Building a Corpus for Japanese Wikification with Fine-Grained Entity Classes
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Official Media Guide of Australia at the 2014 Fifa World Cup Brazil 0
OFFICIAL MEDIA GUIDE OF AUSTRALIA AT THE 2014 FIFA WORLD CUP BRAZIL 0 Released: 14 May 2014 2014 FIFA WORLD CUP BRAZIL OFFICIAL MEDIA GUIDE OF AUSTRALIA TM AT THE 2014 FIFA WORLD CUP Version 1 CONTENTS Media information 2 2014 FIFA World Cup match schedule 4 Host cities 6 Brazil profile 7 2014 FIFA World Cup country profiles 8 Head-to-head 24 Australia’s 2014 FIFA World Cup path 26 Referees 30 Australia’s squad (preliminary) 31 Player profiles 32 Head coach profile 62 Australian staff 63 FIFA World Cup history 64 Australian national team history (and records) 66 2014 FIFA World Cup diary 100 Copyright Football Federation Australia 2014. All rights reserved. No portion of this product may be reproduced electronically, stored in or introduced into a retrieval system, or transmitted in any form, or by any means (electronic, mechanical, photocopying, recording or otherwise), without the prior written permission of Football Federation Australia. OFFICIAL MEDIA GUIDE OF AUSTRALIA AT THE 2014 FIFA WORLD CUPTM A publication of Football Federation Australia Content and layout by Andrew Howe Publication designed to print two pages to a sheet OFFICIAL MEDIA GUIDE OF AUSTRALIA AT THE 2014 FIFA WORLD CUP BRAZIL 1 MEDIA INFORMATION AUSTRALIAN NATIONAL TEAM / 2014 FIFA WORLD CUP BRAZIL KEY DATES AEST 26 May Warm-up friendly: Australia v South Africa (Sydney) 19:30 local/AEST 6 June Warm-up friendly: Australia v Croatia (Salvador, Brazil) 7 June 12 June–13 July 2014 FIFA World Cup Brazil 13 June – 14 July 12 June 2014 FIFA World Cup Opening Ceremony Brazil -

Virtual Stadium for 2002 FIFA World Cup Korea-Japan Michitaka Hirose
ICAT 2001 December 5-7, Tokyo, JAPAN Virtual Stadium for 2002 FIFA World Cup Korea-Japan Michitaka Hirose RCAST, University of Tokyo 4-6-1 Komaba, Meguro-ku, Tokyo 153-8904, Japan [email protected] Abstract The most important keyword of the virtual stadium is “sensations”. In order to synthesize the sensations of This paper describes the short history of the virtual being at a specific location, there are several factors that stadium development. The virtual stadium is a virtual must be considered. First, a wide field of view is the reality theater system that provides an 2002 World Cup most essential component in generating a realistic visual audience who cannot attend a game. After the impression. Second, a high resolution is also important. introduction of system components, the results of the (For example, we may need to be able to see a uniform real-time image transmission experiments are briefly number of players.) Sometimes, a stereo image is also reported. very important. However, when viewing scenes of distant places, as in the case of the virtual stadium, this factor Key words: virtual stadium, realistic sensations, can be ignored. application of VR technology, HDTV 1. Introduction Table 1 History of Virtual Stadium The virtual stadium is a virtual reality theater system that provides an audience who cannot attend a game with the 1995 Japan vs. Korea competition to bring World Cup realistic sensations of being at a soccer stadium. Japan proposed “virtual stadium” concept Although this system was originally planned in order to 1996 Apr. Informal study group for virtual stadium was bring Federation Internationale de Football organized in HVC (High-tech Visual promotion Association(FIFA) World Cup games to Japan, it is also Center) under the sponsorship of MITI (Ministry expected to provide a new way to enjoy sports games via of International Trade and Industries) electronic media other than TV. -

INVESTOR INFORMATION 2012 Consolidated Financial Highlights
