Spreadsheet Program for EPA's Method 301: Field Validation of Pollutant Measurement Methods Form Various Waste Media the Calcul
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Datahand Personal User's Guide
DataHandâ Personal User's Guide Version 1.7.8 October 9, 2003 DataHand® Systems © Copyright 1997, DataHand® Systems, Inc. 3032 North 33rd Avenue Phoenix, AZ 85017 All rights are reserved. No part of this publication may be reproduced, stored in a retrieval system or transmitted in any form or by any means, mechanical, photocopying, recording or otherwise, without the prior written permission of DataHand® Systems, Inc. DataHand® Systems is a registered trademark of DataHand® Systems, Inc. Apple is a registered trademark of Apple Computer, Inc. IBM is a registered trademark of IBM Corporation. Microsoft and Windows are registered trademarks of Microsoft Corporation. Neither DataHand® Systems, Inc. nor its affiliates shall be liable to the purchaser of this product or third parties for damages, losses, costs or expenses incurred by purchaser or third parties as a result of: accident, misuse or abuse of this product or unauthorized modifications, repairs or alterations to this product. DataHand® Systems, Inc. and its affiliates shall not be liable for any damages or problems arising from the use of any options or any consumable products other than those designated as original DataHand® Systems, Inc. products or DataHand® Systems, Inc. approved products. ii User's Guide, Version 1.7.8, October 9, 2003 Congratulations! For choosing the world’s finest User-to-computer interface. You are now on the leading edge of interface technology. Your DataHand® System is a new and advantageous way to work with your computer. Learning to use the system requires commitment, patience and persistence, which will be well rewarded by increased comfort, reduced exposure to injury and long-term productivity increases. -

For the at Only-A Great New Keyboard
BIG GUNS "While the For the AT Only-A Great New Keyboard layout make: The AT's keyboard is an improved version of the PC's and defuses with the good points retained and the irritating ones of the tired c corrected. But it only works with the AT. complaints, upward and outward-comfortable to new locations on the new keyboard. One as most other keys on the keyboard). won't make much difference, but the At doesn'tfirst glanceseemthemuchPC AT'sdifferentkeyboardfrom the touch and a breeze to use. As does Each key has been moved inward: Num• perfect." other one will. The tilde (-) key has Lock is now over the 8 key and Scroll• the PC's. When you take a closer look, the new Enter key, the shift keys leave been moved to make way for the larger Lock over the 9 key. you'J] fmd most of the changes are sub• you plenty of room to hit your mark, a Enter key. It won't be missed by most IBM must have heard the complaints tle, but they are all important-and long change that will certainly cut down on from PC users about the PC's not-quite• overdue. errors. PC users in it. new position where the The AT's is still the same keyboard IBM has not labeled the Tab or Back• Esc key used to be. long-enough 6-foot cord, because the cord to the AT's keyboard is 10 feet with that now-familiar clicking sound space keys-they still only have arrows The shift of the Pipe symbol key (I and \) will be noticeable. -

Proper Keyboarding Technique and Procedures
KB1 Essential Standard Apply the touch method in operating the alpha keys. KB1 - 1.02 Execute the touch method in operating the alphabetic keys. Touch Method of Keyboarding Touch Typing Touch typing (also called touch type or touch method) Typing without using the sense of sight to find the keys. A touch typist learns the location of the keys on the keyboard through muscle memory. This method involves placing the eight fingers in a horizontal row along the middle of the keyboard (the home row) and having them reach for other keys. Touch Method Touch Method of Keyboarding Typing on a keyboard without looking at the keys. Learning to key by touch rather than using the hunt and peck method Hunt and Peck Hunt and Peck Method of Keyboarding Typing on a keyboard using only one or two fingers of each hand. Touch Typists Vs. Hunt and Peck Typists The average touch typist can type 50 to 60 words per minute without typos The two-finger typist using the "hunt and peck" method typically achieves only 20 to 30. Which type of typist do you want to be? Tips for Learning the Touch Method of Keyboarding Do not rush at the early stages of learning. Take your time and the speed will pick up as you progress. Establish and maintain a rhythm while typing so keystrokes are made at equal intervals. Strike keys with the correct fingers. Move your hands and fingers as little as possible. Tips for Learning the Touch Method of Keyboarding Don't hammer on the keys. -

