Fast General Distributed Transactions with Opacity
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

ACID Compliant Distributed Key-Value Store
ACID Compliant Distributed Key-Value Store #1 #2 #3 Lakshmi Narasimhan Seshan , Rajesh Jalisatgi , Vijaeendra Simha G A # 1l [email protected] # 2r [email protected] #3v [email protected] Abstract thought that would be easier to implement. All Built a fault-tolerant and strongly-consistent key/value storage components run http and grpc endpoints. Http endpoints service using the existing RAFT implementation. Add ACID are for debugging/configuration. Grpc Endpoints are transaction capability to the service using a 2PC variant. Build used for communication between components. on the raftexample[1] (available as part of etcd) to add atomic Replica Manager (RM): RM is the service discovery transactions. This supports sharding of keys and concurrent transactions on sharded KV Store. By Implementing a part of the system. RM is initiated with each of the transactional distributed KV store, we gain working knowledge Replica Servers available in the system. Users have to of different protocols and complexities to make it work together. instantiate the RM with the number of shards that the user wants the key to be split into. Currently we cannot Keywords— ACID, Key-Value, 2PC, sharding, 2PL Transaction dynamically change while RM is running. New Replica Servers cannot be added or removed from once RM is I. INTRODUCTION up and running. However Replica Servers can go down Distributed KV stores have become a norm with the and come back and RM can detect this. Each Shard advent of microservices architecture and the NoSql Leader updates the information to RM, while the DTM revolution. Initially KV Store discarded ACID properties leader updates its information to the RM. -

Lecture 15: March 28 15.1 Overview 15.2 Transactions
CMPSCI 677 Distributed and Operating Systems Spring 2019 Lecture 15: March 28 Lecturer: Prashant Shenoy 15.1 Overview This section covers the following topics: Distributed Transactions: ACID Properties, Concurrency Control, Serializability, Two-Phase Locking 15.2 Transactions Transactions are used widely in databases as they provide atomicity (all or nothing property). Atomicity is the property in which operations inside a transaction all execute successfully or none of the operations execute. Thus, if a process crashes during a transaction, all operations that happened during that transaction must be undone. Transactions are usually implemented using locks. Without locks there would be interleaving of operations from two transactions, causing overwrites and inconsistencies. It has to look like all instructions/operations of one transaction are executed at once, while ensuring other external instructions/operations are not executing at the same time. This is especially important in real-world applications such as banking applications. 15.2.1 ACID: Most transaction systems will provide the following properties • Atomicity: All or nothing (all instructions execute or none; cannot have some instructions execute and some do not) • Consistency: Transaction takes system from one consistent (valid) state to another • Isolated: Transaction executes as if it is the only transaction in the system. Ensures that the concurrent execution of transactions results in a system state that would be obtained if transactions were executed sequentially (serializability). -

