Effect of Grammar on Security of Long Passwords
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

NSA Vs. Encryption Article Written by Datto Developer Dan Fuhry First Appeared on Mspmentor.Com in November 2013
SuccessArticle: EncryptionStory NSA vs. Encryption Article written by Datto developer Dan Fuhry first appeared on MSPmentor.com in November 2013. If you’ve been watching the news lately, there is no doubt you have heard about the National Security Agency’s (NSA) surveillance scandal. “We will stand in our firm Recent months have seen a revelation of programs commitment to protect you and that capture domestic and international traffic indiscriminately. Encrypted data gets saved for a your customers.” certain number of years, in case they ever decide to decrypt it. If this alarms you, that’s good. You should be alarmed. I was too, on a very personal level, and have actively been working on changing some long-established habits in order to protect the information that is private and personal to me. For MSPs not in the United States you should be even more alarmed. It’s not even your own government that has the encrypted data, and since you don’t have constitutional protection in the U.S., there is nothing legally standing in the NSA’s way to prevent them from using their dark magical cryptographic powers to obtain your confidential business or personal data. This is a frightening proposition indeed, which is why I want to talk about the position Datto has taken regarding the recent revelations. Before we go any further, allow me to briefly describe my role here. I’m a developer with Datto, and I designed the encryption feature for Datto SIRIS. I picked the ciphers, hash algorithm parameters, and random number generator algorithm, had them peer-reviewed, and then wrote the code. -

Analysis of Password Cracking Methods & Applications
The University of Akron IdeaExchange@UAkron The Dr. Gary B. and Pamela S. Williams Honors Honors Research Projects College Spring 2015 Analysis of Password Cracking Methods & Applications John A. Chester The University Of Akron, [email protected] Please take a moment to share how this work helps you through this survey. Your feedback will be important as we plan further development of our repository. Follow this and additional works at: http://ideaexchange.uakron.edu/honors_research_projects Part of the Information Security Commons Recommended Citation Chester, John A., "Analysis of Password Cracking Methods & Applications" (2015). Honors Research Projects. 7. http://ideaexchange.uakron.edu/honors_research_projects/7 This Honors Research Project is brought to you for free and open access by The Dr. Gary B. and Pamela S. Williams Honors College at IdeaExchange@UAkron, the institutional repository of The nivU ersity of Akron in Akron, Ohio, USA. It has been accepted for inclusion in Honors Research Projects by an authorized administrator of IdeaExchange@UAkron. For more information, please contact [email protected], [email protected]. Analysis of Password Cracking Methods & Applications John A. Chester The University of Akron Abstract -- This project examines the nature of password cracking and modern applications. Several applications for different platforms are studied. Different methods of cracking are explained, including dictionary attack, brute force, and rainbow tables. Password cracking across different mediums is examined. Hashing and how it affects password cracking is discussed. An implementation of two hash-based password cracking algorithms is developed, along with experimental results of their efficiency. I. Introduction Password cracking is the process of either guessing or recovering a password from stored locations or from a data transmission system [1]. -

Implementation and Performance Analysis of PBKDF2, Bcrypt, Scrypt Algorithms
Implementation and Performance Analysis of PBKDF2, Bcrypt, Scrypt Algorithms Levent Ertaul, Manpreet Kaur, Venkata Arun Kumar R Gudise CSU East Bay, Hayward, CA, USA. [email protected], [email protected], [email protected] Abstract- With the increase in mobile wireless or data lookup. Whereas, Cryptographic hash functions are technologies, security breaches are also increasing. It has used for building blocks for HMACs which provides become critical to safeguard our sensitive information message authentication. They ensure integrity of the data from the wrongdoers. So, having strong password is that is transmitted. Collision free hash function is the one pivotal. As almost every website needs you to login and which can never have same hashes of different output. If a create a password, it’s tempting to use same password and b are inputs such that H (a) =H (b), and a ≠ b. for numerous websites like banks, shopping and social User chosen passwords shall not be used directly as networking websites. This way we are making our cryptographic keys as they have low entropy and information easily accessible to hackers. Hence, we need randomness properties [2].Password is the secret value from a strong application for password security and which the cryptographic key can be generated. Figure 1 management. In this paper, we are going to compare the shows the statics of increasing cybercrime every year. Hence performance of 3 key derivation algorithms, namely, there is a need for strong key generation algorithms which PBKDF2 (Password Based Key Derivation Function), can generate the keys which are nearly impossible for the Bcrypt and Scrypt. -

