On the Dimensionality of Deformable Face Models
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Automatic 2.5D Cartoon Modelling
Automatic 2.5D Cartoon Modelling Fengqi An School of Computer Science and Engineering University of New South Wales A dissertation submitted for the degree of Master of Science 2012 PLEASE TYPE THE UNIVERSITY OF NEW SOUTH WALES T hesis!Dissertation Sheet Surname or Family name. AN First namEY. Fengqi Orner namels: Zane Abbreviatlo(1 for degree as given in the University calendar: MSc School: Computer Science & Engineering Faculty: Engineering Title; Automatic 2.50 Cartoon Modelling Abstract 350 words maximum: (PLEASE TYPE) Declarat ion relating to disposition of project thesis/dissertation I hereby grant to the University of New South Wales or its agents the right to archive and to make available my thesis or dissertation in whole orin part in the University libraries in all forms of media, now or here after known, subject to the provisions of the Copyright Act 1968. I retain all property rights, such as patent rights. I also retain the right to use in future works (such as articles or books) all or part of thts thesis or dissertation. I also authorise University Microfilms to use the 350 word abstract of my thesis in Dissertation· Abstracts International (this is applicable to-doctoral theses only) .. ... .............. ~..... ............... 24 I 09 I 2012 Signature · · ·· ·· ·· ···· · ··· ·· ~ ··· · ·· ··· ···· Date The University recognises that there may be exceptional circumstances requiring restrictions on copying or conditions on use. Requests for restriction for a period of up to 2 years must be made in writi'ng. Requests for -

Introduction Week 1, Lecture 1
CS 430 Computer Graphics Introduction Week 1, Lecture 1 David Breen, William Regli and Maxim Peysakhov Department of Computer Science Drexel University 1 Overview • Course Policies/Issues • Brief History of Computer Graphics • The Field of Computer Graphics: A view from 66,000ft • Structure of this course • Homework overview • Introduction and discussion of homework #1 2 Computer Graphics I: Course Goals • Provide introduction to fundamentals of 2D and 3D computer graphics – Representation (lines/curves/surfaces) – Drawing, clipping, transformations and viewing – Implementation of a basic graphics system • draw lines using Postscript • simple frame buffer with PBM & PPM format • ties together 3D projection and 2D drawing 3 Interactive Computer Graphics CS 432 • Learn and program WebGL • Computer Graphics was a pre-requisite – Not anymore • Looks at graphics “one level up” from CS 430 • Useful for Games classes • Part of the HCI and Game Development & Design tracks? 5 Advanced Rendering Techniques (Advanced Computer Graphics) • Might be offered in the Spring term • 3D Computer Graphics • CS 430/536 is a pre-requisite • Implement Ray Tracing algorithm • Lighting, rendering, photorealism • Study Radiosity and Photon Mapping 7 ART Student Images 8 Computer Graphics I: Technical Material • Course coverage – Mathematical preliminaries – 2D lines and curves – Geometric transformations – Line and polygon drawing – 3D viewing, 3D curves and surfaces – Splines, B-Splines and NURBS – Solid Modeling – Color, hidden surface removal, Z-buffering 9 -

CS 4204 Computer Graphics 3D Views and Projection
CS 4204 Computer Graphics 3D views and projection Adapted from notes by Yong Cao 1 Overview of 3D rendering Modeling: * Topic we’ve already discussed • *Define object in local coordinates • *Place object in world coordinates (modeling transformation) Viewing: • Define camera parameters • Find object location in camera coordinates (viewing transformation) Projection: project object to the viewplane Clipping: clip object to the view volume *Viewport transformation *Rasterization: rasterize object Simple teapot demo 3D rendering pipeline Vertices as input Series of operations/transformations to obtain 2D vertices in screen coordinates These can then be rasterized 3D rendering pipeline We’ve already discussed: • Viewport transformation • 3D modeling transformations We’ll talk about remaining topics in reverse order: • 3D clipping (simple extension of 2D clipping) • 3D projection • 3D viewing Clipping: 3D Cohen-Sutherland Use 6-bit outcodes When needed, clip line segment against planes Viewing and Projection Camera Analogy: 1. Set up your tripod and point the camera at the scene (viewing transformation). 2. Arrange the scene to be photographed into the desired composition (modeling transformation). 3. Choose a camera lens or adjust the zoom (projection transformation). 4. Determine how large you want the final photograph to be - for example, you might want it enlarged (viewport transformation). Projection transformations Introduction to Projection Transformations Mapping: f : Rn Rm Projection: n > m Planar Projection: Projection on a plane. -

