HTTP with WebDAV and the existing Internet protocols FTP and POP3 is done. Also a behavioral analysis of existing WebDAV applications is made. The conclusions are that HTTP with WebDAV extensions can replace both FTP and POP3. When using HTTP’s pipelining and persistent connections, better performance than with FTP is achieved. It seems like WebDAV can be used as a universal protocol for client-server solutions, gaining the advantages of HTTP such as encryption and caching. An evaluation of the WebDAV extensions to the HTTP protocol Preface Preface This Master’s Thesis has been made as the final part of my Master of Science degree in Computer Science and Engineering at Luleå University of Technology (LTU). The work has been carried out from September 1999 to January 2000 at Telia ProSoft AB in Malmö. I would like to thank my supervisor at Telia ProSoft, Anders Jönsson, for assistance and guidance throughout the work. -

Uniform Resource Name 1 Uniform Resource Name
Uniform Resource Name 1 Uniform Resource Name A Uniform Resource Name (URN) is a Uniform Resource Identifier (URI) that uses the urn scheme, and does not imply availability of the identified resource. Both URNs (names) and URLs (locators) are URIs, and a particular URI may be a name and a locator at the same time. The Functional Requirements for Uniform Resource Names are described in RFC 1737. The URNs are part of a larger Internet information architecture which is composed of URNs, Uniform Resource Characteristics (URCs), and Uniform Resource Locators (URLs). Each plays a specific role: • URNs are used for identification, • URCs for including meta-information. • URLs for locating or finding resources. RFC 2141 ("URN Syntax") says: Uniform Resource Names (URNs) are intended to serve as persistent, location-independent resource identifiers and are designed to make it easy to map other namespaces (that share the properties of URNs) into URN-space. Therefore, the URN syntax provides a means to encode character data in a form that can be sent in existing protocols, transcribed on most keyboards, etc. It is worth noting that, as stated in RFC 3986 ("Uniform Resource Identifier Generic Syntax"), The term "Uniform Resource Name" (URN) has been used historically to refer to both URIs under the "urn" scheme (RFC 2141), which are required to remain globally unique and persistent even when the resource ceases to exist or becomes unavailable, and to any other URI with the properties of a name. URN Syntax RFC 2141 (dated May 1997 and still classified as requests discussion and suggestions for improvements) describe in BNF the syntax of URNs as: <URN> ::= "urn:" <NID> ":" <NSS> where <NID> is the Namespace Identifier, and <NSS> is the Namespace Specific String. -

Distributed Computing
Distributed computing Mei-Ling Liu Distributed Computing 2/27/2007 Introduction, M. Liu 1 Distributed system, distributed computing Early computing was performed on a single processor. Uni-processor computing can be called centralized computing. A distributed system is a collection of independent computers, interconnected via a network, capable of collaborating on a task. Distributed computing is computing performed in a distributed system. Distributed Computing Introduction, 2/27/2007 2 M. Liu Distributed Systems work stations a local network The Internet a network host Distributed Computing Introduction, 2/27/2007 3 M. Liu Examples of Distributed systems Network of workstations (NOW): a group of networked personal workstations connected to one or more server machines. The Internet An intranet: a network of computers and workstations within an organization, segregated from the Internet via a protective device (a firewall). Distributed Computing Introduction, 2/27/2007 4 M. Liu Example of a large-scale distributed system – eBay (Source: Los Angeles Times.) Distributed Computing Introduction, 2/27/2007 5 M. Liu An example small-scale distributed system (Source: Los Angeles Times.) Distributed Computing Introduction, 2/27/2007 6 M. Liu Computers in a Distributed System Workstations: computers used by end-users to perform computing Server machines: computers which provide resources and services Personal Assistance Devices: handheld computers connected to the system via a wireless communication link. Distributed Computing Introduction, 2/27/2007 7 M. Liu The power of the Internet (Source: the Usability Professional Association’s site.) 60 million American households use computers.(The New York Times, 5/28/98) The number of computer users in the workplace has increased from 600,000 in 1976 to 80 million today.