Improving Random GUI Testing with Image-Based Widget Detection
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Swing: Components for Graphical User Interfaces
Swing: Components for Graphical User Interfaces Computer Science and Engineering College of Engineering The Ohio State University Lecture 22 GUI Computer Science and Engineering The Ohio State University GUI: A Hierarchy of Nested Widgets Computer Science and Engineering The Ohio State University Visual (Containment) Hierarchy Computer Science and Engineering The Ohio State University Top-level widgets: outermost window (a container) Frame, applet, dialog Intermediate widgets: allow nesting (a container) General purpose Panel, scroll pane, tabbed pane, tool bar Special purpose Layered pane Atomic widgets: nothing nested inside Basic controls Button, list, slider, text field Uneditable information displays Label, progress bar, tool tip Interactive displays of highly formatted information Color chooser, file chooser, tree For a visual (“look & feel”) of widgets see: http://java.sun.com/docs/books/tutorial/uiswing/components Vocabulary: Widgets usually referred to as “GUI components” or simply “components” History Computer Science and Engineering The Ohio State University Java 1.0: AWT (Abstract Window Toolkit) Platform-dependent implementations of widgets Java 1.2: Swing Most widgets written entirely in Java More portable Main Swing package: javax.swing Defines various GUI widgets Extensions of classes in AWT Many class names start with “J” Includes 16 nested subpackages javax.swing.event, javax.swing.table, javax.swing.text… Basic GUI widgets include JFrame, JDialog JPanel, JScrollPane, JTabbedPane, -

Proveos User Manual
User Manual Contents Welcome .............................................................................................. 5 How proVEOS Works ...........................................................................................7 Installing the proVEOS Software for Windows ..................................... 9 Configuring Firewall Software .............................................................................10 Installing the Windows proVEOS Software .........................................................14 Signing in to proVEOS ........................................................................................24 Installing the proVEOS Software for Mac........................................... 29 Configuring the Firewall ......................................................................................30 Installing the Mac proVEOS Software.................................................................32 Signing in to proVEOS ........................................................................................34 Presenting with proVEOS ................................................................... 37 Starting a Presentation .......................................................................................40 Managing Participants ........................................................................................40 Chatting with Participants ...................................................................................45 Playing Music and Movies ................................................................ -

Java Programming
CHAPTER 15 Advanced GUI Topics In this chapter, you will: Use content panes Use color Learn more about layout managers Use JPanels to increase layout options Create JScrollPanes Understand events and event handling more thoroughly Use the AWTEvent class methods Handle mouse events Use menus Unless noted otherwise, all images are © 2014 Cengage Learning Copyright 2013 Cengage Learning. All Rights Reserved. May not be copied, scanned, or duplicated, in whole or in part. Due to electronic rights, some third party content may be suppressed from the eBook and/or eChapter(s). Editorial review has deemed that any suppressed content does not materially affect the overall learning experience. Cengage Learning reserves the right to remove additional content at any time if subsequent rights restrictions require it. CHAPTER 15 Advanced GUI Topics Understanding the Content Pane The JFrame class is a top-level container Java Swing class. (The other two top-level container classes are JDialog and JApplet.) Every GUI component that appears on the screen must be part of a containment hierarchy. A containment hierarchy is a tree of components that has a 802 top-level container as its root (that is, at its uppermost level). Every top-level container has a content pane that contains all the visible components in the container’s user interface. The content pane can directly contain components like JButtons, or it can hold other containers, like JPanels, that in turn contain such components. A top-level container can contain a menu bar. A menu bar is a horizontal strip that conventionally is placed at the top of a container and contains user options. -