3D Object Detection from a Single RGB Image Via Perspective Points
PerspectiveNet: 3D Object Detection from a Single RGB Image via Perspective Points Siyuan Huang Yixin Chen Tao Yuan Department of Statistics Department of Statistics Department of Statistics [email protected] [email protected] [email protected] Siyuan Qi Yixin Zhu Song-Chun Zhu Department of Computer Science Department of Statistics Department of Statistics [email protected] [email protected] [email protected] Abstract Detecting 3D objects from a single RGB image is intrinsically ambiguous, thus re- quiring appropriate prior knowledge and intermediate representations as constraints to reduce the uncertainties and improve the consistencies between the 2D image plane and the 3D world coordinate. To address this challenge, we propose to adopt perspective points as a new intermediate representation for 3D object detection, defined as the 2D projections of local Manhattan 3D keypoints to locate an object; these perspective points satisfy geometric constraints imposed by the perspective projection. We further devise PerspectiveNet, an end-to-end trainable model that simultaneously detects the 2D bounding box, 2D perspective points, and 3D object bounding box for each object from a single RGB image. PerspectiveNet yields three unique advantages: (i) 3D object bounding boxes are estimated based on perspective points, bridging the gap between 2D and 3D bounding boxes without the need of category-specific 3D shape priors. (ii) It predicts the perspective points by a template-based method, and a perspective loss is formulated to maintain the perspective constraints. (iii) It maintains the consistency between the 2D per- spective points and 3D bounding boxes via a differentiable projective function. Experiments on SUN RGB-D dataset show that the proposed method significantly outperforms existing RGB-based approaches for 3D object detection. -

DLA-RS4810 3D Enabled D-ILA Media Room Projector
DLA-RS4810 3D Enabled D-ILA Media Room Projector An ideal media room 4K Precision 3D enabled D-ILA projector featuring 4K e-shift 2 technology with a native contrast ratio of 50,000:1 • 1080p Three Chip 3D Enabled D-ILA Projector • Upgraded lens memory function memorizes 5 positions of focus, zoom and shift enabling recall of a variety of • High definition e-shift2 4K Precision (3840 X 2160) aspect ratio configurations Projected Image • Control: LAN / RS-232C / IR / 12 V Screen Trigger • 50,000:1 Native Contrast Ratio Output / New remote control with 3D functions • Multiple Pixel Control with JVC's 8 Band Detection • New 230 Watt NSH Illumination System (improves lamp — 2K to 4K Upscaling Engine life to 4,000 hours in Normal Mode) • Highly customizable built-in 2D to 3D converter • Available exclusively through AVAD custom installers creates dynamic 3D images from 2D video content Certified Performance QC and 3 year parts & labor warranty • 1.4 to 2.8:1 motorized zoom lens with Horizontal and Vertical offset Note: Optional 3D Glasses (PK-AG3 or PK-AG2) and 3D Synchro Emitter (PK-EM2 or PK-EM1) are required for viewing images in 3D. JVC e-shift 2 Projection 4K Precision D-ILA 3D Projection* JVC’s totally revamped optical engine incorporating There's nothing like 3D to immerse you into the scene and the DLA-RS4810 uses the three D-ILA imaging devices and new 4K e-shift 2 frame sequential method which provides separate left-eye and right-eye images technology provides improved contrast and natural through synchronized active shutter glasses. -

View-Dependent 3D Projection Using Depth-Image-Based Head Tracking
View-dependent 3D Projection using Depth-Image-based Head Tracking Jens Garstka Gabriele Peters University of Hagen University of Hagen Chair of Human-Computer-Interaction Chair of Human-Computer-Interaction Universitatsstr.¨ 1, 58097 Hagen, Germany Universitatsstr.¨ 1, 58097 Hagen, Germany [email protected] [email protected] Abstract is also referred to as the signature. Subsequently for each depth image a signature is created and compared against The idea of augmenting our physical reality with virtual the signatures in the database. For the most likely matches entities in an unobtrusive, embedded way, i. e., without the a correlation metric is calculated between these and the im- necessity of wearing hardware or using expensive display age to find the best match. devices is exciting. Due to the development of new inexpen- Late in 2006, Nintendo released a game console with a sive depth camera systems an implementation of this idea new controller called the Wii Remote. This wireless con- became affordable for everyone. This paper demonstrates troller is used as a pointing device and detects movements an approach to capture and track a head using a depth cam- with its three axis accelerometers. Due to the low cost of era. From its position in space we will calculate a view- this controller and the possibility to be connected via Blue- dependent 3D projection of a scene which can be projected tooth, numerous alternative applications, such as those pro- on walls, on tables, or on any other type of flat surface. Our posed by Lee [4], Schlomer¨ et al. -

