Identification of the YES1 Kinase As a Therapeutic Target in Basal-Like
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

In Vivo Imaging of Tgfβ Signalling Components Using Positron
REVIEWS Drug Discovery Today Volume 24, Number 12 December 2019 Reviews KEYNOTE REVIEW In vivo imaging of TGFb signalling components using positron emission tomography 1 1 2 Lonneke Rotteveel Lonneke Rotteveel , Alex J. Poot , Harm Jan Bogaard , received her MSc in drug 3 1 discovery and safety at the Peter ten Dijke , Adriaan A. Lammertsma and VU University in 1 Amsterdam. She is Albert D. Windhorst currently finishing her PhD at the VU University 1 Department of Radiology and Nuclear Medicine, Amsterdam UMC, location VUmc, Amsterdam, The Netherlands Medical Center (VUmc) 2 under the supervision of A. Pulmonary Medicine, Institute for Cardiovascular Research, Amsterdam UMC, location VUmc, Amsterdam, The Netherlands D. Windhorst and Adriaan A. Lammertsma. Her 3 research interest is on the development of positron Department of Cell and Chemical Biology, Oncode Institute, Leiden University Medical Center, Leiden, The emission tomography (PET) tracers that target Netherlands selectively the activin receptor-like kinase 5 in vitro and in vivo. Alex J. Poot obtained his The transforming growth factor b (TGFb) family of cytokines achieves PhD in medicinal chemistry homeostasis through a careful balance and crosstalk with complex from Utrecht University. As postdoctoral researcher at signalling pathways. Inappropriate activation or inhibition of this pathway the VUmc, Amsterdam, he and mutations in its components are related to diseases such as cancer, developed radiolabelled anticancer drugs for PET vascular diseases, and developmental disorders. Quantitative imaging of imaging. In 2014, he accepted a research expression levels of key regulators within this pathway using positron fellowship from Memorial Sloan Kettering Cancer 13 emission tomography (PET) can provide insights into the role of this Center, New York to develop C-labelled probes for tumour metabolism imaging with magnetic resonance in vivo pathway , providing information on underlying pathophysiological imaging (MRI). -

YES1 Amplification Is a Mechanism of Acquired Resistance to EGFR Inhibitors Identified by Transposon Mutagenesis and Clinical Genomics
YES1 amplification is a mechanism of acquired resistance to EGFR inhibitors identified by transposon mutagenesis and clinical genomics Pang-Dian Fana,b,1, Giuseppe Narzisic, Anitha D. Jayaprakashd,2, Elisa Venturinie,3, Nicolas Robinec, Peter Smibertd, Soren Germerf, Helena A. Yug, Emmet J. Jordang,4, Paul K. Paikg, Yelena Y. Janjigiang, Jamie E. Chaftg, Lu Wanga,5, Achim A. Jungblutha, Sumit Middhaa, Lee Spraggona,b,6, Huan Qiaoh, Christine M. Lovlyh, Mark G. Krisg, Gregory J. Rielyg, Katerina Politii, Harold Varmusj,1,7, and Marc Ladanyia,b,1 aDepartment of Pathology, Memorial Sloan Kettering Cancer Center, New York, NY 10065; bHuman Oncology and Pathogenesis Program, Memorial Sloan Kettering Cancer Center, New York, NY 10065; cComputational Biology, New York Genome Center, New York, NY 10013; dTechnology Innovation Lab, New York Genome Center, New York, NY 10013; eProject Management, New York Genome Center, New York, NY 10013; fSequencing Operations, New York Genome Center, New York, NY 10013; gDivision of Solid Tumor Oncology, Department of Medicine, Memorial Sloan Kettering Cancer Center, New York, NY 10065; hVanderbilt–Ingram Cancer Center, Vanderbilt University School of Medicine, Nashville, TN 37232; iDepartment of Pathology and the Yale Cancer Center, Yale University School of Medicine, New Haven, CT 06520; and jCancer Biology and Genetics Program, Sloan Kettering Institute, Memorial Sloan Kettering Cancer Center, New York, NY 10065 Contributed by Harold Varmus, May 8, 2018 (sent for review October 12, 2017; reviewed by Levi Garraway and Alice T. Shaw) In ∼30% of patients with EGFR-mutant lung adenocarcinomas quired resistance to first-generation EGFR TKIs, the underlying whose disease progresses on EGFR inhibitors, the basis for ac- mechanisms still remain to be identified. -

