Introduction to Scientific Computing
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

IPS Signature Release Note V9.17.79
SOPHOS IPS Signature Update Release Notes Version : 9.17.79 Release Date : 19th January 2020 IPS Signature Update Release Information Upgrade Applicable on IPS Signature Release Version 9.17.78 CR250i, CR300i, CR500i-4P, CR500i-6P, CR500i-8P, CR500ia, CR500ia-RP, CR500ia1F, CR500ia10F, CR750ia, CR750ia1F, CR750ia10F, CR1000i-11P, CR1000i-12P, CR1000ia, CR1000ia10F, CR1500i-11P, CR1500i-12P, CR1500ia, CR1500ia10F Sophos Appliance Models CR25iNG, CR25iNG-6P, CR35iNG, CR50iNG, CR100iNG, CR200iNG/XP, CR300iNG/XP, CR500iNG- XP, CR750iNG-XP, CR2500iNG, CR25wiNG, CR25wiNG-6P, CR35wiNG, CRiV1C, CRiV2C, CRiV4C, CRiV8C, CRiV12C, XG85 to XG450, SG105 to SG650 Upgrade Information Upgrade type: Automatic Compatibility Annotations: None Introduction The Release Note document for IPS Signature Database Version 9.17.79 includes support for the new signatures. The following sections describe the release in detail. New IPS Signatures The Sophos Intrusion Prevention System shields the network from known attacks by matching the network traffic against the signatures in the IPS Signature Database. These signatures are developed to significantly increase detection performance and reduce the false alarms. Report false positives at [email protected], along with the application details. January 2020 Page 2 of 245 IPS Signature Update This IPS Release includes Two Thousand, Seven Hundred and Sixty Two(2762) signatures to address One Thousand, Nine Hundred and Thirty Eight(1938) vulnerabilities. New signatures are added for the following vulnerabilities: Name CVE–ID -

Index Images Download 2006 News Crack Serial Warez Full 12 Contact
index images download 2006 news crack serial warez full 12 contact about search spacer privacy 11 logo blog new 10 cgi-bin faq rss home img default 2005 products sitemap archives 1 09 links 01 08 06 2 07 login articles support 05 keygen article 04 03 help events archive 02 register en forum software downloads 3 security 13 category 4 content 14 main 15 press media templates services icons resources info profile 16 2004 18 docs contactus files features html 20 21 5 22 page 6 misc 19 partners 24 terms 2007 23 17 i 27 top 26 9 legal 30 banners xml 29 28 7 tools projects 25 0 user feed themes linux forums jobs business 8 video email books banner reviews view graphics research feedback pdf print ads modules 2003 company blank pub games copyright common site comments people aboutus product sports logos buttons english story image uploads 31 subscribe blogs atom gallery newsletter stats careers music pages publications technology calendar stories photos papers community data history arrow submit www s web library wiki header education go internet b in advertise spam a nav mail users Images members topics disclaimer store clear feeds c awards 2002 Default general pics dir signup solutions map News public doc de weblog index2 shop contacts fr homepage travel button pixel list viewtopic documents overview tips adclick contact_us movies wp-content catalog us p staff hardware wireless global screenshots apps online version directory mobile other advertising tech welcome admin t policy faqs link 2001 training releases space member static join health -

