Maximum Likelihood Estimation for Discrete Determinantal Point Processes
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Maximum Likelihood Estimation in Latent Class Models for Contingency Table Data
Maximum Likelihood Estimation in Latent Class Models for Contingency Table Data Stephen E. Fienberg Department of Statistics, Machine Learning Department and Cylab Carnegie Mellon University Pittsburgh, PA 15213-3890 USA Patricia Hersh Department of Mathematics Indiana University Bloomington, IN 47405-7000 USA Alessandro Rinaldo Department of Statistics Carnegie Mellon University Pittsburgh, PA 15213-3890 USA Yi Zhou Machine Learning Department Carnegie Mellon University Pittsburgh, PA 15213-3890 USA i ii Abstract Statistical models with latent structure have a history going back to the 1950s and have seen widespread use in the social sciences and, more re- cently, in computational biology and in machine learning. Here we study the basic latent class model proposed originally by the sociologist Paul F. Lazarfeld for categorical variables, and we explain its geometric struc- ture. We draw parallels between the statistical and geometric properties of latent class models and we illustrate geometrically the causes of many problems associated with maximum likelihood estimation and related sta- tistical inference. In particular, we focus on issues of non-identifiability and determination of the model dimension, of maximization of the like- lihood function and on the effect of symmetric data. We illustrate these phenomena with a variety of synthetic and real-life tables, of different di- mensions and complexities. Much of the motivation for this work stems from the “100 Swiss Franks” problem, which we introduce and describe in detail. Keywords: latent class model, algebraic geometry, variety, Segre vari- ety, secant variety, effective dimension. CONTENTS iii Contents 1 Introduction 1 2 Latent Class Models for Contingency Tables 2 3 Geometric Description of Latent Class Models 4 4 Examples Involving Synthetic Data 8 4.1 Effective Dimension and Polynomials . -

An ANOVA Test for Parameter Estimability Using Data Cloning with Application to Statistical
An ANOVA Test for Parameter Estimability using Data Cloning with Application to Statistical Inference for Dynamic Systems Corresponding Author: David Campbell Department of Statistics and Actuarial Science Simon Fraser University Surrey, BC V3T 0A3 Canada [email protected] Subhash Lele Department of Mathematical and Statistical Sciences University of Alberta Edmonton, AB T6G 2G1 Canada [email protected] Abstract: Models for complex systems are often built with more parameters than can be uniquely identified by available data. Because of the variety of causes, identifying a lack of parameter identifiability typically requires mathematical manipulation of models, monte carlo simulations, and examination of the Fisher Information Matrix. A simple test for parameter estimability is introduced, using Data Cloning, a Markov Chain Monte Carlo based algorithm. Together, Data cloning and the ANOVA based test determine if the model parameters are estimable and if so, determine their maximum likelihood estimates and provide asymptotic standard errors. When not all model parameters are estimable, the Data Cloning results and the ANOVA test can be used to determine estimable parameter combinations or infer identifiability problems in the model structure. The method is illustrated using three different real data systems that are known to be difficult to analyze. Keywords: Maximum Likelihood Estimation, Over-Parametrized Models, Markov Chain Monte Carlo, Parameter Identifiability, Differential Equation Models 1.INTRODUCTION The ability of dynamic system models to succinctly describe complex behavior with a few but readily interpretable parameters has led to their wide spread popularity. Dynamic system models often try to model all the inherent behavior of the underlying process but the observations do not always have adequate information to support such complexity, leading to parameter inestimability. -

