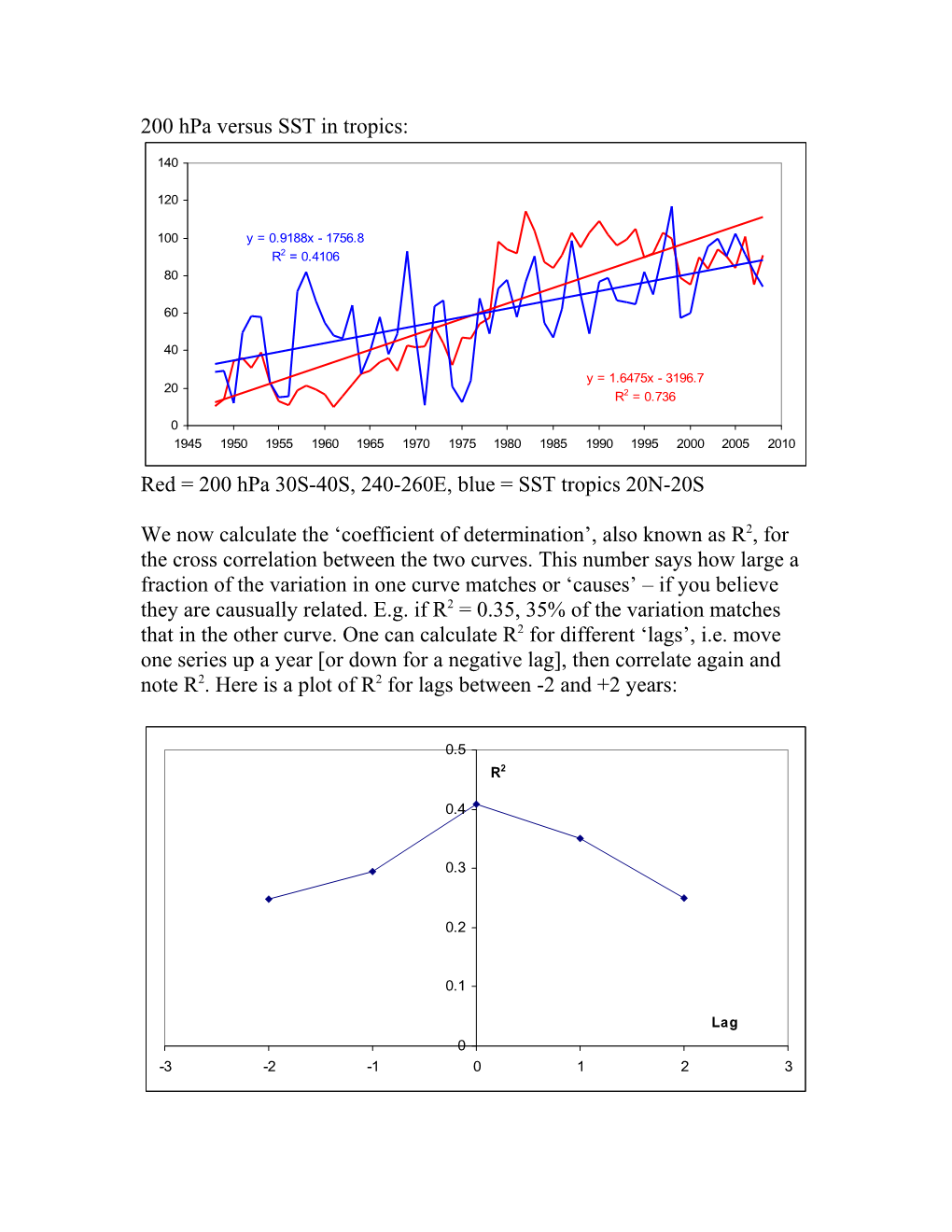
200 hPa versus SST in tropics:
140
120
100 y = 0.9188x - 1756.8 R2 = 0.4106 80
60
40
y = 1.6475x - 3196.7 20 R2 = 0.736
0 1945 1950 1955 1960 1965 1970 1975 1980 1985 1990 1995 2000 2005 2010
Red = 200 hPa 30S-40S, 240-260E, blue = SST tropics 20N-20S
We now calculate the ‘coefficient of determination’, also known as R2, for the cross correlation between the two curves. This number says how large a fraction of the variation in one curve matches or ‘causes’ – if you believe they are causually related. E.g. if R2 = 0.35, 35% of the variation matches that in the other curve. One can calculate R2 for different ‘lags’, i.e. move one series up a year [or down for a negative lag], then correlate again and note R2. Here is a plot of R2 for lags between -2 and +2 years:
0.5 R2
0.4
0.3
0.2
0.1
Lag 0 -3 -2 -1 0 1 2 3 The largest R2 occurs for lag = 0, but the coefficient is large for several lags. There is not much difference. The reason for this is obvious: There is a large ‘auto-correlation’ present: and both curves show an upwards trend, so the analysis so far just says that there is a similar upwards trend in both curves. Moving one curve over a year does not change the trend much. It is clear that the trend must first be removed if we want to compare the fine details.
Removing the trend, the curves look like this:
70 100
60 80 50
40 60 30
20 40
10 20 0 1945 1950 1955 1960 1965 1970 1975 1980 1985 1990 1995 2000 2005 2010 -10 0 -20
-30 -20
And the plot of R2 as a function of lag looks like this:
0.06 R2
0.05
0.04
0.03
0.02
0.01
Lag 0 -3 -2 -1 0 1 2 3 Thus about 5% of the variation of one curve matches that of the other curve at lag zero years.
If we plot both set of coefficients as function of lag, we have:
0.5
0.4
0.3
0.2
0.1
0 -2.5 -2 -1.5 -1 -0.5 0 0.5 1 1.5 2 2.5
Just showing at a glance the effect of the high autocorrelation. The conclusion is that 95% of the variations are unrelated, and the 5% that match do that at zero lag.
Now, people are often very creative in ‘massaging’ the data. One standard trick is to plot the difference between successive values. This accentuates the variation:
40 80
30 60
20 40 10 20 0 1945 1950 1955 1960 1965 1970 1975 1980 1985 1990 1995 2000 2005 20100 -10 -20 -20 -40 -30
-40 -60
-50 -80 And indeed, the coefficient of determination more than triples:
0.18
0.16
0.14
0.12
0.1
0.08
0.06
0.04
0.02
0 -3 -2 -1 0 1 2 3
But still with the best match at zero lag. At this point it becomes clear to an old hand as I in data ‘massaging’ that further and more desperate measures will not alter the conclusion.
How good is this method? To answer that we take one of the time series and construct the other one by copying the data shifted one year plus adding some random noise:
160
140
120 y = 1.6475x - 3196.7 2 100 R = 0.736
80
60 y = 1.6613x - 3224.7 40 R2 = 0.6567 20
0 1940 1950 1960 1970 1980 1990 2000 2010 2020 Here it is clear there is a relationship with a lag of 1 year.
We now go through the same procedure as above, and plot the resulting R2s on one plot:
1
Raw simuated data 0.9 0.8 0.7
0.6 With Trends Removed 0.5
0.4
0.3 0.2
Difference curves 0.1
0 -2.5 -2 -1.5 -1 -0.5 0 0.5 1 1.5 2 2.5
You can clearly see the peak at lag one year.
Extensive trials with more and more random noise added confirm that if there is a signal, this method will find it.