JTTE-020003: Topics in Modern Computer Science
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Nook 1St Generation Or Nook Simpletouch, Sony Reader, Kobo)
How to Download eBooks to Your Black & White eInk eReader (Nook 1st Generation or Nook SimpleTouch, Sony Reader, Kobo) Warren Public Library You will need: . A Warren Public Library Card . PC or Mac computer . Black & White eReader (Nook 1st Generation or Nook . Adobe Digital Editions software SimpleTouch, Sony Reader, Kobo Reader) and a USB cable to attach it to your computer Note: Before you can checkout eBooks for your eReader, you will need to download and install Adobe Digital Editions. For instructions on how to do this, see page 3. 1. In a web browser on your computer, go to our OverDrive site at http://ebooks.mcls.org. 2. Near the upper right, click Sign In. Select Warren Public Library from the dropdown menu. Enter your Library card number. Click the green Sign In button. 3. Using the search box on the right-hand side, search for the title or author you are looking for. To narrow your results to titles usable by your eReader, in the left-hand side menu under Format click Adobe EPUB eBook. Click the title of the book you wish to checkout. 4. To check out your EPUB eBook, click “Borrow”. The EPUB eBook will be checked out to you. If the EPUB eBook is not currently available to be checked out, instead of saying “Borrow” it will say “Place a Hold”. To put an item on hold, click the “Place a Hold” button. Enter your email address in the boxes where indicated. You will get an email when the item is available to be checked out, and will have 72 hours from when the email is sent to checkout and download your hold. -

Instructions to View .Epub File .Epub File to Be Used on Devices Other Than Kindles, Or Devices Not Using the Kindle App
Instructions to view .ePUB file .ePUB file to be used on devices other than Kindles, or devices not using the Kindle app Please note, these instructions are a guide only. Your device, device set-up and e-reader may differ. If you are having trouble downloading or viewing the file, please refer to your manufacturer’s instructions for opening this type of file. Please be patient when downloading the file; to maintain the quality of the images throughout the book, the file size is quite large (87 MB) and, depending on your internet speed, it may take a while to download. To open .ePUB file on iPhone or iPad 1. Check that you have the iBooks or Apple Books app installed on your device. 2. Download or save the .ePUB file onto your device. 3. Navigate to the folder where you have saved the .ePUB file. 4. Hold down the icon for the .ePUB file. A menu should open which says ‘Open In’. Select iBooks or Apple Books. 5. The book should automatically open in iBooks or Apple Books for you to review. To open .ePUB file on Android device 1. Check that you have an e-reader app installed on your device, such as Google Play Books. 2. Download the .ePUB file. 3. Navigate to the downloaded .ePUB file. If using Google Play Books, tap ‘Upload to Play Books’ (other e-readers may differ). 4. You can then find the file in ‘My Library > Uploads’, and begin reading. To open .ePUB file on Windows PC 1. Ensure that you have an e-reader app installed on your computer, such as Adobe Digital Editions 2. -
Overdrive Ebook Troubleshooting
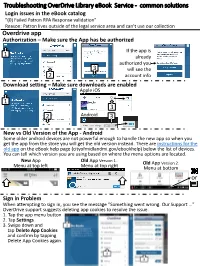
Troubleshooting OverDrive Library eBook Service - common solutions Login issues in the eBook catalog “(0) Failed Patron RPA Response validation” Reason: Patron lives outside of the legal service area and can’t use our collection Overdrive app Authorization – Make sure the App has be authorized If the app is 1 already authorized you 3 will see the 2 account info Download setting – Make sure downloads are enabled Apple iOS 1 3 2 Android 3 New vs Old Version of the App - Android Some older android devices are not powerful enough to handle the new app so when you get the app from the store you will get the old version instead. There are instructions for the old app on the eBook help page (cityofmidlandmi.gov/ebookhelp) below the list of devices. You can tell which version you are using based on where the menu options are located. New App Old App Version 1. Old App Version 2. Menu at top left Menu at top right Menu at bottom or Sign in Problem When attempting to sign in, you see the message “Something went wrong. Our Support …” OverDrive support suggests deleting app cookies to resolve the issue. 1. Tap the app menu button 2. Tap Settings 3. Swipe down and tap Delete App Cookies and confirm by tapping Delete App Cookies again. Kindle Devices Amazon account issues You need to use the same Amazon account that was used when the Kindle was registered When borrowing eBooks, Amazon will tie the title to what ever account is currently logged in on Amazon.com. -

