What Twitter Watches: Tracking Popularity Through Twitter Subgraphs
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

(TMIIIP) Paid Projects Through August 31, 2020 Report Created 9/29/2020
Texas Moving Image Industry Incentive Program (TMIIIP) Paid Projects through August 31, 2020 Report Created 9/29/2020 Company Project Classification Grant Amount In-State Spending Date Paid Texas Jobs Electronic Arts Inc. SWTOR 24 Video Game $ 212,241.78 $ 2,122,417.76 8/19/2020 26 Tasmanian Devil LLC Tasmanian Devil Feature Film $ 19,507.74 $ 260,103.23 8/18/2020 61 Tool of North America LLC Dick's Sporting Goods - DecembeCommercial $ 25,660.00 $ 342,133.35 8/11/2020 53 Powerhouse Animation Studios, In Seis Manos (S01) Television $ 155,480.72 $ 1,554,807.21 8/10/2020 45 FlipNMove Productions Inc. Texas Flip N Move Season 7 Reality Television $ 603,570.00 $ 4,828,560.00 8/6/2020 519 FlipNMove Productions Inc. Texas Flip N Move Season 8 (13 E Reality Television $ 305,447.00 $ 2,443,576.00 8/6/2020 293 Nametag Films Dallas County Community CollegeCommercial $ 14,800.28 $ 296,005.60 8/4/2020 92 The Lost Husband, LLC The Lost Husband Feature Film $ 252,067.71 $ 2,016,541.67 8/3/2020 325 Armature Studio LLC Scramble Video Game $ 33,603.20 $ 672,063.91 8/3/2020 19 Daisy Cutter, LLC Hobby Lobby Christmas 2019 Commercial $ 10,229.82 $ 136,397.63 7/31/2020 31 TVM Productions, Inc. Queen Of The South - Season 2 Television $ 4,059,348.19 $ 18,041,547.51 5/1/2020 1353 Boss Fight Entertainment, Inc Zombie Boss Video Game $ 268,650.81 $ 2,149,206.51 4/30/2020 17 FlipNMove Productions Inc. -
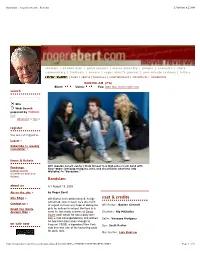
Bandslam __ Rogerebert.Com __ Reviews
Bandslam :: rogerebert.com :: Reviews 17/08/09 8:22 PM reviews | answer man | great movies | movie glossary | people | scanners | store commentary | festivals | oscars | roger ebert's journal | one-minute reviews | letters | news | sports | business | entertainment | classifieds | columnists BANDSLAM (PG) Ebert: Users: You: Rate this movie right now search Site Web Search powered by YAHOO! GO advanced » tips » register You are not logged in. Log in » Subscribe to weekly newsletter » times & tickets Will (Gaelan Conell, center) finds himself in a high school rock band with Fandango loner Sa5m (Vanessa Hudgens, left), and cheerleader Charlotte (Aly Search movie Michalka) in “Bandslam.” showtimes and buy tickets. Bandslam about us / / / August 13, 2009 About the site » by Roger Ebert Site FAQs » Will Burton lives within himself. A high cast & credits school kid, new in town, he’s too much Contact us » of a geek to have any hope of dating the Will Burton: Gaelan Connell Email the Movie girls he notices in school. He lives in a Answer Man » room he has made a shrine to David Charlotte: Aly Michalka Bowie (with whom he has a daily one- way e-mail correspondence) and wishes Sa5m: Vanessa Hudgens he had been born soon enough to on sale now frequent CBGB, a legendary New York Ben: Scott Porter club that was one of the launching pads for punk rock. Mrs. Burton: Lisa Kudrow http://rogerebert.suntimes.com/apps/pbcs.dll/article?AID=/20090812/REVIEWS/908129991 Page 1 of 3 Bandslam :: rogerebert.com :: Reviews 17/08/09 8:22 PM Not that you’d think he was a punk if you saw him. -
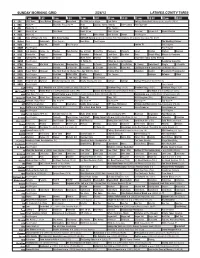
Sunday Morning Grid 2/26/12 Latimes.Com/Tv Times
