Winter Shower in India - a Neurocomputing Based Predictive Model
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Potential Vorticity
POTENTIAL VORTICITY Roger K. Smith March 3, 2003 Contents 1 Potential Vorticity Thinking - How might it help the fore- caster? 2 1.1Introduction............................ 2 1.2WhatisPV-thinking?...................... 4 1.3Examplesof‘PV-thinking’.................... 7 1.3.1 A thought-experiment for understanding tropical cy- clonemotion........................ 7 1.3.2 Kelvin-Helmholtz shear instability . ......... 9 1.3.3 Rossby wave propagation in a β-planechannel..... 12 1.4ThestructureofEPVintheatmosphere............ 13 1.4.1 Isentropicpotentialvorticitymaps........... 14 1.4.2 The vertical structure of upper-air PV anomalies . 18 2 A Potential Vorticity view of cyclogenesis 21 2.1PreliminaryIdeas......................... 21 2.2SurfacelayersofPV....................... 21 2.3Potentialvorticitygradientwaves................ 23 2.4 Baroclinic Instability . .................... 28 2.5 Applications to understanding cyclogenesis . ......... 30 3 Invertibility, iso-PV charts, diabatic and frictional effects. 33 3.1 Invertibility of EPV ........................ 33 3.2Iso-PVcharts........................... 33 3.3Diabaticandfrictionaleffects.................. 34 3.4Theeffectsofdiabaticheatingoncyclogenesis......... 36 3.5Thedemiseofcutofflowsandblockinganticyclones...... 36 3.6AdvantageofPVanalysisofcutofflows............. 37 3.7ThePVstructureoftropicalcyclones.............. 37 1 Chapter 1 Potential Vorticity Thinking - How might it help the forecaster? 1.1 Introduction A review paper on the applications of Potential Vorticity (PV-) concepts by Brian -

Statistical Single-Station Short-Term Forecasting of Temperature and Probability of Precipitation: Area Interpolation and NWP Combination
APRIL 1999 RAIBLE ET AL. 203 Statistical Single-Station Short-Term Forecasting of Temperature and Probability of Precipitation: Area Interpolation and NWP Combination CHRISTOPH C. RAIBLE,GEORG BISCHOF,KLAUS FRAEDRICH, AND EDILBERT KIRK Meteorologisches Institut, UniversitaÈt Hamburg, Hamburg, Germany (Manuscript received 18 February 1998, in ®nal form 21 October 1998) ABSTRACT Two statistical single-station short-term forecast schemes are introduced and applied to real-time weather prediction. A multiple regression model (R model) predicting the temperature anomaly and a multiple regression Markov model (M model) forecasting the probability of precipitation are shown. The following forecast ex- periments conducted for central European weather stations are analyzed: (a) The single-station performance of the statistical models, (b) a linear error minimizing combination of independent forecasts of numerical weather prediction and statistical models, and (c) the forecast representation for a region deduced by applying a suitable interpolation technique. This leads to an operational weather forecasting system for the temperature anomaly and the probability of precipitation; the statistical techniques demonstrated provide a potential for future ap- plications in operational weather forecasts. 1. Introduction (Wilson 1985; Dallavalle 1996; KnuÈpffer 1996) as well Although, in general, numerical weather prediction as the long-term prediction (more than a month ahead) (NWP) models are hard to beat in very short-term fore- of monthly mean temperature (Nicholls 1980; Navato casting (up to 24 h), they do require a substantial amount 1981; Madden 1981; Norton 1985). Thus, the ®rst pur- of computation time and the model forecasts are not pose of this paper is to set up a statistical model of always stable at this timescale. -

