Principles of Programming Languages from Recursion to Iteration Through CPS
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Bringing GNU Emacs to Native Code
Bringing GNU Emacs to Native Code Andrea Corallo Luca Nassi Nicola Manca [email protected] [email protected] [email protected] CNR-SPIN Genoa, Italy ABSTRACT such a long-standing project. Although this makes it didactic, some Emacs Lisp (Elisp) is the Lisp dialect used by the Emacs text editor limitations prevent the current implementation of Emacs Lisp to family. GNU Emacs can currently execute Elisp code either inter- be appealing for broader use. In this context, performance issues preted or byte-interpreted after it has been compiled to byte-code. represent the main bottleneck, which can be broken down in three In this work we discuss the implementation of an optimizing com- main sub-problems: piler approach for Elisp targeting native code. The native compiler • lack of true multi-threading support, employs the byte-compiler’s internal representation as input and • garbage collection speed, exploits libgccjit to achieve code generation using the GNU Com- • code execution speed. piler Collection (GCC) infrastructure. Generated executables are From now on we will focus on the last of these issues, which con- stored as binary files and can be loaded and unloaded dynamically. stitutes the topic of this work. Most of the functionality of the compiler is written in Elisp itself, The current implementation traditionally approaches the prob- including several optimization passes, paired with a C back-end lem of code execution speed in two ways: to interface with the GNU Emacs core and libgccjit. Though still a work in progress, our implementation is able to bootstrap a func- • Implementing a large number of performance-sensitive prim- tional Emacs and compile all lexically scoped Elisp files, including itive functions (also known as subr) in C. -

Hop Client-Side Compilation
Chapter 1 Hop Client-Side Compilation Florian Loitsch1, Manuel Serrano1 Abstract: Hop is a new language for programming interactive Web applications. It aims to replace HTML, JavaScript, and server-side scripting languages (such as PHP, JSP) with a unique language that is used for client-side interactions and server-side computations. A Hop execution platform is made of two compilers: one that compiles the code executed by the server, and one that compiles the code executed by the client. This paper presents the latter. In order to ensure compatibility of Hop graphical user interfaces with popular plain Web browsers, the client-side Hop compiler has to generate regular HTML and JavaScript code. The generated code runs roughly at the same speed as hand- written code. Since the Hop language is built on top of the Scheme program- ming language, compiling Hop to JavaScript is nearly equivalent to compiling Scheme to JavaScript. SCM2JS, the compiler we have designed, supports the whole Scheme core language. In particular, it features proper tail recursion. How- ever complete proper tail recursion may slow down the generated code. Despite an optimization which eliminates up to 40% of instrumentation for tail call in- tensive benchmarks, worst case programs were more than two times slower. As a result Hop only uses a weaker form of tail-call optimization which simplifies recursive tail-calls to while-loops. The techniques presented in this paper can be applied to most strict functional languages such as ML and Lisp. SCM2JS can be downloaded at http://www-sop.inria.fr/mimosa/person- nel/Florian.Loitsch/scheme2js/. -

SI 413, Unit 3: Advanced Scheme
SI 413, Unit 3: Advanced Scheme Daniel S. Roche ([email protected]) Fall 2018 1 Pure Functional Programming Readings for this section: PLP, Sections 10.7 and 10.8 Remember there are two important characteristics of a “pure” functional programming language: • Referential Transparency. This fancy term just means that, for any expression in our program, the result of evaluating it will always be the same. In fact, any referentially transparent expression could be replaced with its value (that is, the result of evaluating it) without changing the program whatsoever. Notice that imperative programming is about as far away from this as possible. For example, consider the C++ for loop: for ( int i = 0; i < 10;++i) { /∗ some s t u f f ∗/ } What can we say about the “stuff” in the body of the loop? Well, it had better not be referentially transparent. If it is, then there’s no point in running over it 10 times! • Functions are First Class. Another way of saying this is that functions are data, just like any number or list. Functions are values, in fact! The specific privileges that a function earns by virtue of being first class include: 1) Functions can be given names. This is not a big deal; we can name functions in pretty much every programming language. In Scheme this just means we can do (define (f x) (∗ x 3 ) ) 2) Functions can be arguments to other functions. This is what you started to get into at the end of Lab 2. For starters, there’s the basic predicate procedure?: (procedure? +) ; #t (procedure? 10) ; #f (procedure? procedure?) ; #t 1 And then there are “higher-order functions” like map and apply: (apply max (list 5 3 10 4)) ; 10 (map sqrt (list 16 9 64)) ; '(4 3 8) What makes the functions “higher-order” is that one of their arguments is itself another function. -

