A Tool to Identify Coordinately Expressed Genes
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

PARSANA-DISSERTATION-2020.Pdf
DECIPHERING TRANSCRIPTIONAL PATTERNS OF GENE REGULATION: A COMPUTATIONAL APPROACH by Princy Parsana A dissertation submitted to The Johns Hopkins University in conformity with the requirements for the degree of Doctor of Philosophy Baltimore, Maryland July, 2020 © 2020 Princy Parsana All rights reserved Abstract With rapid advancements in sequencing technology, we now have the ability to sequence the entire human genome, and to quantify expression of tens of thousands of genes from hundreds of individuals. This provides an extraordinary opportunity to learn phenotype relevant genomic patterns that can improve our understanding of molecular and cellular processes underlying a trait. The high dimensional nature of genomic data presents a range of computational and statistical challenges. This dissertation presents a compilation of projects that were driven by the motivation to efficiently capture gene regulatory patterns in the human transcriptome, while addressing statistical and computational challenges that accompany this data. We attempt to address two major difficulties in this domain: a) artifacts and noise in transcriptomic data, andb) limited statistical power. First, we present our work on investigating the effect of artifactual variation in gene expression data and its impact on trans-eQTL discovery. Here we performed an in-depth analysis of diverse pre-recorded covariates and latent confounders to understand their contribution to heterogeneity in gene expression measurements. Next, we discovered 673 trans-eQTLs across 16 human tissues using v6 data from the Genotype Tissue Expression (GTEx) project. Finally, we characterized two trait-associated trans-eQTLs; one in Skeletal Muscle and another in Thyroid. Second, we present a principal component based residualization method to correct gene expression measurements prior to reconstruction of co-expression networks. -

SPATA33 Localizes Calcineurin to the Mitochondria and Regulates Sperm Motility in Mice
SPATA33 localizes calcineurin to the mitochondria and regulates sperm motility in mice Haruhiko Miyataa, Seiya Ouraa,b, Akane Morohoshia,c, Keisuke Shimadaa, Daisuke Mashikoa,1, Yuki Oyamaa,b, Yuki Kanedaa,b, Takafumi Matsumuraa,2, Ferheen Abbasia,3, and Masahito Ikawaa,b,c,d,4 aResearch Institute for Microbial Diseases, Osaka University, Osaka 5650871, Japan; bGraduate School of Pharmaceutical Sciences, Osaka University, Osaka 5650871, Japan; cGraduate School of Medicine, Osaka University, Osaka 5650871, Japan; and dThe Institute of Medical Science, The University of Tokyo, Tokyo 1088639, Japan Edited by Mariana F. Wolfner, Cornell University, Ithaca, NY, and approved July 27, 2021 (received for review April 8, 2021) Calcineurin is a calcium-dependent phosphatase that plays roles in calcineurin can be a target for reversible and rapidly acting male a variety of biological processes including immune responses. In sper- contraceptives (5). However, it is challenging to develop molecules matozoa, there is a testis-enriched calcineurin composed of PPP3CC and that specifically inhibit sperm calcineurin and not somatic calci- PPP3R2 (sperm calcineurin) that is essential for sperm motility and male neurin because of sequence similarities (82% amino acid identity fertility. Because sperm calcineurin has been proposed as a target for between human PPP3CA and PPP3CC and 85% amino acid reversible male contraceptives, identifying proteins that interact with identity between human PPP3R1 and PPP3R2). Therefore, identi- sperm calcineurin widens the choice for developing specific inhibitors. fying proteins that interact with sperm calcineurin widens the choice Here, by screening the calcineurin-interacting PxIxIT consensus motif of inhibitors that target the sperm calcineurin pathway. in silico and analyzing the function of candidate proteins through the The PxIxIT motif is a conserved sequence found in generation of gene-modified mice, we discovered that SPATA33 inter- calcineurin-binding proteins (8, 9). -