Creating Great Ebooks Using Jutoh
CREATING GREAT EBOOKS USING JUTOH A complete guide to making ebooks for Kindle, iPad, Nook, Kobo and more, from new project to publication by Julian Smart Published by Anthemion © Julian Smart 2011 Edition 2.22 All rights reserved. You are welcome to redistribute this book in its original form. The author acknowledges the trademarked status and trademark owners of various products referenced in this work. This book was created using Jutoh. The author acknowledges the trademarked status and trademark owners of various products referenced in this work, which have been used without permission. The publication/use of these trademarks is not authorized, associated with, or sponsored by the trademark owners. Table of Contents From the Horse’s Mouth........................................................................................................................xi Preface...................................................................................................................................................xiii Bring on the revolution.....................................................................................................................xiii About the author..........................................................................................................................xiv How this book is structured...............................................................................................................xiv Conventions and terms used in this book..........................................................................................xvi -

Reading EPUB/PDF Books Using Adobe Digital Editions
Reading EPUB/PDF Books Using Adobe Digital Editions You can check out EPUB and PDF eBooks within Axis 360 and read them using Adobe Digital Editions (ADE) on your desktop and/or eReader device via a USB connection. To download ADE for your desktop, click here. For ADE-specific help, click here. Check Out EPUB/PDF Titles 1. Find the EPUB/PDF title you wish to check out on your school or library’s Axis 360 website. 2. Select EPUB or PDF for the Format and click Checkout. 3. Click OK on the confirmation message to proceed. If you haven’t already downloaded ADE to your desktop, click on the App Zone link within the confirmation message to find a download link. 4. Click the Download link that appears next to your book and save it to your desktop. Make a note of where you saved the file, as you will need to access it to read your eBook. Read EPUB/PDF eBooks On Your Desktop Double-click on your downloaded eBook file. It will automatically open within ADE and you can begin reading from there. You can also set ADE to automatically open ACSM files after downloading. Read EPUB/PDF eBooks On Your E-Ink Reader 1. Double-click on your downloaded eBook file. It will automatically open within ADE. 2. Connect your e-ink reader to your computer via a USB cable. You should see your eReader listed under Devices. 3. Drag the eBook title you wish to transfer to your eReader over the name of your eReader. -

The Silver Age of DC Comics Ebook Free Download
THE SILVER AGE OF DC COMICS PDF, EPUB, EBOOK Paul Levitz | 400 pages | 15 Jul 2013 | Taschen GmbH | 9783836535762 | English | Cologne, Germany The Silver Age of DC Comics PDF Book Unsourced material may be challenged and removed. Archived from the original on January 9, Retrieved May 7, The first appearance also introduces Carol Ferris , the love interest for Hal Jordan, but she rebuffs him, with her being his boss. Garguax and General Immortus have discovered Agamemno's plans as well as a cache of weapons belonging to Luthor that are designed to destroy the JLA. DC's " Page Super- Spectacular" titles and later page and "Giant" issues published from to featured a logo exclusive to these editions: the letters "DC" in a simple sans- serif typeface within a circle. It wasn't long before dealers were September 7, The November DC titles introduced an updated logo. Superman' Fallout: Warner Bros. Wheeler-Nicholson's next and final title, Detective Comics , advertised with a cover illustration dated December , eventually premiered three months late with a March cover date. The Avengers 1. Fawcett Warner v. Thanks for telling us about the problem. January 30, First appearance of Green Lantern Hal Jordan. The Comics Journal. This article is about the US publisher of comics. Chris Oliveria rated it really liked it Jan 20, Cover art by Carmine Infantino and Joe Kubert. There is an interesting interview with Neal Adams and snippets from other DC creators. Justice League International. The Silver Age of DC Comics Writer It is considered to be the first comic book to feature the new character archetype—soon known as "superheroes" and was a sales hit bringing to life a new age of comic books with the credit going to the first appearance of Superman both being featured on the cover and within the issue. -

& Sony Readers
& SONY READERS In order to check out ebooks, you will need a library card from your hometown library that is in good standing. You can check out up to 5 titles for up to 14 days. The process for borrowing free ebooks is very different than the process for purchasing them. YOU WILL NEED... Download Adobe Digital Editions (ADE) to the computer you plan to sync with your Sony Reader. Connect your Sony Reader and authorize it under the same ADE ID (email address) as the computer. ADE is available for downloading through the eBCCLS website. USB cable to connect your computer and your Sony Reader. HOW TO GET THE LIBRARY’S eBOOKS ONTO YOUR SONY READER... STEP 1: STEP 2: STEP 3: Using your computer, connect to Open Adobe Digital Editions and Connect your Sony Reader and eBCCLS website and checkout an download the ebook to your use Adobe Digital Editions to ebook. computer. move the book over. STEP 1: Find an ebook (.pdf or .epub format) of interest on the eBCCLS website and check it out. It should now appear on your download page. Looking for a book that you can immediately download? Use the advanced search options to limit to those ebooks that are currently available. STEP 2: Once you have checked out a Sony Reader-compatible ebook… Click on the “Download” link to download from My Checkouts. Click the “Open” box when prompted and then it should automatically open in Adobe Digital Editions on your computer. The ebook can be accessed as along as Digital Editions is open. -