Src-Family Kinases Impact Prognosis and Targeted Therapy in Flt3-ITD+ Acute Myeloid Leukemia
Src-Family Kinases Impact Prognosis and Targeted Therapy in Flt3-ITD+ Acute Myeloid Leukemia Title Page by Ravi K. Patel Bachelor of Science, University of Minnesota, 2013 Submitted to the Graduate Faculty of School of Medicine in partial fulfillment of the requirements for the degree of Doctor of Philosophy University of Pittsburgh 2019 Commi ttee Membership Pa UNIVERSITY OF PITTSBURGH SCHOOL OF MEDICINE Commi ttee Membership Page This dissertation was presented by Ravi K. Patel It was defended on May 31, 2019 and approved by Qiming (Jane) Wang, Associate Professor Pharmacology and Chemical Biology Vaughn S. Cooper, Professor of Microbiology and Molecular Genetics Adrian Lee, Professor of Pharmacology and Chemical Biology Laura Stabile, Research Associate Professor of Pharmacology and Chemical Biology Thomas E. Smithgall, Dissertation Director, Professor and Chair of Microbiology and Molecular Genetics ii Copyright © by Ravi K. Patel 2019 iii Abstract Src-Family Kinases Play an Important Role in Flt3-ITD Acute Myeloid Leukemia Prognosis and Drug Efficacy Ravi K. Patel, PhD University of Pittsburgh, 2019 Abstract Acute myelogenous leukemia (AML) is a disease characterized by undifferentiated bone-marrow progenitor cells dominating the bone marrow. Currently the five-year survival rate for AML patients is 27.4 percent. Meanwhile the standard of care for most AML patients has not changed for nearly 50 years. We now know that AML is a genetically heterogeneous disease and therefore it is unlikely that all AML patients will respond to therapy the same way. Upregulation of protein-tyrosine kinase signaling pathways is one common feature of some AML tumors, offering opportunities for targeted therapy. -

Anti-Yes1 Picoband Antibody Catalog # ABO12155
10320 Camino Santa Fe, Suite G San Diego, CA 92121 Tel: 858.875.1900 Fax: 858.622.0609 Anti-Yes1 Picoband Antibody Catalog # ABO12155 Specification Anti-Yes1 Picoband Antibody - Product Information Application WB, IHC Primary Accession P07947 Host Rabbit Reactivity Human Clonality Polyclonal Format Lyophilized Description Rabbit IgG polyclonal antibody for Tyrosine-protein kinase Yes(YES1) detection. Tested with WB, IHC-P in Human. Reconstitution Add 0.2ml of distilled water will yield a concentration of 500ug/ml. Anti- YES1 Picoband antibody, ABO12155, Anti-Yes1 Picoband Antibody - Additional Western blottingAll lanes: Anti YES1 Information (ABO12155) at 0.5ug/mlLane 1: SGC Whole Cell Lysate at 40ugLane 2: A549 Whole Cell Lysate at 40ugLane 3: HEPG2 Whole Cell Gene ID 7525 Lysate at 40ugPredicted bind size: Other Names 61KDObserved bind size: 61KD Tyrosine-protein kinase Yes, 2.7.10.2, Proto-oncogene c-Yes, p61-Yes, YES1, YES Calculated MW 60801 MW KDa Application Details Immunohistochemistry(Paraffin-embedded Section), 0.5-1 µg/ml, Human, By Heat<br>Western blot, 0.1-0.5 µg/ml, Human<br> Subcellular Localization Cell membrane. Cytoplasm, cytoskeleton, microtubule organizing center, centrosome. Anti- YES1 Picoband antibody, Cytoplasm, cytosol. Newly synthesized ABO12155,IHC(P)IHC(P): Human Mammary protein initially accumulates in the Golgi Cancer Tissue region and traffics to the plasma membrane through the exocytic pathway. Anti-Yes1 Picoband Antibody - Background Tissue Specificity Expressed in the epithelial cells of renal Proto-oncogene tyrosine-protein kinase Yes is proximal tubules and stomach as well as an enzyme that in humans is encoded by the Page 1/3 10320 Camino Santa Fe, Suite G San Diego, CA 92121 Tel: 858.875.1900 Fax: 858.622.0609 hematopoietic cells in the bone marrow and YES1 gene. -

