TUTORIAL in BIOSTATISTICS: the Self-Controlled Case Series Method
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

BIOGRAPHICAL SKETCH Garrett M. Fitzmaurice Associate Professor Of
Principal Investigator/Program Director (Last, First, Middle): BIOGRAPHICAL SKETCH Provide the following information for the key personnel and other significant contributors in the order listed on Form Page 2. Follow this format for each person. DO NOT EXCEED FOUR PAGES. NAME POSITION TITLE Garrett M. Fitzmaurice Associate Professor of Biostatistics eRA COMMONS USER NAME EDUCATION/TRAINING (Begin with baccalaureate or other initial professional education, such as nursing, and include postdoctoral training.) DEGREE INSTITUTION AND LOCATION YEAR(s) FIELD OF STUDY (if applicable) National University of Ireland BA, MA 1983, 1987 Psychology University of London MSc 1986 Quantitative Methods Harvard University ScD 1993 Biostatistics Professional Experience: 1986-1989 Statistician, Department of Psychology, New York University 1989-1990 Teaching Assistant, Department of Biostatistics, Harvard School of Public Health 1990-1993 Teaching Fellow in Biostatistics, Department of Biostatistics, Harvard SPH 1993-1994 Post-doctoral Research Fellow, Department of Biostatistics, Harvard SPH 1994-1997 Research Fellow, Nuffield College, Oxford University, United Kingdom 1997-1999 Assistant Professor of Biostatistics, Harvard School of Public Health 1999-present Associate Professor of Biostatistics, Harvard School of Public Health 2004-present Associate Professor of Medicine (Biostatistics), Harvard Medical School 2004-present Biostatistician, Division of General Medicine, Brigham and Women’s Hospital, Boston 2006-present Foreign Adjunct Professor of Biostatistics, -

Global SDG Baseline for WASH in Health Care Facilities Practical Steps to Achieve Universal WASH in Health Care Facilities
Global SDG baseline for WASH in health care facilities Practical steps to achieve universal WASH in health care facilities Questions and Answers What is meant by WASH in health care facilities? The term “WASH in health care facilities” refers to the provision of water, sanitation, health care waste, hygiene and environmental cleaning infrastructure and services across all parts of a facility. “Health care facilities” encompass all formally-recognized facilities that provide health care, including primary (health posts and clinics), secondary, and tertiary (district or national hospitals), public and private (including faith-run), and temporary structures designed for emergency contexts (e.g., cholera treatment centers). They may be located in urban or rural areas. Why is WASH in health care facilities so important? WASH services are fundamental to providing quality care. Without such services, health goals, especially those for reducing maternal and neonatal mortality, reducing the spread of antimicrobial resistance and preventing and containing disease outbreaks will be not met. WASH is also critical to the experience of care. Services such as functional and accessible toilets with menstrual hygiene facilities and safe drinking-water support patient and staff dignity and fulfill basic human rights. With a renewed focus on primary health care services through the Astana Declaration and a renewed focus on preventing early childhood deaths through the Every Child Alive Campaign the opportunity to address WASH in health systems strengthening has never been greater. What are the current global estimates for WASH in health care facilities? The WHO and UNICEF Joint Monitoring Programme (JMP) 2019 SDG baseline report establishes national, regional and global baseline estimates that contribute towards global monitoring of SDG 6, universal access to WASH. -

Menstrual Hygiene Management TOOLKIT
Menstrual Hygiene Management TOOLKIT May 2015 About SPLASH: SPLASH (Schools Promoting Learning Achievement through Sanitation and Hygiene) is a comprehensive school-based water supply, sanitation, and hygiene (WASH) project funded by USAID/Zambia through field support. SPLASH is implemented through the WASHplus project, which supports healthy households and communities by creating and delivering interventions that lead to improvements in WASH and household air pollution (HAP). This five-year project (2010-2015), funded through USAID’s Bureau for Global Health (AID-OAA-A-10-00040) and led by FHI 360 in partnership with CARE and Winrock International, uses at-scale programming approaches to reduce diarrheal diseases and acute respiratory infections, the two top killers of children under age 5 globally. Recommended Citation: SPLASH, 2015. Menstrual Hygiene Management Toolkit. Washington D.C., USA. USAID/WASHplus Project. Contact Information: Justin Lupele Sandra Callier SPLASH Chief of Party WASHplus Project Director Plot 2473 Farmers’ Village, ZNFU Complex 1825 Connecticut Avenue, NW Tiyende Pamodzi Rd, Off Nangwenya Rd Washington, DC 20009-5721 Showgrounds Areas Office tel.: 202-884-8960 P.O. Box 51439 Ridgeway [email protected] Lusaka, Zambia Cell: 0971252490 [email protected] This toolkit is made possible by the generous support of the American people through the United States Agency for International Development (USAID) Bureau for Global Health under terms of Cooperative Agreement No. AID-OAA-A-10-00040. The contents are the responsibility of FHI 360, and do not necessarily reflect the views of USAID or the United States Government. May 2015 ACKNOWLEDGMENT WASHplus/SPLASH is indebted to USAID/Zambia for its financial and technical support to the SPLASH project and the Ministry of Education Science, Vocational Training and Early Education (MESVTEE), Eastern Province for supporting the development of this publication. -

