Verb Classification Using Distributional Similarity in Syntactic
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Verbs Followed by Gerunds & Infinitives
Verbs Followed by Gerunds & Infinitives In English, if you want to follow a verb with another action, you must use a gerund or infinitive. EXAMPLE: We resumed talking. (gerund – verb + ing) I want to see a movie. (infinitive – to + base verb) There are certain verbs that can only be followed by one or the other, and these verbs must be memorized. Many of these verbs are listed below. Verbs commonly followed by a gerund Verbs commonly followed by an infinitive EXAMPLE: “He misses playing with his friends.” EXAMPLE: “She threatened to quit if she didn’t get a raise.” abhor give up (stop) agree mean acknowledge keep (continue) appear need admit keep on arrange neglect advise mention ask offer allow mind (object to) attempt pay anticipate miss beg plan appreciate necessitate can/can’t afford prepare avoid omit can/can’t wait pretend be worth permit care profess can’t help picture chance promise celebrate postpone choose prove confess practice claim refuse consider prevent come remain defend put off consent request delay recall dare resolve detest recollect decide say discontinue recommend demand seek discuss report deserve seem dislike resent determine shudder dispute resist elect strive dread resume endeavor struggle endure risk expect swear enjoy shirk fail tend escape shun get threaten evade suggest grow (up) turn out explain support guarantee venture fancy tolerate hesitate volunteer fear understand hope wait feel like urge hurry want feign warrant incline wish finish learn would like forgive manage yearn 1 • Verbs Followed by Gerunds & Infinitives more free resources, lessons, and quizzes at by Alex © LangVid Language Training, 2013 www.engVid.com Verbs followed by a gerund or infinitive with little to no change in meaning: EXAMPLES: “It started to rain.” ~OR~ “It started raining.” begin like can’t bear love can’t stand prefer continue propose hate start Verbs followed by a gerund or infinitive with a change in meaning: I forgot to meet him. -

The Formation, Translation and Use of Participles in Latin, and the Nature of Relative Time
Chapter 23: Participles Chapter 23 covers the following: the formation, translation and use of participles in Latin, and the nature of relative time. At the end of the lesson we’ll review the vocabulary which you should memorize in this chapter. There are four important rules to remember in Chapter 23: (1) Latin has four participles: the present active, the future active; the perfect passive and the future passive. It lacks, however, a present passive participle (“being [verb]-ed”) and a perfect active participle (“having [verb]-ed”). (2) The perfect passive, future active and future passive participles belong to first/second declension. The present active participle belongs to third declension. (3) The verb esse has only a future active participle (futurus). It lacks both the present active and all passive participles. (4) Participles show relative time. What are participles? At heart, participles are verbs which have been turned into adjectives. Thus, technically participles are “verbal adjectives.” The first part of the word (parti-) means “part;” the second part (-cip-) means “take,” indicating that participles “partake, share” in the characteristics of both verbs and adjectives. In other words, the base of a participle is verbal, giving it some of the qualities of a verb, for instance, tense: it can indicate when the action is happening (now or then or later; i.e. present, past or future); conjugation: what thematic vowel will be used (e.g. -a- in first conjugation, -e- in second, and so on); voice: whether the word it’s attached to is acting or being acted upon (i.e. -

Nouns, Adjectives, Verbs, and Adverbs
Unit 1: The Parts of Speech Noun—a person, place, thing, or idea Name: Person: boy Kate mom Place: house Minnesota ocean Adverbs—describe verbs, adjectives, and other Thing: car desk phone adverbs Idea: freedom prejudice sadness --------------------------------------------------------------- Answers the questions how, when, where, and to Pronoun—a word that takes the place of a noun. what extent Instead of… Kate – she car – it Many words ending in “ly” are adverbs: quickly, smoothly, truly A few other pronouns: he, they, I, you, we, them, who, everyone, anybody, that, many, both, few A few other adverbs: yesterday, ever, rather, quite, earlier --------------------------------------------------------------- --------------------------------------------------------------- Adjective—describes a noun or pronoun Prepositions—show the relationship between a noun or pronoun and another word in the sentence. Answers the questions what kind, which one, how They begin a prepositional phrase, which has a many, and how much noun or pronoun after it, called the object. Articles are a sub category of adjectives and include Think of the box (things you have do to a box). the following three words: a, an, the Some prepositions: over, under, on, from, of, at, old car (what kind) that car (which one) two cars (how many) through, in, next to, against, like --------------------------------------------------------------- Conjunctions—connecting words. --------------------------------------------------------------- Connect ideas and/or sentence parts. Verb—action, condition, or state of being FANBOYS (for, and, nor, but, or, yet, so) Action (things you can do)—think, run, jump, climb, eat, grow A few other conjunctions are found at the beginning of a sentence: however, while, since, because Linking (or helping)—am, is, are, was, were --------------------------------------------------------------- Interjections—show emotion. -