SUNDAY MORNING GRID 2/26/12 LATIMES.COM/TV TIMES 7 am 7:30 8 am 8:30 9 am 9:30 10 am 10:30 11 am 11:30 12 pm 12:30 2 CBS CBS News Face/Nation Rangers Horseland The Path to Las Vegas Epic Poker College Basketball Pittsburgh at Louisville. (N) Å 4 NBC News Å Meet the Press (N) Å News Laureus Sports Awards Golf Central PGA Tour Golf 5 CW News (N) Å In Touch Paid Program 7 ABC News (N) Å This Week News (N) Å News (N) Å News Å Eye on L.A. Award Preview 9 KCAL News (N) Prince Mike Webb Joel Osteen Shook Paid Program 11 FOX Hour of Power (N) (TVG) Fox News Sunday NASCAR Racing Sprint Cup: Daytona 500. From Daytona International Speedway, Fla. (N) Å 13 MyNet Paid Tomorrow’s Paid Program Best Buys Paid Program The Wedding Planner 18 KSCI Paid Hope Hr. Church Paid Program Iranian TV Paid Program 22 KWHY Paid Program Paid Program 24 KVCR Sid Science Curios -ity Thomas Bob Builder Joy of Paint Paint This Dewberry Wyland’s Sara’s Kitchen Kitchen Mexican 28 KCET Hands On Raggs Busytown Peep Pancakes Pufnstuf Land/Lost Hey Kids Taste Simply Ming Moyers & Company 30 ION Turning Pnt. Discovery In Touch Mark Jeske Beyond Paid Program Inspiration Today Camp Meeting 34 KMEX Paid Program Al Punto (N) Fútbol de la Liga Mexicana República Deportiva 40 KTBN Rhema Win Walk Miracle-You Redemption Love In Touch PowerPoint It Is Written B. Conley From Heart King Is J. -

Race in Hollywood: Quantifying the Effect of Race on Movie Performance
Race in Hollywood: Quantifying the Effect of Race on Movie Performance Kaden Lee Brown University 20 December 2014 Abstract I. Introduction This study investigates the effect of a movie’s racial The underrepresentation of minorities in Hollywood composition on three aspects of its performance: ticket films has long been an issue of social discussion and sales, critical reception, and audience satisfaction. Movies discontent. According to the Census Bureau, minorities featuring minority actors are classified as either composed 37.4% of the U.S. population in 2013, up ‘nonwhite films’ or ‘black films,’ with black films defined from 32.6% in 2004.3 Despite this, a study from USC’s as movies featuring predominantly black actors with Media, Diversity, & Social Change Initiative found that white actors playing peripheral roles. After controlling among 600 popular films, only 25.9% of speaking for various production, distribution, and industry factors, characters were from minority groups (Smith, Choueiti the study finds no statistically significant differences & Pieper 2013). Minorities are even more between films starring white and nonwhite leading actors underrepresented in top roles. Only 15.5% of 1,070 in all three aspects of movie performance. In contrast, movies released from 2004-2013 featured a minority black films outperform in estimated ticket sales by actor in the leading role. almost 40% and earn 5-6 more points on Metacritic’s Directors and production studios have often been 100-point Metascore, a composite score of various movie criticized for ‘whitewashing’ major films. In December critics’ reviews. 1 However, the black film factor reduces 2014, director Ridley Scott faced scrutiny for his movie the film’s Internet Movie Database (IMDb) user rating 2 by 0.6 points out of a scale of 10. -

A BUG's LIFE Bandslam
A BUG’SBandslam LIFE Synopsis Will Burton has an uncommon chance to start his short life all over again. In a different town, at a fresh school, with the prospect of new friends, this formerly miserable teen misfit has one shot to reinvent himself as the person he always wanted to be. Discussion Questions • Like Will, have you ever tried to reinvent yourself? What was the result? • On Will’s first day of school in New Jersey, he asks Sa5m how big an event Bandslam was. She explained it as, “Texas High School Football big”. Does/Did your school have an event or a sport that it rallies around? Is this unique to your school or to the entire region in which you live? • We find out at the end of the film that Will’s father wasn’t who Will portrayed him to be? Why was Will so secretive about what his father did? What happened when