Quickhelp Sorenson Ntouch VP2 Calling Features
QuickHelp Sorenson ntouch VP2 Calling Features Use the bookmarks in the left-hand column to jump to the QuickHelp answers to these questions: How do I use the Group Call feature? How do I set up Voice Carry Over (VCO) calling? How do I show the in-call audio level meter? How do I set how long the option bar is displayed in a call? How do I change my Self-View video settings during a call? How do turn the Do Not Disturb mode on and off? How do I use the Group Call feature? You can use the Group Call feature to have a conversation with up 4 other people at one time. A group call begins when you “join” two calls together into one call. You can then add up to 2 other calls (for a total of 4 calls) at once. You can use the ntouch VP2 Group Call feature with all Sorenson endpoints during a point-to-point call. The Group Call feature does not work with Sorenson Video Relay Service (SVRS) calls. The example images below show the Video Privacy mode enabled on all endpoints. This was done to make it easier to see how to use the feature. Step 1. When in an active call, press the OK key on the remote control to open the In-call options bar as shown below. In-call options bar Step 2. Move to the Call button as shown below. Call button Step 3. Select the Call button to open the Call menu as shown below. -

Orbic Wonder User Guide
User guide. Add a Wi-Fi Network ............................................................................................... 19 TABLE OF CONTENTS Forgetting a Wi-Fi network .......................................................................................20 GETTING STARTED Connecting to Bluetooth Devices ............................................................................20 Buttons and Ports .........................................................................................................6 Forgetting a Bluetooth Device ................................................................................. 21 Installing the SIM Card and micro SD Card .............................................................7 Connecting to a Computer ...................................................................................... 21 Charging the Battery ...................................................................................................7 Using micro SD Card for Storage ........................................................................... 21 Turning Your Phone On/Off .......................................................................................8 Sharing Your Phone’s Data Connection .................................................................23 Setting Up Your Phone Out of the Box ......................................................................8 MAKING PHONE CALLS Home Screen ...............................................................................................................9 Place -

Title Keyboard : All Special Keys : Enter, Del, Shift, Backspace ,Tab … Contributors Dhanya.P Std II Reviewers Submission Approval Date Date Ref No
Title Keyboard : All special keys : Enter, Del, Shift, Backspace ,Tab ¼ Contributors Dhanya.P Std II Reviewers Submission Approval Date Date Ref No: This topic describes the special keys on the keyboard of a computer Brief Description and their functionalities . Goal To familiarize the special keys on the keyboard of a computer. Pre-requisites Familiarity with computer. Learning Concepts that special keys on a keyboard has special functionalities. Outcome One Period Duration http://www.ckls.org/~crippel/computerlab/tutorials/keyboard/ References http://computer.howstuffworks.com/ Page Nos: 2,3,4,5,6 Detailed Description Page No: 7 Lesson Plan Page No: 7 Worksheet Page No: 8 Evaluation Page No: 8 Other Notes Detailed Description A computer keyboard is a peripheral , partially modeled after the typewriter keyboard. Keyboards are designed for the input of text and characters. Special Keys Function Keys Cursor Control Keys Esc Key Control Key Shift Key Enter Key Tab Key Insert Key Delete Key ScrollLock Key NumLock Key CapsLock Key Pasue/Break Key PrtScr Key Function Keys F1 through F12 are the function keys. They have special purposes. The following are mainly the purpose of the function keys. But it may vary according to the software currently running. # F1 - Help # F2 - Renames selected file # F3 - Opens the file search box # F4 - Opens the address bar in Windows Explorer # F5 - Refreshes the screen in Windows Explorer # F6 - Navigates between different sections of a Windows Explorer window # F8 - Opens the start-up menu when booting Windows # F11 - Opens full screen mode in Explorer Function Keys F1 through F12 are the function keys. -
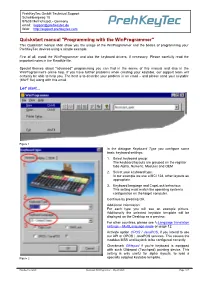
Quickstart Winprogrammer - May 20 2020 Page 1/27
PrehKeyTec GmbH Technical Support Scheinbergweg 10 97638 Mellrichstadt - Germany email: [email protected] Web: http://support.prehkeytec.com Quickstart manual "Programming with the WinProgrammer" This Quickstart manual shall show you the usage of the WinProgrammer and the basics of programming your PrehKeyTec devices using a simple example. First of all, install the WinProgrammer and also the keyboard drivers, if necessary. Please carefully read the important notes in the ReadMe file. Special themes about "advanced" programming you can find in the annex of this manual and also in the WinProgrammer's online help. If you have further problems when creating your keytable, our support team will certainly be able to help you. The best is to describe your problem in an email – and please send your keytable (MWF file) along with this email. Let' start... Figure 1 In the dialogue Keyboard Type you configure some basic keyboard settings: 1. Select keyboard group: The keyboard layouts are grouped on the register tabs Alpha, Numeric, Modules and OEM 2. Select your keyboard type: In our example we use a MCI 128, other layouts as appropriate. 3. Keyboard language and CapsLock behaviour: This setting must match the operating system's configuration on the target computer. Continue by pressing OK. Additional Information: For each type you will see an example picture. Additionally the selected keytable template will be displayed on the Desktop as a preview. For other countries, please see Language translation settings – MultiLanguage mode on page 12. Activate option OPOS / JavaPOS, if you intend to use our API or OPOS / JavaPOS services. This causes the modules MSR and keylock to be configured correctly. -

