BCIS 1305 Business Computer Applications
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Xerox 4890 Highlight Color Laser Printing System Product Reference
XEROX Xerox 4890 HighLight Color Laser Printing System Product Reference Version 5.0 November 1994 720P93720 Xerox Corporation 701 South Aviation Boulevard El Segundo, California 90245 ©1991, 1992, 1993, 1994 by Xerox Corporation. All rights reserved. Copyright protection claimed includes all forms and matters of copyrightable material and information now allowed by statutory or judicial law or hereinafter granted, including without limitation, material generated from the software programs which are displayed on the screen such as icons, screen displays, looks, etc. November 1994 Printed in the United States of America. Publication number: 721P82591 Xerox® and all Xerox products mentioned in this publication are trademarks of Xerox Corporation. Products and trademarks of other companies are also acknowledged. Changes are periodically made to this document. Changes, technical inaccuracies, and typographic errors will be corrected in subsequent editions. This book was produced using the Xerox 6085 Professional Computer System. The typefaces used are Optima, Terminal, and monospace. Table of contents 1. LPS fundamentals 1-1 Electronic printing 1-1 Advantages 1-1 Highlight color 1-2 Uses for highlight color in your documents 1-2 How highlight color is created 1-2 Specifying 4890 colors 1-3 Color-related software considerations 1-4 Adding color to line printer and LCDS data streams 1-4 Adding color to Interpress and PostScript data streams 1-5 Adding color to forms 1-6 Fonts 1-8 Acquiring and loading fonts 1-9 LPS production process overview 1-9 Ink referencing 1-10 Unformatted data 1-10 Formatted data 1-11 4890 HighLight Color LPS major features 1-11 4890 feature reference 1-12 LPS connection options 1-12 System controller 1-13 Optional peripheral cabinet 1-13 Printer 1-13 Paper handling 1-14 Forms 1-15 Fonts 1-15 Printed format 1-15 Highlight color 1-16 Types of output 1-16 DFA/Segment Management 1-16 SCSI System Disk/Floppy Disk 1-18 Color Enhancements 1-18 XEROX 4890 HIGHLIGHT COLOR LPS PRODUCT REFERENCE iii TABLE OF CONTENTS 2. -

Optional Package 1WIRE Paket OPT OW V. 1.0.0 Für Fli4l - 3.4.0
Optional Package 1WIRE Paket OPT_OW V. 1.0.0 für Fli4L - 3.4.0 Karl M. Weckler [email protected] Rockenberg, Mai 2009 OPT_OW Inhaltsverzeichnis Paket OPT_OW.......................................................................................................... 1 Inhaltsverzeichnis ....................................................................................................... 2 Dokumentation des Paketes OPT_OW ...................................................................... 3 1. Einleitung................................................................................................................ 3 1.1. OPT_OW ......................................................................................................... 3 1.2. OW = OneWire = 1-Wire .................................................................................. 3 1.2.1. Der 1-Wire Standard.................................................................................. 3 1.2.2. 1-Wire-Bauteile.......................................................................................... 3 1.2.3. 1-Wire Bus................................................................................................. 3 1.3. OWFS .............................................................................................................. 4 1.4. Fuse................................................................................................................. 4 2. Lizenz .................................................................................................................... -

