Olympiads in Informatics 7 M
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Regional Contest Cookbook
Regional Contest Cookbook About ACM ICPC Mission: ACM International Collegiate Programming Contest (ICPC) provides college students with opportunities to interact with students from other universities and to sharpen and demonstrate their problem-solving, programming, and teamwork skills. The contest provides a platform for ACM, industry, and academia to encourage and focus public attention on the next generation of computing professionals as they pursue excellence. About the Contest The ACM International Collegiate Programming Contest (ICPC) traces its roots to a competition held at Texas A&M in 1970 hosted by the Alpha Chapter of the UPE Computer Science Honor Society. The idea quickly gained popularity within the United States and Canada as an innovative initiative to challenge the top students in the emerging field of computer science. The contest evolved into a multi-tier competition with the first Finals held at the ACM Computer Science Conference in 1977. Operating under the auspices of ACM and headquartered at Baylor University since 1989, the contest has expanded into a global network of universities hosting regional competitions that advance teams to the ACM-ICPC World Finals. Since IBM became sponsor in 1997, the contest has increased by a factor of eight. Participation has grown to involve several tens of thousands of the finest students and faculty in computing disciplines at 1,821 universities from 83 countries on six continents. The contest fosters creativity, teamwork, and innovation in building new software programs, and enables students to test their ability to perform under pressure. Quite simply, it is the oldest, largest, and most prestigious programming contest in the world. -

Technology and Engineering International Journal of Recent
International Journal of Recent Technology and Engineering ISSN : 2277 - 3878 Website: www.ijrte.org Volume-9 Issue-2, JULY 2020 Published by: Blue Eyes Intelligence Engineering and Sciences Publication d E a n n g y i n g o e l e o r i n n h g c e T t n e c Ijrt e e E R X I N P n f L O I O t T R A o e I V N O l G N r IN n a a n r t i u o o n J a l www.ijrte.org Exploring Innovation Editor-In-Chief & CEO Dr. Shiv Kumar Ph.D. (CSE), M.Tech. (IT, Honors), B.Tech. (IT) Senior Member of IEEE, Member of the Elsevier Advisory Panel CEO, Blue Eyes Intelligence Engineering and Sciences Publication, Bhopal (MP), India Associate Editor-In-Chief Prof. Dr. Takialddin Al Smadi PhD. (ECE) M.Sc. (ECE), B.Sc (EME), Member of the Elsevier Professor, Department of Communication and Electronics, Jerash Universtiy, Jerash, Jordan. Dr. Vo Quang Minh PhD. (Agronomy), MSc. (Agronomy), BSc. (Agronomy) Senior Lecturer and Head, Department of Land Resources, College of Environment and Natural Resources (CENRes), Can Tho City, Vietnam. Dr. Stamatis Papadakis PhD. (Philosophy), M.Sc. (Preschool Education), BSc. (Informatics) Member of IEEE, ACM, Elsevier, Springer, PubMed Lecturer, Department of Preschool Education, University of Crete, Greece Dr. Ali OTHMAN Al Janaby Ph.D. (LTE), MSc. (ECE), BSc (EE) Lecturer, Department of Communications Engineering, College of Electronics Engineering University of Ninevah, Iraq. Dr. Hakimjon Zaynidinov PhD. -