Supplementary File
Supplementary file Table S1. Characteristics of studies included in the systematic review. Authors, reference Type of article Number of patients Type of stroke Valderrama [1] case report 1 AIS Oxley [2] case series 5 AIS Morassi [3] case series 6 AIS (n = 4), HS (n = 2) Tunc [4] case series 4 AIS Avula [5] case series 4 AIS (n = 3), TIA (n = 1) Oliver [6] case report 1 AIS Beyrouti [7] case series 6 AIS Al Saiegh [8] case series 2 AIS (n = 1), SAH (n = 1) Gunasekaran [9] case report 1 AIS Goldberg [10] case report 1 AIS Viguier [11] case report 1 AIS Escalard [12] case series/ case control 10 AIS Wang [13] case series 5 AIS Fara [14] case series 3 AIS Moshayedi [15] case report 1 AIS Deliwala [16] case report 1 AIS Sharafi-Razavi [17] case report 1 HS retrospective cohort study (case Jain [18] 35 AIS (n = 26) HS (n = 9) control) retrospective cohort study (case Yaghi [19] 32 AIS control) AIS (n = 35), TIA (n = 5), HS Benussi [20] retrospective cohort study 43 (n = 3) Rudilosso [21] case report 1 AIS Lodigiani [22] retrospective cohort study 9 AIS Malentacchi [23] case report 1 AIS J. Clin. Med. 2020, 9, x; doi: FOR PEER REVIEW www.mdpi.com/journal/jcm J. Clin. Med. 2020, 9, x FOR PEER REVIEW 2 of 8 retrospective cohort study/case Scullen [24] 2 HS + AIS (n = 1), AIS (n = 1) series retrospective cohort study/ case AIS (n = 17), ST (n = 2), HS Sweid [25] 22 series (n = 3) AIS – acute ischemic stroke; HS – haemorrhagic stroke; SAH – subarachnoid haemorrhage; ST – sinus thrombosis; TIA-transient ischemic attack. -

Car Washing Poster
WHEN YOU’RE WASHING YOUR CAR IN THE DRIVEWAY, YOU’RE NOT JUST WASHING YOUR CAR IN THE DRIVEWAY. Storm drains run directly into lakes, rivers or marine waters. When you wash your car in your drive way, the soap can go down the storm drain and pollute our waters. Don’t feed soap to the storm drain. Wash your car right. Keep your waters clean. A message from the Washington Departments of Ecology, Health, Washington Parks & Recreation Commission, Washington Conservation Commission, Puget Sound Partnership, WSU Extension Service, U.S. Environmental Protection Agency and Thurston County Stream Team. When you’re washing We all need clean water. your car in the We drink it, fish in it, play in it. We enjoy all it adds to our lives. In fact, we need it to driveway, you’re not survive. Fish and wildlife do, too. More than 60 percent of water pollution just washing your car comes from things like cars leaking oil, fer- tilizers and pesticides from farms and gar- in the driveway. dens, failing septic tanks, pet waste, and fuel spills from recreational boaters. Clean water is important to all of us. It's up to all of us to make it hap- All these small, dispersed sources add up pen. In recent years sources of water pollution like industrial wastes to a big pollution problem. But each of us from factories have been greatly reduced. Now, most water pollution can do small things to help clean up our comes from things like cars leaking oil, fertilizers from farms and gar- waters too—and that adds up to a pollution dens, and failing septic tanks. -