Analyzing Metadata Performance in Distributed File Systems
Inaugural-Dissertation zur Erlangung der Doktorwurde¨ der Naturwissenschaftlich-Mathematischen Gesamtfakultat¨ der Ruprecht-Karls-Universitat¨ Heidelberg vorgelegt von Diplom-Informatiker Christoph Biardzki aus Thorn Tag der mundlichen¨ Prufung:¨ 19.1.2009 Analyzing Metadata Performance in Distributed File Systems Gutachter: Prof. Dr. Thomas Ludwig Abstract Distributed file systems are important building blocks in modern computing environments. The challenge of increasing I/O bandwidth to files has been largely resolved by the use of parallel file systems and sufficient hardware. However, determining the best means by which to manage large amounts of metadata, which contains information about files and directories stored in a distributed file system, has proved a more difficult challenge. The objective of this thesis is to analyze the role of metadata and present past and current implementations and access semantics. Understanding the development of the current file system interfaces and functionality is a key to understanding their performance limitations. Based on this analysis, a distributed metadata benchmark termed DMetabench is presented. DMetabench significantly improves on existing benchmarks and allows stress on meta- data operations in a distributed file system in a parallelized manner. Both intra-node and inter-node parallelity, current trends in computer architecture, can be explicitly tested with DMetabench. This is due to the fact that a distributed file system can have different seman- tics inside a client node rather than semantics between multiple nodes. As measurements in larger distributed environments may exhibit performance artifacts difficult to explain by reference to average numbers, DMetabench uses a time-logging tech- nique to record time-related changes in the performance of metadata operations and also protocols additional details of the runtime environment for post-benchmark analysis. -

Asterisk/Astguiclient Install from Scratch. V.2.0.4 2007-12-03 by the Astguiclient Group [email protected]
Asterisk/astguiclient install from scratch. v.2.0.4 2007-12-03 By the astGUIclient group [email protected] **** IMPORTANT - In order for vicidial/astguiclient to function correctly please read the REQUIREMENTS.txt for a minimum requirements list. *** End-user Manuals for Agents and Managers are available from http://www.eflo.net This document is meant to be a very in-depth step-by-step explanation of installing the Asterisk open-source PBX on a Linux system and also installing the astGUIclient suite. The instructions will assume starting from nothing and will try to give several side step instructions to account for some differences in choices of hardware and software. The actual installation that I am doing as I write these instructions will be on the following hardware: - Pentium 3 500MHz - Intel motherboard D815BN - 256MB PC133 RAM - 80GB IBM deskstar 7200RPM Hard Drive - Digium Wildcard Single Span T1 Card T100P - 2U rackmount case with 250W power supply - Phone hardware will be a Grandstream BT102 and a Sipura SPA-2000 because they are so cheap and readily available All of these parts, aside from the Digium card and the two SIP VOIP devices, were purchased from ebay and the entire package(with the two VOIP devices and all server hardware included) cost me about $1100 to put together including the phones and Digium adapter. We have many other Asterisk servers at our main office, but this one can be experimented with easily because it was so cheap to make and has a relatively small capacity when compared with a multi-processor server with a quad span T1 card. -