Meta-Analysis of Nasopharyngeal Carcinoma
BMC Genomics BioMed Central Research article Open Access Meta-analysis of nasopharyngeal carcinoma microarray data explores mechanism of EBV-regulated neoplastic transformation Xia Chen†1,2, Shuang Liang†1, WenLing Zheng1,3, ZhiJun Liao1, Tao Shang1 and WenLi Ma*1 Address: 1Institute of Genetic Engineering, Southern Medical University, Guangzhou, PR China, 2Xiangya Pingkuang associated hospital, Pingxiang, Jiangxi, PR China and 3Southern Genomics Research Center, Guangzhou, Guangdong, PR China Email: Xia Chen - [email protected]; Shuang Liang - [email protected]; WenLing Zheng - [email protected]; ZhiJun Liao - [email protected]; Tao Shang - [email protected]; WenLi Ma* - [email protected] * Corresponding author †Equal contributors Published: 7 July 2008 Received: 16 February 2008 Accepted: 7 July 2008 BMC Genomics 2008, 9:322 doi:10.1186/1471-2164-9-322 This article is available from: http://www.biomedcentral.com/1471-2164/9/322 © 2008 Chen et al; licensee BioMed Central Ltd. This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. Abstract Background: Epstein-Barr virus (EBV) presumably plays an important role in the pathogenesis of nasopharyngeal carcinoma (NPC), but the molecular mechanism of EBV-dependent neoplastic transformation is not well understood. The combination of bioinformatics with evidences from biological experiments paved a new way to gain more insights into the molecular mechanism of cancer. Results: We profiled gene expression using a meta-analysis approach. Two sets of meta-genes were obtained. Meta-A genes were identified by finding those commonly activated/deactivated upon EBV infection/reactivation. -

Genetic and Genomic Analysis of Hyperlipidemia, Obesity and Diabetes Using (C57BL/6J × TALLYHO/Jngj) F2 Mice
University of Tennessee, Knoxville TRACE: Tennessee Research and Creative Exchange Nutrition Publications and Other Works Nutrition 12-19-2010 Genetic and genomic analysis of hyperlipidemia, obesity and diabetes using (C57BL/6J × TALLYHO/JngJ) F2 mice Taryn P. Stewart Marshall University Hyoung Y. Kim University of Tennessee - Knoxville, [email protected] Arnold M. Saxton University of Tennessee - Knoxville, [email protected] Jung H. Kim Marshall University Follow this and additional works at: https://trace.tennessee.edu/utk_nutrpubs Part of the Animal Sciences Commons, and the Nutrition Commons Recommended Citation BMC Genomics 2010, 11:713 doi:10.1186/1471-2164-11-713 This Article is brought to you for free and open access by the Nutrition at TRACE: Tennessee Research and Creative Exchange. It has been accepted for inclusion in Nutrition Publications and Other Works by an authorized administrator of TRACE: Tennessee Research and Creative Exchange. For more information, please contact [email protected]. Stewart et al. BMC Genomics 2010, 11:713 http://www.biomedcentral.com/1471-2164/11/713 RESEARCH ARTICLE Open Access Genetic and genomic analysis of hyperlipidemia, obesity and diabetes using (C57BL/6J × TALLYHO/JngJ) F2 mice Taryn P Stewart1, Hyoung Yon Kim2, Arnold M Saxton3, Jung Han Kim1* Abstract Background: Type 2 diabetes (T2D) is the most common form of diabetes in humans and is closely associated with dyslipidemia and obesity that magnifies the mortality and morbidity related to T2D. The genetic contribution to human T2D and related metabolic disorders is evident, and mostly follows polygenic inheritance. The TALLYHO/ JngJ (TH) mice are a polygenic model for T2D characterized by obesity, hyperinsulinemia, impaired glucose uptake and tolerance, hyperlipidemia, and hyperglycemia. -