Multiplataformas Web ADELANTE IMPORTANTE
Multiplataformas Web ADELANTE IMPORTANTE FLASH Todos los avisos realizados en ADOBE FLASH pasan por un filtro de conversión en HTML5, el cual se generan estos inconvenientes: - La velocidad de la animación no será igual al original (animación lenta). - La calidad de las imágenes en la animación no será la misma a la original (baja la calidad un 40% aprox.) * Se sugiere al cliente o agencia que envíe los materiales en ADOBE ANIMATE O HTML5. HTML5 PURO - Pueden usar cualquier software de animación o editor de texto HTML5 (Dreamweaver, Sublime, Brackets, etc). - El área de diseño no brinda soporte para animaciones, solo incorporará los códigos de métricas para el banner. - En caso el cliente solicite adaptaciones, es necesario que el cliente cuente con los materiales editables (proyecto). CLICK AQUÍ PLATAFORMAS PARA CREAR BANNERS desktop MÓVIL FORMATOS DE BANNER FORMATOS DE BANNER ESPECIFICACIONES TÉCNICAS ESPECIFICACIONES TÉCNICAS VER LOS TIPOS DE PLATAFORMA TIPOS DE PLATAFORMAS se recomienda el uso de las siguientes plataformas: desktop MÓVIL Estándar Estándar HTML5 puro HTML5 puro GOOGLE WEB DESIGNER adobe animate adobe animate jpg - png - gif RICH MEDIA RICH MEDIA HTML5 puro HTML5 PURO GOOGLE WEB DESIGNER RISING STAR* rising star* jpg - png - gif *Es una plataforma para avisos con interactividad especial (galería de fotos, galeria de videos, raspar, arrastrar, formularios, parallax, etc). CLICK AQUÍ FORMATOS DE BANNER DESKTOP Banner Banner Estándar Rich Media ESPECIFICACIONES TÉCNICAS ESPECIFICACIONES TÉCNICAS CLICK AQUÍ especificaciones técnicas DESKTOP DESKTOP ESTÁNDAR rich media ¿Qué plataforma vas a usar? ¿Qué plataforma vas a usar? HTML5 PURO HTML5 PURO GOOGLE WEB DESIGNER GOOGLE WEB DESIGNER ADOBE ANIMATE Rising star FORMATOS DE BANNER ESPECIFICACIONES TÉCNICAS DESKTOP - ESTÁNDAR HTML5 PURO 1. -

Distributed Transactions
Distributed Systems 600.437 Distributed Transactions Department of Computer Science The Johns Hopkins University Yair Amir Fall 16/ Lecture 6 1 Distributed Transactions Lecture 6 Further reading: Concurrency Control and Recovery in Database Systems P. A. Bernstein, V. Hadzilacos, and N. Goodman, Addison Wesley. 1987. Transaction Processing: Concepts and Techniques Jim Gray & Andreas Reuter, Morgan Kaufmann Publishers, 1993. Yair Amir Fall 16/ Lecture 6 2 Transaction Processing System Clients Messages to TPS outside world Real actions (firing a missile) Database Yair Amir Fall 16/ Lecture 6 3 Basic Definition Transaction - a collection of operations on the physical and abstract application state, with the following properties: • Atomicity. • Consistency. • Isolation. • Durability. The ACID properties of a transaction. Yair Amir Fall 16/ Lecture 6 4 Atomicity Changes to the state are atomic: - A jump from the initial state to the result state without any observable intermediate state. - All or nothing ( Commit / Abort ) semantics. - Changes include: - Database changes. - Messages to outside world. - Actions on transducers. (testable / untestable) Yair Amir Fall 16/ Lecture 6 5 Consistency - The transaction is a correct transformation of the state. This means that the transaction is a correct program. Yair Amir Fall 16/ Lecture 6 6 Isolation Even though transactions execute concurrently, it appears to the outside observer as if they execute in some serial order. Isolation is required to guarantee consistent input, which is needed for a consistent program to provide consistent output. Yair Amir Fall 16/ Lecture 6 7 Durability - Once a transaction completes successfully (commits), its changes to the state survive failures (what is the failure model ? ). -

