110.108 Calculus I
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Circles Project
Circles Project C. Sormani, MTTI, Lehman College, CUNY MAT631, Fall 2009, Project X BACKGROUND: General Axioms, Half planes, Isosceles Triangles, Perpendicular Lines, Con- gruent Triangles, Parallel Postulate and Similar Triangles. DEFN: A circle of radius R about a point P in a plane is the collection of all points, X, in the plane such that the distance from X to P is R. That is, C(P; R) = fX : d(X; P ) = Rg: Note that a circle is a well defined notion in any metric space. We say P is the center and R is the radius. If d(P; Q) < R then we say Q is an interior point of the circle, and if d(P; Q) > R then Q is an exterior point of the circle. DEFN: The diameter of a circle C(P; R) is a line segment AB such that A; B 2 C(P; R) and the center P 2 AB. The length AB is also called the diameter. THEOREM: The diameter of a circle C(P; R) has length 2R. PROOF: Complete this proof using the definition of a line segment and the betweenness axioms. DEFN: If A; B 2 C(P; R) but P2 = AB then AB is called a chord. THEOREM: A chord of a circle C(P; R) has length < 2R unless it is the diameter. PROOF: Complete this proof using axioms and the above theorem. DEFN: A line L is said to be a tangent line to a circle, if L \ C(P; R) is a single point, Q. The point Q is called the point of contact and L is said to be tangent to the circle at Q. -

Continuous Functions, Smooth Functions and the Derivative C 2012 Yonatan Katznelson
ucsc supplementary notes ams/econ 11a Continuous Functions, Smooth Functions and the Derivative c 2012 Yonatan Katznelson 1. Continuous functions One of the things that economists like to do with mathematical models is to extrapolate the general behavior of an economic system, e.g., forecast future trends, from theoretical assumptions about the variables and functional relations involved. In other words, they would like to be able to tell what's going to happen next, based on what just happened; they would like to be able to make long term predictions; and they would like to be able to locate the extreme values of the functions they are studying, to name a few popular applications. Because of this, it is convenient to work with continuous functions. Definition 1. (i) The function y = f(x) is continuous at the point x0 if f(x0) is defined and (1.1) lim f(x) = f(x0): x!x0 (ii) The function f(x) is continuous in the interval (a; b) = fxja < x < bg, if f(x) is continuous at every point in that interval. Less formally, a function is continuous in the interval (a; b) if the graph of that function is a continuous (i.e., unbroken) line over that interval. Continuous functions are preferable to discontinuous functions for modeling economic behavior because continuous functions are more predictable. Imagine a function modeling the price of a stock over time. If that function were discontinuous at the point t0, then it would be impossible to use our knowledge of the function up to t0 to predict what will happen to the price of the stock after time t0. -

A Brief Summary of Math 125 the Derivative of a Function F Is Another
A Brief Summary of Math 125 The derivative of a function f is another function f 0 defined by f(v) − f(x) f(x + h) − f(x) f 0(x) = lim or (equivalently) f 0(x) = lim v!x v − x h!0 h for each value of x in the domain of f for which the limit exists. The number f 0(c) represents the slope of the graph y = f(x) at the point (c; f(c)). It also represents the rate of change of y with respect to x when x is near c. This interpretation of the derivative leads to applications that involve related rates, that is, related quantities that change with time. An equation for the tangent line to the curve y = f(x) when x = c is y − f(c) = f 0(c)(x − c). The normal line to the curve is the line that is perpendicular to the tangent line. Using the definition of the derivative, it is possible to establish the following derivative formulas. Other useful techniques involve implicit differentiation and logarithmic differentiation. d d d 1 xr = rxr−1; r 6= 0 sin x = cos x arcsin x = p dx dx dx 1 − x2 d 1 d d 1 ln jxj = cos x = − sin x arccos x = −p dx x dx dx 1 − x2 d d d 1 ex = ex tan x = sec2 x arctan x = dx dx dx 1 + x2 d 1 d d 1 log jxj = ; a > 0 cot x = − csc2 x arccot x = − dx a (ln a)x dx dx 1 + x2 d d d 1 ax = (ln a) ax; a > 0 sec x = sec x tan x arcsec x = p dx dx dx jxj x2 − 1 d d 1 csc x = − csc x cot x arccsc x = − p dx dx jxj x2 − 1 d product rule: F (x)G(x) = F (x)G0(x) + G(x)F 0(x) dx d F (x) G(x)F 0(x) − F (x)G0(x) d quotient rule: = chain rule: F G(x) = F 0G(x) G0(x) dx G(x) (G(x))2 dx Mean Value Theorem: If f is continuous on [a; b] and differentiable on (a; b), then there exists a number f(b) − f(a) c in (a; b) such that f 0(c) = . -

