Julia: a Fresh Approach to Numerical Computing
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Metaobject Protocols: Why We Want Them and What Else They Can Do
Metaobject protocols: Why we want them and what else they can do Gregor Kiczales, J.Michael Ashley, Luis Rodriguez, Amin Vahdat, and Daniel G. Bobrow Published in A. Paepcke, editor, Object-Oriented Programming: The CLOS Perspective, pages 101 ¾ 118. The MIT Press, Cambridge, MA, 1993. © Massachusetts Institute of Technology All rights reserved. No part of this book may be reproduced in any form by any electronic or mechanical means (including photocopying, recording, or information storage and retrieval) without permission in writing from the publisher. Metaob ject Proto cols WhyWeWant Them and What Else They Can Do App ears in Object OrientedProgramming: The CLOS Perspective c Copyright 1993 MIT Press Gregor Kiczales, J. Michael Ashley, Luis Ro driguez, Amin Vahdat and Daniel G. Bobrow Original ly conceivedasaneat idea that could help solve problems in the design and implementation of CLOS, the metaobject protocol framework now appears to have applicability to a wide range of problems that come up in high-level languages. This chapter sketches this wider potential, by drawing an analogy to ordinary language design, by presenting some early design principles, and by presenting an overview of three new metaobject protcols we have designed that, respectively, control the semantics of Scheme, the compilation of Scheme, and the static paral lelization of Scheme programs. Intro duction The CLOS Metaob ject Proto col MOP was motivated by the tension b etween, what at the time, seemed liketwo con icting desires. The rst was to have a relatively small but p owerful language for doing ob ject-oriented programming in Lisp. The second was to satisfy what seemed to b e a large numb er of user demands, including: compatibility with previous languages, p erformance compara- ble to or b etter than previous implementations and extensibility to allow further exp erimentation with ob ject-oriented concepts see Chapter 2 for examples of directions in which ob ject-oriented techniques might b e pushed. -

Python – an Introduction
Python { AN IntroduCtion . default parameters . self documenting code Example for extensions: Gnuplot Hans Fangohr, [email protected], CED Seminar 05/02/2004 ² The wc program in Python ² Summary Overview ² Outlook ² Why Python ² Literature: How to get started ² Interactive Python (IPython) ² M. Lutz & D. Ascher: Learning Python Installing extra modules ² ² ISBN: 1565924649 (1999) (new edition 2004, ISBN: Lists ² 0596002815). We point to this book (1999) where For-loops appropriate: Chapter 1 in LP ² ! if-then ² modules and name spaces Alex Martelli: Python in a Nutshell ² ² while ISBN: 0596001886 ² string handling ² ¯le-input, output Deitel & Deitel et al: Python { How to Program ² ² functions ISBN: 0130923613 ² Numerical computation ² some other features Other resources: ² . long numbers www.python.org provides extensive . exceptions ² documentation, tools and download. dictionaries Python { an introduction 1 Python { an introduction 2 Why Python? How to get started: The interpreter and how to run code Chapter 1, p3 in LP Chapter 1, p12 in LP ! Two options: ! All sorts of reasons ;-) interactive session ² ² . Object-oriented scripting language . start Python interpreter (python.exe, python, . power of high-level language double click on icon, . ) . portable, powerful, free . prompt appears (>>>) . mixable (glue together with C/C++, Fortran, . can enter commands (as on MATLAB prompt) . ) . easy to use (save time developing code) execute program ² . easy to learn . Either start interpreter and pass program name . (in-built complex numbers) as argument: python.exe myfirstprogram.py Today: . ² Or make python-program executable . easy to learn (Unix/Linux): . some interesting features of the language ./myfirstprogram.py . use as tool for small sysadmin/data . Note: python-programs tend to end with .py, processing/collecting tasks but this is not necessary. -

MANNING Greenwich (74° W
Object Oriented Perl Object Oriented Perl DAMIAN CONWAY MANNING Greenwich (74° w. long.) For electronic browsing and ordering of this and other Manning books, visit http://www.manning.com. The publisher offers discounts on this book when ordered in quantity. For more information, please contact: Special Sales Department Manning Publications Co. 32 Lafayette Place Fax: (203) 661-9018 Greenwich, CT 06830 email: [email protected] ©2000 by Manning Publications Co. All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted, in any form or by means electronic, mechanical, photocopying, or otherwise, without prior written permission of the publisher. Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in the book, and Manning Publications was aware of a trademark claim, the designations have been printed in initial caps or all caps. Recognizing the importance of preserving what has been written, it is Manning’s policy to have the books we publish printed on acid-free paper, and we exert our best efforts to that end. Library of Congress Cataloging-in-Publication Data Conway, Damian, 1964- Object oriented Perl / Damian Conway. p. cm. includes bibliographical references. ISBN 1-884777-79-1 (alk. paper) 1. Object-oriented programming (Computer science) 2. Perl (Computer program language) I. Title. QA76.64.C639 1999 005.13'3--dc21 99-27793 CIP Manning Publications Co. Copyeditor: Adrianne Harun 32 Lafayette -
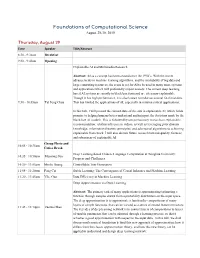
Foundations of Computational Science August 29-30, 2019
Foundations of Computational Science August 29-30, 2019 Thursday, August 29 Time Speaker Title/Abstract 8:30 - 9:30am Breakfast 9:30 - 9:40am Opening Explainable AI and Multimedia Research Abstract: AI as a concept has been around since the 1950’s. With the recent advancements in machine learning algorithms, and the availability of big data and large computing resources, the scene is set for AI to be used in many more systems and applications which will profoundly impact society. The current deep learning based AI systems are mostly in black box form and are often non-explainable. Though it has high performance, it is also known to make occasional fatal mistakes. 9:30 - 10:05am Tat Seng Chua This has limited the applications of AI, especially in mission critical applications. In this talk, I will present the current state-of-the arts in explainable AI, which holds promise to helping humans better understand and interpret the decisions made by the black-box AI models. This is followed by our preliminary research on explainable recommendation, relation inference in videos, as well as leveraging prior domain knowledge, information theoretic principles, and adversarial algorithms to achieving explainable framework. I will also discuss future research towards quality, fairness and robustness of explainable AI. Group Photo and 10:05 - 10:35am Coffee Break Deep Learning-based Chinese Language Computation at Tsinghua University: 10:35 - 10:50am Maosong Sun Progress and Challenges 10:50 - 11:05am Minlie Huang Controllable Text Generation 11:05 - 11:20am Peng Cui Stable Learning: The Convergence of Causal Inference and Machine Learning 11:20 - 11:45am Yike Guo Data Efficiency in Machine Learning Deep Approximation via Deep Learning Abstract: The primary task of many applications is approximating/estimating a function through samples drawn from a probability distribution on the input space. -