Lecture 5 Identifiability
Lecture 5 The Maximum Likelihood method is essentially the only estimation method used in tag recovery or capture recapture models. Theory goes back to R. A. Fisher in 1912 (when he was a third year undergraduate!) and a flurry of later papers. Actually, Edwards (1974) traces the history of such thinking back to Daniel Bernoulli and Johann Lambert in the 18th century. Maximum likelihood is the primary estimation method in statistics. Likelihood Theory is the Foundation of Statistics! The probability of mortality (1–S ) includes harvest mortality (including fish killed, but not retrieved) and “natural" mortality. SS is the probability of survival from one tagging period to the next. 1– is the probability of mortality and includes both harvest and “natural" mortality. This seems odds, at first, because the data relate to only harvest mortality that is reported. Generally, tag recovery data do not allow estimates of the 2 components (i.e., harvest vs. natural mortality). Note that the estimates of survival (SS ) or mortality (1– ) are based on the data from the harvest! Haunting Question: If one had only R" and m, """#"$"% m, m, m, and m "& , could they compute MLEs of Sr and ? Why not? Under what model? Can you see where the assumptions in these models and estimation methods come from? Why are the assumptions explicit? In the analysis of real data, one must be very concerned about the validity of the assumptions made. If an assumption fails, the method may be very dependent upon the truth of the assumption and large bias in the MLEs may result. -

Identifiability of Mixtures of Power-Series Distributions and Related Characterizations
Ann. Inst. Statist. Math. Vol. 47, No. 3, 447-459 (1995) IDENTIFIABILITY OF MIXTURES OF POWER-SERIES DISTRIBUTIONS AND RELATED CHARACTERIZATIONS THEOFANIS SAPATINAS Department of Mathematical Statistics and Operational Research, Exeter University, Exeter EX4-$QE, U.K. (Received January 28, 1994; revised October 24, 1994) Abstract. The concept of the identifiability of mixtures of distributions is discussed and a sufficient condition for the identifiability of the mixture of a large class of discrete distributions, namely that of the power-series distribu- tions, is given. Specifically, by using probabilistic arguments, an elementary and shorter proof of the Liixmann-Ellinghaus's (1987, Statist. Probab. Lett., 5, 375-378) result is obtained. Moreover, it is shown that this result is a spe- cial case of a stronger result connected with the Stieltjes moment problem. Some recent observations due to Singh and Vasudeva (1984, J. Indian Statist. Assoc., 22, 93 96) and Johnson and Kotz (1989, Ann. Inst. Statist. Math., 41, 13-17) concerning characterizations based on conditional distributions are also revealed as special cases of this latter result. Exploiting the notion of the identifiability of power-series mixtures, characterizations based on regression functions (posterior expectations) are obtained. Finally, multivariate general- izations of the preceding results have also been addressed. Key words and phrases: Univariate and multivariate power-series distribu- tions, mixtures of distributions, the moment problem, infinite divisibility, pos- terior expectations. 1. Introduction Mixtures of distributions are used in building probability models quite fre- quently in biological and physical sciences. For instance, in order to study certain characteristics in natural populations of fish, a random sample might be taken and the characteristic measured for each member of the sample; since the character- istic varies with the age of the fish, the distribution of the characteristic in the total population will be a mixture of the distribution at different ages. -

Statistical Identification of Synchronous Spiking
Statistical Identification of Synchronous Spiking Matthew T. Harrison1, Asohan Amarasingham2, and Robert E. Kass3 Contents 1 Introduction 2 2 Synchrony and time scale 4 3 Spike trains and firing rate 5 3.1 Point processes, conditional intensities, and firing rates . 7 3.2 Models of conditional intensities . 9 4 Models for coarse temporal dependence 10 4.1 Cross-correlation histogram (CCH) . 11 4.2 Statistical hypothesis testing . 12 4.3 Independent homogeneous Poisson process (HPP) model . 13 4.3.1 Bootstrap approximation . 14 4.3.2 Monte Carlo approximation . 15 4.3.3 Bootstrap . 15 4.3.4 Acceptance bands . 15 4.3.5 Conditional inference . 16 4.3.6 Uniform model and conditional modeling . 16 4.3.7 Model-based correction . 17 4.4 Identical trials models . 17 4.4.1 Joint peri-stimulus time histogram (JPSTH) . 18 4.4.2 Independent inhomogeneous Poisson process (IPP) model . 18 4.4.3 Exchangeable model and trial shuffling . 20 4.4.4 Trial-to-trial variability (TTV) models . 22 4.5 Temporal smoothness models . 23 4.5.1 Independent inhomogeneous slowly-varying Poisson model . 24 4.5.2 ∆-uniform model and jitter . 25 4.5.3 Heuristic spike resampling methods . 27 4.6 Generalized regression models . 27 4.7 Multiple spike trains and more general precise spike timing . 30 4.8 Comparisons across conditions . 31 5 Discussion 32 1Division of Applied Mathematics, Brown University, Providence RI 02912 USA 2Department of Mathematics, City College of New York, New York NY 10031 USA 3Department of Statistics, Carnegie Mellon University, Pittsburgh PA 15213 USA 1 A Probability and random variables 34 A.1 Statistical models and scientific questions . -