Biometrics & Biostatistics
Hanley and Moodie, J Biomet Biostat 2011, 2:5 Biometrics & Biostatistics http://dx.doi.org/10.4172/2155-6180.1000124 Research Article Article OpenOpen Access Access Sample Size, Precision and Power Calculations: A Unified Approach James A Hanley* and Erica EM Moodie Department of Epidemiology, Biostatistics, and Occupational Health, McGill University, Canada Abstract The sample size formulae given in elementary biostatistics textbooks deal only with simple situations: estimation of one, or a comparison of at most two, mean(s) or proportion(s). While many specialized textbooks give sample formulae/tables for analyses involving odds and rate ratios, few deal explicitly with statistical considera tions for slopes (regression coefficients), for analyses involving confounding variables or with the fact that most analyses rely on some type of generalized linear model. Thus, the investigator is typically forced to use “black-box” computer programs or tables, or to borrow from tables in the social sciences, where the emphasis is on cor- relation coefficients. The concern in the – usually very separate – modules or stand alone software programs is more with user friendly input and output. The emphasis on numerical exactness is particularly unfortunate, given the rough, prospective, and thus uncertain, nature of the exercise, and that different textbooks and software may give different sample sizes for the same design. In addition, some programs focus on required numbers per group, others on an overall number. We present users with a single universal (though sometimes approximate) formula that explicitly isolates the impacts of the various factors one from another, and gives some insight into the determinants for each factor. -

Water, Sanitation and Hygiene (WASH)
July 2018 About Water, Sanitation and UNICEF The United Nations Children’s Fund (UNICEF) Hygiene (WASH) works in more than 190 countries and territories to put children first. UNICEF WASH and Children has helped save more Globally, 2.3 billion people lack access to basic children’s lives than sanitation services and 844 million people lack any other humanitarian organization, by providing access to clean drinking water. The lack of health care and immuni these basic necessities isn’t just inconvenient zations, safe water and — it’s lethal. sanitation, nutrition, education, emergency relief Over 800 children die every day — about 1 and more. UNICEF USA supports UNICEF’s work every 2 minutes — from diarrhea due to unsafe through fundraising, drinking water, poor sanitation, or poor advocacy and education in hygiene. Suffering and death from diseases the United States. Together, like pneumonia, trachoma, scabies, skin we are working toward the and eye infections, cholera and dysentery day when no children die from preventable causes could be prevented by scaling up access and every child has a safe to adequate water supply and sanitation and healthy childhood. facilities and eliminating open defecation. For more information, visit unicefusa.org. Ensuring access to water and sanitation in UNICEF has helped schools can also help reduce the number of increase school children who miss out on their education — enrollment in Malawi through the provision especially girls. Scaling up access to WASH of safe drinking water. also supports efforts to protect vulnerable © UNICEF/UN040976/RICH children from violence, exploitation and abuse, since women and girls bear the heaviest Today, UNICEF has WASH programs in 113 burden in water collection, often undertaking countries to promote the survival, protection long, unsafe journeys to collect water. -

The American Statistician
This article was downloaded by: [T&F Internal Users], [Rob Calver] On: 01 September 2015, At: 02:24 Publisher: Taylor & Francis Informa Ltd Registered in England and Wales Registered Number: 1072954 Registered office: 5 Howick Place, London, SW1P 1WG The American Statistician Publication details, including instructions for authors and subscription information: http://www.tandfonline.com/loi/utas20 Reviews of Books and Teaching Materials Published online: 27 Aug 2015. Click for updates To cite this article: (2015) Reviews of Books and Teaching Materials, The American Statistician, 69:3, 244-252, DOI: 10.1080/00031305.2015.1068616 To link to this article: http://dx.doi.org/10.1080/00031305.2015.1068616 PLEASE SCROLL DOWN FOR ARTICLE Taylor & Francis makes every effort to ensure the accuracy of all the information (the “Content”) contained in the publications on our platform. However, Taylor & Francis, our agents, and our licensors make no representations or warranties whatsoever as to the accuracy, completeness, or suitability for any purpose of the Content. Any opinions and views expressed in this publication are the opinions and views of the authors, and are not the views of or endorsed by Taylor & Francis. The accuracy of the Content should not be relied upon and should be independently verified with primary sources of information. Taylor and Francis shall not be liable for any losses, actions, claims, proceedings, demands, costs, expenses, damages, and other liabilities whatsoever or howsoever caused arising directly or indirectly in connection with, in relation to or arising out of the use of the Content. This article may be used for research, teaching, and private study purposes. -