Key Derivation Functions and Their GPU Implementation
MASARYK UNIVERSITY FACULTY}w¡¢£¤¥¦§¨ OF I !"#$%&'()+,-./012345<yA|NFORMATICS Key derivation functions and their GPU implementation BACHELOR’S THESIS Ondrej Mosnáˇcek Brno, Spring 2015 This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. https://creativecommons.org/licenses/by-nc-sa/4.0/ cbna ii Declaration Hereby I declare, that this paper is my original authorial work, which I have worked out by my own. All sources, references and literature used or excerpted during elaboration of this work are properly cited and listed in complete reference to the due source. Ondrej Mosnáˇcek Advisor: Ing. Milan Brož iii Acknowledgement I would like to thank my supervisor for his guidance and support, and also for his extensive contributions to the Cryptsetup open- source project. Next, I would like to thank my family for their support and pa- tience and also to my friends who were falling behind schedule just like me and thus helped me not to panic. Last but not least, access to computing and storage facilities owned by parties and projects contributing to the National Grid In- frastructure MetaCentrum, provided under the programme “Projects of Large Infrastructure for Research, Development, and Innovations” (LM2010005), is also greatly appreciated. v Abstract Key derivation functions are a key element of many cryptographic applications. Password-based key derivation functions are designed specifically to derive cryptographic keys from low-entropy sources (such as passwords or passphrases) and to counter brute-force and dictionary attacks. However, the most widely adopted standard for password-based key derivation, PBKDF2, as implemented in most applications, is highly susceptible to attacks using Graphics Process- ing Units (GPUs). -

Thread Commissioning White Paper
July 13, 2015 This Thread Technical white paper is provided for reference purposes only. The full technical specification is available to Thread Group Members. To join and gain access, please follow this link: http://threadgroup.org/Join.aspx. If you are already a member, the full specification is available in the Thread Group Portal: http://portal.threadgroup.org. If there are questions or comments on these technical papers, please send them to [email protected]. This document and the information contained herein is provided on an “AS IS” basis and THE THREAD GROUP DISCLAIMS ALL WARRANTIES EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO (A) ANY WARRANTY THAT THE USE OF THE INFORMATION HEREIN WILL NOT INFRINGE ANY RIGHTS OF THIRD PARTIES (INCLUDING WITHOUT LIMITATION ANY INTELLECTUAL PROPERTY RIGHTS INCLUDING PATENT, COPYRIGHT OR TRADEMARK RIGHTS) OR (B) ANY IMPLIED WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE, TITLE OR NONINFRINGEMENT. IN NO EVENT WILL THE THREAD GROUP BE LIABLE FOR ANY LOSS OF PROFITS, LOSS OF BUSINESS, LOSS OF USE OF DATA, INTERRUPTION OF BUSINESS, OR FOR ANY OTHER DIRECT, INDIRECT, SPECIAL OR EXEMPLARY, INCIDENTAL, PUNITIVE OR CONSEQUENTIAL DAMAGES OF ANY KIND, IN CONTRACT OR IN TORT, IN CONNECTION WITH THIS DOCUMENT OR THE INFORMATION CONTAINED HEREIN, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH LOSS OR DAMAGE. Copyright 2015 Thread Group, Inc. All rights reserved. Thread Commissioning July 2015 Revision History Revision Date Comments 1.0 January 29, 2015 Initial Release 2.0 July 13, 2015 Public Release 1 Contents Introduction ................................................................................ 2 Terminology ................................................................................ 2 System Topology ............................................................................... 4 Degrees of Separation .......................................................................................... -

Harden Zero Knowledge Password Proofs Against Offline Dictionary
Harden Zero Knowledge Password Proofs Against Offline Dictionary Attacks Gijs Van Laer Rono Dasgupta Aditya Patil [email protected] [email protected] [email protected] Matthew Green [email protected] December 12, 2016 Abstract Traditional authentication systems offer ease of use but the security they provide often proves to be inadequate. Hackers use means to gain access to company servers and steal entire databases of password hashes. These hashes are then subject to offline dictionary attacks resulting in the disclosure of millions of passwords. Such password breaches have become commonplace and have caused several major companies to face major losses. Password reuse is a common practice among users and a password breach disclosing a single password on a particular service could result in a user also losing access to their other accounts. Solutions such as multi-factor authentication add some level of security but do not completely solve the problem. There is a need to move towards stronger authentication schemes that do not compromise on ease of use, both for the user and the service provider. In this paper, we propose a novel authentication protocol that is proven hard against offline dictionary attacks. Our protocol implements a combination of a Zero Knowledge Password Proof and a sequentially memory hard hash function. In a concrete instan- tiation of the protocol, we use Schnorr's Zero Knowledge Password Proof combined with the Fiat-Shamir Heuristic for the Zero Knowledge Password Proof and scrypt for the sequentially memory hard hash function. We also describe a library implementing our protocol that we have developed along with an example web application that uses the library. -