Art of Programming Contests
ART OF PROGRAMMING CONTEST C Programming Tutorials | Data Structures | Algorithms Compiled by Ahmed Shamsul Arefin Graduate Student, Institute of Information and Comunicaion Technology Bangladesh University of Engineering and Technology (BUET) BSc. in Computer Science and Engineering, CUET Reviewed By Steven Halim School of Computing, National University of Singapore Singapore. Dr. M. Lutfar Rahman Professor, Departent of Computer Science and Engineering University of Dhaka. Foreworded By Professor Miguel A. Revilla ACM-ICPC International Steering Committee Member and Problem Archivist University of Valladolid, Spain. http://acmicpc-live-archive.uva.es http://online-judge.uva.es Gyankosh Prokashoni, Bangladesh ISBN 984-32-3382-4 DEDICATED TO Shahriar Manzoor Judge ACM/ICPC World Finals 2003-2006 (Whose mails, posts and problems are invaluable to all programmers) And My loving parents and colleagues ACKNOWLEDGEMENTS I would like to thank following people for supporting me and helping me for the significant improvement of my humble works. Infact, this list is still incomplete. Professor Miguel A. Revilla University of Valladolid, Spain. Dr. M Kaykobad North South University, Bangladesh Dr. M. Zafar Iqbal Shahjalal University of Science and Technology, Bangladesh Dr. M. Lutfar Rahman University of Dhaka, Bangladesh Dr. Abu Taher Daffodil International University Howard Cheng University of Lethbridge, Canada Steven Halim National University of Singapore, Singapore Shahriar Manzoor South East University, Bangladesh Carlos Marcelino Casas Cuadrado -

ACM-ICPC Contents Table of Contents
ACM-ICPC Contents Table of Contents Welcome to Stockholm 3 Greetings 4-12 2009 Awards 13-16 World Finals Activities 17 Excursions 18 Venues 19 City Hall Walking around Stockholm 20 Stockholm Hotels 21 Schedule of Events 22-25 About the World Finals 26 Team Participation Since 1989 27 Contest History Past Winners 28 Policies and Procedures 29-31 World Finals Rules for 2009 32-34 ICPC World Finals Team Roster 35-41 World Finals Staff and Volunteers 42-47 Host University KTH CSC 48 1 Welcome to Stockholm Welcome to Stockholm Beauty on water, are words often said about Stock- holm. From the first day we started to plan for the 2009 World Finals we said “we want to show our beautiful city, we want the whole city to be our venue”. This is why you will live in the city center, right next to the water, you will walk around the city, along the water, you will travel to many places in the city, maybe even on water, and you will drink the clean water from the lake that cuts through the city, surrounding its islands, as it meets the Baltic Sea. When you wake up on Wednesday you will have been able to see Stockholm from many points of view. You will have experienced not only the water, but also the beautiful KTH Campus and maybe got a little of the Nobel spirit. All of us from the KTH organizing team deeply hope you will wake up on Wednesday and think “these days in Stockholm I will never forget”. -

Download ACM ICPC World Finals 2014 Brochure
Contents 7 WELCOME! 19 CONTEST About the Contest ________________________________20 Contest Growth __________________________________ 22 Past Winners ___________________________________ 23 The World of ICPC _______________________________24 World Finals Rules ________________________________ 26 Organizers _____________________________________ 30 33 HOST Ural Federal University ____________________________34 UrFU Institute of Mathematics and Computer Science ______ 36 39 JUDGES TEAMS 45 Africa and Middle East ____________________________46 South Pacific ___________________________________46 Asia __________________________________________47 Europe ________________________________________ 50 Latin America ___________________________________ 53 North America __________________________________ 55 AWARDS 59 About the ICPC Awards ____________________________60 Mark Measures Award ____________________________ 61 UPE Abacus Award _______________________________ 62 UPE Distinguished International Service Award ___________ 63 Joseph S. DeBlasi Award ___________________________64 ICPC Outstanding International Service Award ___________65 Coach Awards ___________________________________66 71 LOCATION Venues ________________________________________ 72 Transport & Communication ________________________ 73 Hotels _________________________________________ 74 eBurg at a Glance ________________________________76 ICPC Zone Landmarks _____________________________78 81 VOLUNTEERS ICPC Staff ______________________________________82 Regional Contest Directors -