Supporting Return-Value Optimisation in Coroutines
Document P1663R0 Reply To Lewis Baker <[email protected]> Date 2019-06-18 Audience Evolution Supporting return-value optimisation in coroutines Abstract 2 Background 3 Motivation 4 RVO for coroutines and co_await expressions 6 Return-Value Optimisation for normal functions 6 Return-Value Optimisation for co_await expressions 8 Status Quo 8 Passing a handle to the return-value slot 8 Resuming with an exception 10 Multiple Resumption Paths and Symmetric Transfer 10 Simplifying the Awaiter concept 11 Specifying the return-type of an awaitable 12 Calculating the address of the return-value 12 Benefits and Implications of RVO-style awaitables 14 Generalising set_exception() to set_error<E>() 17 Avoiding copies when returning a temporary 17 A library solution to avoiding construction of temporaries 19 Language support for avoiding construction of temporaries 21 Avoiding copies for nested calls 22 Adding support for this incrementally 23 Conclusion 24 Acknowledgements 24 Appendix - Examples 25 Abstract Note that this paper is intended to motivate the adoption of changes described in P1745R0 for C++20 to allow adding support for async RVO in a future version of C++. The changes described in this paper can be added incrementally post-C++20. The current design of the coroutines language feature defines the lowering of a co_await expression such that the result of the expression is produced by a call to the await_resume() method on the awaiter object. This design means that a producer that asynchronously produces a value needs to store the value somewhere before calling .resume() so that the await_resume() method can then return that value. -

A History of Clojure
A History of Clojure RICH HICKEY, Cognitect, Inc., USA Shepherd: Mira Mezini, Technische Universität Darmstadt, Germany Clojure was designed to be a general-purpose, practical functional language, suitable for use by professionals wherever its host language, e.g., Java, would be. Initially designed in 2005 and released in 2007, Clojure is a dialect of Lisp, but is not a direct descendant of any prior Lisp. It complements programming with pure functions of immutable data with concurrency-safe state management constructs that support writing correct multithreaded programs without the complexity of mutex locks. Clojure is intentionally hosted, in that it compiles to and runs on the runtime of another language, such as the JVM. This is more than an implementation strategy; numerous features ensure that programs written in Clojure can leverage and interoperate with the libraries of the host language directly and efficiently. In spite of combining two (at the time) rather unpopular ideas, functional programming and Lisp, Clojure has since seen adoption in industries as diverse as finance, climate science, retail, databases, analytics, publishing, healthcare, advertising and genomics, and by consultancies and startups worldwide, much to the career-altering surprise of its author. Most of the ideas in Clojure were not novel, but their combination puts Clojure in a unique spot in language design (functional, hosted, Lisp). This paper recounts the motivation behind the initial development of Clojure and the rationale for various design decisions and language constructs. It then covers its evolution subsequent to release and adoption. CCS Concepts: • Software and its engineering ! General programming languages; • Social and pro- fessional topics ! History of programming languages. -