Anamorphic Projection: Analogical/Digital Algorithms
Nexus Netw J (2015) 17:253–285 DOI 10.1007/s00004-014-0225-5 RESEARCH Anamorphic Projection: Analogical/Digital Algorithms Francesco Di Paola • Pietro Pedone • Laura Inzerillo • Cettina Santagati Published online: 27 November 2014 Ó Kim Williams Books, Turin 2014 Abstract The study presents the first results of a wider research project dealing with the theme of ‘‘anamorphosis’’, a specific technique of geometric projection of a shape on a surface. Here we investigate how new digital techniques make it possible to simplify the anamorphic applications even in cases of projections on complex surfaces. After a short excursus of the most famous historical and contemporary applications, we propose several possible approaches for managing the geometry of anamorphic curves both in the field of descriptive geometry (by using interactive tools such as Cabrı` and GeoGebra) and during the complex surfaces realization process, from concept design to manufacture, through CNC systems (by adopting generative procedural algorithms elaborated in Grasshopper). Keywords Anamorphosis Anamorphic technique Descriptive geometry Architectural geometry Generative algorithms Free form surfaces F. Di Paola (&) Á L. Inzerillo Department of Architecture (Darch), University of Palermo, Viale delle Scienze, Edificio 8-scala F4, 90128 Palermo, Italy e-mail: [email protected] L. Inzerillo e-mail: [email protected] F. Di Paola Á L. Inzerillo Á C. Santagati Department of Communication, Interactive Graphics and Augmented Reality, IEMEST, Istituto Euro Mediterraneo di Scienza e Tecnologia, 90139 Palermo, Italy P. Pedone Polytechnic of Milan, Bulding-Architectural Engineering, EDA, 23900 Lecco, Italy e-mail: [email protected] C. Santagati Department of Architecture, University of Catania, 95125 Catania, Italy e-mail: [email protected] 254 F. -

Projection Mapping Technologies for AR
Projection Mapping Technologies for AR Daisuke iwai Osaka University, Machikaneyamacho 1-3, Toyonaka, Osaka 5608531, Japan Keywords: Projection mapping, augmented reality, computational display ABSTRACT collaborative works, and machine manipulations. This talk also introduces such systems that were proposed by This invited talk will present recent projection mapping our group. Figure 1 shows the representative images of technologies for augmented reality. First, fundamental researches introduced in this talk. technologies are briefly explained, which have been proposed to overcome the technical limitations of ordinary projectors. Second, augmented reality (AR) applications 2. FUNDAMENTAL TECHNOLOGIES using projection mapping technologies are introduced. We developed fundamental technologies to 1. INTRODUCTION overcome the technical limitations of current projection Projection mapping is one of the fundamental displays and to achieve robust user manipulation approaches to realize augmented reality (AR) systems. measurement under dynamic projection illuminations to Compared to other approaches such as video/optical realize flexible and robust interactive systems. see-through AR, it can provide AR experiences without We use cameras, ranging from normal RGB cameras restricting users by head-mounted/use-worn/hand-held to near and far infrared (IR) cameras, to measure user devices. In addition, the users can directly see the manipulation as well as scene geometry and reflectance augmentations with natural field-of-view. On the other properties. For the user measurement, we apply IR hand, there are several technical issues to be solved to cameras to robustly detect user's touch actions even display geometrically and photometrically correct images under projection-based dynamic illumination. In onto non-planar and textured surfaces. This invited talk particular, we propose two touch detection techniques; introduces various techniques that our group proposed so one measures finger nail color change by touch action far. -