ICPC FACT SHEET – 9 May 2017 the 41St Annual World Finals of The
ICPC FACT SHEET – 9 May 2017 The 41st Annual World Finals of the ACM International Collegiate Programming Contest (ICPC) Sponsored by IBM Hosted by Excellence in Computer Programming in Rapid City, South Dakota, USA, 20-25 May 2017 About the Contest – acmicpc.org, also icpc.baylor.edu The ACM International Collegiate Programming Contest (ICPC) is the premiere global programming competition conducted by and for the world’s universities. The competition operates under the auspices of ACM, is sponsored by IBM, and is headquartered at Baylor University. For nearly four decades, the ICPC has grown to be a game-changing global competitive educational program that has raised aspirations and performance of generations of the world’s problem solvers in the computing sciences and engineering. Teams of three students represent their universities in multiple levels of regional competition. Volunteer coaches prepare their teams with intense training and instruction in algorithms, programming, and teamwork strategy. Several ICPC universities and ICPC volunteers provide online judging systems to all free of charge. Top teams from regional competition advance to the final round. This year’s regional competitions will advance 133 teams to the World Championship round - the 2017 ACM-ICPC World Finals sponsored by IBM and hosted by Excellence in Computer Programming – which will be conducted on 24 May, 2017 in Rapid City, South Dakota, USA. The ICPC traces its roots to a competition held at Texas A&M in 1970 hosted by the Alpha Chapter of the UPE Computer Science Honor Society. The idea quickly gained popularity within the United States and Canada as an innovative initiative to raise the aspirations, performance, and opportunity of the top students in the emerging field of computer science. -
2013Brochure.Pdf
Welcome to the 2013 ACM ICPC World Finals sponsored by IBM hosted by ITMO 4 5 Contents Honorary Patronage .......................... 8 Honorary Committee ......................... 9 Welcome to Saint Petersburg .......... 20 University ITMO ............................... 26 About the Contest ........................... 38 World Finals Rules ........................... 46 World Finals Judges ........................ 52 Team Roster .................................... 58 Awards ............................................ 70 Schedule ......................................... 78 ICPC 2013 Venues .......................... 82 ICPC Volunteers ............................ 100 Special Thanks .............................. 109 7 2013 ACM ICPC World Finals Honorary Patronage Dmitry Medvedev Prime Minister of Russia Dear guests, I am glad to meet you in Saint Petersburg. I am really pleased that the World Finals is taking place in this city. You have chosen the occupation that provides you with unique opportunities not only for self-realiza- tion, but also for the development of entire humanity. Advancing to such a prestigious contest as the World Finals is already a great achievement. I’m sure that serious preparations, profound knowledge and creative approach to solving the most complex prob- lems will help you achieve great results, justify your mentors’ expectations and show that it is you who are the best programmers of the world. I wish all the teams good luck in the upcom- ing competition and vivid impressions of staying in the Northern capital to our foreign guests. Dmitry Medvedev Prime Minister of Russian Federation 8 2013 ACM ICPC World Finals Honorary Committee Georgy Poltavchenko Governor of Saint Petersburg Dmitry Livanov Minister of Education and Science Nikolai Nikiforov Minister of Telecom and Mass Media Vladimir Vasilev Rector of University ITMO 9 Welcome from the Governor of Saint Petersburg Dear friends, I’m glad to welcome organizers and partici- pants of the 37th ACM ICPC World Finals in Saint Petersburg. -