Genome-Wide DNA Methylation Analysis of KRAS Mutant Cell Lines Ben Yi Tew1,5, Joel K
www.nature.com/scientificreports OPEN Genome-wide DNA methylation analysis of KRAS mutant cell lines Ben Yi Tew1,5, Joel K. Durand2,5, Kirsten L. Bryant2, Tikvah K. Hayes2, Sen Peng3, Nhan L. Tran4, Gerald C. Gooden1, David N. Buckley1, Channing J. Der2, Albert S. Baldwin2 ✉ & Bodour Salhia1 ✉ Oncogenic RAS mutations are associated with DNA methylation changes that alter gene expression to drive cancer. Recent studies suggest that DNA methylation changes may be stochastic in nature, while other groups propose distinct signaling pathways responsible for aberrant methylation. Better understanding of DNA methylation events associated with oncogenic KRAS expression could enhance therapeutic approaches. Here we analyzed the basal CpG methylation of 11 KRAS-mutant and dependent pancreatic cancer cell lines and observed strikingly similar methylation patterns. KRAS knockdown resulted in unique methylation changes with limited overlap between each cell line. In KRAS-mutant Pa16C pancreatic cancer cells, while KRAS knockdown resulted in over 8,000 diferentially methylated (DM) CpGs, treatment with the ERK1/2-selective inhibitor SCH772984 showed less than 40 DM CpGs, suggesting that ERK is not a broadly active driver of KRAS-associated DNA methylation. KRAS G12V overexpression in an isogenic lung model reveals >50,600 DM CpGs compared to non-transformed controls. In lung and pancreatic cells, gene ontology analyses of DM promoters show an enrichment for genes involved in diferentiation and development. Taken all together, KRAS-mediated DNA methylation are stochastic and independent of canonical downstream efector signaling. These epigenetically altered genes associated with KRAS expression could represent potential therapeutic targets in KRAS-driven cancer. Activating KRAS mutations can be found in nearly 25 percent of all cancers1. -

Supplemental Information
Supplemental information Dissection of the genomic structure of the miR-183/96/182 gene. Previously, we showed that the miR-183/96/182 cluster is an intergenic miRNA cluster, located in a ~60-kb interval between the genes encoding nuclear respiratory factor-1 (Nrf1) and ubiquitin-conjugating enzyme E2H (Ube2h) on mouse chr6qA3.3 (1). To start to uncover the genomic structure of the miR- 183/96/182 gene, we first studied genomic features around miR-183/96/182 in the UCSC genome browser (http://genome.UCSC.edu/), and identified two CpG islands 3.4-6.5 kb 5’ of pre-miR-183, the most 5’ miRNA of the cluster (Fig. 1A; Fig. S1 and Seq. S1). A cDNA clone, AK044220, located at 3.2-4.6 kb 5’ to pre-miR-183, encompasses the second CpG island (Fig. 1A; Fig. S1). We hypothesized that this cDNA clone was derived from 5’ exon(s) of the primary transcript of the miR-183/96/182 gene, as CpG islands are often associated with promoters (2). Supporting this hypothesis, multiple expressed sequences detected by gene-trap clones, including clone D016D06 (3, 4), were co-localized with the cDNA clone AK044220 (Fig. 1A; Fig. S1). Clone D016D06, deposited by the German GeneTrap Consortium (GGTC) (http://tikus.gsf.de) (3, 4), was derived from insertion of a retroviral construct, rFlpROSAβgeo in 129S2 ES cells (Fig. 1A and C). The rFlpROSAβgeo construct carries a promoterless reporter gene, the β−geo cassette - an in-frame fusion of the β-galactosidase and neomycin resistance (Neor) gene (5), with a splicing acceptor (SA) immediately upstream, and a polyA signal downstream of the β−geo cassette (Fig. -