people found out about Will’s real father? Have you ever had to keep something secret to avoid confrontation or ridicule from others? • Will loves music but is not a musician. He is still able to be involved with music as a band manager, which he excels at. Sa5m loves to read but we never see her write. What do you think career options are for someone who loves to read but doesn’t necessarily want to be an author? What are the activities that you love the most? Have you thought about how you could incorporate these activities into what you want to do with a career someday? • By the end of the film Will finally heard from his hero, David Bowie. -

NAME David Bewley ACTORS CLEARINGHOUSE Film
NAME David Bewley ACTORS CLEARINGHOUSE HEIGHT 5’ 11” HAIR Brown 501 NORTH IH 35 - AUSTIN, TEXAS 78702 WEIGHT 150 EYES Blue (512) 476-3412 - TX. LIC. #126 Film & Television Production / Title / Client Role / Character Director / Network How to Eat Fried Worms Rob Simon Bob Dolman; Walden Media Bandslam Letter Carrier Todd Graff; Walden Media “In Plain Sight” Albert Stoakes Sam Weisman; USA Networks “Friday Night Lights” Peter Jeffrey Reiner; NBC “The Edmond Bulldogs” (pilot) Lead (various) René Pinnell; MTV “$5.15/Hour” Vice President Richard Linklater; HBO Mouthgarden in Progress Knute Scroggins Derek Doublin; Bright Orange Blue “Backpack Picnic” Lead (various) OnNetworks, Inc. “Meet the Bulldogs” Lead (various) René Pinnell The Dad Family (I, II & III) Dad Derek Doublin; OHW Shorts The Reverse Side Lead Micheal Cintron Commercial Production / Title / Client Role / Character Director / Agency Fireteam Reloaded (viral campaign) Principal VOC Reversal Films Beavis & Butthead DVD Infomercial Featured VOC Mike Judge; MTV Chick-Fil-A “Peach Bowl” Featured OC Ken Lewin; Synthetic Pictures Keep Our Land Grand Featured OC Steve Sturges; Visual Image CD Warehouse Principal OC Jordan Associates Industrial Production / Title / Client Role / Character Director / Agency Dysphagia & Developmental… Principal VOC Darren Dunn; SATTRN for the OKDHS A Mission of Caring: OK DHS Principal OC Darren Dunn; SATTRN for the OKDHS OKC Addy Awards Film Principal OC Steve Sturges; Visual Image Theatre Production / Title / Client Role / Character Director / Agency -
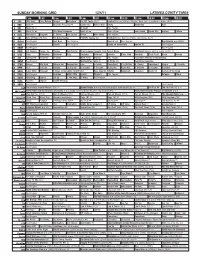
Sunday Morning Grid 12/4/11 Latimes.Com/Tv Times
SUNDAY MORNING GRID 12/4/11 LATIMES.COM/TV TIMES 7 am 7:30 8 am 8:30 9 am 9:30 10 am 10:30 11 am 11:30 12 pm 12:30 2 CBS CBS News Face/Nation Danger Horseland The NFL Today (N) Å Football Raiders at Miami Dolphins. From Sun Life Stadium in Miami. (N) Å 4 NBC News Å Meet the Press (N) Å Conference Willa’s Wild Skiing Swimming Golf 5 CW News (N) Å In Touch Paid Program 7 ABC News (N) Å This Week-Amanpour News (N) Å News (N) Å Jack Hanna Ocean Mys. Explore Culture 9 KCAL Tomorrow’s Kingdom K. Shook Joel Osteen Prince Mike Webb Paid Program 11 FOX Hour of Power (N) (TVG) Fox News Sunday FOX NFL Sunday (N) Football Denver Broncos at Minnesota Vikings. (N) Å 13 MyNet Paid Program Best Buys Paid Program Best of L.A. Paid Program Bee Season ›› (2005) 18 KSCI Paid Program Church Paid Program Hecho en Guatemala Iranian TV Paid Program 22 KWHY Paid Program Paid Program 24 KVCR Sid Science Curios -ity Thomas Bob Builder Classic Gospel Special: Tent Revival Home Prohibition Groups push to outlaw alcohol. Å 28 KCET Cons. Wubbulous Busytown Peep Pancakes Pufnstuf Lidsville Place, Own Roadtrip Chefs Field Pépin Venetia 30 ION Turning Pnt. Discovery In Touch Mark Jeske Beyond Paid Program Inspiration Ministry Campmeeting 34 KMEX Paid Program Muchachitas Como Tu Al Punto (N) República Deportiva 40 KTBN Rhema Win Walk Miracle-You Redemption Love In Touch PowerPoint It Is Written B. Conley From Heart King Is J. -