Software Manual IDEA – the Software
Software Manual IDEA – The Software Version 1.1 Open Technologies Srl WWW.SCANINABOX.COM Copyright © 2016 Open Technologies Srl First printing, June 2016 Contents I Part One 1 IDEA - the application for Scan in a Box .........................7 1.1 Application Interface7 1.1.1 Project management panel..........................................8 1.1.2 3D view panel....................................................9 1.1.3 Toolbar......................................................... 10 1.1.3.1 Project management (orange)........................................... 10 1.1.3.2 Acquisition (bordeaux)................................................ 10 1.1.3.3 Alignment (light blue)................................................. 11 1.1.3.4 Selection (turquoise).................................................. 11 1.1.3.5 Rendering (pink).................................................... 12 1.1.3.6 General (purple).................................................... 12 1.1.3.7 Features specific to range images (blue)..................................... 13 1.1.3.8 Features specific to triangle meshes (light green)................................ 13 2 Using IDEA ................................................... 17 2.1 Optical set-up 17 2.1.1 Optical set-up mode................................................ 19 2.1.2 Calibration of the optical head........................................ 22 2.2 Capture and alignment 25 2.2.1 Free mode acquisition............................................... 26 2.2.2 Turn Table acquisition mode.......................................... -

LWUIT Developer's Guide
Lightweight UI Toolkit Developer’s Guide Part No. 07-08-10 July 2010 Copyright © 2008, 2010 Oracle and/or its affiliates. All rights reserved. This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this is software or related software documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, the following notice is applicable: U.S. GOVERNMENT RIGHTS Programs, software, databases, and related documentation and technical data delivered to U.S. Government customers are "commercial computer software" or "commercial technical data" pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, the use, duplication, disclosure, modification, and adaptation shall be subject to the restrictions and license terms set forth in the applicable Government contract, and, to the extent applicable by the terms of the Government contract, the additional rights set forth in FAR 52.227-19, Commercial Computer Software License (December 2007). Oracle America, Inc., 500 Oracle Parkway, Redwood City, CA 94065. -

COMP1006/1406 Notes 2
COMP1406/1006 - Design and Implementation of Computer Applications Winter 2006 2 Applications and LayoutManagers What's in This Set of Notes? We look here at how to create a graphical user interface (i.e., with windows) in JAVA. Creating GUIs in JAVA requires adding components onto windows. We will find out how to do this as well as look at an interesting JAVA feature called a "LayoutManager" that automatically arranges components on the window. This allows us to create simple windows without having to worry about resizing issues. Here are the individual topics found in this set of notes (click on one to go there): • 2.1 Creating a Basic GUI Application • 2.2 Components and Containers • 2.3 Layout Managers o 2.3.1 NullLayout o 2.3.2 FlowLayout o 2.3.3 BorderLayout o 2.3.4 CardLayout o 2.3.5 GridLayout o 2.3.6 GridBagLayout o 2.3.7 BoxLayout 2.1 Creating a Basic GUI Application Recall that a Graphical User Interface (GUI) is a user interface that has one or more windows. A frame: • is the JAVA terminology for a window (i.e., its a window frame) • represented by the Frame and JFrame classes in JAVA • used to show information and handle user interaction • has no security restrictions ... can modify files, perform I/O, open network connections to other computers, etc.. The following code creates a basic window frame in JAVA and shows it on the screen: javax.swing.JFrame frame = new javax.swing.JFrame("This appears at the top of the window"); frame.setSize(300, 100); frame.setVisible(true); Here is what it looks like: Although this code for bringing up a new window can appear anywhere, we typically designate a whole class to represent the window (that is, the JAVA application). -

Release Notes for Fedora 15
Fedora 15 Release Notes Release Notes for Fedora 15 Edited by The Fedora Docs Team Copyright © 2011 Red Hat, Inc. and others. The text of and illustrations in this document are licensed by Red Hat under a Creative Commons Attribution–Share Alike 3.0 Unported license ("CC-BY-SA"). An explanation of CC-BY-SA is available at http://creativecommons.org/licenses/by-sa/3.0/. The original authors of this document, and Red Hat, designate the Fedora Project as the "Attribution Party" for purposes of CC-BY-SA. In accordance with CC-BY-SA, if you distribute this document or an adaptation of it, you must provide the URL for the original version. Red Hat, as the licensor of this document, waives the right to enforce, and agrees not to assert, Section 4d of CC-BY-SA to the fullest extent permitted by applicable law. Red Hat, Red Hat Enterprise Linux, the Shadowman logo, JBoss, MetaMatrix, Fedora, the Infinity Logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries. For guidelines on the permitted uses of the Fedora trademarks, refer to https:// fedoraproject.org/wiki/Legal:Trademark_guidelines. Linux® is the registered trademark of Linus Torvalds in the United States and other countries. Java® is a registered trademark of Oracle and/or its affiliates. XFS® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries. MySQL® is a registered trademark of MySQL AB in the United States, the European Union and other countries. All other trademarks are the property of their respective owners. -