The Sufficient and Necessary Condition for the Identifiability And
The Sufficient and Necessary Condition for the Identifiability and Estimability of the DINA Model Yuqi Gu and Gongjun Xu University of Michigan Abstract Cognitive Diagnosis Models (CDMs) are useful statistical tools in cognitive diagno- sis assessment. However, as many other latent variable models, the CDMs often suffer from the non-identifiability issue. This work gives the sufficient and necessary condition for identifiability of the basic DINA model, which not only addresses the open problem in Xu and Zhang (2016, Psychomatrika, 81:625-649) on the minimal requirement for identifiability, but also sheds light on the study of more general CDMs, which often cover DINA as a submodel. Moreover, we show the identifiability condition ensures the consistent estimation of the model parameters. From a practical perspective, the identifiability condition only depends on the Q-matrix structure and is easy to verify, which would provide a guideline for designing statistically valid and estimable cognitive diagnosis tests. Keywords: cognitive diagnosis models, identifiability, estimability, Q-matrix. arXiv:1711.03174v2 [stat.ME] 24 Apr 2018 1 Introduction Cognitive Diagnosis Models (CDMs), also called Diagnostic Classification Models (DCMs), are useful statistical tools in cognitive diagnosis assessment, which aims to achieve a fine- grained decision on an individual's latent attributes, such as skills, knowledge, personality 1 traits, or psychological disorders, based on his or her observed responses to some designed diagnostic items. The CDMs fall into the more general regime of restricted latent class models in the statistics literature, and model the complex relationships among the items, the latent attributes and the item responses for a set of items and a sample of respondents. -
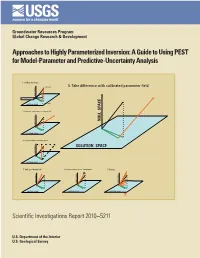
A Guide to Using PEST for Model-Parameter and Predictive-Uncertainty Analysis
Groundwater Resources Program Global Change Research & Development Approaches to Highly Parameterized Inversion: A Guide to Using PEST for Model-Parameter and Predictive-Uncertainty Analysis 1. Calibrate the model p (unknown) 3. Take difference with calibrated parameter field NULL SPACE Total parameter error p (estimated) SOLUTION SPACE 2. Generate a parameter set using C(p) NULL SPACE NULL SPACE SOLUTION SPACE 4. Project difference to null space SOLUTION SPACE NULL SPACE SOLUTION SPACE 5. Add to calibrated field 6. Adjust solution space components 7. Repeat . NULL SPACE NULL SPACE NULL SPACE SOLUTION SPACE SOLUTION SPACE SOLUTION SPACE Scientific Investigations Report 2010–5211 U.S. Department of the Interior U.S. Geological Survey Cover figure Processing steps required for generation of a sequence of calibration-constrained parameter fields by use of the null-space Monte Carlo methodology Approaches to Highly Parameterized Inversion: A Guide to Using PEST for Model-Parameter and Predictive-Uncertainty Analysis By John E. Doherty, Randall J. Hunt, and Matthew J. Tonkin Groundwater Resources Program Global Change Research & Development Scientific Investigations Report 2010–5211 U.S. Department of the Interior U.S. Geological Survey U.S. Department of the Interior KEN SALAZAR, Secretary U.S. Geological Survey Marcia K. McNutt, Director U.S. Geological Survey, Reston, Virginia: 2011 For more information on the USGS—the Federal source for science about the Earth, its natural and living resources, natural hazards, and the environment, visit http://www.usgs.gov or call 1–888–ASK–USGS. For an overview of USGS information products, including maps, imagery, and publications, visit http://www.usgs.gov/pubprod To order this and other USGS information products, visit http://store.usgs.gov Any use of trade, product, or firm names is for descriptive purposes only and does not imply endorsement by the U.S. -