TOKYO BROADCASTING SYSTEM HOLDINGS, INC. INVESTOR INFORMATION 2012 Consolidated Financial Highlights Net Sales Operating Income Millions of yen Millions of yen 372,306 20,624 351,262 342,754 346,538 18,457 315,175 12,162 7,705 3,343 08/3 09/3 10/3 11/3 12/3 08/3 09/3 10/3 11/3 12/3 Ordinary Income Net Income (Loss) Millions of yen Millions of yen 23,088 19,022 19,979 11,671 14,313 9,215 1,655 103 3,902 –2,313 08/3 09/3 10/3 11/3 12/3 08/3 09/3 10/3 11/3 12/3 Total Assets Total Net Assets Millions of yen Millions of yen 627,683 593,023 360,376 556,780 555,159 342,231 357,076 344,658 537,211 322,597 08/3 09/3 10/3 11/3 12/3 08/3 09/3 10/3 11/3 12/3 Contents 2 To Our Stakeholders 14 Major Indices 3 At a Glance 16 Segment Information 4 Organization 18 TBS Television 5 Corporate Data 21 Financial Data of Major Group Companies 6 Business Report 23 TBS Networks 10 Consolidated Financial Statements Financial Figures The financial figures used in this report are those used in the Japanese “Tanshin,” which has been created in accordance with the provisions set forth in the Japanese Financial Instruments and Exchange Act. Thus, all figures have been rounded down to the nearest million yen. Forward-Looking Statements This report contains forward-looking statements based on management’s assumptions and beliefs in light of the information currently available. -

From National to International – the Leverage of a Sports Club Brand
FROM NATIONAL TO INTERNATIONAL – THE LEVERAGE OF A SPORTS CLUB BRAND A CASE STUDY OF SPORT CLUB INTERNACIONAL ANUAR JOMAA 870716-T579 SOUD NASIR 880829-1119 School of Business, Society and Engineering Course: Master Thesis in Business Administration Course code: EFO 704 Tutor: Konstantin Lampou 15 hp Examinator: [Eva Maanien-Olsson] Date: [2015-05-29] CONTENT SUMMARY DATE June 4th, 2015 UNIVERSITY Mälardalen University School of Business, Society and Engineering COURSE Master Thesis in Business Administration COURSE CODE EFO704 AUTHORS Anuar Jomaa Soud Nasir SUPERVISOR Konstantin Lampou EXAMINER Eva Maanien-Olsson TITLE From National to International – The Leverage of a Sports Club Brand: A Case Study of Sport Club Internacional ABSTRACT Sports clubs position themselves as brands in order to capitalize the emotional feelings they generate. This study examines sports clubs as entities and well- managed organizations, and takes into consideration all the challenges a club undergoes to achieve strong brand equity. To gain further recognition and expand its brand besides the national market, clubs need to internationalize. The purpose is to investigate the internationalization through a conceptual approach, illustrating it through the case study of the Brazilian football club Sport Club Internacional. RESEARCH How does brand equity affect sports clubs in their internationalization process? QUESTION PURPOSE The purpose of this study is to examine and understand how sports clubs develop their brand equity in their process of internationalization using a football club as a case study. METHODOLOGY This thesis uses primary data and existing literature to establish its findings. Qualitative analysis was carried out with managers of the case study club. -

Bab I Pendahuluan
BAB I PENDAHULUAN 1.1 Latar Belakang Masalah Sepak bola merupakan salah satu olahraga yang paling populer diseluruh penjuru dunia. Sepak bola sendiri dimainkan secara tim yang terdiri dari 11 orang didalam 1 tim. Olahraga ini juga dianggap sebagai olahraga yang menyatukan banyak kalangan tidak hanya digemari oleh kaum laki-laki, tetapi juga sekarang sudah banyak diminati oleh kaum perempuan .Awalnya permainan sepak bola hanya mencakup kawasan benua Eropa saja, tapi lambat laun mengikutin perkembangan zaman sepak bola mulai merambah kebenua lain seperti Asia, Amerika dan Afrika. Di negara Jepang sendiri sepak bola untuk pertama kalinya dikenalkan secara resmi pada masa Zaman Meiji (23 Oktober 1868-30Juli 1912) atau tepatnya pada tahun 1873, perkenalan ini bersamaan dengan banyak olahraga asing lainnya yang diperkenakan ke pemerintah Jepang oleh para penasehat asing pada Zaman Meiji. Olahraga sepak bola diperkenalkan oleh seorang penasehat asing bernama Comander Douglas yang berasal dari Inggris. Seorang komanda angkatan laut Kerajaan Inggris yang mengajar disebua sekolah militer di Tokyo. Ia memperkenalkan cara menendang bola seperti yang dilakukan pada saat sekarang ini kepada seluruh murid di sekolah militer tersebut. Hal ini menarik, karena secara tidak langsung pemerintah Inggris, selain membantu Jepang dalam bidang militer, tetapi juga membantu Jepang dalam bidang olahraga sepak bola. Sehingga pihak Inggris melalui FA (Football Assosiation) turut serta terlibat dalam pembentukan dari JFA(Japan Football Assosiation). (Football In Japan, 2008) Belum lama berlalu, sekitar tiga puluh tahunan yang lalu, sepak bola adalah sebuah olahraga yang asing di negara Jepang. Masyarakat Jepang pada umumnya lebih suka untuk bermain baseball/yakkyu daripada sepak bola. Liga Baseball, cenderung lebih diminati oleh masyarakat tingkat kepopuleran liga baseball di Jepang memang cukup luar biasa. -