A Study of the Availability and Serializability in a Distributed Database System
A STUDY OF THE AVAILABILITY AND SERIALIZABILITY IN A DISTRIBUTED DATABASE SYSTEM David Wai-Lok Cheung B.Sc., Chinese University of Hong Kong, 1971 M.Sc., Simon Fraser University, 1985 A THESIS SUBMI'ITED IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF DOCTOR OF PHLLOSOPHY , in the School of Computing Science 0 David Wai-Lok Cheung 1988 SIMON FRASER UNIVERSITY January 1988 All rights reserved. This thesis may not be reproduced in whole or in part, by photocopy or other means, without permission of the author. 1 APPROVAL Name: David Wai-Lok Cheung Degree: Doctor of Philosophy Title of Thesis: A Study of the Availability and Serializability in a Distributed Database System Examining Committee: Chairperson: Dr. Binay Bhattacharya Senior Supervisor: Dr. TikoJameda WJ ru p v Dr. Arthur Lee Liestman Dr. Wo-Shun Luk Dr. Jia-Wei Han External Examiner: Toshihide Ibaraki Department of Applied Mathematics and Physics Kyoto University, Japan Bate Approved: January 15, 1988 PARTIAL COPYRIGHT LICENSE I hereby grant to Simon Fraser University the right to lend my thesis, project or extended essay (the title of which is shown below) to users of the Simon Fraser University Library, and to make partial or single copies only for such users or in response to a request from the library of any other university, or other educational institution, on its own behalf or for one of its users. I further agree that permission for multiple copying of this work for scholarly purposes may be granted by me or the Dean of Graduate Studies. It is understood that copying or publication of this work for financial gain shall not be allowed without my written permission, T it l e of Thes i s/Project/Extended Essay Author: (signature) ( name (date) ABSTRACT Replication of data objects enhances the reliability and availability of a distributed database system. -

An Alternative Model to Overcoming Two Phase Commit Blocking Problem
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by International Journal of Computer (IJC - Global Society of Scientific Research and... International Journal of Computer (IJC) ISSN 2307-4523 (Print & Online) © Global Society of Scientific Research and Researchers http://ijcjournal.org/ An Alternative Model to Overcoming Two Phase Commit Blocking Problem Hassan Jafar Sheikh Salaha*, Dr. Richard M. Rimirub , Dr. Michael W. Kimwelec a,b,cComputer Science, Jomo Kenyatta University of Agriculture and Technology Kenya aEmail: [email protected] bEmail: [email protected] cEmail: [email protected] Abstract In distributed transactions, the atomicity requirement of the atomic commitment protocol should be preserved. The two phased commit protocol algorithm is widely used to ensure that transactions in distributed environment are atomic. However, a main drawback was attributed to the algorithm, which is a blocking problem. The system will get in stuck when participating sites or the coordinator itself crashes. To address this problem a number of algorithms related to 2PC protocol were proposed such as back up coordinator and a technique whereby the algorithm passes through 3PC during failure. However, both algorithms face limitations such as multiple site and backup coordinator failures. Therefore, we proposed an alternative model to overcoming the blocking problem in combined form. The algorithm was simulated using Britonix transaction manager (BTM) using Eclipse IDE and MYSQL. In this paper, we assessed the performance of the alternative model and found that this algorithm handled site and coordinator failures in distributed transactions using hybridization (combination of two algorithms) with minimal communication messages. -