Engram: a Systematic Approach to Optimize Keyboard Layouts for Touch Typing, with Example for the English Language
Preprints (www.preprints.org) | NOT PEER-REVIEWED | Posted: 10 March 2021 doi:10.20944/preprints202103.0287.v1 Engram: a systematic approach to optimize keyboard layouts for touch typing, with example for the English language 1 Arno Klein , PhD 1 MATTER Lab, Child Mind Institute, New York, NY, United States Corresponding Author: Arno Klein, PhD MATTER Lab Child Mind Institute 101 E 56th St NY, NY 10022 United States Phone: 1-347-577-2091 Email: [email protected] ORCID ID: 0000-0002-0707-2889 Abstract Most computer keyboard layouts (mappings of characters to keys) do not reflect the ergonomics of the human hand, resulting in preventable repetitive strain injuries. We present a set of ergonomics principles relevant to touch typing, introduce a scoring model that encodes these principles, and outline a systematic approach for developing optimized keyboard layouts in any language based on this scoring model coupled with character-pair frequencies. We then create a keyboard layout optimized for touch typing in English by constraining key assignments to reduce lateral finger movements and enforce easy access to high-frequency letters and letter pairs, applying open source software to generate millions of layouts, and evaluating them based on Google’s N-gram data. We use two independent scoring methods to compare the resulting Engram layout against 10 other prominent keyboard layouts based on a variety of publicly available text sources. The Engram layout scores consistently higher than other keyboard layouts. Keywords keyboard layout, optimized keyboard layout, keyboard, touch typing, bigram frequencies Practitioner summary Most keyboard layouts (character mappings) have questionable ergonomics foundations, resulting in preventable repetitive strain injuries. -

Winbox P1 Instruction Manual
Winbox P1 Instruction manual table of Contents: First, PS4/Switch/X1 mouse operation Second, the factory default mouse and keyboard mapping Three or four sets of map save/switch Fourth, the mouse DPI sensitivity adjustment Five, H2 burst key to quickly adjust the burst frequency Sixth, physical shortcut button usage Seven, PS4/Switch/X1 third-party handle control Eight, doubles Nine, firmware upgrade Ten, replace the macro function XI. Handle vibration switch and force adjustment function Twelve, cool Wei button assistant instructions Take the button distribution of X1,PS4,Pro,joy-con handle an example: First、PS4/Switch/X1 Key, or mouse action 1:Insert the keyboard and mouse to Winbox P1 2:Connect Winbox P1with the given date line to PS4/Switch/X1 gaming consoles 3 : Press Enter Key of the keyboard or other key positions that map the home key to control the PS4/Switch/X1 game console with the keypad Important Notes: a、 Before connecting to Winbox P1, disconnect your own Bluetooth Controller (or use another PS4 accounts), such as PS4 "setting - peripheral device –Bluetooth - find the corresponding Controller to disconnect" .After connecting to Winbox P1, you need to press the Enter on keyboard or other keys that map the home key to use b、Before using the Switch, please set "Pro Controller Wired Communication" in the Switch system menu to ON. When connected enter the settings “System Settings-Controllers and Sensors-Disconnect Controllers” to disconnect the Controller's own Bluetooth connection. C、X1 host users must use the P1 to play the mouse and keyboard, the X1 original handle must be wired to P1 to guide. -