Structured Video and the Construction of Space
In Proceedings of IS&T/SPIE’s Symposium on Electronic Imaging, February, 1995. Structured Video and the Construction of Space Judith S. Donath November 1994 Abstract Image sequences can now be synthesized by compositing elements - objects, backgrounds, people - from pre-existing source images. What are the rules that govern the placement of these elements in their new frames? If geometric projection is assumed to govern the composition, there is some freedom to move the elements about, but the range of placements is quite limited. Furthermore, projective geometry is not perceptually ideal – think of the distortions seen at the edges of wide angle photographs. These distortions are not found in perspective paintings: painters modify the portrayal of certain objects to make them perceptually correct. This paper first reviews projective geometry in the context of image compositing and then introduces perceptually based composition. Its basis in human vision is analyzed and its application to image compositing discussed. 1 Structured Video and Space In traditional video the frame is indivisible and the sequence – a recording of events occurring in a single place and time – is the basic editing unit. In structured video, events in a frame are no longer limited to simultaneous, collocated actions. The basic units in structured video are 2 or 3D image components, rather than the rectangular frames used in traditional video. New image sequences can be made by compositing actors and objects taken from a variety of source images onto a new background. Sequences can be synthesized that depict real, but previously unfilmable events: a discussion among several distant people, or the comings and goings of the members of an electronic community. -
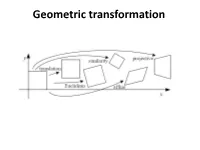
Geometric Transformation
Geometric transformation References • http://szeliski.org/Book/ • http://www.cs.cornell.edu/courses/cs5670/2019sp/lectu res/lectures.html • http://www.cs.cmu.edu/~16385/ contents • 2D->2D transformations • 3D->3D transformations • 3D->2D transformations (3D projections) – Perspective projection – Orthographic projection Objective • Being able to do all of the below transformations with matrix manipulation: translation rotation scale shear affine projective • Why matrix manipulation? Objective • Being able to do all of the below transformations with matrix manipulation: translation rotation scale shear affine projective • Why matrix manipulation? Because then we can easily concatenate transformations (for example translation and then rotation). 2D planar transformations scale • How? Scale scale Scale scale matrix representation of scaling: scaling matrix S Scale Shear • How? Shear Shear or in matrix form: Shear Rotation • How? rotation 푟 around the origin 푟 φ Rotation Polar coordinates… x = r cos (φ) y = r sin (φ) x’ = r cos (φ + θ) y’ = r sin (φ + θ) Trigonometric Identity… x’ = r cos(φ) cos(θ) – r sin(φ) sin(θ) rotation y’ = r sin(φ) cos(θ) + r cos(φ) sin(θ) 푟 around the origin Substitute… x’ = x cos(θ) - y sin(θ) 푟 y’ = x sin(θ) + y cos(θ) φ Rotation or in matrix form: rotation around the origin Important rotation matrix features • det 푅 = 1 – If det 푅 = −1 then this is a roto-reflection matrix • 푅푇 = 푅−1 ՞ 푅푅푇 = 푅푇푅 = 퐼 ՞ orthogonal matrix ՞ a square matrix whose columns and rows are orthogonal unit vectors. Concatenation • How do we do concatenation of two or more transformations? Concatenation • How do we do concatenation of two or more transformations? • Easy with matrix multiplication! Translation • How? Translation ′ 푥 = 푥 + 푡푥 ′ 푦 = 푦 + 푡푦 What about matrix representation? Translation ′ 푥 = 푥 + 푡푥 ′ 푦 = 푦 + 푡푦 What about matrix representation? Not possible. -

Better Pixels in Professional Projectors
Better Pixels in Professional Projectors White Paper Better Pixels in Professional Projectors January, 2016 By Chris Chinnock Insight Media 3 Morgan Ave., Norwalk, CT 06851 USA 203-831-8464 www.insightmedia.info In collaboration with Insight Media www.insightmedia.info 3 Morgan Ave. 1 Copyright 2016 Norwalk, CT 06851 USA All rights reserved Better Pixels in Professional Projectors Table of Contents Introduction ................................................................................................................4 What are Better Pixels? ..............................................................................................4 Consumer TV vs. Professional Projection .................................................................................. 4 Higher Brightness ....................................................................................................................... 5 Benefits & Trade-offs .......................................................................................................................................... 5 Uniformity .................................................................................................................................. 6 Benefits & Trade-offs .......................................................................................................................................... 6 Enhanced Resolution .................................................................................................................. 6 Benefits & Trade-offs ......................................................................................................................................... -

20179 Short Throw 3D Projector Brochure EN V3.Indd
ULTRA-SHORT THROW 1-CHIP DLPTM PROJECTORS ULTRA-SHORT THROW PT-CW230 3D PROJECTORS PT-CX200 PT-CW230 SERIES TM SUPPORTING VARIOUS 3D SYSTEMS NVIDIA™ 3D VISION™ DLPTM LINK™ You can build the 3D system by using the configuration shown below. Enjoy vivid 3D As synchronized signals are contained in 3D images that you view, you can build the worlds such as powerful high-definition games, digital photos, 3D Blu-ray Discs, 3D system without connecting the emitter. streaming movies and videos. Configuration: 3D Contents + 3D Reproduction apparatus + 3D Glasses (DLPTM LinkTM system) IR system + + + 3D SYNC OUT terminal (of PT-CW230/CX200) and the IR emitter are connected to build INNOVATIVE ULTRA-SHORT THROW 3D READY PROJECTORS the 3D system. Microsoft® Windows Compatible NVIDIATM NVIDIATM 3D VisionTM kit PT-CW230/CX200 Vista®-/ Windows® 7- graphic card Configuration: 3D Contents + 3D Reproduction apparatus + 3D Glasses (IR system) + IR Emitter WITH NEW APPLICATIONS based computer New ultra-short throw projectors can project images onto a large VIEWING 3D IMAGES 80-inch screen with a short projection distance of 0.32 m. These View 3D images at a distance at least three times further than the height of the screen. Each person views and feels the 3D images differently. In some cases, the effects may cause viewers to feel sick. If you see double 3D images or do not see stereoscopic images, you may feel fatigue or discomfort If you feel sick, immediately stop viewing 3D images. Children under the age projectors can be installed either horizontally or vertically to meet of six should not view 3D images.