Tail Recursion • Natural Recursion with Immutable Data Can Be Space- Inefficient Compared to Loop Iteration with Mutable Data
CS 251 SpringFall 2019 2020 Principles of of Programming Programming Languages Languages Ben Wood Topics λ Ben Wood Recursion is an elegant and natural match for many computations and data structures. Tail Recursion • Natural recursion with immutable data can be space- inefficient compared to loop iteration with mutable data. • Tail recursion eliminates the space inefficiency with a +tail.rkt simple, general pattern. • Recursion over immutable data expresses iteration more clearly than loop iteration with mutable state. • More higher-order patterns: fold https://cs.wellesley.edu/~cs251/s20/ Tail Recursion 1 Tail Recursion 2 Naturally recursive factorial CS 240-style machine model Registers Code Stack (define (fact n) Call frame (if (= n 0) 1 Call frame (* n (fact (- n 1))))) Call frame Heap arguments, variables, fixed size, general purpose general size, fixed return address per function call Space: O( ) Program How efficient is this implementation? Counter cons cells, Time: O( ) Stack data structures, … Pointer Tail Recursion 3 Tail Recursion 4 Evaluation (define (fact n) (if (= n 0) Naturally recursive factorial example 1 (* n (fact (- n 1))))) Call stacks at each step (fact 3) (fact 3): 3*_ (fact 3): 3*_ (fact 3): 3*_ (define (fact n) (fact 2) (fact 2): 2*_ (fact 2): 2*_ (if (= n 0) Compute result so far Base case returns 1 after/from recursive call. (fact 1) (fact 1): 1*_ base result. Remember: n ↦ 2; and (* n (fact (- n 1))))) “rest of function” for this call. (fact 0) Recursive case returns result so far. Compute remaining argument before/for recursive call. (fact 3): 3*_ (fact 3): 3*_ (fact 3): 3*_ (fact 3): 3*2 (fact 2): 2*_ (fact 2): 2*_ (fact 2): 2*1 Space: O( ) (fact 1): 1*_ (fact 1): 1*1 Time: O( ) (fact 0): 1 Tail Recursion 5 Tail Recursion 6 Tail recursive factorial Common patterns of work Accumulator parameter Natural recursion: Tail recursion: provides result so far. -

Interprocedural Control Flow Analysis of First-Order Programs with Tail Call Optimization 1 Introduction
Interpro cedural Control Flow Analysis of FirstOrder Programs with Tail Call Optimization Saumya K Debray and To dd A Pro ebsting Department of Computer Science The University of Arizona Tucson AZ USA Email fdebray toddgcsarizonaedu Decemb er Abstract The analysis of control ow Involves guring out where returns will go How this may b e done With items LR and Is what in this pap er we show Intro duction Most co de optimizations dep end on control ow analysis typically expressed in the form of a control ow graph Traditional algorithms construct intrapro cedural ow graphs which do not account for control ow b etween pro cedures Optimizations that dep end on this limited information cannot consider the b e havior of other pro cedures Interpro cedural versions of these optimizations must capture the ow of control across pro cedure b oundaries Determining interpro cedural control ow for rstorder programs is relatively straightforward in the absence of tail call optimization since pro cedures return control to the p oint imme diately after the call Tail call optimization complicates the analysis b ecause returns may transfer control to a pro cedure other than the active pro cedures caller The problem can b e illustrated by the following simple program that tak es a list of values and prints in their original order all the values that satisfy some prop erty eg exceed To take advantage of tailcall optimization it uses an accumulator to collect these values as it traverses the input list However this causes the order of the values in the -

A Modern Reversible Programming Language April 10, 2015
Arrow: A Modern Reversible Programming Language Author: Advisor: Eli Rose Bob Geitz Abstract Reversible programming languages are those whose programs can be run backwards as well as forwards. This condition impacts even the most basic constructs, such as =, if and while. I discuss Janus, the first im- perative reversible programming language, and its limitations. I then introduce Arrow, a reversible language with modern features, including functions. Example programs are provided. April 10, 2015 Introduction: Many processes in the world have the property of reversibility. To start washing your hands, you turn the knob to the right, and the water starts to flow; the process can be undone, and the water turned off, by turning the knob to the left. To turn your computer on, you press the power button; this too can be undone, by again pressing the power button. In each situation, we had a process (turning the knob, pressing the power button) and a rule that told us how to \undo" that process (turning the knob the other way, and pressing the power button again). Call the second two the inverses of the first two. By a reversible process, I mean a process that has an inverse. Consider two billiard balls, with certain positions and velocities such that they are about to collide. The collision is produced by moving the balls accord- ing to the laws of physics for a few seconds. Take that as our process. It turns out that we can find an inverse for this process { a set of rules to follow which will undo the collision and restore the balls to their original states1. -