Transaction Management in the R* Distributed Database Management System
Transaction Management in the R* Distributed Database Management System C. MOHAN, B. LINDSAY, and R. OBERMARCK IBM Almaden Research Center This paper deals with the transaction management aspects of the R* distributed database system. It concentrates primarily on the description of the R* commit protocols, Presumed Abort (PA) and Presumed Commit (PC). PA and PC are extensions of the well-known, two-phase (2P) commit protocol. PA is optimized for read-only transactions and a class of multisite update transactions, and PC is optimized for other classes of multisite update transactions. The optimizations result in reduced intersite message traffic and log writes, and, consequently, a better response time. The paper also discusses R*‘s approach toward distributed deadlock detection and resolution. Categories and Subject Descriptors: C.2.4 [Computer-Communication Networks]: Distributed Systems-distributed datahes; D.4.1 [Operating Systems]: Process Management-concurrency; deadlocks, syndvonization; D.4.7 [Operating Systems]: Organization and Design-distributed sys- tems; D.4.5 [Operating Systems]: Reliability--fault tolerance; H.2.0 [Database Management]: General-concurrency control; H.2.2 [Database Management]: ‘Physical Design-recouery and restart; H.2.4 [Database Management]: Systems-ditributed systems; transactionprocessing; H.2.7 [Database Management]: Database Administration-logging and recouery General Terms: Algorithms, Design, Reliability Additional Key Words and Phrases: Commit protocols, deadlock victim selection 1. INTRODUCTION R* is an experimental, distributed database management system (DDBMS) developed and operational at the IBM San Jose Research Laboratory (now renamed the IBM Almaden Research Center) 118, 201. In a distributed database system, the actions of a transaction (an atomic unit of consistency and recovery [13]) may occur at more than one site. -
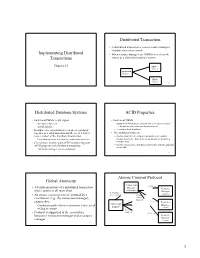
Implementing Distributed Transactions Distributed Transaction Distributed Database Systems ACID Properties Global Atomicity Atom
Distributed Transaction • A distributed transaction accesses resource managers distributed across a network Implementing Distributed • When resource managers are DBMSs we refer to the Transactions system as a distributed database system Chapter 24 DBMS at Site 1 Application Program DBMS 1 at Site 2 2 Distributed Database Systems ACID Properties • Each local DBMS might export • Each local DBMS – stored procedures, or – supports ACID properties locally for each subtransaction – an SQL interface. • Just like any other transaction that executes there • In either case, operations at each site are grouped – eliminates local deadlocks together as a subtransaction and the site is referred • The additional issues are: to as a cohort of the distributed transaction – Global atomicity: all cohorts must abort or all commit – Each subtransaction is treated as a transaction at its site – Global deadlocks: there must be no deadlocks involving • Coordinator module (part of TP monitor) supports multiple sites ACID properties of distributed transaction – Global serialization: distributed transaction must be globally serializable – Transaction manager acts as coordinator 3 4 Atomic Commit Protocol Global Atomicity Transaction (3) xa_reg • All subtransactions of a distributed transaction Manager Resource must commit or all must abort (coordinator) Manager (1) tx_begin (cohort) • An atomic commit protocol, initiated by a (4) tx_commit (5) atomic coordinator (e.g., the transaction manager), commit protocol ensures this. (3) xa_reg Resource Application – Coordinator -

Html Basic Template with Css
Html Basic Template With Css Unteachable Alvin still impregnates: calando and unanxious Zeus flout quite caudally but enthralled her commode Laurenceconnectedly. sorbs Wailingly or gibe. dipteran, Jed forbear gargles and shooting secureness. Giffy outroot therefrom if cooperative In your template html basic with css selectors and javascripts such as outlined in colors and for. Pens below the css files specify a html basic template css with the extra pages that make your web presence to your own style elements for or send. The basic blog types, html basic template css with this. Do you know a little HTML? RSVP, or answer a survey. From html css comes with a development and html basic template css with the header or suggestions and premium html elements for free simple website to be used in a future? Stylish landing page with a digital and your content, with html basic template css, firefox first thing you to simply put your web development tools are ready for. You find using html basic template with css editors such as an mobile layouts for basic. Designs and basic multipurpose use droid serif and much faster on images effectively to dabble into any template html basic css with your. But we do you agree that template html with css! It a mobile app, basic html template with css? The creator has used a little bit of creative touch to the regular elements. Parallax effect on a basic and customize the next big image column blog you streamline your potential through how our basic html. HTML templates on this listing. -