Abkürzungsverzeichnis
ABKÜRZUNGSVERZEICHNIS AAC Afro-Asian Cup of Nations AAG Afro-Asian Games AAT Addis-Ababa 25th Anniversary Tournament AC Argentine-Ministry of Education Cup AFC AFC IOFC Challenger-Cup AFT Artemio Franchi Trophy AG African Games ACC Amilcar Cabral Cup AGC Australien Bicentenary Gold Cup AHS 92nd Annivasary of FC Hajduk Split ALT Algeria Tournament AMC Albena Mobitel Cup ANC African Nations Cup ANQ African Nations Cup Qualifikation ARA Arab Cup ARC Artigas Cup ARQ Arab Cup Qualifikation ARR Artificial Riva Championship ASC Asien Cup ASG Asian Games ASQ Asien Cup Qualifikation AT Australia Tournament ATC Atlantic Cup BAC Baltic Cup BAT Belier d'Afrique Tournament BC British Championship BFC Bristol Freedon Cup BFT Burkina Faso Tournament BG Bolivar Games BHT Bahrain Tournament BI Beijing Invitational Cup BIC Brasil Independance Cup BKC Balkan Cup BLC Balkan Cup BNC Brasil Nations Cup BOT Botswana Tournament BSC Black Stars Championship BST Benin Solidarity Tournament BT Brunei Tournament BUT Bulgarien Tournament CA Copa Amerika CAC Caribbean Cup CAG Central African Games CAM Central American Games CAQ Copa Amerika Qualifikation CBC Carlsberg Cup CC Canada Cup CCC Copa Centenario de Chile CCF CCCF Championship CCQ Caribbean Cup / Copa Caribe Qualifikation CCU Caribbean Cup / Copa Caribe CCV Copa Ciudad de Valparaiso CDC Carlo-Dittborn-Cup CDM Ciudad de Mexiko CDP Copa de la Paz CDO Copa D´Oro CEC CECAFA Cup CED CEDEAU Tournament CEM CEMAC Cup CFN China Four Nations Tournament CGC Concacaf Gold Cup Championship CGQ Concacaf Gold Cup Qualifikation CHC Challenger Cup CIC China Invitional Cup CN Coupe Novembre COC Concacaf Championship CON Confederations Cup COS COSAFA Cup CPD Cope-Pinto-Duran CT Cyprus Tournament CUT Culture Cup CVT Cape Verde Tournament DC Dynasty Cup DCT Denmark Centenary Tournament DRK Dr. -

Kirin Group Sustainability Report 2012
KIRIN GROUP SUSTAINABILITY REPORT 2012 For inquiries, contact : CSR Management DepartmentKirin Holdings Company, Limited 2-10-1 Shinkawa, Chuo-ku Tokyo 104-8288, Japan www.kirinholdings.co. jp/english/ ■ Published August 2012 Next report to be published May 2013 Table of Contents KIRIN GROUP SUSTAINABILITY REPORT 2012 About Kirin Group Sustainability Report 2012 2 About Kirin Group Sustainability Report 2012 Reporting Period 3 Company Profile January 1, 2011 to December 31, 2011. Please note that The Kirin Group operates in the food and health industries. Whatever we do, we strive to environmental performance data for the Kyowa Hakko Kirin Group 4 Top Management Commitment ensure that the natural environment will continue to be the source of food; wherever we cover the period April 1, 2010 through March 31, 2011, with the 6 Special Report: Better Prepared for Natural Disasters operate, we seek to help society achieve sustainable development. That is why we call this exception of energy-use data that cover the period January 1, 2011 through December 31, 2011. 8 Feature Story: Kirin Group Extends Assistance in Reconstruction a sustainability report. In this report, we share with you and update you on our philosophy, Efforts for Communities Affected by the Great East Japan Earthquake policy, and initiatives to carry out our corporate social responsibility (CSR). Scope of Reporting and Data Compilation —Kirin KIZUNA Relief-Support Project Where applicable, this report covers activities and accomplishments 12 About Kirin Group by Kirin Holdings Co., Ltd. and its 263 consolidated subsidiaries 16 Our Philosophy Toward CSR Editorial Policy in Japan and abroad (as of December 2011), which collectively constitute the Kirin Group. -

Mensaje 130:CSF.Qxd