Case Series: COVID-19 Infection Causing New-Onset Diabetes Mellitus?
Endocrinology & Metabolism International Journal Case Series Open Access Case series: COVID-19 infection causing new-onset diabetes mellitus? Abstract Volume 9 Issue 1 - 2021 Objectives: This paper seeks to explore the hypothesis of the potential diabetogenic effect 1 2 of SARS-COV-2 (Severe Acute respiratory syndrome coronavirus). Rujuta Katkar, Narasa Raju Madam 1Consultant Endocrinologist at Yuma Regional Medical Center, Case series presentation: We present a case series of observation among 8 patients of age USA 2 group ranging from 34 to 74 years with a BMI range of 26.61 to 53.21 Kilogram/square Hospitalist at Yuma Regional Medical Center, USA meters that developed new-onset diabetes after COVID-19 infection. Correspondence: Rujuta Katkar, MD, Consultant Severe Acute Respiratory Syndrome Coronavirus (SARS-COV-2), commonly known as Endocrinologist at Yuma Regional Medical Center, 2851 S Coronavirus or COVID-19(Coronavirus infectious disease), gains entry into the cells by Avenue B, Bldg.20, Yuma, AZ-85364, USA, Tel 2034359976, binding to the Angiotensin-converting enzyme-2(ACE-2) receptors located in essential Email metabolic tissues including the pancreas, adipose tissue, small intestine, and kidneys. Received: March 25, 2021 | Published: April 02, 2021 The evidence reviewed from the scientific literature describes how ACE 2 receptors play a role in the pathogenesis of diabetes and the plausible interaction of SARS-COV-2 with ACE 2 receptors in metabolic organs and tissues. Conclusion: The 8 patients without a past medical history of diabetes admitted with COVID-19 infection developed new-onset diabetes mellitus due to plausible interaction of SARS-COV-2 with ACE 2 receptors. -

Water, Sanitation and Hygiene in Health Care Facilities: Driving Transformational Change for Women and Girls Wateraid/ James Kiyimba Wateraid
Water, sanitation and hygiene in health care facilities: driving transformational change for women and girls WaterAid/ James Kiyimba WaterAid/ 1 Water, sanitation and hygiene in health care facilities: driving transformational change for women and girls Access to clean water, sanitation and hygiene (WASH) in healthcare facilities is a fundamental component of Universal Health Coverage (UHC) and underpins the delivery of safe, quality health services for all, especially women and girls. As the main users of health services and the primary caregivers for family members in many countries around the world, the burden of poor WASH in healthcare facilities falls disproportionately on women. Improving access to WASH in healthcare settings, designed with gender considerations, can contribute to sustainable improvements in the quality of healthcare services, supporting core aspects of UHC including equity and dignity, and ultimately, to positive health and empowerment outcomes for women and their families. Despite being a fundamental component of health systems, WASH services are too often neglected and under-prioritised by governments and development partners. In 2018, the United Nations Secretary General issued a Global Call to Action to elevate the importance of, and prioritize action on, WASH in healthcare facilities. This is in line with the SDGs WaterAid/ James Kiyimba WaterAid/ on health (SDG 3) and clean water and sanitation (SDG 6), and supports a long-term vision that all healthcare facilities provide quality care in a safe, clean environment -
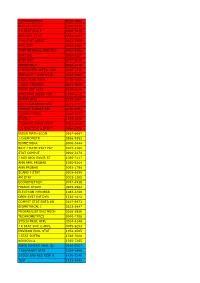
Econometrica 0012-9682 Biostatistics 1465-4644 J R
ECONOMETRICA 0012-9682 BIOSTATISTICS 1465-4644 J R STAT SOC B 1369-7412 ANN APPL STAT 1932-6157 J AM STAT ASSOC 0162-1459 ANN STAT 0090-5364 STAT METHODS MED RES 0962-2802 STAT SCI 0883-4237 STAT MED 0277-6715 BIOMETRICS 0006-341X CHEMOMETR INTELL LAB 0169-7439 IEEE ACM T COMPUT BI 1545-5963 J BUS ECON STAT 0735-0015 J QUAL TECHNOL 0022-4065 FUZZY SET SYST 0165-0114 STAT APPL GENET MOL 1544-6115 PHARM STAT 1539-1604 MULTIVAR BEHAV RES 0027-3171 PROBAB THEORY REL 0178-8051 J COMPUT BIOL 1066-5277 STATA J 1536-867X J COMPUT GRAPH STAT 1061-8600 J R STAT SOC A STAT 0964-1998 INSUR MATH ECON 0167-6687 J CHEMOMETR 0886-9383 BIOMETRIKA 0006-3444 BRIT J MATH STAT PSY 0007-1102 STAT COMPUT 0960-3174 J AGR BIOL ENVIR ST 1085-7117 ANN APPL PROBAB 1050-5164 ANN PROBAB 0091-1798 SCAND J STAT 0303-6898 AM STAT 0003-1305 ECONOMET REV 0747-4938 FINANC STOCH 0949-2984 ELECTRON J PROBAB 1083-6489 OPEN SYST INF DYN 1230-1612 COMPUT STAT DATA AN 0167-9473 BIOMETRICAL J 0323-3847 PROBABILIST ENG MECH 0266-8920 TECHNOMETRICS 0040-1706 STOCH PROC APPL 0304-4149 J R STAT SOC C-APPL 0035-9254 ENVIRON ECOL STAT 1352-8505 J STAT SOFTW 1548-7660 BERNOULLI 1350-7265 INFIN DIMENS ANAL QU 0219-0257 J BIOPHARM STAT 1054-3406 STOCH ENV RES RISK A 1436-3240 TEST 1133-0686 ASTIN BULL 0515-0361 ADV APPL PROBAB 0001-8678 J TIME SER ANAL 0143-9782 MATH POPUL STUD 0889-8480 COMB PROBAB COMPUT 0963-5483 LIFETIME DATA ANAL 1380-7870 METHODOL COMPUT APPL 1387-5841 ECONOMET J 1368-4221 STATISTICS 0233-1888 J APPL PROBAB 0021-9002 J MULTIVARIATE ANAL 0047-259X ENVIRONMETRICS 1180-4009 -