Meanings of Identification in Econometrics
The Identification Zoo - Meanings of Identification in Econometrics Arthur Lewbel Boston College First version January 2016, Final preprint version October 2019, Published version: Journal of Economic Literature, December 2019, 57(4). Abstract Over two dozen different terms for identification appear in the econometrics literature, including set identification, causal identification, local identification, generic identification, weak identification, identification at infinity, and many more. This survey: 1. gives a new framework unifying existing definitions of point identification, 2. summarizes and compares the zooful of different terms associated with identification that appear in the literature, and 3. discusses concepts closely related to identification, such as normalizations and the differences in identification between structural models and causal, reduced form models. JEL codes: C10, B16 Keywords: Identification, Econometrics, Coherence, Completeness, Randomization, Causal inference, Reduced Form Models, Instrumental Variables, Structural Models, Observational Equivalence, Normalizations, Nonparamet- rics, Semiparametrics. I would like to thank Steven Durlauf, Jim Heckman, Judea Pearl, Krishna Pendakur, Frederic Vermeulen, Daniel Ben-Moshe, Xun Tang, Juan-Carlos Escanciano, Jeremy Fox, Eric Renault, Yingying Dong, Laurens Cherchye, Matthew Gentzkow, Fabio Schiantarelli, Andrew Pua, Ping Yu, and five anonymous referees for many helpful sug- gestions. All errors are my own. Corresponding address: Arthur Lewbel, Dept of Economics, Boston College, -

Maximum Likelihood Estimation of a Finite Mixture of Logistic Regression
Maximum likelihood estimation of a finite mixture of logistic regression models in a continuous data stream Prof. dr. M.C. Kaptein Dr. P. Ketelaar Abstract In marketing we are often confronted with a continuous stream of responses to market- ing messages. Such streaming data provide invaluable information regarding message effectiveness and segmentation. However, streaming data are hard to analyze using conventional methods: their high volume and the fact that they are continuously aug- mented means that it takes considerable time to analyze them. We propose a method for estimating a finite mixture of logistic regression models which can be used to cluster cus- tomers based on a continuous stream of responses. This method, which we coin oFMLR, allows segments to be identified in data streams or extremely large static datasets. Con- trary toblack box algorithms, oFMLR provides model estimates that are directly inter- pretable. We first introduce oFMLR, explaining in passing general topics such as online estimation and the EM algorithm, making this paper a high level overview of possible methods of dealing with large data streams in marketing practice. Next, we discuss model convergence, identifiability, and relations to alternative, Bayesian, methods; we also identify more general issues that arise from dealing with continuously augmented data sets. Finally, we introduce the oFMLR [R] package and evaluate the method by numerical simulation and by analyzing a large customer clickstream dataset. Keywords: Clustering, Finite mixture models, Logistic regression, Online estimation, Expectation-Maximization. 1 Introduction In marketing we are often confronted with continuous data streams of customer behavior (Su and Chen, 2015; Chatterjee et al., 2003; Moe and Fader, 2004; Bucklin and Sismeiro, 2009). -

