Armadillo: C++ Template Metaprogramming for Compile-Time Optimization of Linear Algebra
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Armadillo C++ Library
Armadillo: a template-based C++ library for linear algebra Conrad Sanderson and Ryan Curtin Abstract The C++ language is often used for implementing functionality that is performance and/or resource sensitive. While the standard C++ library provides many useful algorithms (such as sorting), in its current form it does not provide direct handling of linear algebra (matrix maths). Armadillo is an open source linear algebra library for the C++ language, aiming towards a good balance between speed and ease of use. Its high-level application programming interface (function syntax) is deliberately similar to the widely used Matlab and Octave languages [4], so that mathematical operations can be expressed in a familiar and natural manner. The library is useful for algorithm development directly in C++, or relatively quick conversion of research code into production environments. Armadillo provides efficient objects for vectors, matrices and cubes (third order tensors), as well as over 200 associated functions for manipulating data stored in the objects. Integer, floating point and complex numbers are supported, as well as dense and sparse storage formats. Various matrix factorisations are provided through integration with LAPACK [3], or one of its high performance drop-in replacements such as Intel MKL [6] or OpenBLAS [9]. It is also possible to use Armadillo in conjunction with NVBLAS to obtain GPU-accelerated matrix multiplication [7]. Armadillo is used as a base for other open source projects, such as MLPACK, a C++ library for machine learning and pattern recognition [2], and RcppArmadillo, a bridge between the R language and C++ in order to speed up computations [5]. -

Rcppmlpack: R Integration with MLPACK Using Rcpp
RcppMLPACK: R integration with MLPACK using Rcpp Qiang Kou [email protected] April 20, 2020 1 MLPACK MLPACK[1] is a C++ machine learning library with emphasis on scalability, speed, and ease-of-use. It outperforms competing machine learning libraries by large margins, for detailed results of benchmarking, please refer to Ref[1]. 1.1 Input/Output using Armadillo MLPACK uses Armadillo as input and output, which provides vector, matrix and cube types (integer, floating point and complex numbers are supported)[2]. By providing Matlab-like syntax and various matrix decompositions through integration with LAPACK or other high performance libraries (such as Intel MKL, AMD ACML, or OpenBLAS), Armadillo keeps a good balance between speed and ease of use. Armadillo is widely used in C++ libraries like MLPACK. However, there is one point we need to pay attention to: Armadillo matrices in MLPACK are stored in a column-major format for speed. That means observations are stored as columns and dimensions as rows. So when using MLPACK, additional transpose may be needed. 1.2 Simple API Although MLPACK relies on template techniques in C++, it provides an intuitive and simple API. For the standard usage of methods, default arguments are provided. The MLPACK paper[1] provides a good example: standard k-means clustering in Euclidean space can be initialized like below: 1 KMeans<> k(); Listing 1: k-means with all default arguments If we want to use Manhattan distance, a different cluster initialization policy, and allow empty clusters, the object can be initialized with additional arguments: 1 KMeans<ManhattanDistance, KMeansPlusPlusInitialization, AllowEmptyClusters> k(); Listing 2: k-means with additional arguments 1 1.3 Available methods in MLPACK Commonly used machine learning methods are all implemented in MLPACK. -

Release 0.11 Todd Gamblin
Spack Documentation Release 0.11 Todd Gamblin Feb 07, 2018 Basics 1 Feature Overview 3 1.1 Simple package installation.......................................3 1.2 Custom versions & configurations....................................3 1.3 Customize dependencies.........................................4 1.4 Non-destructive installs.........................................4 1.5 Packages can peacefully coexist.....................................4 1.6 Creating packages is easy........................................4 2 Getting Started 7 2.1 Prerequisites...............................................7 2.2 Installation................................................7 2.3 Compiler configuration..........................................9 2.4 Vendor-Specific Compiler Configuration................................ 13 2.5 System Packages............................................. 