Migration from Windows to Linux for a Small Engineering Firm "A&G Associates"
Rochester Institute of Technology RIT Scholar Works Theses 2004 Migration from Windows to Linux for a small engineering firm "A&G Associates" Trimbak Vohra Follow this and additional works at: https://scholarworks.rit.edu/theses Recommended Citation Vohra, Trimbak, "Migration from Windows to Linux for a small engineering firm A&G" Associates"" (2004). Thesis. Rochester Institute of Technology. Accessed from This Thesis is brought to you for free and open access by RIT Scholar Works. It has been accepted for inclusion in Theses by an authorized administrator of RIT Scholar Works. For more information, please contact [email protected]. Migration from Windows to Linux for a Small Engineering Firm "A&G Associates" (H ' _T ^^L. WBBmBmBBBBmb- Windows Linux by Trimbak Vohra Thesis submitted in partial fulfillment of the requirements for the degree of Master of Science in Information Technology Rochester Institute of Technology B. Thomas Golisano College of Computing and Information Sciences Date: December 2, 2004 12/B2/28B2 14:46 5854752181 RIT INFORMATION TECH PAGE 02 Rochester Institute of Teehnology B. Thomas Golisano College of Computing and Information Sciences Master of Science in Information Technology Thesis Approval Form Student Name: Trimbak Vohra Thesis Title: Migration from Windows to Unux for a Small Engineeriog Firm "A&G Associates" Thesis Committee Name Signature Date Luther Troell luther IrQell, Ph.D ttL ",j7/Uy Chair G. L. Barido Prof. ~~orge Barido ? - Dec:. -cl7' Committee Member Thomas Oxford Mr. Thomas OxfocQ \ 2. L~( Q~ Committee Member Thesis Reproduction Permission Form Rochester Institute of Technology B. Thomas Golisano College of Computing and Information Sciences Master of Science in Information Technology Migration from Windows to Linux for a Small Engineering Firm "A&G Associates" I,Trimbak Vohra, hereby grant permission to the Wallace Library of the Rochester Institute of Technology to reproduce my thesis in whole or in part. -
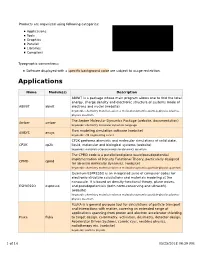
Libraries Compilers
Products are organized using following categories: Applications Tools Graphics Parallel Libraries Compilers Typographic conventions: Software displayed with a specific background color are subject to usage restriction. Applications Name Module(s) Description ABINIT is a package whose main program allows one to find the total energy, charge density and electronic structure of systems made of ABINIT abinit electrons and nuclei (website) keywords: chemistry materials-science molecular-dynamics particle-physics plasma- physics quantum The Amber Molecular Dynamics Package (website, documentation) Amber amber keywords: chemistry molecular-dynamics language Flow modeling simulation software (website) ANSYS ansys keywords: cfd engineering solver CP2K performs atomistic and molecular simulations of solid state, CP2K cp2k liquid, molecular and biological systems (website) keywords: materials-science molecular-dynamics quantum The CPMD code is a parallelized plane wave/pseudopotential implementation of Density Functional Theory, particularly designed CPMD cpmd for ab-initio molecular dynamics. (website) keywords: chemistry materials-science molecular-dynamics particle-physics quantum Quantum ESPRESSO is an integrated suite of computer codes for electronic-structure calculations and materials modeling at the nanoscale. It is based on density-functional theory, plane waves, ESPRESSO espresso and pseudopotentials (both norm-conserving and ultrasoft). (website) keywords: chemistry materials-science molecular-dynamics particle-physics plasma- physics quantum -