Secant Lines TEACHER NOTES
TEACHER NOTES Secant Lines About the Lesson In this activity, students will observe the slopes of the secant and tangent line as a point on the function approaches the point of tangency. As a result, students will: • Determine the average rate of change for an interval. • Determine the average rate of change on a closed interval. • Approximate the instantaneous rate of change using the slope of the secant line. Tech Tips: Vocabulary • This activity includes screen • secant line captures taken from the TI-84 • tangent line Plus CE. It is also appropriate for use with the rest of the TI-84 Teacher Preparation and Notes Plus family. Slight variations to • Students are introduced to many initial calculus concepts in this these directions may be activity. Students develop the concept that the slope of the required if using other calculator tangent line representing the instantaneous rate of change of a models. function at a given value of x and that the instantaneous rate of • Watch for additional Tech Tips change of a function can be estimated by the slope of the secant throughout the activity for the line. This estimation gets better the closer point gets to point of specific technology you are tangency. using. (Note: This is only true if Y1(x) is differentiable at point P.) • Access free tutorials at http://education.ti.com/calculato Activity Materials rs/pd/US/Online- • Compatible TI Technologies: Learning/Tutorials • Any required calculator files can TI-84 Plus* be distributed to students via TI-84 Plus Silver Edition* handheld-to-handheld transfer. TI-84 Plus C Silver Edition TI-84 Plus CE Lesson Files: * with the latest operating system (2.55MP) featuring MathPrint TM functionality. -

Visual Differential Calculus
Proceedings of 2014 Zone 1 Conference of the American Society for Engineering Education (ASEE Zone 1) Visual Differential Calculus Andrew Grossfield, Ph.D., P.E., Life Member, ASEE, IEEE Abstract— This expository paper is intended to provide = (y2 – y1) / (x2 – x1) = = m = tan(α) Equation 1 engineering and technology students with a purely visual and intuitive approach to differential calculus. The plan is that where α is the angle of inclination of the line with the students who see intuitively the benefits of the strategies of horizontal. Since the direction of a straight line is constant at calculus will be encouraged to master the algebraic form changing techniques such as solving, factoring and completing every point, so too will be the angle of inclination, the slope, the square. Differential calculus will be treated as a continuation m, of the line and the difference quotient between any pair of of the study of branches11 of continuous and smooth curves points. In the case of a straight line vertical changes, Δy, are described by equations which was initiated in a pre-calculus or always the same multiple, m, of the corresponding horizontal advanced algebra course. Functions are defined as the single changes, Δx, whether or not the changes are small. valued expressions which describe the branches of the curves. However for curves which are not straight lines, the Derivatives are secondary functions derived from the just mentioned functions in order to obtain the slopes of the lines situation is not as simple. Select two pairs of points at random tangent to the curves. -

Calculus Terminology
AP Calculus BC Calculus Terminology Absolute Convergence Asymptote Continued Sum Absolute Maximum Average Rate of Change Continuous Function Absolute Minimum Average Value of a Function Continuously Differentiable Function Absolutely Convergent Axis of Rotation Converge Acceleration Boundary Value Problem Converge Absolutely Alternating Series Bounded Function Converge Conditionally Alternating Series Remainder Bounded Sequence Convergence Tests Alternating Series Test Bounds of Integration Convergent Sequence Analytic Methods Calculus Convergent Series Annulus Cartesian Form Critical Number Antiderivative of a Function Cavalieri’s Principle Critical Point Approximation by Differentials Center of Mass Formula Critical Value Arc Length of a Curve Centroid Curly d Area below a Curve Chain Rule Curve Area between Curves Comparison Test Curve Sketching Area of an Ellipse Concave Cusp Area of a Parabolic Segment Concave Down Cylindrical Shell Method Area under a Curve Concave Up Decreasing Function Area Using Parametric Equations Conditional Convergence Definite Integral Area Using Polar Coordinates Constant Term Definite Integral Rules Degenerate Divergent Series Function Operations Del Operator e Fundamental Theorem of Calculus Deleted Neighborhood Ellipsoid GLB Derivative End Behavior Global Maximum Derivative of a Power Series Essential Discontinuity Global Minimum Derivative Rules Explicit Differentiation Golden Spiral Difference Quotient Explicit Function Graphic Methods Differentiable Exponential Decay Greatest Lower Bound Differential -