Table of Contents
Table of Contents Page Greetings ACM Japan 1 IBM Tokyo Research Lab 2 ACM 3 ICPC 4 IBM Executive Sponsor 5 UPE 6 World Finals Director 7 Minister of State for Innovation 8 IPSJ 9 Schedule of Events 11 About the Contest History and Growth 13 Past Winners 15 Rules 17 Policies and Procedures 21 World Finals Roster 25 2007 Awards ICPC Founders Award 31 ICPC World Finals Hosts Award 32 ICPC Distinguished International Service Award 33 Joseph S. DeBlasi Outstanding Contribution Award 34 2007 Staff and Volunteers 35 Host Committee 40 About ACM Japan 41 About IBM Tokyo Research Lab 42 IBM University Programs at a Glance 43 Japanese Phrases 44 Images of Japan 45 ACM International Collegiate Programming Contest World Finals 2007 - Tokyo, Japan Greetings from the ACM Japan Chapter Welcome to the 31st Annual ACM ICPC World Finals sponsored by IBM! Congratulations to all contestants for advancing to the World Finals! I am sure that you have all worked hard preparing for this contest. During this World Finals week, there will be numerous activities outside of the contest itself. Please take advantage of them. Make new friends; learn something new; and most important, enjoy yourselves! Some of you may have noticed that, unlike previous years, this World Finals is not hosted by a single university. ACM Japan Chapter is proud to co-host this event with the help of multiple universities. 2007 marks the 10th year that ACM Japan Chapter has been involved with ICPC at the regional contest level. So we are especially excited to have the opportu- nity to hold the World Finals in Japan this year. -

ACM INTERNATIONAL COLLEGIATE PROGRAMMING CONTEST Sponsored by IBM
The ACM INTERNATIONAL COLLEGIATE PROGRAMMING CONTEST sponsored by IBM FACT SHEET – December 9, 2005 – World Finals Second Edition About the Contest The ACM International Collegiate Programming Contest (ICPC) traces its roots to a competition held at Texas A&M in 1970 hosted by the Alpha Chapter of the UPE Computer Science Honor Society. The idea quickly gained popularity within the United States and Canada as an innovative initiative to challenge the top students in the emerging field of computer science. The contest evolved into a multi-tier competition with the first Finals held at the ACM Computer Science Conference in 1977. Operating under the auspices of ACM and headquartered at Baylor University since 1989, the contest has expanded into a global network of universities hosting regional competitions that advance teams to the ACM-ICPC World Finals. Since IBM became sponsor in 1997, the contest has increased by a factor of seven. Participation has grown to involve several tens of thousands of the finest students and faculty in computing disciplines at over 1,700 universities from 84 countries on six continents. The contest fosters creativity, teamwork, and innovation in building new software programs, and enables students to test their ability to perform under pressure. Quite simply, it is the oldest, largest, and most prestigious programming contest in the world. The annual event is comprised of several levels of competition: • Local Contests – Universities choose teams or hold local contests to select one or more teams to represent them at the next level of competition. Selection takes place from a field of over 300,000 students in computing disciplines worldwide. -
Survey for BS in Data Science
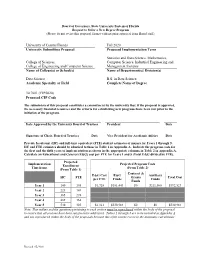
Board of Governors, State University System of Florida Request to Offer a New Degree Program (Please do not revise this proposal format without prior approval from Board staff) University of Central Florida Fall 2020 University Submitting Proposal Proposed Implementation Term Statistics and Data Science, Mathematics, College of Sciences, Computer Science, Industrial Engineering and College of Engineering and Computer Science Management Systems Name of College(s) or School(s) Name of Department(s)/ Division(s) Data Science B.S. in Data Science Academic Specialty or Field Complete Name of Degree 30.7001 (CIP2020) Proposed CIP Code The submission of this proposal constitutes a commitment by the university that, if the proposal is approved, the necessary financial resources and the criteria for establishing new programs have been met prior to the initiation of the program. Date Approved by the University Board of Trustees President Date Signature of Chair, Board of Trustees Date Vice President for Academic Affairs Date Provide headcount (HC) and full-time equivalent (FTE) student estimates of majors for Years 1 through 5. HC and FTE estimates should be identical to those in Table 1 in Appendix A. Indicate the program costs for the first and the fifth years of implementation as shown in the appropriate columns in Table 2 in Appendix A. Calculate an Educational and General (E&G) cost per FTE for Years 1 and 5 (Total E&G divided by FTE). Projected Implementation Projected Program Costs Enrollment Timeframe (From Table 2) (From Table 1) Contract & E&G Cost E&G Auxiliary HC FTE Grants Total Cost per FTE Funds Funds Funds Year 1 140 105 $1,728 $181,443 $0 $211,080 $392,523 Year 2 225 169 Year 3 365 274 Year 4 485 364 Year 5 540 405 $1,311 $530,984 $0 $0 $530,984 Note: This outline and the questions pertaining to each section must be reproduced within the body of the proposal to ensure that all sections have been satisfactorily addressed. -