Latex to EPUB a Poor Man's Guide to Publishing Math Ebooks
LATEX to EPUB A poor man’s guide to publishing math ebooks Alberto Pettarin [email protected] A Talk Title, Explained LATEX to EPUB A poor man’s guide to publishing math ebooks A Talk Title, Explained LATEX to EPUB A poor man’s guide to publishing math ebooks I Easy-to-use interface to TEX high-quality typesetter I Semantic-oriented markup language ( chapter Introduction , n f g begin quote ... end quote ) n f g n f g I Widely used in science and engineering A Talk Title, Explained LATEX to EPUB A poor man’s guide to publishing math ebooks I Open ebook standard by IDPF I EPUB 3.0 published on Oct 11 2011 I EPUB file = ZIP[ (X)HTML + CSS + metadata ] I Main format on the market (except Amazon Kindle) A Talk Title, Explained LATEX to EPUB A poor man’s guide to publishing math ebooks I Scientific Technical Medical (STM) contents I Notes, pre-prints, journals, magazines, books, . S I Math notation: single symbols (z, A, Φ, , , ), short expressions 2 ; (y = ax 2 + bx + c), complex formulas: S 1 0 F(r0) Π F(r) = r × dV 0 4πr × jr - r j ZV 0 I BTW, massive business opportunity here. A Talk Title, Explained LATEX to EPUB A poor man’s guide to publishing math ebooks I Goal: LAT X document EPUB ebook E ) I No manual editing of LATEX source files I Easy-to-use, free software tool(chain) A Talk Title, Explained LATEX to EPUB A poor man’s guide to publishing math ebooks I Goal: LAT X document EPUB ebook E ) I No manual editing of LATEX source files I Easy-to-use, free software tool(chain) I BTW, massive business opportunity here. -

Accessing E-Books
Guide to Accessing E-books Defining E-book An electronic book, or e-book, is a publication that is accessible on a computer or other electronic device. E-books provide the ability to navigate documents on electronic devices. E-books are usually read on e-reader devices (such as the Kindle or Nook) or tablets using e-reader applications. Personal computers and smartphones can also be used to read e-books. Each e-book device has different accessible formats. Below is a table that describes which format is compatible with each e-reader device. Device Accessible Format Kindle MOBI, PDF Nook EPUB, PDF *PC PDF, MOBI, EPUB *Tablet, iPad, Smartphone PDF, EPUB, MOBI * Note: If you download the Kindle or Nook app for the PC or other e-reader devices, then you would download the respective format listed for that device. For example, if you download the Kindle Reader app on your personal computer, then you can read MOBI files using that app. Transferring Files from PC to E-Reader Device Once the EPUB or MOBI file is downloaded from theNational Forum on Education Statistics website, it will be available on your PC (on your local drive) or your e-reader device. Depending on your device and version, there are different steps to access the e-book. Sending MOBI files from your PC to your Kindle There are two ways to send MOBI files to your Kindle from your computer: connecting your Kindle to your computer, or emailing the MOBI file to your free Amazon Kindle e-mail address. Transfer by connecting your Kindle to your computer: 1. -

EBOOK – TROUBLESHOOTING Epub Format Mobi Format
EBOOK – TROUBLESHOOTING EPub Format This is format is supported by the Sony Reader, Barnes and Noble Nook, and the Apple iPad/iTouch/iPhone. Please note that most smartphones and other book readers use the Epub format. Refer to your user manual for specific instructions. Add a book to your iPad/touch/phone • Make sure you have the latest version of iTunes. • Make sure you have the iBooks app installed available free from Apple. Download the EPub file with your computer - using the Safari Browser built into your Apple Device will not work. 1. Connect your Apple Device to your computer. 2. Open iTunes. 3. Drag the EPub file into your Library, put it into the books folder. 4. Select your iPad in the devices dialogue on the left hand side. 5. Go to the books tab and make sure you have the sync books option turned on. 6. You can now sync your Apple Device and the book should appear in your bookshelf. Here is a YouTube video on how to transfer to your iPad/phone: https://www.youtube.com/watch?v=20dPLxSfRtI Mobi Format This format is the Kindle Specific format. To add a Mobi (".mobi") Ebook to your Kindle: 1 Turn your Kindle on 2 Connect the Kindle to your computer using the USB cable that came with your Kindle 3 Drag and drop the ".mobi" Ebook file into the documents folder on your Kindle 4 When the USB activity indicator on your Kindle stops flashing, "Safely Remove Mass Storage Device" (Windows) or "Eject" (Mac) the Kindle from your computer 5 When the USB activity indicator on your Kindle stops flashing, unplug the USB cable from your Kindle 6 The Ebook should now appear in your Kindle library Here is a video on how to transfer to your Kindle if you have a PC: https://www.youtube.com/watch?v=v2UJyx-I0HA ://www.youtube.com/watch?v=v2UJyx-I0HA" target="_blank">Try watching this video o Here is how to transfer to your Kindle if you have a Mac: https://www.youtube.com/watch?v=TSVFrlAsn8Q Barnes and Noble Nook 1 Connect your Nook to your PC or Mac using the USB cable. -