ISSUES : DATA SET Investigating the Footprint of Climate Change On
- 1 - TIEE Teaching Issues and Experiments in Ecology - Volume 10, April 2014 ISSUES : DATA SET Investigating the footprint of climate change on phenology and ecological interactions in north-central North America Kellen M. Calinger Department of Evolution, Ecology, and Organismal Biology, The Ohio State University, Columbus, OH 43210-1293; [email protected] THE ECOLOGICAL QUESTION: Have long-term temperatures changed throughout Ohio? How will these temperature changes impact plant and animal phenology, ecological interactions, and, as a result, species diversity? ECOLOGICAL CONTENT: Climate change, phenology, pollinators, trophic mismatch, species diversity, arrival time, mutualism WHAT STUDENTS DO: o Produce and analyze graphs of temperature change using large, long-term data sets (Synthesis, Analysis) o Develop methods for calculating species-specific shifts in flowering time with temperature increase (Synthesis) o Use these methods to calculate flowering shifts in six plant Aquilegia canadensis (red columbine) species (Application) flowering with open and closed flowers o Describe the ecological consequences of shifting plant and animal phenology (Comprehension) o Understand how interactions between species as well as with their abiotic environment affect community structure and species diversity (Knowledge, Comprehension) o Evaluate data “cherry-picking” as a climate change skeptic tactic (Evaluation) STUDENT-ACTIVE APPROACHES: Open-ended inquiry, guided inquiry, cooperative learning, critical thinking SKILLS: Work with large data sets, create and analyze multiple types of graphs, connect the development of procedures and data analysis to clarifying ecological impacts of climate change ASSESSABLE OUTCOMES: Student-made graphs, calculations of temperature and phenology shifts, answers to short questions, brief paragraphs describing student-generated methods TIEE, Volume 10 © 2014 – Kellen M. -

A Review of Ocean/Sea Subsurface Water Temperature Studies from Remote Sensing and Non-Remote Sensing Methods
water Review A Review of Ocean/Sea Subsurface Water Temperature Studies from Remote Sensing and Non-Remote Sensing Methods Elahe Akbari 1,2, Seyed Kazem Alavipanah 1,*, Mehrdad Jeihouni 1, Mohammad Hajeb 1,3, Dagmar Haase 4,5 and Sadroddin Alavipanah 4 1 Department of Remote Sensing and GIS, Faculty of Geography, University of Tehran, Tehran 1417853933, Iran; [email protected] (E.A.); [email protected] (M.J.); [email protected] (M.H.) 2 Department of Climatology and Geomorphology, Faculty of Geography and Environmental Sciences, Hakim Sabzevari University, Sabzevar 9617976487, Iran 3 Department of Remote Sensing and GIS, Shahid Beheshti University, Tehran 1983963113, Iran 4 Department of Geography, Humboldt University of Berlin, Unter den Linden 6, 10099 Berlin, Germany; [email protected] (D.H.); [email protected] (S.A.) 5 Department of Computational Landscape Ecology, Helmholtz Centre for Environmental Research UFZ, 04318 Leipzig, Germany * Correspondence: [email protected]; Tel.: +98-21-6111-3536 Received: 3 October 2017; Accepted: 16 November 2017; Published: 14 December 2017 Abstract: Oceans/Seas are important components of Earth that are affected by global warming and climate change. Recent studies have indicated that the deeper oceans are responsible for climate variability by changing the Earth’s ecosystem; therefore, assessing them has become more important. Remote sensing can provide sea surface data at high spatial/temporal resolution and with large spatial coverage, which allows for remarkable discoveries in the ocean sciences. The deep layers of the ocean/sea, however, cannot be directly detected by satellite remote sensors. -

Appendix a Gempak Parameters
GEMPAK Parameters APPENDIX A GEMPAK PARAMETERS This appendix contains a list of the GEMPAK parameters. Algorithms used in computing these parameters are also included. The following constants are used in the computations: KAPPA = Poisson's constant = 2 / 7 G = Gravitational constant = 9.80616 m/sec/sec GAMUSD = Standard atmospheric lapse rate = 6.5 K/km RDGAS = Gas constant for dry air = 287.04 J/K/kg PI = Circumference / diameter = 3.14159265 References for some of the algorithms: Bolton, D., 1980: The computation of equivalent potential temperature., Monthly Weather Review, 108, pp 1046-1053. Miller, R.C., 1972: Notes on Severe Storm Forecasting Procedures of the Air Force Global Weather Central, AWS Tech. Report 200. Wallace, J.M., P.V. Hobbs, 1977: Atmospheric Science, Academic Press, 467 pp. TEMPERATURE PARAMETERS TMPC - Temperature in Celsius TMPF - Temperature in Fahrenheit TMPK - Temperature in Kelvin STHA - Surface potential temperature in Kelvin STHK - Surface potential temperature in Kelvin N-AWIPS 5.6.L User’s Guide A-1 October 2003 GEMPAK Parameters STHC - Surface potential temperature in Celsius STHE - Surface equivalent potential temperature in Kelvin STHS - Surface saturation equivalent pot. temperature in Kelvin THTA - Potential temperature in Kelvin THTK - Potential temperature in Kelvin THTC - Potential temperature in Celsius THTE - Equivalent potential temperature in Kelvin THTS - Saturation equivalent pot. temperature in Kelvin TVRK - Virtual temperature in Kelvin TVRC - Virtual temperature in Celsius TVRF - Virtual -