Programming Challenges (PDF)
TEXTS IN COMPUTER SCIENCE Editors David Gries Fred B. Schneider Springer New York Berlin Heidelberg Hong Kong London Milan Paris Tokyo This page intentionally left blank Steven S. Skiena Miguel A. Revilla PROGRAMMING CHALLENGES The Programming Contest Training Manual With 65 Illustrations Steven S. Skiena Miguel A. Revilla Department of Computer Science Department of Applied Mathematics SUNY Stony Brook and Computer Science Stony Brook, NY 11794-4400, USA Faculty of Sciences [email protected] University of Valladolid Valladolid, 47011, SPAIN [email protected] Series Editors: David Gries Fred B. Schneider Department of Computer Science Department of Computer Science 415 Boyd Graduate Studies Upson Hall Research Center Cornell University The University of Georgia Ithaca, NY 14853-7501, USA Athens, GA 30602-7404, USA Cover illustration: “Spectator,” by William Rose © 2002. Library of Congress Cataloging-in-Publication Data Skeina, Steven S. Programming challenges : the programming contest training manual / Steven S. Skiena, Miguel A. Revilla. p. cm. — (Texts in computer science) Includes bibliographical references and index. ISBN 0-387-00163-8 (softcover : alk. paper) 1. Computer programming. I. Revilla, Miguel A. II. Title. III. Series. QA76.6.S598 2003 005.1—dc21 2002044523 ISBN 0-387-00163-8 Printed on acid-free paper. © 2003 Springer-Verlag New York, Inc. All rights reserved. This work may not be translated or copied in whole or in part without the written permission of the publisher (Springer-Verlag New York, Inc., 175 Fifth Avenue, New York, NY 10010, USA), except for brief excerpts in connection with reviews or scholarly analysis. Use in connection with any form of information storage and retrieval, electronic adaptation, computer software, or by similar or dissimilar methodology now known or hereafter developed is forbidden. -

Detroit Free Press
Detroit Free Press January 22, 2004 Thursday 0 EDITION WHERE HOCKEY IS KING: Keweenaw Peninsula embraces skates, sticks and pucks BY SHAWN WINDSOR that is, in many ways, defined ample, the home of Tom Izzo FREE PRESS by the game. and Steve Mariucci, basketball STAFF WRITER and football rule. "What do you do here in the Four-foot icicles hung high winter otherwise?" said the But from Houghton north to and dangerous from the out- stoic snowplow driver from the tip of the Keweenaw, it's side corners of the old rink, Mohawk, a few dozen homes all hockey. Consider that next stalactites crystallized during bunched together further up year is the 100-year anniver- the brutal winters in the most into Keweenaw. sary of the Portage Lakes, the remote region of the state. first professional hockey team It was the kind of moment in the world. The Lakes Inside the Armory, an anti- played out thousands of times played in the five-team Inter- quated, gun-metal shrine with in the snow-drenched national Hockey League. The a quarter-moon-shaped roof reaches of the Upper Penin- other teams were based in that pokes through the white- sula. From Houghton to Cop- Calumet, Pittsburgh, Sault out horizon in Calumet, young per Harbor, from Eagle River Ste. Marie, Mich., and Sault teenage boys swooped to Ahmeek, somewhere, Ste. Marie, Ontario. around the ice, crashing their someone, is lacing up a pair of 100-pound frames into the skates, grabbing a stick and The league lasted three boards, scrambling for the chasing a puck.