User Guide &OHMJTI
LG930 User Guide &OHMJTI -( 6TFS(VJEF This guide helps you get started using your phone. If you need more information, please visit www.lg.com t4PNFPGUIFDPOUFOUTPGUIJTNBOVBMNBZOPU BQQMZUPZPVSQIPOF5IJTEFQFOETPOZPVSQIPOFT TPGUXBSFBOEZPVSTFSWJDFQSPWJEFS t5IJTIBOETFUJTOPUSFDPNNFOEFEGPSUIFWJTVBMMZ JNQBJSFECFDBVTFPGJUTUPVDITDSFFOLFZCPBSE t$PQZSJHIUª-(&MFDUSPOJDT *OD"MMSJHIUT SFTFSWFE-(BOEUIF-(MPHPBSFSFHJTUFSFE USBEFNBSLTPG-((SPVQBOEJUTSFMBUFEFOUJUJFT"MM PUIFSUSBEFNBSLTBSFUIFQSPQFSUZPGUIFJSSFTQFDUJWF PXOFST t(PPHMF .BQT (NBJM :PV5VCF 5BML BOE"OESPJE.BSLFUBSFUSBEFNBSLTPG(PPHMF *OD Table of Contents For Your Safety ...............................5 Safety Guidelines ..........................11 Important Notice ...........................28 Google Account Set-up .................51 Your Phone................................... .34 Getting Started .............................36 Calls ..............................................53 54 54 54 Your Home screen ........................41 Contacts....................................... .55 55 55 Favorite 55 Messaging/Email ..........................56 56 57 44 44 45 46 Social Networking ........................60 Camera .........................................62 65 65 Video Camera ...............................66 Google Applications ......................76 66 76 67 76 67 76 67 77 68 77 77 68 78 78 Multimedia....................................69 Table of Contents Utilities..........................................83 84 85 86 The Web ........................................87 87 87 My CCI App........... -

User Guide Guía Del Usuario
MFL68604701 (1.1) Guía del Usuario User Guide User Guide User This booklet is made from 98% post-consumer recycled paper. This booklet is printed with soy ink. Printed in Mexico &RS\ULJKW/*(OHFWURQLFV,QF$OOULJKWVUHVHUYHG /*DQGWKH/*ORJRDUHUHJLVWHUHGWUDGHPDUNVRI/*&RUS $OORWKHUWUDGHPDUNVDUHWKHSURSHUW\RIWKHLUUHVSHFWLYH RZQHUV Important Customer Information 1 Before you begin Before reading this user guide and getting started, please review the separate Product Safety and Warranty Information guide for important product safety and warranty information about your device. 2 Table of Contents Important Customer Information...............................................1 Table of Contents .......................................................................2 The Basics ...................................................................................5 Phone Overview .................................................................................................... 5 Help ....................................................................................................................... 8 Setting Up Your Phone ........................................................................................8 Removing the Battery and SIM Card ................................................................10 Inserting and Removing a Memory Card ..........................................................12 Charging the Phone ............................................................................................13 Optimizing Battery Life ......................................................................................14 -

Basic Ipad Use
Basic iPad Use Your iPad: Taking a screen shot: Hold down the home key and then press and release the sleep/wake switch. The screen will white out for a moment and you have just taken a screen shot! The screen shot will appear in the Photos app. Hints: ● A quick double tap of the home button or a four finger swipe up will display open apps. If you then swipe right, you will see a shortcut to the volume and screen brightness. ● To minimize an app once it is open, touch the home button once or pinch with five fingers. ● To toggle between various open apps, tap the home button twice to view the open apps to select from. Alternatively, a four finger swipe to the right or left will take you to the other open apps as well. ● To help extend battery life, double tap the home button (or four finger swipe up) to see which apps are open and potentially draining your battery. Once displayed, simply tap and hold one of the apps until it jiggles. A minus sign will appear in the top left corner of the app. Tap the minus sign to close. 1 Settings: ● Tap your “Settings” icon on the home screen. This app opens the door to the settings of your iPad. Take a moment to explore the choices under “General”: Sounds, Locks, Restrictions Setting up a Wifi Connection: ● Tap your “Settings” icon on the home screen. ● On the left side, tap WiFi. (Make sure it is turned on) ● Choose a network. At CAIS, it will be CAIS-WiFi.