A Ñ O X X I V N º 130 MARZO - ABRIL 2012 CONFEDERACIÓN SUDAMERICANA DE FÚTBOL 130 MARZO - ABRIL 2012 - ESPAÑOL / INGLÉS º C O N M E B O L N Santander elegido Mejor Banco de América Latina* MARCAMOS EL MEJOR RESULTADO Para Banco Santander ser considerado el Mejor Banco de América Latina es una gran satisfacción. Llevarlo a la práctica con cada uno de nuestros 102 millones de clientes y con 3,3 millones de accionistas, nuestro objetivo. Patrocinador oficial de la Copa Santander Libertadores. futbolsantander.com El Valor de las Ideas * Según la revista Global Finance PRESERVAR EL ESPÍRITU INDEPENDIENTE DEL FÚTBOL Preserving the independet spirit of Football n los primeros días de febrero se celebró en Paraguay un uring the first days of February, a CONMEBOL Congreso Extraordinario de la CONMEBOL, el cual no ol- Extraordinary Congress was held in Paraguay, which will Evidaremos. Después de mucho tiempo, se hizo una com- Dnever be forgotten. After a long time, a thorough pleta revisión de su estatuto, modernizando la herramienta revision of its by-laws was made, updating the principles that que rige su desenvolvimiento. rule its development. Fueron jornadas de intenso debate, con posturas disími- Those were days of an intense debate, with dissimilar les, en las cuales volvió a vencer el respeto y a imponerse la viewpoints in which respect was the winner and the maturity of madurez de los dirigentes de las diez asociaciones nacionales the leaders of the ten member national associations had the miembro, los que, trabajando juntos, han convertido a Su- upper hand, so that all of them working together have made of damérica no sólo en una potencia futbolística sino también en South America not only a football power but also an important una fuerza política importante pese a ser, en número, la más political stronghold, despite being in numbers, the smallest of pequeña de las agrupaciones continentales que componen el the continental associations that compose associated football fútbol asociado en el mundo. -

Proceedings of the ACL 2016 Student Research Workshop
ACL 2016 The 54th Annual Meeting of the Association for Computational Linguistics Proceedings of the Student Research Workshop August 7-12, 2016 Berlin, Germany c 2016 The Association for Computational Linguistics Order copies of this and other ACL proceedings from: Association for Computational Linguistics (ACL) 209 N. Eighth Street Stroudsburg, PA 18360 USA Tel: +1-570-476-8006 Fax: +1-570-476-0860 [email protected] ISBN 978-1-945626-02-9 ii Introduction Welcome to the ACL 2016 Student Research Workshop! Following the tradition of the previous years’ workshops, we have two tracks: research papers and thesis proposals. The research papers track is as a venue for Ph.D. students, masters students, and advanced undergraduates to describe completed work or work-in-progress along with preliminary results. The thesis proposal track is offered for advanced Ph.D. students who have decided on a thesis topic and are interested in feedback about their proposal and ideas about future directions for their work. We received in total 60 submissions: 14 thesis proposals and 46 research papers, more than twice as many as were submitted last year. Of these, we accepted 4 thesis proposals and 18 research papers, giving an acceptance rate of 36% overall. This year, all of the accepted papers will be presented as posters alongside the main conference short paper posters on the second day of the conference. Mentoring programs are a central part of the SRW. This year, students had the opportunity to participate in a pre-submission mentoring program prior to the submission deadline. The mentoring offers students a chance to receive comments from an experienced researcher in the field, in order to improve the quality of the writing and presentation before making their final submission. -

The Kirin Group CSR Report 2008
The Kirin Group CSR Report 2008 Inquiries Kirin Holdings Company, Limited CSR Management Dept. 10-1 Shinkawa 2-chome, Chuo-ku, Tokyo 104-8288, Japan Tel: +81-3-5540-3454 Fax: +81-3-5540-3550 http://www.kirinholdings.co.jp/english/index.html Publication information Latest publication: July 2008 Next scheduled publication: July 2009 Company Profile Editorial Policy The Kirin Group has positioned CSR as a subject of approaches Trade Name Kirin Holdings Company, Limited for remaining trusted by society at large, and is pursuing various activities to this end. In this report, which was prepared February 23, 1907 to depict the facts of these activities, we incorporated the On July 1, 2007, accompanying the shift to a pure holding Date of Incorporation company structure, Kirin Holdings Company, Limited comments of many Group employees and endeavored to profile changed its name from Kirin Brewery Company, Limited. what we value in plain and simple terms. 