(Form Factor), Btx (Form Factor), Computer Form
0NB8RPHZLWIR » Book » Motherboard Form Factors: Atx, at (Form Factor), Btx (Form Factor), Computer Form... Read eBook Online MOTHERBOARD FORM FACTORS: ATX, AT (FORM FACTOR), BTX (FORM FACTOR), COMPUTER FORM FACTOR, COM EXPRESS, COREEXPRESS, DIAMOND SYSTEMS CORPORATION, To read Motherboard Form Factors: Atx, at (Form Factor), Btx (Form Factor), Computer Form Factor, Com Express, Coreexpress, Diamond Systems Corporation, PDF, please refer to the hyperlink beneath and download the document or gain access to other information which might be have conjunction with MOTHERBOARD FORM FACTORS: ATX, AT (FORM FACTOR), BTX (FORM FACTOR), COMPUTER FORM FACTOR, COM EXPRESS, COREEXPRESS, DIAMOND SYSTEMS CORPORATION, book. Download PDF Motherboard Form Factors: Atx, at (Form Factor), Btx (Form Factor), Computer Form Factor, Com Express, Coreexpress, Diamond Systems Corporation, Authored by Source Wikipedia Released at 2016 Filesize: 2.04 MB Reviews A really awesome pdf with perfect and lucid reasons. Yes, it is actually engage in, continue to an interesting and amazing literature. I am effortlessly will get a delight of studying a published pdf. -- Shaniya Stamm Extremely helpful to all of group of people. It really is loaded with wisdom and knowledge I am just delighted to inform you that this is actually the best pdf we have read within my personal existence and might be he very best publication for possibly. -- Lon Jerde This publication is amazing. it absolutely was writtern very completely and helpful. Its been printed in an remarkably straightforward way and it is simply after i finished reading through this ebook through which in fact altered me, change the way i think. -- Jodie Schneider TERMS | DMCA EGV2GBDX9VA8 » PDF » Motherboard Form Factors: Atx, at (Form Factor), Btx (Form Factor), Computer Form.. -

What Is an Operating System III 2.1 Compnents II an Operating System
Page 1 of 6 What is an Operating System III 2.1 Compnents II An operating system (OS) is software that manages computer hardware and software resources and provides common services for computer programs. The operating system is an essential component of the system software in a computer system. Application programs usually require an operating system to function. Memory management Among other things, a multiprogramming operating system kernel must be responsible for managing all system memory which is currently in use by programs. This ensures that a program does not interfere with memory already in use by another program. Since programs time share, each program must have independent access to memory. Cooperative memory management, used by many early operating systems, assumes that all programs make voluntary use of the kernel's memory manager, and do not exceed their allocated memory. This system of memory management is almost never seen any more, since programs often contain bugs which can cause them to exceed their allocated memory. If a program fails, it may cause memory used by one or more other programs to be affected or overwritten. Malicious programs or viruses may purposefully alter another program's memory, or may affect the operation of the operating system itself. With cooperative memory management, it takes only one misbehaved program to crash the system. Memory protection enables the kernel to limit a process' access to the computer's memory. Various methods of memory protection exist, including memory segmentation and paging. All methods require some level of hardware support (such as the 80286 MMU), which doesn't exist in all computers. -

Powerview Command Reference
PowerView Command Reference TRACE32 Online Help TRACE32 Directory TRACE32 Index TRACE32 Documents ...................................................................................................................... PowerView User Interface ............................................................................................................ PowerView Command Reference .............................................................................................1 History ...................................................................................................................................... 12 ABORT ...................................................................................................................................... 13 ABORT Abort driver program 13 AREA ........................................................................................................................................ 14 AREA Message windows 14 AREA.CLEAR Clear area 15 AREA.CLOSE Close output file 15 AREA.Create Create or modify message area 16 AREA.Delete Delete message area 17 AREA.List Display a detailed list off all message areas 18 AREA.OPEN Open output file 20 AREA.PIPE Redirect area to stdout 21 AREA.RESet Reset areas 21 AREA.SAVE Save AREA window contents to file 21 AREA.Select Select area 22 AREA.STDERR Redirect area to stderr 23 AREA.STDOUT Redirect area to stdout 23 AREA.view Display message area in AREA window 24 AutoSTOre .............................................................................................................................. -