Free Software Statistics
Free Software click here to return to methods page click here to return to social change page This page lists primarily statistical software, along with mapping, spreadsheets, database, stuff to do data analysis or management. At the bottom of this page, I list some pages that link to other free software and computer related stuff, like browsers, office suites, computer security, etc. Please note: I've only used a few of these software programs a little bit, so I can't say much about how good they are, whether they crash, have viruses, or much else about them. If you use them, please let me know how well they work. If there are any major problems, I'll take them off this list. I'm sorry to add the usual disclaimer that, while I don't expect any probems with them, if you use any of these, I can't be responsible for any problems that may occur. Also, I'm not necessarily recommending any, just providing info and links. Statistics There are many free statistical programs. Here http://en.citizendium.org/wiki/Free_statistical_software for an article at Citizendium about free statistical software (draft as of April 2009). Also see here http://gsociology.icaap.org/methods/softsum.html for a brief summary of some of the programs. Several of these stat programs were reviewed in an article in the Journal of Industrial Technology, (Volume 21-2, April 2005). http://www.nait.org/jit/current.html "A Short Preview of Free Statistical Software Packages for Teaching Statistics to Industrial Technology Majors" Ms. -
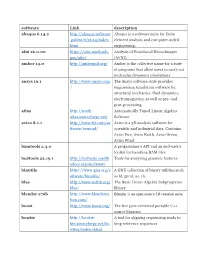
Software Link Description Abaqus 6.14.2 Abaqus Is a Software Suite for Finite .Polimi.It/V6.14/Index
software Link description abaqus 6.14.2 http://abaqus.software Abaqus is a software suite for finite .polimi.it/v6.14/index. element analysis and computer-aided html engineering. afni 16.0.00 https://afni.nimh.nih. Analysis of Functional NeuroImages gov/afni/ (AFNI) amber 14.0 http://ambermd.org/ Amber is the collective name for a suite of programs that allow users to carry out molecular dynamics simulations ansys 16.1 http://www.ansys.com The Ansys software suite provides / engineering simulation software for structural mechanics, fluid dynamics, electromagnetics, as well as pre- and post-processing. atlas http://math- Automatically Tuned Linear Algebra atlas.sourceforge.net/ Software avizo 8.1.1 http://www.fei.com/so Avizo is a 3D analysis software for ftware/avizo3d/ scientific and industrial data. Contains Avizo Fire, Avizo Earth, Avizo Green, Avizo Wind bamtools 2.3.0 A programmer's API and an end-user's toolkit for handling BAM files. bedtools 22.19.1 http://bedtools.readth Tools for analyzing genomic features edocs.org/en/latest/ binutils https://www.gnu.org/s A GNU collection of binary utilities such oftware/binutils/ as ld, gprof, as, etc. blas http://www.netlib.org/ The Basic Linear Algebra Subprograms blas/ library blender 276b http://www.blenderna Blender is an open source 3D creation suite. tion.com/ boost http://www.boost.org/ The free peer-reviewed portable C++ source libraries bowtie http://bowtie- A tool for aligning sequencing reads to bio.sourceforge.net/bo long reference sequences wtie2/index.shtml bwa http://bio- The Burrows-Wheeler Alignment tool is bwa.sourceforge.net/ a tool for aligning sequencing against a large reference genome campari2 http://campari.sourcef Campari v2 orge.net/ cblas350 http://www.netlib.org/ CBLAS is BLAS implementation in C blas/#_cblas charm++661 http://charmplusplus. -

Computadoras Electronicas
COMPUTADORAS ELECTRONICAS Prólogo En la unidad 0 se hace una introducción, definiendo algunos conceptos previos. En la unidad 1 se muestran las diversas tecnologías en las que se fueron construyendo las computadoras. Luego se hace una breve revisión de los principios de circuitos digitales secuenciales y combinacionales, para comprender luego el Hardware principal de la computadora, como ser la Unidad Lógico Aritmética y la Unidad De Memoria. También se exponen las principales tecnologías de semiconductor con las que son construidas las computadoras actuales. Y se hace una descripción funcional de todas y cada una de las partes elementales de la computadora. Finalmente se describen los dos tipos básicos de arquitectura de computadoras ejemplificando cada uno. En la unidad 2 se hace un repaso de sistemas posicionales de numeración haciendo especial énfasis en el hexadecimal y binario. Además se desarrollan los diferentes códigos binarios con los que la maquina almacena y procesa la diversa información digital. En la unidad 3 se hace una integración de las unidades anteriores en la programación de un microcontrolador específico. Haciendo uso de un entorno de desarrollo integrado para tal fin. Utilizando el lenguaje Ensamblador ya que al ser de bajo nivel se puede tener una compresión mas profunda de lo que ocurre a nivel Hardware y poder relacionarlo con el Software. En la unidad 4 finalmente se expone el lenguaje C, luego de haber pasado por el Ensamblador se busca un mayor nivel de abstracción para poder resolver problemas de mayor complejidad. Este material se realizó con fines didácticos y se encuentra en proceso de desarrollo. -