A Syntactic Analysis of Copular Sentences*
A SYNTACTIC ANALYSIS OF COPULAR SENTENCES* Masato Niimura Nanzan University 1. Introduction Copular is a verb whose main function is to link subjects with predicate complements. In a limited sense, the copular refers to a verb that does not have any semantic content, but links subjects and predicate complements. In a broad sense, the copular contains a verb that has its own meaning and bears the syntactic function of “the copular.” Higgins (1979) analyses English copular sentences and classifies them into three types. (1) a. predicational sentence b. specificational sentence c. identificational sentence Examples are as follows: (2) a. John is a philosopher. b. The bank robber is John Smith. c. That man is Mary’s brother. (2a) is an example of predicational sentence. This type takes a reference as subject, and states its property in predicate. In (2a), the reference is John, and its property is a philosopher. (2b) is an example of specificational sentence, which expresses what meets a kind of condition. In (2b), what meets the condition of the bank robber is John Smith. (2c) is an example of identificational sentence, which identifies two references. This sentence identifies that man and Mary’s brother. * This paper is part of my MA thesis submitted to Nanzan University in March, 2007. This paper was also presented at the Connecticut-Nanzan-Siena Workshop on Linguistic Theory and Language Acquisition, held at Nanzan University on February 21, 2007. I would like to thank the participants for the discussions and comments on this paper. My thanks go to Keiko Murasugi, Mamoru Saito, Tomohiro Fujii, Masatake Arimoto, Jonah Lin, Yasuaki Abe, William McClure, Keiko Yano and Nobuko Mizushima for the invaluable comments and discussions on the research presented in this paper. -

Grammar Workshop Verb Tenses
Grammar Workshop Verb Tenses* JOSEPHINE BOYLE WILLEM OPPERMAN ACADEMIC SUPPORT AND ACCESS CENTER AMERICAN UNIVERSITY SEPTEMBER 29, 2 0 1 6 *Sources consulted: Purdue OWL and Grammarly Handbook What is a Verb? Every basic sentence in the English language must have a noun and a verb. Verbs are action words. Verbs describe what the subject of the sentence is doing. Verbs can describe physical actions like movement, less concrete actions like thinking and feeling, and a state of being, as explained by the verb to be. What is a Verb? There are two specific uses for verbs: Put a motionless noun into motion, or to change its motion. If you can do it, its an action verb. (walk, run, study, learn) Link the subject of the sentence to something which describes the subject. If you can’t do it, it’s probably a linking verb. (am, is) Action Verbs: Susie ran a mile around the track. “Ran” gets Susie moving around the track. Bob went to the book store. “Went” gets Bob moving out the door and doing the shopping at the bookstore. Linking Verbs: I am bored. It’s difficult to “am,” so this is likely a linking verb. It’s connecting the subject “I” to the state of being bored. Verb Tenses Verb tenses are a way for the writer to express time in the English language. There are nine basic verb tenses: Simple Present: They talk Present Continuous: They are talking Present Perfect: They have talked Simple Past: They talked Past Continuous: They were talking Past Perfect: They had talked Future: They will talk Future Continuous: They will be talking Future Perfect: They will have talked Simple Present Tense Simple Present: Used to describe a general state or action that is repeated. -

PARTS of SPEECH ADJECTIVE: Describes a Noun Or Pronoun; Tells
PARTS OF SPEECH ADJECTIVE: Describes a noun or pronoun; tells which one, what kind or how many. ADVERB: Describes verbs, adjectives, or other adverbs; tells how, why, when, where, to what extent. CONJUNCTION: A word that joins two or more structures; may be coordinating, subordinating, or correlative. INTERJECTION: A word, usually at the beginning of a sentence, which is used to show emotion: one expressing strong emotion is followed by an exclamation point (!); mild emotion followed by a comma (,). NOUN: Name of a person, place, or thing (tells who or what); may be concrete or abstract; common or proper, singular or plural. PREPOSITION: A word that connects a noun or noun phrase (the object) to another word, phrase, or clause and conveys a relation between the elements. PRONOUN: Takes the place of a person, place, or thing: can function any way a noun can function; may be nominative, objective, or possessive; may be singular or plural; may be personal (therefore, first, second or third person), demonstrative, intensive, interrogative, reflexive, relative, or indefinite. VERB: Word that represents an action or a state of being; may be action, linking, or helping; may be past, present, or future tense; may be singular or plural; may have active or passive voice; may be indicative, imperative, or subjunctive mood. FUNCTIONS OF WORDS WITHIN A SENTENCE: CLAUSE: A group of words that contains a subject and complete predicate: may be independent (able to stand alone as a simple sentence) or dependent (unable to stand alone, not expressing a complete thought, acting as either a noun, adjective, or adverb). -