Maplogic Layout Manager User's Manual
MAPLOGIC CORPORATION GIS Software Solutions MapLogic Layout Manager User’s Manual MapLogic Layout Manager User’s Manual © 2009 MapLogic Corporation All Rights Reserved 330 West Canton Ave., Winter Park, Florida 32789 Phone (407) 657-1250 • Fax (407) 657-7008 MapLogic Layout Manager is a trademark of MapLogic Corporation. ArcGIS, ArcMap and ArcView are registered trademarks of ESRI. Table of Contents Introduction _____________________________________________________________________ 1 What Is MapLogic Layout Manager? ____________________________________________ 1 MapLogic Layout Manager User Interface ____________________________________________ 2 The Layouts Tab ____________________________________________________________ 2 The MapLogic Layout Manager Toolbar _________________________________________ 3 Element Properties __________________________________________________________ 4 Before You Get Started ____________________________________________________________ 6 How The MapLogic Layout Manager Changes The ArcMap Document_________________ 6 Different Licenses For The MapLogic Layout Manager _____________________________ 6 Basic Concepts ___________________________________________________________________ 8 Multiple Layouts Within The ArcMap Document __________________________________ 8 The Map Series Layout _______________________________________________________ 8 The Map Book Layout _______________________________________________________ 9 New Elements You Can Add To Map Series And Book Layouts _____________________ 10 Two-Sided Map -
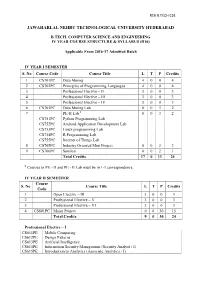
R16 B.TECH CSE IV Year Syllabus
R16 B.TECH CSE. JAWAHARLAL NEHRU TECHNOLOGICAL UNIVERSITY HYDERABAD B.TECH. COMPUTER SCIENCE AND ENGINEERING IV YEAR COURSE STRUCTURE & SYLLABUS (R16) Applicable From 2016-17 Admitted Batch IV YEAR I SEMESTER S. No Course Code Course Title L T P Credits 1 CS701PC Data Mining 4 0 0 4 2 CS702PC Principles of Programming Languages 4 0 0 4 3 Professional Elective – II 3 0 0 3 4 Professional Elective – III 3 0 0 3 5 Professional Elective – IV 3 0 0 3 6 CS703PC Data Mining Lab 0 0 3 2 7 PE-II Lab # 0 0 3 2 CS751PC Python Programming Lab CS752PC Android Application Development Lab CS753PC Linux programming Lab CS754PC R Programming Lab CS755PC Internet of Things Lab 8 CS705PC Industry Oriented Mini Project 0 0 3 2 9 CS706PC Seminar 0 0 2 1 Total Credits 17 0 11 24 # Courses in PE - II and PE - II Lab must be in 1-1 correspondence. IV YEAR II SEMESTER Course S. No Course Title L T P Credits Code 1 Open Elective – III 3 0 0 3 2 Professional Elective – V 3 0 0 3 3 Professional Elective – VI 3 0 0 3 4 CS801PC Major Project 0 0 30 15 Total Credits 9 0 30 24 Professional Elective – I CS611PE Mobile Computing CS612PE Design Patterns CS613PE Artificial Intelligence CS614PE Information Security Management (Security Analyst - I) CS615PE Introduction to Analytics (Associate Analytics - I) R16 B.TECH CSE. Professional Elective – II CS721PE Python Programming CS722PE Android Application Development CS723PE Linux Programming CS724PE R Programming CS725PE Internet of Things Professional Elective - III CS731PE Distributed Systems CS732PE Machine Learning CS733PE -