Human TGF Beta Receptor 2 ELISA Kit (ARG81882)
Product datasheet [email protected] ARG81882 Package: 96 wells Human TGF beta Receptor 2 ELISA Kit Store at: 4°C Component Cat. No. Component Name Package Temp ARG81882-001 Antibody-coated 8 X 12 strips 4°C. Unused strips microplate should be sealed tightly in the air-tight pouch. ARG81882-002 Standard 2 X 10 ng/vial 4°C ARG81882-003 Standard/Sample 30 ml (Ready to use) 4°C diluent ARG81882-004 Antibody conjugate 1 vial (100 µl) 4°C concentrate (100X) ARG81882-005 Antibody diluent 12 ml (Ready to use) 4°C buffer ARG81882-006 HRP-Streptavidin 1 vial (100 µl) 4°C concentrate (100X) ARG81882-007 HRP-Streptavidin 12 ml (Ready to use) 4°C diluent buffer ARG81882-008 25X Wash buffer 20 ml 4°C ARG81882-009 TMB substrate 10 ml (Ready to use) 4°C (Protect from light) ARG81882-010 STOP solution 10 ml (Ready to use) 4°C ARG81882-011 Plate sealer 4 strips Room temperature Summary Product Description ARG81882 Human TGF beta Receptor 2 ELISA Kit is an Enzyme Immunoassay kit for the quantification of Human TGF beta Receptor 2 in serum, plasma (heparin, EDTA) and cell culture supernatants. Tested Reactivity Hu Tested Application ELISA Specificity There is no detectable cross-reactivity with other relevant proteins. Target Name TGF beta Receptor 2 Conjugation HRP Conjugation Note Substrate: TMB and read at 450 nm. Sensitivity 7.8 pg/ml Sample Type Serum, plasma (heparin, EDTA) and cell culture supernatants. Standard Range 15.6 - 1000 pg/ml Sample Volume 100 µl www.arigobio.com 1/3 Precision Intra-Assay CV: 5.3%; Inter-Assay CV: 6.0% Alternate Names FAA3; AAT3; TbetaR-II; TGF-beta receptor type-2; LDS2B; MFS2; TGF-beta type II receptor; EC 2.7.11.30; TAAD2; TGFR-2; LDS2; Transforming growth factor-beta receptor type II; TGFbeta-RII; TGF-beta receptor type II; RIIC; LDS1B Application Instructions Assay Time ~ 5 hours Properties Form 96 well Storage instruction Store the kit at 2-8°C. -