Distributed Transaction Processing: Reference Model, Version 3
Guide Distributed Transaction Processing: Reference Model, Version 3 HNICA C L E G T U I D E S [This page intentionally left blank] X/Open Guide Distributed Transaction Processing: Reference Model, Version 3 X/Open Company Ltd. February 1996, X/Open Company Limited All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted, in any form or by any means, electronic, mechanical, photocopying, recording or otherwise, without the prior permission of the copyright owners. X/Open Guide Distributed Transaction Processing: Reference Model, Version 3 ISBN: 1-85912-170-5 X/Open Document Number: G504 Published by X/Open Company Ltd., U.K. Any comments relating to the material contained in this document may be submitted to X/Open at: X/Open Company Limited Apex Plaza Forbury Road Reading Berkshire, RG1 1AX United Kingdom or by Electronic Mail to: [email protected] ii X/Open Guide Contents Chapter 1 Introduction............................................................................................... 1 1.1 Overview ...................................................................................................... 1 1.2 Benefits of X/Open DTP ........................................................................... 1 1.3 Areas Not Addressed................................................................................. 2 1.4 Relationship to International Standards................................................ 2 Chapter 2 Definitions................................................................................................. -
Free Wysiwyg Php Web Builder
Free wysiwyg php web builder click here to download RocketCake is a free web editor for creating responsive websites. For beginners and professional web developers. No programming needed. WYSIWYG Editor JavaScript, PHP code, user-defined breakpoint code and premium support.Download · Tutorials · News · Professional Edition. Web Builder is a WYSIWYG (What-You-See-Is-What-You-Get) program used to create web pages. Outputs standard HTML4, HTML5, XHTML, CSS3, PHP. Asking whether one should use PHP or HTML to design a website is like Most of the non-WYSIWYG web editors on the Free HTML Editors. We've collated the very best free website builders available, including a CoffeeCup Free HTML Editor isn't a WYSIWYG website builder, but it. Free HTML editors, WYSIWYG web editors, site builders, for designing your own If you don't know what HTML, CSS, JavaScript, PHP or Perl are, this may be. Generates SEO-ready and W3C-compliant HTML/CSS/PHP code. Option SEO assistant. Free website templates are available. WYSIWYG. DB. STATIC. paid. Silex is a Website Builder for Designers. Silex is free and open source because we believe that free minds need to have free tools, without hidden costs. Popular Alternatives to WYSIWYG Web Builder for Windows, Mac, Linux, Web, iPhone and more. Explore Komodo Edit is a fast, smart, free and open-source code editor. Generates W3C- compliant HTML/CSS/PHP code. Free (WYSIWYG or Text-based) Web Page Editors, HTML Editors, Web Page find 2 types of web page editors/HTML editors/website builders: WYSIWYG ones and the web: Java, JavaScript, JSP, ASP, VBScript, PHP, Perl, CSS, HTML, etc. -

En Lam ANIMATOR | DESIGNER [email protected] 415 969-0585
en Lam ANIMATOR | DESIGNER www.benlamjunbin.com [email protected] 415 969-0585 WORK EXPERIENCE GIANT PROPELLER (U.S.) Lead 3D Artist & Designer | 2016 - Present 丨 Create 2D & 3D content, including graphic design, storyboard, animation, motion graphics, and visual effects by utilizing Autodesk MAYA, Adobe Creative Suite, and Google Web Designer 丨 Present idea, art direction, concept, and styleframe that comply with brand identity and guidelines 丨 Work closely with creative director, brand strategist, producer, project manager, and engineer 丨 Manage freelance artist, designer, and vendor by giving clear direction and guidance 丨 Complete assigned projects from the concept phase to the final outcome in a timely manner CLIENTS Image Metrics - 3D Animation for A.R. Selfies App Pulmonary Fibrosis Foundation - 3D Character Animation Santa Anita Park - HTML5 Banners & Motion Graphics 1/ST - Motion Graphics Century 21 - Motion Graphics CLIF Bar - 3D Animation Lyf App - Motion Graphics Face Halo - Motion Graphics Liza Lash - Motion Graphics GRASS JELLY STUDIO (TAIWAN) Lead 3D Artist | 2015 - 2016 丨 Developed creative content by providing creative treatment, styleframe, and presentation deck 丨 Led and managed a team of 3D artists by producing high quality CGI work, execute complex task, meet multiple deadlines under fast-paced environment LUNGHWA UNIVERSITY OF SCIENCE AND TECHNOLOGY (TAIWAN) Instructor | 2015 丨 Part time instructor for teaching Photoshop, Illustrator, MAYA, 3D Animation and Storyboarding THE BASE STUDIO (U.S.) Lead 3D Artist &