Proper Tail Recursion and Space Efficiency
Proper Tail Recursion and Space Efficiency William D Clinger Northeastern University [email protected] Abstract E ..- (quote c> constants The IEEE/ANSI standard for Scheme requires implementa- I variable references tions to be properly tail recursive. This ensures that portable L lambda expressions code can rely upon the space efficiency of continuation-pass- (if EO El E2) conditional expressions ing style and other idioms. On its face, proper tail recursion I (set! I Eo) assignments concerns the efficiency of procedure calls that occur within (Eo El . ..I procedure calls ..- a tail context. When examined closely, proper tail recur- L ..-’ (lambda (11 . > E) sion also depends upon the fact that garbage collection can TRUE 1 FALSE 1 NUM:z 1 SYM:I be asymptotically more space-efficient than Algol-like stack v$E&3;. .) I * * * allocation. Proper tail recursion is not the same as ad hoc tail call Location optimization in stack-based languages. Proper tail recursion Identifier often precludes stack allocation of variables, but yields a well-defined asymptotic space complexity that can be relied upon by portable programs. Figure 1: Internal syntax of Core Scheme. This paper offers a formal and implementation-indepen- dent definition of proper tail recursion for Scheme. It also shows how an entire family of reference implementations can execution of an iterative computation in constant be used to characterize related safe-for-space properties, and space, even if the iterative computation is de- proves the asymptotic inequalities that hold between them. scribed by a syntactically recursive procedure. The standard’s citation refers to a technical report that uses 1 Introduction CPS-conversion to explain what proper tail recursion meant in the context of the first Scheme compiler [Ste78]. -