Linux. Sécuriser Un Réseau
11960_Securiser_Linux_XP 31/10/06 9:40 Page 1 Cahiers Cahiers de de l’Admin Collection dirigée par Nat Makarévitch Delaunay Boutherin l’Admin B. B. Ingénieur de formation, Bernard Boutherin a éd. éd. e été administrateur système et e 3 édition réseau successivement dans e trois laboratoires du CNRS. Il 3 est actuellement responsable in- 3 Quelles règles d’or appliquer pour préserver la sûreté d’un réseau Linux ? formatique du LPSC à Grenoble Comment protéger les systèmes et les données ? et est chargé de mission pour la sécurité informatique auprès de la direction de l’IN2P3 (18 labo- Grâce à des principes simples et à la mise en œuvre d’outils libres réputés pour ratoires de recherche, près de leur efficacité, on apprendra dans ce cahier à améliorer l’architecture d’un réseau trois mille utilisateurs). d’entreprise et à le protéger contre les intrusions, dénis de service et autres Bernard Boutherin attaques. On verra notamment comment filtrer des flux (netfilter/IPtables…), De formation universitaire, sécuriser la messagerie (milter-greylist, ClamAV…), chiffrer avec SSL (stunnel…) Benoit Delaunay travaille Benoit Delaunay et (Open)SSH. On étudiera les techniques et outils de surveillance (métrologie avec actuellement au Centre de Cal- MRTG, empreintes Tripwire, détection d’intrusion avec des outils tel Snort, créa- cul de l’IN2P3 (Institut National tion de tableaux de bord) et l’authentification unique (SSO) avec LDAP, Kerberos, de Physique Nucléaire et de PAM, les certificats X509 et les PKI… Physique des Particules). Il y est Linux administrateur système et ré- Linux seau en charge de la sécurité informatique. -
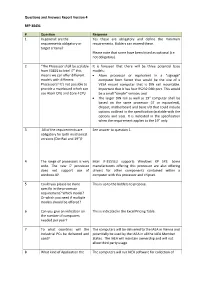
Questions and Answers Report Version 4 RFP 30431 # Question
Questions and Answers Report Version 4 RFP 30431 # Question Response 1 In general: are the Yes these are obligatory and define the minimum requirements obligatory or requirements. Bidders can exceed these. target criteria? Please note that some have been listed as optional (i.e. not obligatory). 2 “The Processor shall be scalable It is foreseen that there will be three potential base from E3825 to Intel i7” this models: means we can offer different • Atom processor or equivalent in a “signage” models with different computer form factor that would be the size of a Processors? It’s not possible to VESA mount computer that is DIN rail mountable. provide a mainboard which can Important that it has four RS232 DB9 port. This would use Atom CPU and Core-I CPU be a small “simple” version; and • The larger DIN rail as well as 19” computer shall be based on the same processor (i7 or equivalent), chipset, motherboard and basic I/O that could include options outlined in the specification (scalable with the options and size). It is indicated in the specification when the requirement applies to the 19” only. 3 All of the requirements are See answer to question 1. obligatory for both mechanical versions (Din-Rail and 19”)? 4 The range of processors is very Intel i7-3555LU supports Windows XP SP3. Some wide. The new i7 processor manufacturers offering this processor are also offering does not support use of drivers for other components contained within a windows XP. computer with this processor and chipset. 5 Could you please be more This is up to the bidders to propose. -