Genesis of Diamond Dust and Thick Cloud Episodes Observed Above Dome C, Antarctica by Ricaud Et Al
Manuscript Title: Genesis of Diamond Dust and Thick Cloud Episodes observed above Dome C, Antarctica by Ricaud et al. RESPONSES TO THE REVIEWERS We would like to thank the reviewers for their insightful comments that were helpful in improving substantially the presentation and contents of the revised manuscript. We have addressed appropriately all issues raised by the reviewers. The reviewers' comments are repeated below in blue and our responses appear in black. The title has been modified into: Genesis of Diamond Dust, Ice Fog and Thick Cloud Episodes observed and modelled above Dome C, Antarctica We have inserted this sentence in the acknowledgments: We finally would like to thank the two anonymous reviewers to their fruitful comments. Changes have been highlighted in yellow in the revised manuscript. 1 Anonymous Referee #1 This manuscript intends to study of cold weather conditions (over Antarctica). It focuses on clouds and diamond dust, and various observational platforms and model simulations over more than 1 month of observations. There are several issues with this manuscript and need to be improved significantly before goes to publication. Because of above I see that paper needs to be improved significantly before making a decision if it is appropriate for this ACP. ® Specific changes have been made in response to the reviewers' comments and are described below. Major/minor issues: 1. Objectives are not clearly set up. Lots of information but nothing to do with objectives. ® We have clarified this crucial point. The objectives of the paper are mainly to investigate the processes that cause the presence of thick cloud and diamond dust/ice fog episodes above the Dome C station based on observations and verify whether operational models can evaluate them. -

Predicting Extremes Presenter: Gil Compo
Predicting Extremes Presenter: Gil Compo Subject Matter Experts: Tom Hamill, Marty Hoerling, Matt Newman, Judith Perlwitz NOAA Physical Sciences Laboratory Review November 16-20, 2020 Physical Science for Predicting Extremes Observe Initial focus in What extreme events have happened? How can we measure the important processes? Predicting Extremes is on Users & Stakeholders Subseasonal to Understand Seasonal (S2S) Physical Sciences LaboratoryHow predictable is an extreme event? What are the physical laws governing the processes? Predict Generate improved predictions, consistent with our understanding of the physical laws. By design, PSL’s activities are “predicting Predict the expected forecast skill in advance the nation’s path through a varying and changing climate” consistent with NOAA’s encompassing mission to “understand Communicate and predict changes in climate, weather, Convey what is known and not known about extremes in oceans, and coasts, and to share that ways that facilitate effective decision making. knowledge and information with others.” 2 Goals for Predicting Extremes • Observe Extreme Events Advanced observations Data assimilation Reanalysis • Understand conditional and unconditional (climatological) distributions and their tails What is predictable at what leads? • Improve predictions of these distributions at all leads Even the mean is hard! Only some forecasts may have useful skill – Need to identify “Forecasts of Opportunity” • Communicate new understanding and improved predictions to stakeholders and decision makers -