CS 137 Part 9 Fibonacci, More on Tail Recursion, Map and Filter Fibonacci Numbers
CS 137 Part 9 Fibonacci, More on Tail Recursion, Map and Filter Fibonacci Numbers • An ubiquitous sequence named after Leonardo de Pisa (circa 1200) defined by 8 0 if n == 0 <> fib(n) = 1 if n == 1 > :fib(n-1) + fib(n-2) otherwise Examples in Nature • Plants, Pinecones, Sunflowers, • Rabbits, Golden Spiral and Ratio connections • Tool's song Lateralus • https://www.youtube.com/watch?v=wS7CZIJVxFY Fibonacci First Attempt #include <stdio.h> int fib (int n){ if (n == 0) return 0; if (n == 1) return 1; return fib(n-1)+fib(n-2); } int main () { printf("%d\n",fib(3)); printf("%d\n",fib(10)); //f_45 is largest that fits in integer. printf("%d\n",fib(45)); return 0; } Fibonacci Call Tree Fibonacci Call Tree • The tree is really large, containing O(2n) many nodes (Actually grows with φn where φ is the golden ratio (1.618) ) • Number of fib(1) leaves is fib(n) • Summing these is O(fib(n)) • Thus, the code on the previous slide runs in O(fib(n)) which is exponential! Improvements • This implementation of Fibonacci shouldn't take this long - After all, by hand you could certainly compute more than fib(45). • We could change the code so that we're no longer calling the stack each time, rather we're using iterative structures. • This would reduce the runtime to O(n). Iterative Fibonacci int fib(int n){ if(n==0) return 0; int prev = 0, cur = 1; for(int i=2; i<n; i++){ int next = prev + cur; prev = cur ; cur = next ; } return cur; } Trace n prev cur next 1 0 1 2 1 1 1 3 1 2 2 4 2 3 3 5 3 5 5 Tail Recursive Fibonacci int fib_tr(int prev, int cur, int n){ if(n==0) return cur; return fib_tr(cur, prev + cur, n-1); } int fib(int n){ if(n==0) return 0; return fib_tr(0,1,n-1); } Picture Tail Call Elimination Tail call elimination can reuse the activation record for each instance of fib tr(). -
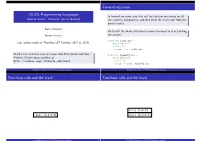
CS 321 Programming Languages Forward Recursion Functions Calls
tally [] y0 tally [] y0 tally [8] y8+0 tally [8] y8+0 tally [6;8] y6+8 tally [6;8] y6+8 tally [2;6;8] y2+14 y2+14 y4+16 y4+16 20 20 Forward recursion CS 321 Programming Languages In forward recursion, you first call the function recursively on all Intro to OCaml – Recursion (tail vs forward) the recursive components, and then build the final result from the partial results. Baris Aktemur Wait until the whole structure has been traversed to start building Ozye˘ginUniversity¨ the answer. th # let rec tally lst= Last update made on Thursday 12 October, 2017 at 11:25. match lst with |[] ->0 |x::xs ->x+ tally xs;; Much of the contents here are taken from Elsa Gunter and Sam # let rec squareUp lst= Kamin’s OCaml notes available at match lst with http://courses.engr.illinois.edu/cs421 |[] ->[] |x::xs ->(x*x)::squareUp xs;; Ozye˘gin¨ University — CS 321 Programming Languages 1 Ozye˘gin¨ University — CS 321 Programming Languages 2 Functions calls and the stack Functions calls and the stack tally [2;6;8] tally [4;2;6;8] tally [4;2;6;8] Ozye˘gin¨ University — CS 321 Programming Languages 3 Ozye˘gin¨ University — CS 321 Programming Languages 3 tally [] y0 tally [] y0 tally [8] y8+0 y8+0 y6+8 y6+8 y2+14 y2+14 y4+16 y4+16 20 20 y0 y8+0 y8+0 y6+8 y6+8 y2+14 y2+14 y4+16 y4+16 20 20 Functions calls and the stack Functions calls and the stack tally [8] tally [6;8] tally [6;8] tally [2;6;8] tally [2;6;8] tally [4;2;6;8] tally [4;2;6;8] Ozye˘gin¨ University — CS 321 Programming Languages 3 Ozye˘gin¨ University — CS 321 Programming Languages 3 Functions calls -

Programming Clojure
Extracted from: Programming Clojure This PDF file contains pages extracted from Programming Clojure, published by the Pragmatic Bookshelf. For more information or to purchase a paperback or PDF copy, please visit http://www.pragprog.com. Note: This extract contains some colored text (particularly in code listing). This is available only in online versions of the books. The printed versions are black and white. Pagination might vary between the online and printer versions; the content is otherwise identical. Copyright © 2008 The Pragmatic Programmers, LLC. All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted, in any form, or by any means, electronic, mechanical, photocopying, recording, or otherwise, without the prior consent of the publisher. Many of the designations used by manufacturers and sellers to distinguish their prod- ucts are claimed as trademarks. Where those designations appear in this book, and The Pragmatic Programmers, LLC was aware of a trademark claim, the designations have been printed in initial capital letters or in all capitals. The Pragmatic Starter Kit, The Pragmatic Programmer, Pragmatic Programming, Pragmatic Bookshelf and the linking g device are trademarks of The Pragmatic Programmers, LLC. Every precaution was taken in the preparation of this book. However, the publisher assumes no responsibility for errors or omissions, or for damages that may result from the use of information (including program listings) contained herein. Our Pragmatic courses, workshops, and other products can help you and your team create better software and have more fun. For more information, as well as the latest Pragmatic titles, please visit us at http://www.pragprog.com Copyright © 2009 Stuart Halloway.