AGL HMI Framework Architecture Document
AGL HMI Framework Architecture Document Version Date 0.9 2019/x/x AGL HMI Framework Architecture Document 1. HMI Framework overview ........................................................................................ 4 1.1. Oerview .............................................................................................................. 4 1.1.1. HMI-FW Components ................................................................................. 5 1.1.2. Related components ..................................................................................... 6 2. GUI-library ................................................................................................................ 7 2.1. Overview ............................................................................................................ 7 2.1.1. Related external components ....................................................................... 7 2.1.2. Internal Components ................................................................................... 8 2.2. Graphics functions .............................................................................................. 9 2.2.1. Procedure necessary for HMI-Apps ............................................................ 9 2.2.2. Software configuration of GUI-lib ............................................................ 10 2.3. Sound functions ................................................................................................ 12 2.4. Input functions ................................................................................................. -

Java Lecture 5 AWT
Java Lecture 5 AWT Abstract Windows Toolkit: A Java window is a set of nested components, starting from the outermost window down to the smallest user interface (UI) component. Peers: Peers are native GUI components (native to the platform). When a Java program creates and displays a Java AWT component, that component actually creates and displays a native component (called a peer). Thus, under Windows 95, a windows 95 button, or dialog, etc. is generated. Under Solaris a Motif peer and under Macintosh, a Macintosh peer. Components include seeable things such as: windows menu bars buttons text fields and non-seeable things like containers which can include other components. Containers have layout managers that deal with positioning and shaping of components. The nesting of components within containers within other components creates a hierarchy for painting and event passing. Major components: Containers: Containers are generic AWT components that can contain other components, including other containers. The most common form of container is the panel, which represents a container that can be displayed on screen. Applets are a form of panel (in fact, the "Applet" class is a subclass of the "Panel" class). Canvases: A canvas is a simple drawing surface. Although you can draw on panels, (as you've been doing all along), canvases are good for painting images or other graphics operations. UI components: These can include buttons, lists, simple popup menus, checkboxes test fields, and other typical elements of a user interface. Window construction components: These include windows, frames, menu bars, and dialogs. These are listed separately from the other UI components because you'll use these less often--particularly in applets. -

Manual – Remote Control Page 2 of 111 7.2 Authenticating on the Remote Computer Using a Windows User Account 28
TeamViewer 10 Manual Remote Control Rev 10.3-201506 TeamViewer GmbH • Jahnstraße 30 D-73037 Göppingen www.teamviewer.com Table of contents 1 About TeamViewer 5 1.1 About the software 5 1.2 About the manual 5 2 Basics 7 2.1 How TeamViewer works 7 2.2 Description of the main TeamViewer window 7 3 Establishing a connection with TeamViewer 10 4 The Remote Control connection mode 11 4.1 Remote Control window options 11 4.2 Remote computer options in the TeamViewer Panel 18 5 The File Transfer connection mode 21 5.1 Options in File Transfer connection mode 21 5.2 Transferring files using drag and drop 23 5.3 File transfer via the Windows context menu 24 6 The VPN connection mode 25 6.1 Sample uses of TeamViewer VPN 25 6.2 Requirements for using TeamViewer VPN 25 6.3 VPN dialog box options 26 7 Other connection options 27 7.1 Establishing a LAN connection using the IP address 27 TeamViewer 10 Manual – Remote Control www.teamviewer.com Page 2 of 111 7.2 Authenticating on the Remote Computer using a Windows user account 28 7.3 Establish a connection via a Windows shortcut 29 7.4 Connections to your own computers without a password. 30 8 Computers & Contacts – Managing Contacts 32 8.1 The TeamViewer account 33 8.2 Computers & Contacts options 37 8.3 Service cases 53 8.4 Integrated system health checks 56 9 Multimedia functions 58 9.1 Options within the Session list 58 9.2 Transmitting webcam video to your partner 58 9.3 Talk to your partner via Voice over IP or conference call 59 9.4 Chatting with your partner during a TeamViewer session 61 9.5