2017 Edition of ‘Blue Ridge Thunder’ the Biannual Newsletter of the National Weather Service (NWS) Office in Blacksburg, VA
Welcome to the spring 2017 edition of ‘Blue Ridge Thunder’ the biannual newsletter of the National Weather Service (NWS) office in Blacksburg, VA. In this issue you will find articles of interest on the weather and climate of our region and the people and technologies needed to bring accurate forecasts and warnings to the public. Weather Highlight Spring Storms produce tornadoes and flooding Peter Corrigan, Senior Service Hydrologist Inside this Issue: 1: Weather Highlight Late April and early May of 2017 saw a return to a more active Spring storms produce weather pattern across the Blacksburg County Warning Area (CWA). tornadoes and flooding Two tornadoes developed during the overnight hours of May 4-5 as an upper level low tracked across the Tennessee Valley and pushed a 3: GOES 16 Debut complex frontal system through the region overnight. Low level southeast flow led to atmospheric saturation and around 3 AM a line 4: Advances in Lightning of convective storms entered Rockingham County, NC. An embedded Detection cell within this line became briefly tornadic around 312 AM and 5: The new EHWO persisted for six minutes according to the NWS damage assessment survey conducted later that day. The survey team confirmed an EF1 6: Winter 2016-2017 tornado (on the enhanced Fujita scale) with winds as high as 110 Breaks Records mph along a 3.3 mile track through the western portions of Eden. 7: Summer 2017 Outlook 8: Tropical Forecast 9: Heat Safety and Recent WFO Staff Changes Damage from EF1 tornado in Eden, NC – May 5, 2017 Blue Ridge Thunder – Spring 2017 Page 1 While damage was significant, with 25 homes and In late April the story was flooding which occurred nine businesses sustaining damage, there were no as a result of several days of heavy rainfall from injuries or fatalities. -

Resolving Inconsistencies in Extreme Precipitation‐Temperature
RESEARCH LETTER Resolving Inconsistencies in Extreme 10.1029/2020GL089723 Precipitation‐Temperature Key Points: • Correct sampling of dry‐bulb Sensitivities temperature before storm events J. B. Visser1 , C. Wasko2 , A. Sharma1 , and R. Nathan2 resolves inconsistencies in extreme precipitation‐temperature 1School of Civil and Environmental Engineering, University of New South Wales, Sydney, New South Wales, Australia, sensitivities 2 • Previous underestimation of Department of Infrastructure Engineering, University of Melbourne, Parkville, Victoria, Australia sensitivities is likely due to localized cooling and intermittent nature of precipitation Abstract Extreme precipitation events are intensifying with increasing temperatures. However, • ‐ Dry bulb temperature drives observed extreme precipitation‐temperature sensitivities have been found to vary significantly across the short‐duration precipitation extremes, contrary to previous dew globe. Here we show that negative sensitivities found in previous studies are the result of limited point temperature based findings consideration of within‐day temperature variations due to precipitation. We find that short‐duration extreme precipitation can be better described by subdaily atmospheric conditions before the start of storm Supporting Information: events, resulting in positive sensitivities with increased consistency with the Clausius‐Clapeyron relation • Supporting Information S1 across a wide range of climatic regions. Contrary to previous studies that advocate that dew point temperature drives precipitation, dry‐bulb temperature is found to be a sufficient descriptor of precipitation ‐ Correspondence to: variability. We argue that analysis methods for estimating extreme precipitation temperature sensitivities A. Sharma, should account for the strong and prolonged cooling effect of intense precipitation, as well as for the [email protected] intermittent nature of precipitation. Plain Language Summary Increasing global temperatures are likely to result in the Citation: fi fl Visser, J. -

Summary of METROMEX, Volume 2: Causes of Precipitation Anomalies
BULLETIN 63 Summary of METROMEX, Volume 2: Causes of Precipitation Anomalies by B. ACKERMAN, S. A. CHANGNON. JR., ©. DZURISIN, D. L GATZ, R. C. GROSH, S. D. HILBERS, F. A. HUFF, J. W. MANSELL, H. T. OCHS. Ill, M. E. PEDEN, P. T. SCHICKEDANZ, R. G. SEMONIN, and J. L. VOGEL Title: Summary of METROMEX, Volume 2: Causes of Precipitation Anomalies. Abstract: This is the last of two volumes presenting the major findings from the 1971-1975 METROMEX field operations at St. Louis. It presents climatological analyses of surface weath- er conditions, but primarily concerns those factors helping to describe the causes of the anom- alies. Volume 1 covers spatial and temporal distributions of surface precipitation and severe storms, and impacts of urban-produced precipitation anomalies. Volume 2 describes relevant surface weather conditions including temperature, moisture, and winds, all influenced by the urban area. Urban influences extend well into the boundary layer affecting aerosol distribu- tions, winds, and the thermodynamic structure, and often reach cloud base levels. Studies of modification of cloud and rain processes show urban-industrial influences on 1) initiation, local distribution, and characteristics of summer cumulus clouds; and 2) development of precipita- tion in clouds and the resulting surface rain entities. Reference: Ackerman, B., S. A. Changnon, Jr., G. Dzurisin, D. L. Gatz, R. C. Grosh, S. D. Hilberg. F. A. Huff, J. W. Mansell, H. T. Ochs, HI, M. E. Peden, P. T. Schickedanz, R. G. Semohin, and J. L. Vogel. Summary of METROMEX, Volume 2: Causes of Precipitation Anomalies, Illinois State Water Survey, Urbana, Bulletin 63, 1978. -