II-2.03 Encryption Policy
II-2.03 Encryption Policy The Universities at Shady Grove Effective Date: 5/01/2019 Policy Type: IT Security Policy Section II: Data Security PUBLIC Page 1 of 4 The Universities at Shady Grove is hereinafter referred to as "USG" and the Office of Information Technology as “OIT.” 1.0 Purpose The purpose of this policy is to outline USG's standards for use of encryption technology in order to properly secure and manage appropriately its data assets. There are additional USG security policies that reference the types of data that require encryption. This policy does not cover what types of data must be encrypted, but rather how encryption is to be implemented and controlled. 2.0 Scope The scope of this policy covers all data stored on or transmitted across USG-owned, USG- managed, and USG-leased systems, devices, media, and networks. This policy also applies to all USG hired personnel, contractors, and third-party services. 3.0 Policy 3.1 Encryption Minimum Standards USG requires the use of all encryption algorithms and standards to, at a minimum, comply with the following: • NIST Special Publication 800-175B (“Guideline for Using Cryptographic Standards in the Federal Government: Cryptographic Mechanisms”), • Federal Information Processing Standards (FIPS) Publication 140-2 (“Security Requirements for Cryptographic Modules”), • Or any other superseding publication, regulation, or USM/State of Maryland policy The use of proprietary encryption is expressly forbidden since it has not been subjected to public inspection and its security cannot -
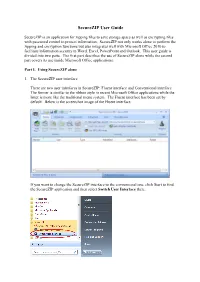
Securezip User Guide
SecureZIP User Guide SecureZIP is an application for zipping files to save storage space as well as encrypting files with password control to protect information. SecureZIP not only works alone to perform the zipping and encryption functions but also integrates well with Microsoft Office 2010 to facilitate information security in Word, Excel, PowerPoint and Outlook. This user guide is divided into two parts. The first part describes the use of SecureZIP alone while the second part covers its use inside Microsoft Office applications. Part I. Using SecureZIP alone 1. The SecureZIP user interface There are two user interfaces in SecureZIP: Fluent interface and Conventional interface. The former is similar to the ribbon style in recent Microsoft Office applications while the latter is more like the traditional menu system. The Fluent interface has been set by default. Below is the screenshot image of the Fluent interface. If you want to change the SecureZIP interface to the conventional one, click Start to find the SecureZIP application and then select Switch User Interface there. After clicking Switch User Interface, you will see the following window: You may choose to keep the Fluent interface or change it to the Conventional interface. Below is the screenshot image of the Conventional interface. 2. Encryption Method and Encryption Algorithm You can encrypt files to secure the information when you add them to an archive. For additional security, you may also encrypt the names of files and folders in an archive so that no information will be disclosed without the encryption password. Strong encryption is always preferred since it is far more secure than the older traditional ZIP encryption. -

Analysis and Processing of Cryptographic Protocols
Analysis and Processing of Cryptographic Protocols Submitted in partial fulfilment of the requirements of the degree of Bachelor of Science (Honours) of Rhodes University Bradley Cowie Grahamstown, South Africa November 2009 Abstract The field of Information Security and the sub-field of Cryptographic Protocols are both vast and continually evolving fields. The use of cryptographic protocols as a means to provide security to web servers and services at the transport layer, by providing both en- cryption and authentication to data transfer, has become increasingly popular. However, it is noted that it is rather difficult to perform legitimate analysis, intrusion detection and debugging on data that has passed through a cryptographic protocol as it is encrypted. The aim of this thesis is to design a framework, named Project Bellerophon, that is capa- ble of decrypting traffic that has been encrypted by an arbitrary cryptographic protocol. Once the plain-text has been retrieved further analysis may take place. To aid in this an in depth investigation of the TLS protocol was undertaken. This pro- duced a detailed document considering the message structures and the related fields con- tained within these messages which are involved in the TLS handshake process. Detailed examples explaining the processes that are involved in obtaining and generating the var- ious cryptographic components were explored. A systems design was proposed, considering the role of each of the components required in order to produce an accurate decryption of traffic encrypted by a cryptographic protocol. Investigations into the accuracy and the efficiency of Project Bellerophon to decrypt specific test data were conducted. -