Fran & Rich Juro
Fran & Rich Juro Written and Composed by Jason Robert Brown Originally Produced for the New York stage by Arielle Tepper and Mary Bell Originally Produced by Northlight Theatre Chicago, IL Feb. 26–March 21, 2021 Directed by Susan Baer Collins Scenic & Lighting Designer Music Director Jim Othuse Jim Boggess Costume Designer Properties Master Lindsay Pape Darin Kuehler Sound Designers Scenic Artist Tim Burkhart & Janet Morr John Gibilisco Production Coordinator Choreographer Greg Scheer Michelle Garrity Technical Director Stage Manager Darrin Golden Steve Priesman Assistant Director / OCP Directing Fellow Dara Hogan Audio and/or visual recording of this production is strictly prohibited. Hawks Mainstage Series Sponsor: Director’s Notes Cast Bios | Musical Numbers | Orchestra Love? CAST Cathy ......................................................... Bailey Carlson Like most enduring works in the theatre, The Jamie .....................................................Thomas A.C. Gjere Last Five Years is a love story. This one captures insightful and poignant moments in a relationship through a series of wonderful songs by composer MUSICAL NUMBERS Jason Robert Brown. Though the story is simple, Brown’s concept requires that these songs not be presented in a familiar, chronological way. Jamie’s Still Hurting ............................................................Cathy songs go forward in time, from the beginning to Shiksa Goddess ........................................................ Jamie the end of their five years together, while Cathy’s -

NETFLIX – CATALOGO USA 20 Dicembre 2015 1. 009-1: the End Of
NETFLIX – CATALOGO USA 20 dicembre 2015 1. 009-1: The End of the Beginning (2013) , 85 imdb 2. 1,000 Times Good Night (2013) , 117 imdb 3. 1000 to 1: The Cory Weissman Story (2014) , 98 imdbAvailable in HD on your TV 4. 1001 Grams (2014) , 90 imdb 5. 100 Bloody Acres (2012) , 1hr 30m imdbAvailable in HD on your TV 6. 10.0 Earthquake (2014) , 87 imdb 7. 100 Ghost Street: Richard Speck (2012) , 1hr 23m imdbAvailable in HD on your TV 8. 100, The - Season 1 (2014) 4.3, 1 Season imdbClosed Captions: [ Available in HD on your TV 9. 100, The - Season 2 (2014) , 41 imdbAvailable in HD on your TV 10. 101 Dalmatians (1996) 3.6, 1hr 42m imdbClosed Captions: [ 11. 10 Questions for the Dalai Lama (2006) 3.9, 1hr 27m imdbClosed Captions: [ 12. 10 Rules for Sleeping Around (2013) , 1hr 34m imdbAvailable in HD on your TV 13. 11 Blocks (2015) , 78 imdb 14. 12/12/12 (2012) 2.4, 1hr 25m imdbClosed Captions: [ Available in HD on your TV 15. 12 Dates of Christmas (2011) 3.8, 1hr 26m imdbClosed Captions: [ Available in HD on your TV 16. 12 Horas 2 Minutos (2012) , 70 imdb 17. 12 Segundos (2013) , 85 imdb 18. 13 Assassins (2010) , 2hr 5m imdbAvailable in HD on your TV 19. 13 Going on 30 (2004) 3.5, 1hr 37m imdbClosed Captions: [ Available in HD on your TV 20. 13 Sins (2014) 3.6, 1hr 32m imdbClosed Captions: [ Available in HD on your TV 21. 14 Blades (2010) , 113 imdbAvailable in HD on your TV 22. -
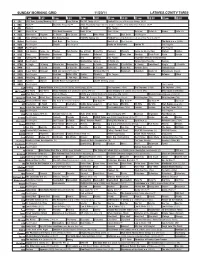
Sunday Morning Grid 11/20/11 Latimes.Com/Tv Times
SUNDAY MORNING GRID 11/20/11 LATIMES.COM/TV TIMES 7 am 7:30 8 am 8:30 9 am 9:30 10 am 10:30 11 am 11:30 12 pm 12:30 2 CBS CBS News Sunday Morning (N) Å Face/Nation The NFL Today (N) Å Football Raiders at Minnesota Vikings. (N) Å 4 NBC News Å Meet the Press (N) Å 2011 Presidents Cup Final Day. Singles matches. From Melbourne, Australia. (N) Å 5 CW News Å In Touch Paid Program 7 ABC News (N) Å This Week-Amanpour News (N) Å News (N) Å News Å Vista L.A. Heroes Vista L.A. 9 KCAL Tomorrow’s Kingdom K. Shook Joel Osteen Prince Mike Webb Paid Best Deals Paid Program 11 FOX Hour