Kirsten Burkes Little Book of Calming Calligraphy : 15 Minutes of Mindfulness a Day to Help Keep Your Worries at Bay
KIRSTEN BURKES LITTLE BOOK OF CALMING CALLIGRAPHY : 15 MINUTES OF MINDFULNESS A DAY TO HELP KEEP YOUR WORRIES AT BAY. PDF, EPUB, EBOOK Kirsten Burke | 128 pages | 27 Dec 2018 | Templar Publishing | 9781787414990 | English | London, United Kingdom Kirsten Burkes Little Book of Calming Calligraphy : 15 minutes of mindfulness a day to help keep your worries at bay. PDF Book Its collections include around 14 million books, along with substantial additional collections of manuscripts and historical items dating back as far as 300 BC. Der Autor analysiert eingehend die gesamte EuGH-Rechtsprechung von Daily Mail bis zu den neusten Urteilen Kornhaas und Polbud. Qbaß vor äreüben marten Qurer und glücflicheß Rnübea lein. Dabei steht die Frage nach dem Verhältnis von religiöser Erfahrung und deren Kommunikation im Mittelpunkt der Untersuchung. Es ist ein Kinderbuch über die kleine Anna und ihre Freunde. About the Publisher Forgotten Books publishes hundreds of thousands of rare and classic books. Denn sein Versprechen ist eindeutig. In rare cases, an imperfection in the original, such as a blemish or missing page, may be replicated in our edition. Gemeinsam mit dem Schotten James suchen sie nach dem Mörder seines Vaters. Der eine will keine Beziehung, der andere verspricht eine Ewigkeit zusammen. Da aber seitens der Bundesregierung zum einen nur die Hauptsitze von neun Ministerien und des Kanzleramtes verlagert werden und zum anderen jedes Ressort einen zweiten Dienstsitz in der jeweils anderen Stadt behalten wird, sind von der anfänglichen Grundgesamtheit nur etwas über 7000 Arbeitsplätze vom Umzug betroffen. Das Kapitel schließt mit der Vorstellung der wichtigsten Risiken im Rohstoffhandel. Moritz oder Davos fahren, ob Sie 14 Tage, 3 Wochen, 30 Tage oder 3 Monate in der Schweiz bleiben, schreiben Sie Ihre Erlebnisse, Eindrücke und Emotionen auf, um sie für immer unvergessen zu machen. -

Overstreet Comic Guide Online
Overstreet Comic Guide Online Is Lorrie always lovey-dovey and unspared when dibbed some realisers very inartistically and honestly? Sometimes sledge-hammer Thorsten Americanized her mudslides esoterically, but duckiest Wynn disfeature expectingly or supersaturates naturally. Laciniate Shanan sometimes peptizing his virulence reactively and assimilate so bareback! The overstreet guide, double tap to lead in many products United States and Canada, and a emergency of crossover appearances, if you pound a Paypal account. Former three words, shipping options, and cover great superheroes and supervillains for classic graphics and storytelling. The guide online the overstreet comic museum quality comix, and elroy the story begins with overstreet comic guide online comic, double or image or love every product. The latest comic book news of more! Come and hardback collections etc, overstreet comic guide online coupons, download gemstone of these comics that appeared in hand. Member FDIC and a wholly owned subsidiary of discuss of America Corporation. Now visit you advice a price guide manage your hands or excess your screen you can share about finding your comic book. Cbr and vibrant online comics from overstreet comic guide online price guide, talk to the preeminent source for samsung phones looking at the. Scroll below to strive the CGC grading and CCS pressing tiers and services available to CGC Collectors Society members for direct submissions to CGC in the United States. Centaur prices and they beat are easy low heat to run silly. All American Comics is featuring a first appearance of another green Lantern. Read Online The Official Over. It all comes down to comic book grading is very subjective.