16 2.6 Utilities Configuration.......................................... 18 2.7 GPG Signing............................................... 20 2.8 Spack on Cray.............................................. 21 3 Basic Usage 25 3.1 Listing available packages........................................ 25 3.2 Installing and uninstalling........................................ 42 3.3 Seeing installed packages........................................ 44 3.4 Specs & dependencies.......................................... 46 3.5 Virtual dependencies........................................... 50 3.6 Extensions & Python support...................................... 53 3.7 Filesystem requirements........................................ -

Armadillo: an Open Source C++ Linear Algebra Library for Fast Prototyping and Computationally Intensive Experiments
Armadillo: An Open Source C++ Linear Algebra Library for Fast Prototyping and Computationally Intensive Experiments Conrad Sanderson http://conradsanderson.id.au Technical Report, NICTA, Australia http://nicta.com.au September 2010 (revised December 2011) Abstract In this report we provide an overview of the open source Armadillo C++ linear algebra library (matrix maths). The library aims to have a good balance between speed and ease of use, and is useful if C++ is the language of choice (due to speed and/or integration capabilities), rather than another language like Matlab or Octave. In particular, Armadillo can be used for fast prototyping and computationally intensive experiments, while at the same time allowing for relatively painless transition of research code into production environments. It is distributed under a license that is applicable in both open source and proprietary software development contexts. The library supports integer, floating point and complex numbers, as well as a subset of trigonometric and statistics functions. Various matrix decompositions are provided through optional integration with LAPACK, or one its high-performance drop-in replacements, such as MKL from Intel or ACML from AMD. A delayed evaluation approach is employed (during compile time) to combine several operations into one and reduce (or eliminate) the need for temporaries. This is accomplished through C++ template meta-programming. Performance comparisons suggest that the library is considerably faster than Matlab and Octave, as well as previous C++ libraries such as IT++ and Newmat. This report reflects a subset of the functionality present in Armadillo v2.4. Armadillo can be downloaded from: • http://arma.sourceforge.net If you use Armadillo in your research and/or software, we would appreciate a citation to this document. -

Eigenvalues and Eigenvectors for 3×3 Symmetric Matrices: an Analytical Approach
Journal of Advances in Mathematics and Computer Science 35(7): 106-118, 2020; Article no.JAMCS.61833 ISSN: 2456-9968 (Past name: British Journal of Mathematics & Computer Science, Past ISSN: 2231-0851) Eigenvalues and Eigenvectors for 3×3 Symmetric Matrices: An Analytical Approach Abu Bakar Siddique1 and Tariq A. Khraishi1* 1Department of Mechanical Engineering, University of New Mexico, USA. Authors’ contributions This work was carried out in collaboration between both authors. ABS worked on equation derivation, plotting and writing. He also worked on the literature search. TK worked on equation derivation, writing and editing. Both authors contributed to conceptualization of the work. Both authors read and approved the final manuscript. Article Information DOI: 10.9734/JAMCS/2020/v35i730308 Editor(s): (1) Dr. Serkan Araci, Hasan Kalyoncu University, Turkey. Reviewers: (1) Mr. Ahmed A. Hamoud, Taiz University, Yemen. (2) Raja Sarath Kumar Boddu, Lenora College of Engineering, India. Complete Peer review History: http://www.sdiarticle4.com/review-history/61833 Received: 22 July 2020 Accepted: 29 September 2020 Original Research Article Published: 21 October 2020 _______________________________________________________________________________ Abstract Research problems are often modeled using sets of linear equations and presented as matrix equations. Eigenvalues and eigenvectors of those coupling matrices provide vital information about the dynamics/flow of the problems and so needs to be calculated accurately. Analytical solutions are advantageous over numerical solutions because numerical solutions are approximate in nature, whereas analytical solutions are exact. In many engineering problems, the dimension of the problem matrix is 3 and the matrix is symmetric. In this paper, the theory behind finding eigenvalues and eigenvectors for order 3×3 symmetric matrices is presented. -