Análise Integrativa De Perfis Transcricionais De Pacientes Com
UNIVERSIDADE DE SÃO PAULO FACULDADE DE MEDICINA DE RIBEIRÃO PRETO PROGRAMA DE PÓS-GRADUAÇÃO EM GENÉTICA ADRIANE FEIJÓ EVANGELISTA Análise integrativa de perfis transcricionais de pacientes com diabetes mellitus tipo 1, tipo 2 e gestacional, comparando-os com manifestações demográficas, clínicas, laboratoriais, fisiopatológicas e terapêuticas Ribeirão Preto – 2012 ADRIANE FEIJÓ EVANGELISTA Análise integrativa de perfis transcricionais de pacientes com diabetes mellitus tipo 1, tipo 2 e gestacional, comparando-os com manifestações demográficas, clínicas, laboratoriais, fisiopatológicas e terapêuticas Tese apresentada à Faculdade de Medicina de Ribeirão Preto da Universidade de São Paulo para obtenção do título de Doutor em Ciências. Área de Concentração: Genética Orientador: Prof. Dr. Eduardo Antonio Donadi Co-orientador: Prof. Dr. Geraldo A. S. Passos Ribeirão Preto – 2012 AUTORIZO A REPRODUÇÃO E DIVULGAÇÃO TOTAL OU PARCIAL DESTE TRABALHO, POR QUALQUER MEIO CONVENCIONAL OU ELETRÔNICO, PARA FINS DE ESTUDO E PESQUISA, DESDE QUE CITADA A FONTE. FICHA CATALOGRÁFICA Evangelista, Adriane Feijó Análise integrativa de perfis transcricionais de pacientes com diabetes mellitus tipo 1, tipo 2 e gestacional, comparando-os com manifestações demográficas, clínicas, laboratoriais, fisiopatológicas e terapêuticas. Ribeirão Preto, 2012 192p. Tese de Doutorado apresentada à Faculdade de Medicina de Ribeirão Preto da Universidade de São Paulo. Área de Concentração: Genética. Orientador: Donadi, Eduardo Antonio Co-orientador: Passos, Geraldo A. 1. Expressão gênica – microarrays 2. Análise bioinformática por module maps 3. Diabetes mellitus tipo 1 4. Diabetes mellitus tipo 2 5. Diabetes mellitus gestacional FOLHA DE APROVAÇÃO ADRIANE FEIJÓ EVANGELISTA Análise integrativa de perfis transcricionais de pacientes com diabetes mellitus tipo 1, tipo 2 e gestacional, comparando-os com manifestações demográficas, clínicas, laboratoriais, fisiopatológicas e terapêuticas. -

Role of RUNX1 in Aberrant Retinal Angiogenesis Jonathan D
Page 1 of 25 Diabetes Identification of RUNX1 as a mediator of aberrant retinal angiogenesis Short Title: Role of RUNX1 in aberrant retinal angiogenesis Jonathan D. Lam,†1 Daniel J. Oh,†1 Lindsay L. Wong,1 Dhanesh Amarnani,1 Cindy Park- Windhol,1 Angie V. Sanchez,1 Jonathan Cardona-Velez,1,2 Declan McGuone,3 Anat O. Stemmer- Rachamimov,3 Dean Eliott,4 Diane R. Bielenberg,5 Tave van Zyl,4 Lishuang Shen,1 Xiaowu Gai,6 Patricia A. D’Amore*,1,7 Leo A. Kim*,1,4 Joseph F. Arboleda-Velasquez*1 Author affiliations: 1Schepens Eye Research Institute/Massachusetts Eye and Ear, Department of Ophthalmology, Harvard Medical School, 20 Staniford St., Boston, MA 02114 2Universidad Pontificia Bolivariana, Medellin, Colombia, #68- a, Cq. 1 #68305, Medellín, Antioquia, Colombia 3C.S. Kubik Laboratory for Neuropathology, Massachusetts General Hospital, 55 Fruit St., Boston, MA 02114 4Retina Service, Massachusetts Eye and Ear Infirmary, Department of Ophthalmology, Harvard Medical School, 243 Charles St., Boston, MA 02114 5Vascular Biology Program, Boston Children’s Hospital, Department of Surgery, Harvard Medical School, 300 Longwood Ave., Boston, MA 02115 6Center for Personalized Medicine, Children’s Hospital Los Angeles, Los Angeles, 4650 Sunset Blvd, Los Angeles, CA 90027, USA 7Department of Pathology, Harvard Medical School, 25 Shattuck St., Boston, MA 02115 Corresponding authors: Joseph F. Arboleda-Velasquez: [email protected] Ph: (617) 912-2517 Leo Kim: [email protected] Ph: (617) 912-2562 Patricia D’Amore: [email protected] Ph: (617) 912-2559 Fax: (617) 912-0128 20 Staniford St. Boston MA, 02114 † These authors contributed equally to this manuscript Word Count: 1905 Tables and Figures: 4 Diabetes Publish Ahead of Print, published online April 11, 2017 Diabetes Page 2 of 25 Abstract Proliferative diabetic retinopathy (PDR) is a common cause of blindness in the developed world’s working adult population, and affects those with type 1 and type 2 diabetes mellitus. -