Probabilistic Passphrase Cracking
Probabilistic Passphrase Cracking Luc Gommans Radically Open Security February 12, 2018 Abstract Passphrases are an alternative to passwords that are supposed to be easier to remember for users. For passwords, cracking tools are widely available, helping us understand their strengths and weaknesses. For passphrase cracking, there is currently no common approach which is universally seen as the most effective way. In this work, we attempted to find and implement the most effective method. We compared Markov chains, n-grams and a hybrid dictionary attack. The latter was found to be most effective, both in terms of efficiency and the number of results. Excluding the time required to build the dictionary from English Wikipedia and Wikiquote articles, it took only 10 minutes to crack over 2.3 million unique passphrases by using a hybrid dictionary attack with hashcat. Future users could download such a dictionary without having to compile it manually from various sources. 1 1 Introduction Requirements for secure passwords are getting more and more stringent to stay ahead of the increase in computational capacity of commonly accessible sys- tems. Using passphrases, users can approach the problem differently: instead of a complex sequence of characters, form a string of random, common words. The most famous example is `correct horse battery staple': four words with no coherence, but many people in the field can recall this phrase without ever trying to memorize it[own]. Studies also show that users have fewer difficulties when memorizing a passphrase than when memorizing equally-strong random passwords[behavioral-analysis][pwd-memorability]. Password cracking tools, which help us understand the strength (or weakness) of passwords, are widely available. -

8 Steps to a Strong Password, Infographic
8 steps to a strong password Imagine Lyrics Useful tips for your online protection A PASSWORD A;7;3oLSgkM’%3 epoxy hippo double pA5SWRD bread listen neuron plaza Word character alternatives Passphrase instead of password Imagine all the people living life Beware of a dictionary attack 1 do not work 2 A passphrase is a multi-word password that is specific 3 in peace... 4 Due to the growing sophistication of attacks, replacing letters and has meaning. This “hidden sense” makes the passphrase A few words of caution about passphrases. Although this A dictionary attack is a method of hacking your password with numbers or special characters does not work if the easier to remember for its creator. It is much harder to 8-word phrase looks like an unbeatable passphrase, by systematically entering similar terms from various original word mirrors an existing dictionary word. Attackers memorize passwords containing a long string of letters the opposite is true. Famous quotes and well-known phrases dictionaries. To prevent attackers cracking your password expect character alternatives and can predict their usage. (lower/upper case), numbers and characters than or lyrics are highly predictable. Cybercriminals exploit by this method, we suggest you use at least a 7-word a meaningful passphrase. databases of popular phrases, so it is not so dicult to crack passphrase with words in random order. your multi-word password. Change the order of words randomly. It will make your passphrase more secure. epoxy hippo double bread listen neuron PASSWORDS Your OTP is 364956 ****** plaza 6 months 27 million years More is better One passphrase for one site 2-Factor Authentication Use a password vault 5 Why a 7 word passphrase? Because password strength is 6 The basic rule is do not use the same passwords or 7 2FA is always a good way to deter attackers. -

Security Analysis of Truecrypt
Security Analysis of TrueCrypt November 16, 2015 Authors This study was executed by the Fraunhofer Institute for Secure Information Technology on behalf of the Federal Office for Information Security. This publication was authored by Mauro Baluda Andreas Fuchs Philipp Holzinger Lisa Nguyen Lotfi ben Othmane Andreas Poller Jürgen Repp Johannes Späth Jan Steffan Stefan Triller Eric Bodden Fraunhofer Institute for Secure Information Technology Rheinstraße 75 64295 Darmstadt Germany The authors wish to thank Andreas Junestam and Nicolas Guigo of the Open Crypto Audit Project for clarifications regarding their own security assessment of TrueCrypt. Thanks go also to Andreas Follner, Technische Universtät Darmstadt, who gave valueable input regarding the exploitability of buffer-overflow vulnerabilities that the OCAP-report mentions. Federal Office for Information Security Post Box 20 03 63 D-53133 Bonn Phone: +49 22899 9582-0 E-Mail: [email protected] Internet: https://www.bsi.bund.de © Federal Office for Information Security 2015 Security Analysis of TrueCrypt Contents 1 Summary 6 1.1 Aim ........................................... 6 1.2 Procedure........................................ 6 1.3 Results.......................................... 7 2 Analysis of the differences between versions 7.0a and 7.1a9 2.1 Procedure........................................ 9 2.2 Differences relevant to security ............................ 9 2.3 Other differences.................................... 10 2.4 Summary ........................................ 11 3 Evaluation of the OCAP Phase 1 Test Report 13 3.1 Comments on OCAP.................................. 13 3.1.1 Scope of the report............................... 13 3.1.2 Comments on the individual findings of the OCAP report......... 13 3.1.3 Detailed manual analysis of Finding 3 .................... 15 3.1.4 Checking the findings using Coverity....................