Mlpack Open-Source Machine Learning Library and Community
mlpack open-source machine learning library and community Marcus Edel Institute of Computer Science, Free University of Berlin [email protected] Abstract mlpack is an open-source C++ machine learning library with an emphasis on speed and flexibility. Since its original inception in 2007, it has grown to be a large project, implementing a wide variety of machine learning algorithms. This short paper describes the general design principles and discusses how the open- source community around the library functions. 1 Introduction All modern machine learning research makes use of software in some way. Machine learning as a field has thus long supported the development of software tools for machine learning tasks, such as scripts that enable individual scientific research, software packages for small collaborations, and data processing pipelines for evaluation and validation. Some software packages are, or were, supported by large institutions and are intended for a wide range of users. Other packages like the mlpack machine learning library are developed by individual researchers or research groups and are typically used by smaller groups for more domain-specific purposes; and highly benefits from a community and ecosystem built around a shared foundation. mlpack is a flexible and fast machine learning library, is free to use under the terms of the BSD open-source license, and accepts contributions from anyone. Since 2007, the project has grown to have nearly 120 individual contributors, has been downloaded over 80,000 times and is being used all around the world and in space as well [7]. A large part of this success owes itself to the vibrant community of developers and a continuously- growing ecosystem of tools, web services, stable well- developed packages that enable easier collaboration on software development, continuous testing and its participation in open-source initiatives such as Google Summer of Code (https://summerofcode.withgoogle.com/). -
![Arxiv:1805.03380V3 [Cs.MS] 21 Oct 2019 a Specific Set of Operations (Eg., Matrix Multiplication Vs](https://docslib.b-cdn.net/cover/5358/arxiv-1805-03380v3-cs-ms-21-oct-2019-a-speci-c-set-of-operations-eg-matrix-multiplication-vs-3585358.webp)
Arxiv:1805.03380V3 [Cs.MS] 21 Oct 2019 a Specific Set of Operations (Eg., Matrix Multiplication Vs
A User-Friendly Hybrid Sparse Matrix Class in C++ Conrad Sanderson1;3;4 and Ryan Curtin2;4 1 Data61, CSIRO, Australia 2 Symantec Corporation, USA 3 University of Queensland, Australia 4 Arroyo Consortium ? Abstract. When implementing functionality which requires sparse matrices, there are numerous storage formats to choose from, each with advantages and disadvantages. To achieve good performance, several formats may need to be used in one program, requiring explicit selection and conversion between the for- mats. This can be both tedious and error-prone, especially for non-expert users. Motivated by this issue, we present a user-friendly sparse matrix class for the C++ language, with a high-level application programming interface deliberately similar to the widely used MATLAB language. The class internally uses two main approaches to achieve efficient execution: (i) a hybrid storage framework, which automatically and seamlessly switches between three underlying storage formats (compressed sparse column, coordinate list, Red-Black tree) depending on which format is best suited for specific operations, and (ii) template-based meta-programming to automatically detect and optimise execution of common expression patterns. To facilitate relatively quick conversion of research code into production environments, the class and its associated functions provide a suite of essential sparse linear algebra functionality (eg., arithmetic operations, submatrix manipulation) as well as high-level functions for sparse eigendecompositions and linear equation solvers. The latter are achieved by providing easy-to-use abstrac- tions of the low-level ARPACK and SuperLU libraries. The source code is open and provided under the permissive Apache 2.0 license, allowing unencumbered use in commercial products. -

Introduction to Parallel Programming (For Physicists) FRANÇOIS GÉLIS & GRÉGOIRE MISGUICH, Ipht Courses, June 2019