1 Noun Classes and Classifiers, Semantics of Alexandra Y
1 Noun classes and classifiers, semantics of Alexandra Y. Aikhenvald Research Centre for Linguistic Typology, La Trobe University, Melbourne Abstract Almost all languages have some grammatical means for the linguistic categorization of noun referents. Noun categorization devices range from the lexical numeral classifiers of South-East Asia to the highly grammaticalized noun classes and genders in African and Indo-European languages. Further noun categorization devices include noun classifiers, classifiers in possessive constructions, verbal classifiers, and two rare types: locative and deictic classifiers. Classifiers and noun classes provide a unique insight into how the world is categorized through language in terms of universal semantic parameters involving humanness, animacy, sex, shape, form, consistency, orientation in space, and the functional properties of referents. ABBREVIATIONS: ABS - absolutive; CL - classifier; ERG - ergative; FEM - feminine; LOC – locative; MASC - masculine; SG – singular 2 KEY WORDS: noun classes, genders, classifiers, possessive constructions, shape, form, function, social status, metaphorical extension 3 Almost all languages have some grammatical means for the linguistic categorization of nouns and nominals. The continuum of noun categorization devices covers a range of devices from the lexical numeral classifiers of South-East Asia to the highly grammaticalized gender agreement classes of Indo-European languages. They have a similar semantic basis, and one can develop from the other. They provide a unique insight into how people categorize the world through their language in terms of universal semantic parameters involving humanness, animacy, sex, shape, form, consistency, and functional properties. Noun categorization devices are morphemes which occur in surface structures under specifiable conditions, and denote some salient perceived or imputed characteristics of the entity to which an associated noun refers (Allan 1977: 285). -

Resulting Copulas and Their Complements in British and American English: a Corpus Based Study
UNIVERZITA PALACKÉHO V OLOMOUCI FILOZOFICKÁ FAKULTA Katedra anglistiky a amerikanistiky Martin Dokoupil anglická filologie & francouzská filologie Resulting Copulas and their Complements in British and American English: A Corpus Based Study. Bakalářská práce Vedoucí diplomové práce: Mgr. Michaela Martinková, PhD. OLOMOUC 2011 Prohlašuji, že jsem tuto bakalářskou práci vypracoval samostatně na základě uvedených pramenů a literatury. V Olomouci, dne 10. srpna 2011 podpis 2 I hereby declare that this bachelor thesis is completely my own work and that I used only the cited sources. Olomouc, 10th August 2011 signature 3 Děkuji vedoucí mé bakalářské práce Mgr. Michaele Martinkové, PhD. za ochotu, trpělivost a cenné rady při psaní této práce. 4 Table of Contents: 1 Introduction ..........................................................................................................................6 2 Theoretical Preliminaries ....................................................................................................7 2.1 Literature .....................................................................................................................7 2.2 Copular verb in general ..............................................................................................8 2.2.1 Copular verb .......................................................................................................8 2.2.2 Prototypical copular usage ...............................................................................8 2.2.3 Copular verb complementation -

A Present Participle Is the –Ing Form of a Verb When It Is Used As an Adjective
WHAT IS A PARTICIPLE? A participle is a verbal that is used as an adjective. A verbal is a word that is based on a verb but does not act as a verb. A participle is used to modify either a noun or a pronoun. For example: Here the participle barking The barking dog wanted to come inside. modifies the dog. WHAT IS A PARTICIPIAL PHRASE? A participial phrase is a phrase that begins with a participle and includes objects or other modifi- ers. It also acts as an adjective. For example: Here the participial phrase Barking loudly, the dog wanted to come inside. barking loudly modifies the dog. There are two types of participles: present participles and past participles. Present participles end in –ing , while past participles end in –ed , -en , -d, -t, or –n. A present participle is the –ing form of a verb when it is used as an adjective. Note: a present participle is different from a gerund , which is the –ing form of a verb when it is used as a noun . The approaching deadline hung over the heads of all the people in the office. Here, approaching is an adjective that is used to describe the deadline. The leaping flames from the burning building presented the firefighters with the responsibility of protecting other nearby buildings from the growing fire. Here, leaping , burning , and growing are verbals used as adjectives to describe a noun (flames, building, and fire respectively) in the sentence, thereby qualifying them as present participles. Although it ends in –ing , protecting is not a partici - ple because it is acting as a noun in the sentence (object of the preposition), thereby qualifying it as a gerund. -