A Cytokine Protein-Protein Interaction Network for Identifying Key Molecules in Rheumatoid Arthritis
RESEARCH ARTICLE A cytokine protein-protein interaction network for identifying key molecules in rheumatoid arthritis Venugopal Panga1,2, Srivatsan Raghunathan1* 1 Institute of Bioinformatics and Applied Biotechnology (IBAB), Biotech Park, Electronics City Phase I, Bengaluru, Karnataka, India, 2 Manipal Academy of Higher Education, Manipal, Karnataka, India * [email protected] a1111111111 a1111111111 a1111111111 a1111111111 Abstract a1111111111 Rheumatoid arthritis (RA) is a chronic inflammatory disease of the synovial joints. Though the current RA therapeutics such as disease-modifying antirheumatic drugs (DMARDs), nonsteroidal anti-inflammatory drugs (NSAIDs) and biologics can halt the progression of the disease, none of these would either dramatically reduce or cure RA. So, the identification of OPEN ACCESS potential therapeutic targets and new therapies for RA are active areas of research. Several Citation: Panga V, Raghunathan S (2018) A studies have discovered the involvement of cytokines in the pathogenesis of this disease. cytokine protein-protein interaction network for identifying key molecules in rheumatoid arthritis. These cytokines induce signal transduction pathways in RA synovial fibroblasts (RASF). PLoS ONE 13(6): e0199530. https://doi.org/ These pathways share many signal transducers and their interacting proteins, resulting in 10.1371/journal.pone.0199530 the formation of a signaling network. In order to understand the involvement of this network Editor: Hua Zhou, Macau University of Science and in RA pathogenesis, it is essential to identify the key transducers and their interacting pro- Technology, MACAO teins that are part of this network. In this study, based on a detailed literature survey, we Received: August 21, 2017 have identified a list of 12 cytokines that induce signal transduction pathways in RASF. -
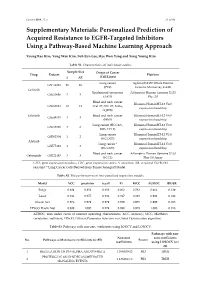
Personalized Prediction of Acquired Resistance to EGFR-Targeted Inhibitors Using a Pathway-Based Machine Learning Approach
Cancers 2019, 11, x S1 of S9 Supplementary Materials: Personalized Prediction of Acquired Resistance to EGFR-Targeted Inhibitors Using a Pathway-Based Machine Learning Approach Young Rae Kim, Yong Wan Kim, Suh Eun Lee, Hye Won Yang and Sung Young Kim Table S1. Characteristics of individual studies. Sample Size Origin of Cancer Drug Dataset Platform S AR (Cell Lines) Lung cancer Agilent-014850 Whole Human GSE34228 26 26 (PC9) Genome Microarray 4x44K Gefitinib Epidermoid carcinoma Affymetrix Human Genome U133 GSE10696 3 3 (A431) Plus 2.0 Head and neck cancer Illumina HumanHT-12 V4.0 GSE62061 12 12 (Cal-27, SSC-25, FaDu, expression beadchip SQ20B) Erlotinib Head and neck cancer Illumina HumanHT-12 V4.0 GSE49135 3 3 (HN5) expression beadchip Lung cancer (HCC827, Illumina HumanHT-12 V3.0 GSE38310 3 6 ER3, T15-2) expression beadchip Lung cancer Illumina HumanHT-12 V3.0 GSE62504 1 2 (HCC827) expression beadchip Afatinib Lung cancer * Illumina HumanHT-12 V4.0 GSE75468 1 3 (HCC827) expression beadchip Head and neck cancer Affymetrix Human Genome U133 Cetuximab GSE21483 3 3 (SCC1) Plus 2.0 Array GEO, gene expression omnibus; GSE, gene expression series; S, sensitive; AR, acquired EGFR-TKI resistant; * Lung Cancer Cells Derived from Tumor Xenograft Model. Table S2. The performances of four penalized regression models. Model ACC precision recall F1 MCC AUROC BRIER Ridge 0.889 0.852 0.958 0.902 0.782 0.964 0.129 Lasso 0.944 0.957 0.938 0.947 0.889 0.991 0.042 Elastic Net 0.978 0.979 0.979 0.979 0.955 0.999 0.023 EPSGO Elastic Net 0.989 1.000 0.979 0.989 0.978 1.000 0.018 AUROC, area under curve of receiver operating characteristic; ACC, accuracy; MCC, Matthews correlation coefficient; EPSGO, Efficient Parameter Selection via Global Optimization algorithm. -

(51) International Patent Classification: C12N 5/0783 (2010.01) A61K 35/1 7 (2015.01) Declarations Under Rule 4.17: C12N 5/10 (2
( (51) International Patent Classification: Declarations under Rule 4.17: C12N 5/0783 (2010.01) A61K 35/1 7 (2015.01) — as to applicant's entitlement to apply for and be granted a C12N 5/10 (2006.01) A61P 35/00 (2006.01) patent (Rule 4.17(H)) (21) International Application Number: — as to the applicant's entitlement to claim the priority of the PCT/US2020/0 18443 earlier application (Rule 4.17(iii)) (22) International Filing Date: Published: 14 February 2020 (14.02.2020) — with international search report (Art. 21(3)) — before the expiration of the time limit for amending the (25) Filing Language: English claims and to be republished in the event of receipt of (26) Publication Language: English amendments (Rule 48.2(h)) (30) Priority Data: 62/806,457 15 February 2019 (15.02.2019) US 62/841,066 30 April 2019 (30.04.2019) US 62/841,684 0 1 May 2019 (01.05.2019) US 62/943,649 04 December 2019 (04. 12.2019) US (71) Applicant: EDITAS MEDICINE, INC. [US/US] ; 11Hur¬ ley Street, Cambridge, MA 02141 (US). (72) Inventors: WELSTEAD, Gordon, Grant; 12 Devon Ter¬ race, Newton, MA 02459 (US). BORGES, Christopher; 2 1 Cumberland Rd Reading, MA 01867 (US). WONG, Karrie, Kawai; 20 Warwick Street, Unit 3, Somerville, MA 02145 (US). (74) Agent: ZACHARAKIS, Maria, Laccotripe et a ; Mc¬ Carter & English, LLP, 265 Franklin Street, Boston, MA 021 10 (US). (81) Designated States (unless otherwise indicated, for every kind of national protection available) : AE, AG, AL, AM, AO, AT, AU, AZ, BA, BB, BG, BH, BN, BR, BW, BY, BZ, CA, CH, CL, CN, CO, CR, CU, CZ, DE, DJ, DK, DM, DO, DZ, EC, EE, EG, ES, FI, GB, GD, GE, GH, GM, GT, HN, HR, HU, ID, IL, IN, IR, IS, JO, JP, KE, KG, KH, KN, KP, KR, KW, KZ, LA, LC, LK, LR, LS, LU, LY, MA, MD, ME, MG, MK, MN, MW, MX, MY, MZ, NA, NG, NI, NO, NZ, OM, PA, PE, PG, PH, PL, PT, QA, RO, RS, RU, RW, SA, SC, SD, SE, SG, SK, SL, ST, SV, SY, TH, TJ, TM, TN, TR, TT, TZ, UA, UG, US, UZ, VC, VN, WS, ZA, ZM, ZW. -