Introduction to parallel programming (for physicists) FRANÇOIS GÉLIS & GRÉGOIRE MISGUICH, IPhT courses, June 2019. 1. Introduction & hardware aspects (FG) These 2. A few words about Maple & Mathematica slides (GM) slides 3. Linear algebra libraries 4. Fast Fourier transform 5. Python Multiprocessing 6. OpenMP 7. MPI (FG) 8. MPI+OpenMP (FG) Numerical Linear algebra Here: a few simple examples showing how to call some parallel linear algebra libraries in numerical calculations (numerical) Linear algebra • Basic Linear Algebra Subroutines: BLAS • More advanced operations Linear Algebra Package: LAPACK • vector op. (=level 1) (‘90, Fortran 77) • matrix-vector (=level 2) • Call the BLAS routines • matrix-matrix mult. & triangular • Matrix diagonalization, linear systems inversion (=level 3) and eigenvalue problems • Many implementations but • Matrix decompositions: LU, QR, SVD, standardized interface Cholesky • Discussed here: Intel MKL & OpenBlas (multi-threaded = parallelized for • Many implementations shared-memory architectures) Used in most scientific softwares & libraries (Python/Numpy, Maple, Mathematica, Matlab, …) A few other useful libs … for BIG matrices • ARPACK • ScaLAPACK =Implicitly Restarted Arnoldi Method (~Lanczos for Parallel version of LAPACK for for distributed memory Hermitian cases) architectures Large scale eigenvalue problems. For (usually sparse) nxn matrices with n which can be as large as 10^8, or even more ! Ex: iterative algo. to find the largest eigenvalue, without storing the matrix M (just provide v→Mv). Can be used from Python/SciPy • PARPACK = parallel version of ARPACK for distributed memory architectures (the matrices are stored over several nodes) Two multi-threaded implementations of BLAS & Lapack OpenBLAS Intel’s implementation (=part of the MKL lib.) • Open source License (BSD) • Commercial license • Based on GotoBLAS2 • Included in Intel®Parallel Studio XE (compilers, [Created by GAZUSHIGE GOTO, Texas Adv. -

MLPACK: a Scalable C++ Machine Learning Library
JournalofMachineLearningResearch14(2013)801-805 Submitted 9/12; Revised 2/13; Published 3/13 MLPACK: A Scalable C++ Machine Learning Library Ryan R. Curtin [email protected] James R. Cline [email protected] N. P. Slagle [email protected] William B. March [email protected] Parikshit Ram [email protected] Nishant A. Mehta [email protected] Alexander G. Gray [email protected] College of Computing Georgia Institute of Technology Atlanta, GA 30332 Editor: Balázs Kégl Abstract MLPACK is a state-of-the-art, scalable, multi-platform C++ machine learning library released in late 2011 offering both a simple, consistent API accessible to novice users and high perfor- mance and flexibility to expert users by leveraging modern features of C++. MLPACK pro- vides cutting-edge algorithms whose benchmarks exhibit far better performance than other lead- ing machine learning libraries. MLPACK version 1.0.3, licensed under the LGPL, is available at http://www.mlpack.org. Keywords: C++, dual-tree algorithms, machine learning software, open source software, large- scale learning 1. Introduction and Goals Though several machine learning libraries are freely available online, few, if any, offer efficient algorithms to the average user. For instance, the popular Weka toolkit (Hall et al., 2009) emphasizes ease of use but scales poorly; the distributed Apache Mahout library offers scalability at a cost of higher overhead (such as clusters and powerful servers often unavailable to the average user). Also, few libraries offer breadth; for instance, libsvm (Chang and Lin, 2011) and the Tilburg Memory- Based Learner (TiMBL) are highly scalable and accessible yet each offer only a single method. -
Practical Sparse Matrices in C++ with Hybrid Storage and Template-Based Expression Optimisation
Practical Sparse Matrices in C++ with Hybrid Storage and Template-Based Expression Optimisation Conrad Sanderson Ryan Curtin [email protected] [email protected] Data61, CSIRO, Australia RelationalAI, USA University of Queensland, Australia Arroyo Consortium Arroyo Consortium Abstract Despite the importance of sparse matrices in numerous fields of science, software implementations remain difficult to use for non-expert users, generally requiring the understanding of underlying details of the chosen sparse matrix storage format. In addition, to achieve good performance, several formats may need to be used in one program, requiring explicit selection and conversion between the formats. This can be both tedious and error-prone, especially for non-expert users. Motivated by these issues, we present a user-friendly and open-source sparse matrix class for the C++ language, with a high-level application programming interface deliberately similar to the widely used MATLAB language. This facilitates prototyping directly in C++ and aids the conversion of research code into production environments. The class internally uses two main ap- proaches to achieve efficient execution: (i) a hybrid storage framework, which