CHAPTER 3: Derivatives
CHAPTER 3: Derivatives 3.1: Derivatives, Tangent Lines, and Rates of Change 3.2: Derivative Functions and Differentiability 3.3: Techniques of Differentiation 3.4: Derivatives of Trigonometric Functions 3.5: Differentials and Linearization of Functions 3.6: Chain Rule 3.7: Implicit Differentiation 3.8: Related Rates • Derivatives represent slopes of tangent lines and rates of change (such as velocity). • In this chapter, we will define derivatives and derivative functions using limits. • We will develop short cut techniques for finding derivatives. • Tangent lines correspond to local linear approximations of functions. • Implicit differentiation is a technique used in applied related rates problems. (Section 3.1: Derivatives, Tangent Lines, and Rates of Change) 3.1.1 SECTION 3.1: DERIVATIVES, TANGENT LINES, AND RATES OF CHANGE LEARNING OBJECTIVES • Relate difference quotients to slopes of secant lines and average rates of change. • Know, understand, and apply the Limit Definition of the Derivative at a Point. • Relate derivatives to slopes of tangent lines and instantaneous rates of change. • Relate opposite reciprocals of derivatives to slopes of normal lines. PART A: SECANT LINES • For now, assume that f is a polynomial function of x. (We will relax this assumption in Part B.) Assume that a is a constant. • Temporarily fix an arbitrary real value of x. (By “arbitrary,” we mean that any real value will do). Later, instead of thinking of x as a fixed (or single) value, we will think of it as a “moving” or “varying” variable that can take on different values. The secant line to the graph of f on the interval []a, x , where a < x , is the line that passes through the points a, fa and x, fx. -
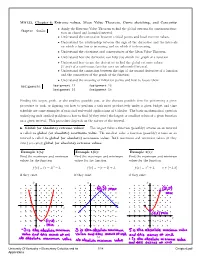
MA123, Chapter 6: Extreme Values, Mean Value
MA123, Chapter 6: Extreme values, Mean Value Theorem, Curve sketching, and Concavity • Apply the Extreme Value Theorem to find the global extrema for continuous func- Chapter Goals: tion on closed and bounded interval. • Understand the connection between critical points and localextremevalues. • Understand the relationship between the sign of the derivative and the intervals on which a function is increasing and on which it is decreasing. • Understand the statement and consequences of the Mean Value Theorem. • Understand how the derivative can help you sketch the graph ofafunction. • Understand how to use the derivative to find the global extremevalues (if any) of a continuous function over an unbounded interval. • Understand the connection between the sign of the second derivative of a function and the concavities of the graph of the function. • Understand the meaning of inflection points and how to locate them. Assignments: Assignment 12 Assignment 13 Assignment 14 Assignment 15 Finding the largest profit, or the smallest possible cost, or the shortest possible time for performing a given procedure or task, or figuring out how to perform a task most productively under a given budget and time schedule are some examples of practical real-world applications of Calculus. The basic mathematical question underlying such applied problems is how to find (if they exist)thelargestorsmallestvaluesofagivenfunction on a given interval. This procedure depends on the nature of the interval. ! Global (or absolute) extreme values: The largest value a function (possibly) attains on an interval is called its global (or absolute) maximum value.Thesmallestvalueafunction(possibly)attainsonan interval is called its global (or absolute) minimum value.Bothmaximumandminimumvalues(ifthey exist) are called global (or absolute) extreme values. -

Chapter 4 Differentiation in the Study of Calculus of Functions of One Variable, the Notions of Continuity, Differentiability and Integrability Play a Central Role
Chapter 4 Differentiation In the study of calculus of functions of one variable, the notions of continuity, differentiability and integrability play a central role. The previous chapter was devoted to continuity and its consequences and the next chapter will focus on integrability. In this chapter we will define the derivative of a function of one variable and discuss several important consequences of differentiability. For example, we will show that differentiability implies continuity. We will use the definition of derivative to derive a few differentiation formulas but we assume the formulas for differentiating the most common elementary functions are known from a previous course. Similarly, we assume that the rules for differentiating are already known although the chain rule and some of its corollaries are proved in the solved problems. We shall not emphasize the various geometrical and physical applications of the derivative but will concentrate instead on the mathematical aspects of differentiation. In particular, we present several forms of the mean value theorem for derivatives, including the Cauchy mean value theorem which leads to L’Hôpital’s rule. This latter result is useful in evaluating so called indeterminate limits of various kinds. Finally we will discuss the representation of a function by Taylor polynomials. The Derivative Let fx denote a real valued function with domain D containing an L ? neighborhood of a point x0 5 D; i.e. x0 is an interior point of D since there is an L ; 0 such that NLx0 D. Then for any h such that 0 9 |h| 9 L, we can define the difference quotient for f near x0, fx + h ? fx D fx : 0 0 4.1 h 0 h It is well known from elementary calculus (and easy to see from a sketch of the graph of f near x0 ) that Dhfx0 represents the slope of a secant line through the points x0,fx0 and x0 + h,fx0 + h. -