Protein Tyrosine Kinases: Their Roles and Their Targeting in Leukemia
cancers Review Protein Tyrosine Kinases: Their Roles and Their Targeting in Leukemia Kalpana K. Bhanumathy 1,*, Amrutha Balagopal 1, Frederick S. Vizeacoumar 2 , Franco J. Vizeacoumar 1,3, Andrew Freywald 2 and Vincenzo Giambra 4,* 1 Division of Oncology, College of Medicine, University of Saskatchewan, Saskatoon, SK S7N 5E5, Canada; [email protected] (A.B.); [email protected] (F.J.V.) 2 Department of Pathology and Laboratory Medicine, College of Medicine, University of Saskatchewan, Saskatoon, SK S7N 5E5, Canada; [email protected] (F.S.V.); [email protected] (A.F.) 3 Cancer Research Department, Saskatchewan Cancer Agency, 107 Wiggins Road, Saskatoon, SK S7N 5E5, Canada 4 Institute for Stem Cell Biology, Regenerative Medicine and Innovative Therapies (ISBReMIT), Fondazione IRCCS Casa Sollievo della Sofferenza, 71013 San Giovanni Rotondo, FG, Italy * Correspondence: [email protected] (K.K.B.); [email protected] (V.G.); Tel.: +1-(306)-716-7456 (K.K.B.); +39-0882-416574 (V.G.) Simple Summary: Protein phosphorylation is a key regulatory mechanism that controls a wide variety of cellular responses. This process is catalysed by the members of the protein kinase su- perfamily that are classified into two main families based on their ability to phosphorylate either tyrosine or serine and threonine residues in their substrates. Massive research efforts have been invested in dissecting the functions of tyrosine kinases, revealing their importance in the initiation and progression of human malignancies. Based on these investigations, numerous tyrosine kinase inhibitors have been included in clinical protocols and proved to be effective in targeted therapies for various haematological malignancies. -

Beclin 1 Regulates Neuronal Transforming Growth Factor-Β Signaling by Mediating Recycling of the Type I Receptor ALK5 Caitlin E
O’Brien et al. Molecular Neurodegeneration (2015) 10:69 DOI 10.1186/s13024-015-0065-0 RESEARCH ARTICLE Open Access Beclin 1 regulates neuronal transforming growth factor-β signaling by mediating recycling of the type I receptor ALK5 Caitlin E. O’Brien1,2,3, Liana Bonanno2,3,4, Hui Zhang2,3 and Tony Wyss-Coray2,3* Abstract Background: Beclin 1 is a key regulator of multiple trafficking pathways, including autophagy and receptor recycling in yeast and microglia. Decreased beclin 1 levels in the CNS result in neurodegeneration, an effect attributed to impaired autophagy. However, neurons also rely heavily on trophic factors, and signaling through these pathways requires the proper trafficking of trophic factor receptors. Results: We discovered that beclin 1 regulates signaling through the neuroprotective TGF-β pathway. Beclin 1 is required for recycling of the type I TGF-β receptor ALK5. We show that beclin 1 recruits the retromer to ALK5 and facilitates its localization to Rab11+ endosomes. Decreased levels of beclin 1, or its binding partners VPS34 and UVRAG, impair TGF-β signaling. Conclusions: These findings identify beclin 1 as a positive regulator of a trophic signaling pathway via receptor recycling, and suggest that neuronal death induced by decreased beclin 1 levels may also be due to impaired trophic factor signaling. Keywords: Beclin 1, VPS34, Retromer, TGF-β, ALK5, Protein sorting, Receptor recycling, Neurodegeneration Background Beclin 1 is highly expressed in the nervous system and Beclin 1 is a component of the type III is essential for neuronal survival. While beclin 1 knock- phosphatidylinositol-3-kinase (PI3K) complex. -