State of the Climate in 2010
State of the climate in 2010 Citation Blunden, J., D. S. Arndt, and M. O. Baringer. “State of the Climate in 2010.” Bulletin of the American Meteorological Society 92 (2011): S1-S236. Web. 8 Dec. 2011. © 2011 American Meteorological Society As Published http://dx.doi.org/10.1175/1520-0477-92.6.S1 Publisher American Meteorological Society Version Final published version Accessed Mon Mar 26 14:41:06 EDT 2012 Citable Link http://hdl.handle.net/1721.1/67483 Terms of Use Article is made available in accordance with the publisher's policy and may be subject to US copyright law. Please refer to the publisher's site for terms of use. Detailed Terms J. Blunden, D. S. Arndt, and M. O. Baringer, Eds. Associate Eds. H. J. Diamond, A. J. Dolman, R. L. Fogt, B. D. Hall, M. Jeffries, J. M. Levy, J. M. Renwick, J. Richter-Menge, P. W. Thorne, L. A. Vincent, and K. M. Willett Special Supplement to the Bulletin of the American Meteorological Society Vol. 92, No. 6, June 2011 STATE OF THE CLIMATE IN 2010 STATE OF THE CLIMATE IN 2010 JUNE 2011 | S1 HOW TO CITE THIS DOCUMENT __________________________________________________________________________________________ Citing the complete report: Blunden, J., D. S. Arndt, and M. O. Baringer, Eds., 2011: State of the Climate in 2010. Bull. Amer. Meteor. Soc., 92 (6), S1 –S266. Citing a chapter (example): Fogt, R. L., Ed., 2011: Antarctica [in “State of the Climate in 2010”]. Bull. Amer. Meteor. Soc., 92 (6), S161 –S171. Citing a section (example): Wovrosh, A. J., S. Barreira, and R. -
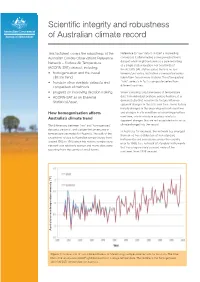
Factsheet on Public Availability of ACORN-SAT
Scientific integrity and robustness of Australian climate record This factsheet covers the robustness of the Reference to ‘raw’ data is in itself a misleading Australian Climate Observations Reference concept as it often implies some pre-adjustment Network – Surface Air Temperature dataset which might be taken as a pure recording at a single station location. For two-thirds of (ACORN-SAT) dataset, including: the ACORN-SAT station series there is no raw • homogenisation and the overall temperature series, but rather a composited series climate trend taken from two or more stations. The often quoted • trends in other available datasets and “raw” series is in fact a composite series from comparison of methods different locations. • progress on improving decision making When compiling long time-series of temperature • ACORN-SAT as an Essential data from individual locations across Australia, it is Statistical Asset. demonstrable that non-climatic factors influence apparent changes in the data over time. These factors include changes in the observing network over time How homogenisation affects and changes in site conditions or observing practices over time, which introduce spurious artefacts Australia’s climate trend (apparent changes that are not associated with actual The differences between ‘raw’ and ‘homogenised’ climate change) into the record. datasets are small, and capture the uncertainty in In Australia, for example, the network has changed temperature estimates for Australia. The bulk of the from an ad-hoc distribution of non-standard uncertainty relates to Australian temperatures from instruments and enclosures across the country around 1910 to 1940 when the national temperature prior to 1908, to a network of standard instruments network was relatively sparser and many sites were that has progressively covered more of the reporting from the centre of small towns.