ATLAS Installation Guide ∗
ATLAS Installation Guide ∗ R. Clint Whaley y July 10, 2014 Abstract This note provides a brief overview of ATLAS, and describes how to install it. It includes extensive discussion of common configure options, and describes why they might be employed on various platforms. In addition to discussing how to configure and build the ATLAS package, this note also describes how an installer can confirm that the resulting libraries are producing correct answers and running efficiently. Extensive examples are provided, including a full-length example showing the installation of both ATLAS and LAPACK on an example architecture. ∗This work was supported in part by National Science Foundation CRI grant SNS-0551504 [email protected], www.cs.utsa.edu/∼whaley CONTENTS CONTENTS Contents 1 Introduction 1 2 Overview of an ATLAS Installation 2 2.1 Downloading the software and checking for known errors . 2 2.2 Turn off CPU throttling when installing ATLAS . 2 2.3 Basic Steps of an ATLAS install . 3 3 The ATLAS configure step 4 3.1 Building a full LAPACK library using ATLAS and netlib's LAPACK . 4 3.1.1 LAPACK APIs . 5 3.1.2 Obtaining netlib's LAPACK . 5 3.2 Changing the compilers and flags that ATLAS uses for the build . 5 3.2.1 Changing ATLAS interface compilers to match your usage . 6 3.2.2 Rough guide to overriding ATLAS's compiler choice/changing flags . 7 3.2.3 Forcing ATLAS to use a particular gcc . 7 3.2.4 Installing ATLAS when you don't have access to a FORTRAN compiler . -

ATLAS Installation Guide ∗
ATLAS Installation Guide ∗ R. Clint Whaley y July 27, 2016 Abstract This note provides a brief overview of ATLAS, and describes how to install it. It includes extensive discussion of common configure options, and describes why they might be employed on various platforms. In addition to discussing how to configure and build the ATLAS package, this note also describes how an installer can confirm that the resulting libraries are producing correct answers and running efficiently. Extensive examples are provided, including a full-length example showing the installation of both ATLAS and LAPACK on an example architecture. ∗This work was supported in part by National Science Foundation CRI grant SNS-0551504 [email protected], www.cs.utsa.edu/∼whaley CONTENTS CONTENTS Contents 1 Introduction 1 2 Overview of an ATLAS Installation 2 2.1 Downloading the software and checking for known errors . 2 2.2 Turn off CPU throttling when installing ATLAS . 2 2.3 Basic Steps of an ATLAS install . 3 3 The ATLAS configure step 4 3.1 Building a full LAPACK library using ATLAS and netlib's LAPACK . 5 3.1.1 LAPACK APIs . 5 3.1.2 Obtaining netlib's LAPACK . 5 3.2 Changing the compilers and flags that ATLAS uses for the build . 5 3.2.1 Changing ATLAS interface compilers to match your usage . 7 3.2.2 Rough guide to overriding ATLAS's compiler choice/changing flags . 7 3.2.3 Forcing ATLAS to use a particular gcc . 8 3.2.4 Installing ATLAS when you don't have access to a FORTRAN compiler . -

Wiki: Opensourceroadshow
Open Source Roadshow with AOL - Case Study: Mozilla Project Open Source Roadshow with AOL - Case Study: Mozilla Project What is open source software? Why pay for software when it is free? How can teaching and research be aided by open source software? What is the technology surrounding Netscape? What innovative applications have been built, through community involvement, upon Mozilla, the code at the heart of Netscape, the first Web browser? What are the security challenges and strategies relating to open source development? Students, faculty, staff, and visitors are invited to attend any or all of a day-long program on these topics to be held October 24, 2002, from 8 a.m. -5 p.m. in the Donaldson Brown Hotel and Conference Center, followed by an evening meeting of the ACM Student Chapter. The Roadshow is being hosted by the Internet Technology Innovation Center at Virginia Tech in cooperation with AOL and Virginia's Center for Innovative Technology. Join in the discussion and enjoy the demonstrations and refreshments! Sessions will be led a team coming from Netscape and Mozilla, with support from AOL. Mitchell Baker is the general troubleshooter, spokesperson, and policy arbitrator for mozilla.org. Scott Collins has been a participant and contributor on the mozilla project since its inception. Mitch Stoltz is the lead security engineer for the Netscape client team. Sessions will run all day on the 24th. Many are of general interest, but some will be oriented toward those with a focus on technology. Pick and choose to suit your background and schedule. For more information contact Ed Fox (x1-5113, [email protected]).