of Power (N) (TVG) Fox News Sunday FOX NFL Sunday (N) Football Tampa Bay Buccaneers at Green Bay Packers. (N) Å 13 MyNet Paid Program Best Buys Paid Program Best of L.A. Paid Program The Hoax ››› (2006) 18 KSCI Paid Program Church Paid Program Hecho en Guatemala Iranian TV Paid Program 22 KWHY Paid Program Paid Program 24 KVCR Sid Science Curios -ity Thomas Bob Builder Joy of Paint Paint This Dewberry Wyland’s Home for Christy Rost Kitchen Kitchen 28 KCET Cons. Wubbulous Busytown Peep Pancakes Pufnstuf Lidsville Place, Own Roadtrip Chefs Field Pépin Venetia 30 ION Turning Pnt. Discovery In Touch Paid Beyond Paid Program Inspiration Ministry Campmeeting 34 KMEX Paid Program Muchachitas Como Tu Al Punto (N) Aurora Valle Presenta... Vecinos 40 KTBN K. Hagin Ed Young Miracle-You Redemption Love In Touch PowerPoint It Is Written B. -
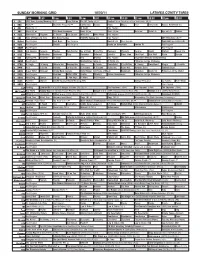
Sunday Morning Grid 10/30/11 Latimes.Com/Tv Times
SUNDAY MORNING GRID 10/30/11 LATIMES.COM/TV TIMES 7 am 7:30 8 am 8:30 9 am 9:30 10 am 10:30 11 am 11:30 12 pm 12:30 2 CBS CBS News Sunday Morning (N) Å Face/Nation The NFL Today (N) Å Football Miami Dolphins at New York Giants. (N) Å 4 NBC News Å Meet the Press (N) Å Conference George House House Paid Travel Cafe Access Hollywood (N) 5 CW News (N) Å In Touch Paid Program 7 ABC News (N) Å This Week-Amanpour News (N) Å News (N) Å News Å Vista L.A. Eye on L.A. Motion 9 KCAL Tomorrow’s Kingdom K. Shook Joel Osteen Ministries Mike Webb Paid Program 11 FOX Hour of Power (N) (TVG) Fox News Sunday FOX NFL Sunday (N) Paid Program UFC Primetime (N) Å 13 MyNet Paid Program Best Buys Paid Program Best of L.A. Paid Program From Hell ›› (2001) (R) 18 KSCI Paid Program Church Paid Program Hecho en Guatemala Iranian TV Paid Program 22 KWHY Paid Program Paid Program 24 KVCR Sid Science Curiosity Thomas Bob Builder Joy of Paint Paint This Dewberry Wyland’s Cuisine Cook’s Kitchen Sweet Life 28 KCET Cons. Wubbulous Busytown Peep Pancakes Pufnstuf Lidsville Place, Own Chef Paul Burt Wolf Pépin Venetia 30 ION Turning Pnt. Discovery In Touch Paid Beyond Paid Program Inspiration Ministry Campmeeting 34 KMEX Paid Program Muchachitas Como Tu Al Punto (N) Fútbol de la Liga Mexicana 40 KTBN K. Hagin Ed Young Miracle-You Redemption Love In Touch PowerPoint It Is Written B. -

Sunday Morning Grid 12/18/11
SUNDAY MORNING GRID 12/18/11 LATIMES.COM/TV TIMES 7 am 7:30 8 am 8:30 9 am 9:30 10 am 10:30 11 am 11:30 12 pm 12:30 2 CBS CBS News Sunday Morning (N) Å Face/Nation The NFL Today (N) Å Football Cincinnati Bengals at St. Louis Rams. (N) Å 4 NBC News Å Meet the Press (N) Å Conference Snowboarding USSA Grand Prix. Å Action Sports From Breckenridge, Colo. (N) Å 5 CW News (N) Å In Touch Paid Program Friends Friends 7 ABC News (N) Å This Week-Amanpour News (N) Å News (N) Å News Å Vista L.A. Paid Program 9 KCAL Tomorrow’s Kingdom K. Shook Joel Osteen Prince Mike Webb Paid Program 11 FOX Hour of Power (N) (TVG) Fox News Sunday FOX NFL Sunday (N) Football Washington Redskins at New York Giants. (N) Å 13 MyNet Paid Program Best Buys Paid Program Best of L.A. Paid Program Hates Chris 18 KSCI Paid Program Church Paid Program Hecho en Guatemala Iranian TV Paid Program 22 KWHY Paid Program Paid Program 24 KVCR Sid Science Curios -ity Thomas Bob Builder Joy of Paint Paint This Dewberry Wyland’s Cuisine Kitchen Kitchen Sweet Life 28 KCET Cons. Wubbulous Busytown Peep Pancakes Pufnstuf Lidsville Place, Own Roadtrip Chefs Field Pépin Venetia 30 ION Turning Pnt. Discovery In Touch Mark Jeske Beyond Paid McMahon Inspiration Ministry Campmeeting 34 KMEX Paid Program Muchachitas Como Tu Al Punto (N) Vidas Paralelas Vecinos 40 KTBN Rhema Win Walk Miracle-You Redemption Love In Touch PowerPoint It Is Written B.