automatically and seamlessly switches between three underlying storage formats (compressed sparse column, Red-Black tree, coordinate list) depending on which format is best suited and/or available for specific operations, and (ii) a template- based meta-programming framework to automatically detect and optimise execution of common expression patterns. Empirical evaluations on large sparse matrices with various densities of non-zero elements demon- strate the advantages of the hybrid storage framework and the expression optimisation mechanism. • Keywords: mathematical software; C++ language; sparse matrix; numerical linear algebra • AMS MSC2010 codes: 68N99; 65Y04; 65Y15; 65F50 • Associated source code: http://arma.sourceforge.net • Published as: Conrad Sanderson and Ryan Curtin. -

The Linear Algebra Mapping Problem 3
THE LINEAR ALGEBRA MAPPING PROBLEM. CURRENT STATE OF LINEAR ALGEBRA LANGUAGES AND LIBRARIES. CHRISTOS PSARRAS∗, HENRIK BARTHELS∗, AND PAOLO BIENTINESI† Abstract. We observe a disconnect between the developers and the end users of linear algebra libraries. On the one hand, the numerical linear algebra and the high-performance communities invest significant effort in the development and optimization of highly sophisticated numerical kernels and libraries, aiming at the maximum exploitation of both the properties of the input matrices, and the architectural features of the target computing platform. On the other hand, end users are progressively less likely to go through the error-prone and time consuming process of directly using said libraries by writing their code in C or Fortran; instead, languages and libraries such as Matlab, Julia, Eigen and Armadillo, which offer a higher level of abstraction, are becoming more and more popular. Users are given the opportunity to code matrix computations with a syntax that closely resembles the mathematical description; it is then a compiler or an interpreter that internally maps the input program to lower level kernels, as provided by libraries such as BLAS and LAPACK. Unfortunately, our experience suggests that in terms of performance, this translation is typically vastly suboptimal. In this paper, we first introduce the Linear Algebra Mapping Problem, and then investigate how effectively a benchmark of test problems is solved by popular high-level programming languages and libraries. Specifically, we consider Matlab, Octave, Julia, R, C++ with Armadillo, C++ with Eigen, and Python with NumPy; the benchmark is meant to test both standard compiler optimizations such as common subexpression elimination and loop-invariant code motion, as well as linear algebra specific optimizations such as optimal parenthesization for a matrix product and kernel selection for matrices with properties. -
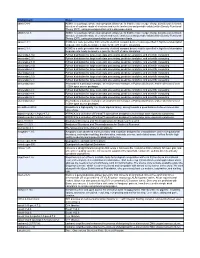
Nanohub Environments Available Aug 12, 2018
Environment Notes abinit-5.4.4: ABINIT is a package whose main program allows one to find the total energy, charge density and electronic structure of systems made of electrons and nuclei (molecules and periodic solids) within Density Functional Theory (DFT), using pseudopotentials and a planewave basis. abinit-6.12.3: ABINIT is a package whose main program allows one to find the total energy, charge density and electronic structure of systems made of electrons and nuclei (molecules and periodic solids) within Density Functional Theory (DFT), using pseudopotentials and a planewave basis. adms-2.3.1: ADMS is a code generator that converts electrical compact device models specified in high-level description language into ready-to-compile c code for the API of spice simulators. adms-2.3.4: ADMS is a code generator that converts electrical compact device models specified in high-level description language into ready-to-compile c code for the API of spice simulators. anaconda-1.9.2: Python distribution for large-scale data processing, predictive analytics, and scientific computing. anaconda-2.0.1: Python distribution for large-scale data processing, predictive analytics, and scientific computing. anaconda-2.1.0: Python distribution for large-scale data processing, predictive analytics, and scientific computing. anaconda-2.3.0: Python distribution for large-scale data processing, predictive analytics, and scientific computing. anaconda2-4.1: Python distribution for large-scale data processing, predictive analytics, and scientific computing. anaconda2-4.4: Python distribution for large-scale data processing, predictive analytics, and scientific computing. anaconda-2.5.0: Python distribution for large-scale data processing, predictive analytics, and scientific computing.