Identification of Potential Key Genes and Pathway Linked with Sporadic Creutzfeldt-Jakob Disease Based on Integrated Bioinformatics Analyses
medRxiv preprint doi: https://doi.org/10.1101/2020.12.21.20248688; this version posted December 24, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted medRxiv a license to display the preprint in perpetuity. All rights reserved. No reuse allowed without permission. Identification of potential key genes and pathway linked with sporadic Creutzfeldt-Jakob disease based on integrated bioinformatics analyses Basavaraj Vastrad1, Chanabasayya Vastrad*2 , Iranna Kotturshetti 1. Department of Biochemistry, Basaveshwar College of Pharmacy, Gadag, Karnataka 582103, India. 2. Biostatistics and Bioinformatics, Chanabasava Nilaya, Bharthinagar, Dharwad 580001, Karanataka, India. 3. Department of Ayurveda, Rajiv Gandhi Education Society`s Ayurvedic Medical College, Ron, Karnataka 562209, India. * Chanabasayya Vastrad [email protected] Ph: +919480073398 Chanabasava Nilaya, Bharthinagar, Dharwad 580001 , Karanataka, India NOTE: This preprint reports new research that has not been certified by peer review and should not be used to guide clinical practice. medRxiv preprint doi: https://doi.org/10.1101/2020.12.21.20248688; this version posted December 24, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted medRxiv a license to display the preprint in perpetuity. All rights reserved. No reuse allowed without permission. Abstract Sporadic Creutzfeldt-Jakob disease (sCJD) is neurodegenerative disease also called prion disease linked with poor prognosis. The aim of the current study was to illuminate the underlying molecular mechanisms of sCJD. The mRNA microarray dataset GSE124571 was downloaded from the Gene Expression Omnibus database. Differentially expressed genes (DEGs) were screened. -
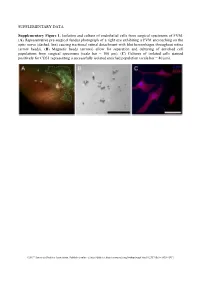
Supplementary Figures and Tables
SUPPLEMENTARY DATA Supplementary Figure 1. Isolation and culture of endothelial cells from surgical specimens of FVM. (A) Representative pre-surgical fundus photograph of a right eye exhibiting a FVM encroaching on the optic nerve (dashed line) causing tractional retinal detachment with blot hemorrhages throughout retina (arrow heads). (B) Magnetic beads (arrows) allow for separation and culturing of enriched cell populations from surgical specimens (scale bar = 100 μm). (C) Cultures of isolated cells stained positively for CD31 representing a successfully isolated enriched population (scale bar = 40 μm). ©2017 American Diabetes Association. Published online at http://diabetes.diabetesjournals.org/lookup/suppl/doi:10.2337/db16-1035/-/DC1 SUPPLEMENTARY DATA Supplementary Figure 2. Efficient siRNA knockdown of RUNX1 expression and function demonstrated by qRT-PCR, Western Blot, and scratch assay. (A) RUNX1 siRNA induced a 60% reduction of RUNX1 expression measured by qRT-PCR 48 hrs post-transfection whereas expression of RUNX2 and RUNX3, the two other mammalian RUNX orthologues, showed no significant changes, indicating specificity of our siRNA. Functional inhibition of Runx1 signaling was demonstrated by a 330% increase in insulin-like growth factor binding protein-3 (IGFBP3) RNA expression level, a known target of RUNX1 inhibition. Western blot demonstrated similar reduction in protein levels. (B) siRNA- 2’s effect on RUNX1 was validated by qRT-PCR and western blot, demonstrating a similar reduction in both RNA and protein. Scratch assay demonstrates functional inhibition of RUNX1 by siRNA-2. ns: not significant, * p < 0.05, *** p < 0.001 ©2017 American Diabetes Association. Published online at http://diabetes.diabetesjournals.org/lookup/suppl/doi:10.2337/db16-1035/-/DC1 SUPPLEMENTARY DATA Supplementary Table 1. -