Curriculum Vitae Jianwen Cai
CURRICULUM VITAE JIANWEN CAI Business Address: Department of Biostatistics, CB # 7420 The University of North Carolina at Chapel Hill Chapel Hill, NC 27599-7420 TEL: (919) 966-7788 FAX: (919) 966-3804 Email: [email protected] Education: 1992 - Ph.D. (Biostatistics), University of Washington, Seattle, Washington. 1989 - M.S. (Biostatistics), University of Washington, Seattle, Washington. 1985 - B.S. (Mathematics), Shandong University, Jinan, P. R. China. Positions: Teaching Assistant: Department of Biostatistics, University of Washington, 1988 - 1990. Research Assistant: Cardiovascular Health Study, University of Washington, 1988 - 1990. Fred Hutchinson Cancer Research Center, 1990 - 1992. Research Associate: Fred Hutchinson Cancer Research Center, 1992 - 1992. Assistant Professor: Department of Biostatistics, University of North Carolina at Chapel Hill, 1992 - 1999. Associate Professor: Department of Biostatistics, University of North Carolina at Chapel Hill, 1999 - 2004. Professor: Department of Biostatistics, University of North Carolina at Chapel Hill, 2004 - present. Interim Chair: Department of Biostatistics, University of North Carolina at Chapel Hill, 2006. Associate Chair: Department of Biostatistics, University of North Carolina at Chapel Hill, 2006-present. Professional Societies: American Statistical Association (ASA) International Biometric Society (ENAR) Institute of Mathematical Statistics (IMS) International Chinese Statistical Association (ICSA) 1 Research Interests: Survival Analysis and Regression Models, Design and Analysis of Clinical Trials, Analysis of Correlated Responses, Cancer Biology, Cardiovascular Disease Research, Obesity Research, Epidemiological Models. Awards/Honors: UNC School of Public Health McGavran Award for Excellence in Teaching, 2004. American Statistical Association Fellow, 2005 Institute of Mathematical Statistics Fellow, 2009 Professional Service: Associate Editor: Biometrics: 2000-2010. Lifetime Data Analysis: 2002-. Statistics in Biosciences: 2009-. Board Member: ENAR Regional Advisory Board, 1996-1998.