TBK1 Provides Context-Selective Support of the Activated AKT/Mtor Pathway in Lung
Author Manuscript Published OnlineFirst on July 17, 2017; DOI: 10.1158/0008-5472.CAN-17-0829 Author manuscripts have been peer reviewed and accepted for publication but have not yet been edited. TBK1 Provides Context-Selective Support of the Activated AKT/mTOR Pathway in Lung Cancer Jonathan M. Cooper1, Yi-Hung Ou1,2, Elizabeth A. McMillan1, Rachel M. Vaden1, Aubhishek Zaman1, Brian O. Bodemann1, Gurbani Makkar1, Bruce A. Posner3, and Michael A. White1* 1Department of Cell Biology, UT Southwestern Medical Center, Dallas, TX 75390, USA 2 Current address: Department of Pharmacology, Weill Cornell Medical College, New York, NY 10065, USA 3Department of Biochemistry, UT Southwestern Medical Center, Dallas, TX 75390, USA Running Title: KRAS-mutant subtype-specific addiction to TBK1 Key Words: TBK1; mTOR/AKT; KRAS; Mesenchymal; NSCLC Grant Support This work was supported by the National Institutes of Health (CA142543, UTSW Cancer Center Support Grant supporting B.A. Posner; CA071443, CA197717, and CA176284, awarded to M.A. White.) and The Welch Foundation (I-1414, awarded to M.A. White.). *Correspondence to: Michael A. White, Ph.D. Department of Cell Biology UT Southwestern Medical Center Dallas, TX 75390-9039 Phone: 214-648-4212; Fax: 214-648-5814; Email: [email protected] Downloaded from cancerres.aacrjournals.org on October 1, 2021. © 2017 American Association for Cancer Research. Author Manuscript Published OnlineFirst on July 17, 2017; DOI: 10.1158/0008-5472.CAN-17-0829 Author manuscripts have been peer reviewed and accepted for publication but have not yet been edited. Conflicts of Interest Disclosure: Michael A. White is currently Chief Scientific Officer and Vice President of Tumor Cell Biology at Pfizer, Inc. -

Oncogenic Potential of Bisphenol a and Common Environmental Contaminants in Human Mammary Epithelial Cells
International Journal of Molecular Sciences Article Oncogenic Potential of Bisphenol A and Common Environmental Contaminants in Human Mammary Epithelial Cells Vidhya A Nair 1 , Satu Valo 2, Päivi Peltomäki 2, Khuloud Bajbouj 1 and Wael M. Abdel-Rahman 1,3,* 1 Sharjah Institute for Medical Research, University of Sharjah, Sharjah P.O. Box 27272, UAE; [email protected] (V.A.N.); [email protected] (K.B.) 2 Department of Medical and Clinical Genetics, University of Helsinki, FI-00014 Helsinki, Finland; [email protected] (S.V.); paivi.peltomaki@helsinki.fi (P.P.) 3 Department of Medical Laboratory Sciences, College of Health Sciences, University of Sharjah, Sharjah P.O. Box 27272, UAE * Correspondence: [email protected]; Tel.: +971-65057556; Fax: +971-65057515 Received: 3 April 2020; Accepted: 19 May 2020; Published: 25 May 2020 Abstract: There is an ample epidemiological evidence to support the role of environmental contaminants such as bisphenol A (BPA) in breast cancer development but the molecular mechanisms of their action are still not fully understood. Therefore, we sought to analyze the effects of three common contaminants (BPA; 4-tert-octylphenol, OP; hexabromocyclododecane, HBCD) on mammary epithelial cell (HME1) and MCF7 breast cancer cell line. We also supplied some data on methoxychlor, MXC; 4-nonylphenol, NP; and 2-amino-1-methyl-6-phenylimidazo [4–b] pyridine, PhIP. We focused on testing the prolonged (two months) exposure to low nano-molar concentrations (0.0015–0.0048 nM) presumed to be oncogenic and found that they induced DNA damage (evidenced by upregulation of pH2A.X, pCHK1, pCHK2, p-P53) and disrupted the cell cycle.