Chapter 2, Lecture 2: Convex Functions 1 Definition Of
Math 484: Nonlinear Programming1 Mikhail Lavrov Chapter 2, Lecture 2: Convex functions February 6, 2019 University of Illinois at Urbana-Champaign 1 Definition of convex functions n 00 Convex functions f : R ! R with Hf(x) 0 for all x, or functions f : R ! R with f (x) ≥ 0 for all x, are going to be our model of what we want convex functions to be. But we actually work with a slightly more general definition that doesn't require us to say anything about derivatives. n Let C ⊆ R be a convex set. A function f : C ! R is convex on C if, for all x; y 2 C, the inequality holds that f(tx + (1 − t)y) ≤ tf(x) + (1 − t)f(y): (We ask for C to be convex so that tx + (1 − t)y is guaranteed to stay in the domain of f.) This is easiest to visualize in one dimension: x1 x2 The point tx+(1−t)y is somewhere on the line segment [x; y]. The left-hand side of the definition, f(tx + (1 − t)y), is just the value of the function at that point: the green curve in the diagram. The right-hand side of the definition, tf(x) + (1 − t)f(y), is the dashed line segment: a straight line that meets f at x and y. So, geometrically, the definition says that secant lines of f always lie above the graph of f. Although the picture we drew is for a function R ! R, nothing different happens in higher dimen- sions, because only points on the line segment [x; y] (and f's values at those points) play a role in the inequality. -
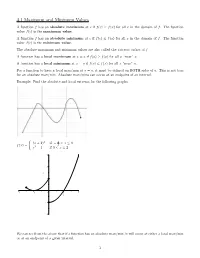
4.1 Maximum and Minimum Values a Function F Has an Absolute Maximum at C If F(C) ≥ F(X) for All X in the Domain of F
4.1 Maximum and Minimum Values A function f has an absolute maximum at c if f(c) ≥ f(x) for all x in the domain of f. The function value f(c) is the maximum value. A function f has an absolute minimum at c if f(c) ≤ f(x) for all x in the domain of f. The function value f(c) is the minimum value. The absolute maximum and minimum values are also called the extreme values of f. A function has a local maximum at x = a if f(a) ≥ f(x) for all x \near" a. A function has a local minimum at x = a if f(a) ≤ f(x) for all x \near" a. For a function to have a local max/min at x = a, it must be defined on BOTH sides of a. This is not true for an absolute max/min. Absolute max/mins can occur at an endpoint of an interval. Example: Find the absolute and local extrema for the following graphs. ( (x + 1)2 if − 3 < x ≤ 0 f(x) = 2 x2 − 1 if 0 < x ≤ 2 We can see from the above that if a function has an absolute max/min, it will occur at either a local max/min or at an endpoint of a given interval. 1 Very Important Fact: ALL local extrema of a function f will occur at values of x where the derivative is 0 or the derivative is undefined! The values of x in the domain of f for which f 0(x) = 0 or f 0(x) is undefined are called the critical numbers or critical values of f. -

First Semester Calculus Students' Concept Definitions and Concept Images of the Tangent Line and How These Relate to Students' Understandings of the Derivative
Graduate Theses, Dissertations, and Problem Reports 2016 First Semester Calculus Students' Concept Definitions and Concept Images of the Tangent Line and How These Relate to Students' Understandings of the Derivative Brittany Vincent Follow this and additional works at: https://researchrepository.wvu.edu/etd Recommended Citation Vincent, Brittany, "First Semester Calculus Students' Concept Definitions and Concept Images of the Tangent Line and How These Relate to Students' Understandings of the Derivative" (2016). Graduate Theses, Dissertations, and Problem Reports. 6876. https://researchrepository.wvu.edu/etd/6876 This Dissertation is protected by copyright and/or related rights. It has been brought to you by the The Research Repository @ WVU with permission from the rights-holder(s). You are free to use this Dissertation in any way that is permitted by the copyright and related rights legislation that applies to your use. For other uses you must obtain permission from the rights-holder(s) directly, unless additional rights are indicated by a Creative Commons license in the record and/ or on the work itself. This Dissertation has been accepted for inclusion in WVU Graduate Theses, Dissertations, and Problem Reports collection by an authorized administrator of The Research Repository @ WVU. For more information, please contact [email protected]. First Semester Calculus Students’ Concept Definitions and Concept Images of the Tangent Line and How These Relate to Students’ Understandings of the Derivative Brittany Vincent Dissertation submitted to the Eberly College of Arts and Sciences at West Virginia University in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Mathematics Vicki Sealey, Ph.D., Chair Nicole Engelke Infante, Ph.D.