Irmx® 286/Irmx® II Troubleshooting Guide
iRMX® 286/iRMX® II Troubleshooting Guide Q1/1990 Order Number: 273472-001 inter iRMX® 286/iRMX® II Troubleshooting Guide Q1/1990 Order Number: 273472-001 Intel Corporation 2402 W. Beardsley Road Phoenix, Arizona Mailstop DV2-42 Intel Corporation (UK) Ltd. Pipers Way Swindon, Wiltshire SN3 1 RJ United Kingdom Intel Japan KK 5-6 Tokodai, Toyosato-machi Tsukuba-gun Ibaragi-Pref. 300-26 An Intel Technical Report from Technical Support Operations Copyright ©1990, Intel Corporation Copyright ©1990, Intel Corporation The information in this document is subject to change without notice. Intel Corporation makes no warranty of any kind with regard to this material, including, but not limited to, the implied warranties of merchantability and fitness for a particular purpose. Intel Corporation assumes no responsibility for any errors that ~ay :!ppe3r in this d~ur:::ent. Intel Corpomtion make:; nc ccmmitmcut tv update nor to keep C"l..iiTeilt thc information contained in this document. Intel Corporation assUmes no responsibility for the use of any circuitry other than circuitry embodied in an Intel product. No other circuit patent licenses are implied. Intel software products are copyrighted by and shall remain the property of Intel Corporation. Use, duplication or disclosure is subject to restrictions stated in Intel's software license, or as defined in FAR 52.227-7013. No part of this document may be copied or reproduced in any form or by any means without the prior written consent of Intel Corporation. The following are trademarks of Intel Corporation -

The Profession of IT Multitasking Without Thrashing Lessons from Operating Systems Teach How to Do Multitasking Without Thrashing
viewpoints VDOI:10.1145/3126494 Peter J. Denning The Profession of IT Multitasking Without Thrashing Lessons from operating systems teach how to do multitasking without thrashing. UR INDIVIDUAL ABILITY to The first four destinations basi- mercial world with its OS 360 in 1965. be productive has been cally remove incoming tasks from your Operating systems implement mul- hard stressed by the sheer workspace, the fifth closes quick loops, titasking by cycling a CPU through a load of task requests we and the sixth holds your incomplete list of all incomplete tasks, giving each receive via the Internet. In loops. GTD helps you keep track of one a time slice on the CPU. If the task 2001, David Allen published Getting these unfinished loops. does not complete by the end of its O 1 Things Done, a best-selling book about The idea of tasks being closed loops time slice, the OS interrupts it and puts a system for managing all our tasks to of a conversation between a requester it on the end of the list. To switch the eliminate stress and increase produc- and a perform was first proposed in CPU context, the OS saves all the CPU tivity. Allen claims that a considerable 1979 by Fernando Flores.5 The “condi- registers of the current task and loads amount of stress comes our way when tions of satisfaction” that are produced the registers of the new task. The de- we have too many incomplete tasks. by the performer define loop comple- signers set the time slice length long He views tasks as loops connecting tion and allow tracking the movement enough to keep the total context switch someone making a request and you of the conversation toward completion. -

Department of Electrical Engineering
Display of digitally processed data Item Type text; Thesis-Reproduction (electronic) Authors Jurich, Samuel, 1929- Publisher The University of Arizona. Rights Copyright © is held by the author. Digital access to this material is made possible by the University Libraries, University of Arizona. Further transmission, reproduction or presentation (such as public display or performance) of protected items is prohibited except with permission of the author. Download date 23/09/2021 17:48:33 Link to Item http://hdl.handle.net/10150/551403 DISPLAY OP DIGITALLY PROCESSED DATA ■ v : ' hJ Sarauel Jurlch A Thesis Submitted to the Faculty of the : - ‘ DEPARTMENT OF ELECTRICAL ENGINEERING In Partial Fulfillment of the Requirements For the Degree of : o ' MASTER OF SCIENCE : ' In the Graduate College A UNIVERSITY OF ARIZONA 1 9 5 9 This thesis has been submitted in partial fulfillment of requirements for an advanced degree at the University of Arizona and is deposited in the University Library to be made available to borrowers under rules of the Library. Brief quotations from this thesis are allowable without special permission, provided that accurate acknowledgment of source is made. Requests for permission for extended quotation from or reproduction of this manuscript in whole or in part may be granted by the head of the major department or the Dean of the Graduate College when in their judgment the proposed use of the material is in the interests of scholarship. In all other instances, however, permission must be obtained from the author. SIGNED: This thesis has been approved on the date shown below: 6 4f/?y /9S~<7 John R. -