UNCORRECTED PROOFS © JOHN BENJAMINS PUBLISHING COMPANY 1St Proofs 224 Michael Cysouw
Chapter 7 A typology of honorific uses of clusivity Michael Cysouw Max Planck Institute for Evolutionary Anthropology In many languages, pronouns are used with special meanings in honorific contexts. The most widespread phenomenon cross-linguistically is the usage of a plural pronoun instead of a singular to mark respect. In this chapter, I will investigate the possibility of using clusivity in honorific contexts. This is a rare phenomenon, but a thorough investigation has resulted in a reasonably diverse set of examples, taken from languages all over the world. It turns out that there are many different honorific contexts in which an inclusive or exclusive pronoun can be used. The most commonly attested variant is the usage of an inclusive pronoun with a po- lite connotation, indicating social distance. Keywords: politeness, respect, syncretism, clusivity 1. Introduction In his study of the cross-linguistic variation of honorific reference, Head (1978: 178) claims that inclusive reference, when used honorifically, indicates less social dis- tance. However, he claims this on the basis of only two cases. In this chapter, a sur- vey will be presented of a large set of languages, in which an inclusive or exclusive marker is used in an honorific sense. It turns out that Head’s claim is not accurate. In contrast, it appears that inclusive marking is in many cases a sign of greater so- cial distance, although the variability of the possible honorific usages is larger than might have been expected. There are also cases in which an inclusive is used in an impolite fashion or cases in which an exclusive is used in a polite fashion. -
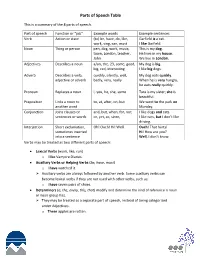
Parts of Speech Table
Parts of Speech Table This is a summary of the 8 parts of speech. Part of speech Function or “job” Example words Example sentences Verb Action or state (to) be, have, do, like, Garfield is a cat. work, sing, can, must I like Garfield. Noun Thing or person pen, dog, work, music, This is my dog. town, London, teacher, He lives in my house. John We live in London. Adjectives Describes a noun a/an, the, 23, some, good, My dog is big. big, red, interesting I like big dogs. Adverb Describes a verb, quickly, silently, well, My dog eats quickly. adjective or adverb badly, very, really When he is very hungry, he eats really quickly. Pronoun Replaces a noun I, you, he, she, some Tara is my sister; she is beautiful. Preposition Links a noun to to, at, after, on, but We went to the park on another word Monday. Conjunction Joins clauses or and, but, when, for, nor, I like dogs and cats. sentences or words or, yet, so, since, I like cars, but I don’t like driving. Interjection Short exclamation, Oh! Ouch! Hi! Well. Ouch! That hurts! sometimes inserted Hi! How are you? into a sentence Well, I don’t know. Verbs may be treated as two different parts of speech: Lexical Verbs (work, like, run) o I like Vampire Diaries. Auxiliary Verbs or Helping Verbs (be, have, must) o I have watched it. Auxiliary verbs are always followed by another verb. Some auxiliary verbs can become lexical verbs if they are not used with other verbs, such as: o I have seven pairs of shoes. -

Quick Guide to Sentence Structure and Parts of Speech in English
A Quick Guide to Sentence Structure and Parts of Speech in English names a person, place, thing, quality or idea noun Examples: Chicago, Mary, table, kindness Juan lives in Chicago. Mary likes to travel. The table is set for dinner. She is full of kindness. Every complete sentence (or independent clause) must include a subiect. This subject is often a noun. Without the subject, the reader wonders "who, what, or where?" Likes to travel. -Who likes to travel? Mary likes to travel. The is set for dinner. -What is set for dinner? The table is set for dinner. describes an action or state verb Examples: write, have, sing, (to) be, can Students write essays. My cat has a tail. She sings well. The city is exciting. We can talk. Every complete sentence (or independent clause) must also include a verb. The verb describes what action the subject of the sentence performs. This action can also be a state of being. Students essays. -What do the students Students write essays. She well. do? She sings well. The city exciting -What does she do well? The city is exciting. -What is the city? Every complete sentence (or independent clause) must also be a complete thought. If it contains a noun and a verb, but it is not a complete thought, then it is a dependent clause. When Mark runs. -What happens when Mark runs? When Mark runs, he sweats. Because it is hot. -What happens because? We hydrate because it is hot. COnJ"unction joins sentences, clauses or phrases Examples: and, so, but It rained, so the game was canceled.