Core Guide: Correlation Structures in Mixed Effects Models for Longitudinal Data Analysis
Core Guide: Correlation Structures in Mixed Effects Models for Longitudinal Data Analysis Part of a series addressing common issues in statistical and epidemiological design and analysis Background Longitudinal data, also commonly called repeated measures data, is defined as data collected on subjects, or another unit of analysis (e.g., village) repeatedly over time. Whereas a time series usually includes a long time series on a single (or small number of) sequences, repeated measures are typically measured on a relatively large number of subjects over a more limited period of time. Measurements may be approximately equally spaced, as may be the case in carefully controlled laboratory studies or clinical trials, or unequally spaced, as may be the case in electronic health records (EHR) data where subjects are measured when they happen to go to the doctor. Longitudinal data may also be balanced (i.e., having the same number of measures on each subject) or unbalanced. Two primary methods of choice for analyzing the relationship between an outcome and time (and other covariates) are generalized estimating equations (GEE) and mixed-effects models (see Fitzmaurice, Laird, and Ware (2011)1 for detailed background on each method). The current guide focuses on mixed-effects models, commonly referred to succinctly as “mixed models”. When data are repeatedly measured on the same subject over time, data collected on the same individual are generally positively correlated with each other. For example, my weight today is generally correlated with my weight one month from now, and my current risk of malaria is often correlated with my risk last month, as well as last year at the same time (seasonal effect). -

Regression Discontinuity Design with Multivalued Treatments∗
Regression Discontinuity Design with Multivalued Treatments∗ Carolina Caetano Gregorio Caetano Juan Carlos Escancianoy University of Georgia University of Georgia Universidad Carlos III de Madrid June 2020 Abstract We study identification and estimation in the Regression Discontinuity Design (RDD) with a multivalued treatment variable. We also allow for the inclusion of covariates. We show that with- out additional information, treatment effects are not identified. We give necessary and sufficient conditions that lead to identification of LATEs as well as of weighted averages of the conditional LATEs. We show that if the first stage discontinuities of the multiple treatments conditional on covariates are linearly independent, then it is possible to identify multivariate weighted averages of the treatment effects with convenient identifiable weights. If, moreover, treatment effects do not vary with some covariates or a flexible parametric structure can be assumed, it is possible to identify (in fact, over-identify) all the treatment effects. The over-identification can be used to test these assumptions. We propose a simple estimator, which can be programmed in packaged software as a Two-Stage Least Squares regression, and packaged standard errors and tests can also be used. Finally, we implement our approach to identify the effects of different types of insurance coverage on health care utilization, as in Card, Dobkin and Maestas(2008). Keywords: Regression Discontinuity Design; Multiple Treatments; Over-identifying restrictions; Nonparametric; LATE; Medicare; Health Insurance. JEL classification: C13; C14; C21; I13 arXiv:2007.00185v1 [econ.EM] 1 Jul 2020 ∗We would like to thank numerous seminar participants at various departments and conferences since 2014 for useful comments. -

Logistic Regression
CHAPTER 5 Logistic regression Logistic regression is the standard way to model binary outcomes (that is, data yi that take on the values 0 or 1). Section 5.1 introduces logistic regression in a simple example with one predictor, then for most of the rest of the chapter we work through an extended example with multiple predictors and interactions. 5.1 Logistic regression with a single predictor Example: modeling political preference given income Conservative parties generally receive more support among voters with higher in- comes. We illustrate classical logistic regression with a simple analysis of this pat- tern from the National Election Study in 1992. For each respondent i in this poll, we label yi =1ifheorshepreferredGeorgeBush(theRepublicancandidatefor president) or 0 if he or she preferred Bill Clinton (the Democratic candidate), for now excluding respondents who preferred Ross Perot or other candidates, or had no opinion. We predict preferences given the respondent’s income level, which is characterized on a five-point scale.1 The data are shown as (jittered) dots in Figure 5.1, along with the fitted logistic regression line, a curve that is constrained to lie between 0 and 1. We interpret the line as the probability that y =1givenx—in mathematical notation, Pr(y =1x). We fit and display the logistic regression using the following R function calls:| fit.1 <- glm (vote ~ income, family=binomial(link="logit")) Rcode display (fit.1) to yield coef.est coef.se Routput (Intercept) -1.40 0.19 income 0.33 0.06 n=1179,k=2 residual deviance = 1556.9, null deviance = 1591.2 (difference = 34.3) 1 The fitted model is Pr(yi =1)=logit− ( 1.40 + 0.33 income).