English Arabic Technical Computing Dictionary
English Arabic Technical Computing Dictionary Arabeyes Arabisation Team http://wiki.arabeyes.org/Technical Dictionary Versin: 0.1.29-04-2007 April 29, 2007 This is a compilation of the Technical Computing Dictionary that is under development at Arabeyes, the Arabic UNIX project. The technical dictionary aims to to translate and standardise technical terms that are used in software. It is an effort to unify the terms used across all Open Source projects and to present the user with consistant and understandable interfaces. This work is licensed under the FreeBSD Documentation License, the text of which is available at the back of this document. Contributors are welcome, please consult the URL above or contact [email protected]. Q Ì ÉJ ªË@ éÒ¢@ Ñ«YË QK AK.Q« ¨ðQåÓ .« èQK ñ¢ ÕæK ø YË@ úæ®JË@ úGñAm '@ ñÓA®ÊË éj èYë . l×. @QK. éÔg. QK ú¯ éÊÒªJÖÏ@ éJ J®JË@ HAjÊ¢Ö Ï@ YJ kñKð éÔg. QK úÍ@ ñÓA®Ë@ ¬YîE .ºKñJ ËAK. éîD J.Ë@ ÐYjJÒÊË éÒj. Óð éÓñê®Ó H. ñAg éêk. @ð Õç'Y®JË ð á ÔgQÖÏ@ á K. H. PAJË@ øXA®JË ,H. ñAmÌ'@ . ¾JÖ Ï .ñÓA®Ë@ éK AîE ú ¯ èQ¯ñJÖÏ@ ð ZAKñÊË ø X @ ú G. ø Q¯ ékP ù ë ñÓA®Ë@ ékP . éJ K.QªËAK. ÕÎ @ [email protected] . úΫ ÈAB@ ð@ èC«@ à@ñJªË@ úÍ@ H. AëYË@ ZAg. QË@ ,á ÒëAÖÏ@ ɾK. I. kQK A Abortive release êm .× (ú¾J.) ¨A¢®K@ Abort Aêk . @ Abscissa ú æJ Absolute address Ê¢Ó à@ñ J« Absolute pathname Ê¢Ó PAÓ Õæ @ Absolute path Ê¢Ó PAÓ Absolute Ê¢Ó Abstract class XQm.× J Abstract data type XQm.× HA KAJ K. -

1St Slide Set Operating Systems
Organizational Information Operating Systems Generations of Computer Systems and Operating Systems 1st Slide Set Operating Systems Prof. Dr. Christian Baun Frankfurt University of Applied Sciences (1971–2014: Fachhochschule Frankfurt am Main) Faculty of Computer Science and Engineering [email protected] Prof. Dr. Christian Baun – 1st Slide Set Operating Systems – Frankfurt University of Applied Sciences – WS2021 1/24 Organizational Information Operating Systems Generations of Computer Systems and Operating Systems Organizational Information E-Mail: [email protected] !!! Tell me when problems problems exist at an early stage !!! Homepage: http://www.christianbaun.de !!! Check the course page regularly !!! The homepage contains among others the lecture notes Presentation slides in English and German language Exercise sheets in English and German language Sample solutions of the exercise sheers Old exams and their sample solutions What is the password? There is no password! The content of the English and German slides is identical, but please use the English slides for the exam preparation to become familiar with the technical terms Prof. Dr. Christian Baun – 1st Slide Set Operating Systems – Frankfurt University of Applied Sciences – WS2021 2/24 Organizational Information Operating Systems Generations of Computer Systems and Operating Systems Literature My slide sets were the basis for these books The two-column layout (English/German) of the bilingual book is quite useful for this course You can download both books for free via the FRA-UAS library from the intranet Prof. Dr. Christian Baun – 1st Slide Set Operating Systems – Frankfurt University of Applied Sciences – WS2021 3/24 Organizational Information Operating Systems Generations of Computer Systems and Operating Systems Learning Objectives of this Slide Set At the end of this slide set You know/understand.