Identification of Eight Genes Encoding Chemokine-Like
中国科技论文在线 http://www.paper.edu.cn Genomics 81 (2003) 609–617 Identification of eight genes encoding chemokine-like factor superfamily members 1–8 (CKLFSF1–8) by in silico cloning and experimental validation૾ Wenling Han,1 Peiguo Ding,1 Mingxu Xu, Lu Wang, Min Rui, Shuang Shi, Yanan Liu, Ying Zheng, Yingyu Chen, Tian Yang, and Dalong Ma* Center for Human Disease Genomics, Peking University, 38 Xueyuan Road, Beijing 100083, China Received 21 November 2002; accepted 14 March 2003 Abstract TM4SF11 is only 102 kb from the chemokine gene cluster composed of SCYA22, SCYD1, and SCYA17 on chromosome 16q13. CKLF maps on chromosome 16q22. CKLFs have some characteristics associated with the CCL22/MDC, CX3CL1/fractalkine, CCL17/TARC, and TM4SF proteins. Bioinformatics based on CKLF2 cDNA and protein sequences in combination with experimental validation identified eight novel genes designated chemokine-like factor superfamily members 1–8 (CKLFSF1–8). CKLFSF1–8 form gene clusters; the sequence identities between CKLF2 and CKLFSF1–8 are from 12.5 to 39.7%. Most of the CKLFSFs have alternative RNA splicing forms. CKLFSF1 has a CC motif and higher sequence similarity with chemokines than with any of the other CKLFSFs. CKLFSF8 shares 39.3% amino acid identity with TM4SF11. CKLFSF1 links the CKLFSF family with chemokines, and CKLFSF8 links it with TM4SF. The characteristics of CKLFSF2–7 are intermediate between CKLFSF1 and CKLFSF8. This indicates that CKLFSF represents a novel gene family between the SCY and the TM4SF gene families. © 2003 Elsevier Science (USA). All rights reserved. Keywords: CKLF; CKLFSF; Bioinformatics; Gene cluster; Chemokine; TM4SF11 Chemokines are small, secreted proteins that can be CXC chemokines (CXCL1–16), 2 C chemokines (XCL1– subdivided according to their NH2-terminal cysteine-motif 2), and one CX3C chemokine (CX3CL1/fractalkine) iden- into the CC, CXC, C, and CX3C classes. -

MOCHI Enables Discovery of Heterogeneous Interactome Modules in 3D Nucleome
Downloaded from genome.cshlp.org on October 4, 2021 - Published by Cold Spring Harbor Laboratory Press MOCHI enables discovery of heterogeneous interactome modules in 3D nucleome Dechao Tian1,# , Ruochi Zhang1,# , Yang Zhang1, Xiaopeng Zhu1, and Jian Ma1,* 1Computational Biology Department, School of Computer Science, Carnegie Mellon University, Pittsburgh, PA 15213, USA #These two authors contributed equally *Correspondence: [email protected] Contact To whom correspondence should be addressed: Jian Ma School of Computer Science Carnegie Mellon University 7705 Gates-Hillman Complex 5000 Forbes Avenue Pittsburgh, PA 15213 Phone: +1 (412) 268-2776 Email: [email protected] 1 Downloaded from genome.cshlp.org on October 4, 2021 - Published by Cold Spring Harbor Laboratory Press Abstract The composition of the cell nucleus is highly heterogeneous, with different constituents forming complex interactomes. However, the global patterns of these interwoven heterogeneous interactomes remain poorly understood. Here we focus on two different interactomes, chromatin interaction network and gene regulatory network, as a proof-of-principle, to identify heterogeneous interactome modules (HIMs), each of which represents a cluster of gene loci that are in spatial contact more frequently than expected and that are regulated by the same group of transcription factors. HIM integrates transcription factor binding and 3D genome structure to reflect “transcriptional niche” in the nucleus. We develop a new algorithm MOCHI to facilitate the discovery of HIMs based on network motif clustering in heterogeneous interactomes. By applying MOCHI to five different cell types, we found that HIMs have strong spatial preference within the nucleus and exhibit distinct functional properties. Through integrative analysis, this work demonstrates the utility of MOCHI to identify HIMs, which may provide new perspectives on the interplay between transcriptional regulation and 3D genome organization.