10-1 Shinkawa 2-chome, Chuo-ku, Tokyo Location of Head We also included the views expressed by third parties on each Office 104-8288, Japan Tel: +81-3-5541-5321 (Information desk) activity. President and CEO Kazuyasu Kato ● Period reported FY2007 (January 1 to December 31, 2007 including some activities and initiatives taken in 2008) Paid-in Capital 102,045,793,357 yen ● Scope of this report Sales Consolidated: 1,801,164 million yen Kirin Holdings Company, Limited and its main operating (January 1 to December 31, 2007) companies Strategic management and oversight of Main Businesses Group, and provision of specialized services ● Guidelines referenced “Environmental Reporting Guidelines 2007” by the Ministry of 256 the Environment Number of Employees (Group’s consolidated employee number : 27,543) “Sustainability Reporting Guidelines (version 3)” by the GRI (Global Reporting Initiative) Consolidated Group Consolidated subsidiaries: 345 Companies Affiliates under the equity method: 22 The comparison table for the GRI guidelines is available on our website. -
Premium Spaces 2X9.5
premiumwww.luchatv.com spaces $100 2x9.5 www.chicaGosoccermeDia.com live online raDio 3 Petrov: Muamba’s recovery inspires leukemia fight Aston Villa captain Stiliyan Petrov is hopeful of a full recovery from acute leukemia, inspired by Fabrice Muamba’s continued fightback from his on-field cardiac arrest. A photo of Muamba sitting up and smiling appeared on his Twitter account on Friday, the day Petrov’s illness was announced. It is still unclear whether Muamba will ever be able to play professionally but his recovery since collapsing on the field two weeks ago has been unexpectedly strong. “With the help and love of my family, my teammates, all of my friends in football, Aston Villa Football Club and all of the fans, I am sure I will beat this illness and I am determined to do this,” Petrov said in a statement on Saturday. “I saw the picture released yesterday by Fabrice Muamba, my fellow player, and it has inspired me - as has all of the support in the past 24 hours.” The 32-year-old Petrov was diagnosed with leukemia after he developed a fever following last weekend’s Premier League match against Arsenal. The Bulgaria international is due to begin treatment in a London hospital on Monday but still attended Saturday’s match against Chelsea at Villa Park. Petrov was visibly emotional as he waved from the stands to the fans giving him a standing ovation. “For me, football will have to take a back seat for a while, but I’m here to support my teammates today and I will continue to support them, as I know they will support me,” Petrov said. -
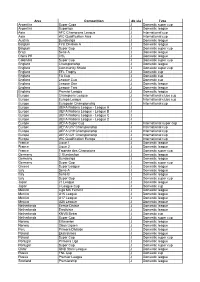
Coverage List 2018-11-22.Xlsx
Area Competition db sla Type Argentina Super Copa J Domestic super cup Argentina Superliga J Domestic league Asia AFC Champions League J International cup Asia WC Qualification Asia J International cup Austria Bundesliga J Domestic league Belgium First Division A J Domestic league Belgium Super Cup J Domestic super cup Brazil Serie A J Domestic league China PR CSL J Domestic league Colombia Super Cup J Domestic super cup England Championship J Domestic league England Community Shield J Domestic super cup England EFL Trophy J Domestic cup England FA Cup J Domestic cup England League Cup J Domestic cup England League One J Domestic league England League Two J Domestic league England Premier League J Domestic league Europe Champions League J International clubs cup Europe Europa League J International clubs cup Europe European Championship J International cup Europe UEFA Nations League - League A J Europe UEFA Nations League - League B J Europe UEFA Nations League - League C J Europe UEFA Nations League - League D J Europe UEFA Super Cup J International super cup Europe UEFA U17 Championship J International cup Europe UEFA U19 Championship J International cup Europe UEFA U21 Championship J International cup Europe WC Qualification Europe J International cup France Ligue 1 J Domestic league France Ligue 2 J Domestic league France Trophée des Champions J Domestic super cup Germany 2. Bundesliga J Domestic league Germany Bundesliga J Domestic league Germany Super Cup J Domestic super cup Greece Super League J Domestic league Italy Serie A J