R from a Programmer's Perspective Accompanying Manual for an R Course Held by M
DSMZ R programming course R from a programmer's perspective Accompanying manual for an R course held by M. Göker at the DSMZ, 11/05/2012 & 25/05/2012. Slightly improved version, 10/09/2012. This document is distributed under the CC BY 3.0 license. See http://creativecommons.org/licenses/by/3.0 for details. Introduction The purpose of this course is to cover aspects of R programming that are either unlikely to be covered elsewhere or likely to be surprising for programmers who have worked with other languages. The course thus tries not be comprehensive but sort of complementary to other sources of information. Also, the material needed to by compiled in short time and perhaps suffers from important omissions. For the same reason, potential participants should not expect a fully fleshed out presentation but a combination of a text-only document (this one) with example code comprising the solutions of the exercises. The topics covered include R's general features as a programming language, a recapitulation of R's type system, advanced coding of functions, error handling, the use of attributes in R, object-oriented programming in the S3 system, and constructing R packages (in this order). The expected audience comprises R users whose own code largely consists of self-written functions, as well as programmers who are fluent in other languages and have some experience with R. Interactive users of R without programming experience elsewhere are unlikely to benefit from this course because quite a few programming skills cannot be covered here but have to be presupposed. -

Computational Science and Engineering
Computational Science and Engineering, PhD College of Engineering Graduate Coordinator: TBA Email: Phone: Department Chair: Marwan Bikdash Email: [email protected] Phone: 336-334-7437 The PhD in Computational Science and Engineering (CSE) is an interdisciplinary graduate program designed for students who seek to use advanced computational methods to solve large problems in diverse fields ranging from the basic sciences (physics, chemistry, mathematics, etc.) to sociology, biology, engineering, and economics. The mission of Computational Science and Engineering is to graduate professionals who (a) have expertise in developing novel computational methodologies and products, and/or (b) have extended their expertise in specific disciplines (in science, technology, engineering, and socioeconomics) with computational tools. The Ph.D. program is designed for students with graduate and undergraduate degrees in a variety of fields including engineering, chemistry, physics, mathematics, computer science, and economics who will be trained to develop problem-solving methodologies and computational tools for solving challenging problems. Research in Computational Science and Engineering includes: computational system theory, big data and computational statistics, high-performance computing and scientific visualization, multi-scale and multi-physics modeling, computational solid, fluid and nonlinear dynamics, computational geometry, fast and scalable algorithms, computational civil engineering, bioinformatics and computational biology, and computational physics. Additional Admission Requirements Master of Science or Engineering degree in Computational Science and Engineering (CSE) or in science, engineering, business, economics, technology or in a field allied to computational science or computational engineering field. GRE scores Program Outcomes: Students will demonstrate critical thinking and ability in conducting research in engineering, science and mathematics through computational modeling and simulations. -

Towards Practical Runtime Type Instantiation
Towards Practical Runtime Type Instantiation Karl Naden Carnegie Mellon University [email protected] Abstract 2. Dispatch Problem Statement Symmetric multiple dispatch, generic functions, and variant type In contrast with traditional dynamic dispatch, the runtime of a lan- parameters are powerful language features that have been shown guage with multiple dispatch cannot necessarily use any static in- to aid in modular and extensible library design. However, when formation about the call site provided by the typechecker. It must symmetric dispatch is applied to generic functions, type parameters check if there exists a more specific function declaration than the may have to be instantiated as a part of dispatch. Adding variant one statically chosen that has the same name and is applicable to generics increases the complexity of type instantiation, potentially the runtime types of the provided arguments. The process for deter- making it prohibitively expensive. We present a syntactic restriction mining when a function declaration is more specific than another is on generic functions and an algorithm designed and implemented for laid out in [4]. A fully instantiated function declaration is applicable the Fortress programming language that simplifies the computation if the runtime types of the arguments are subtypes of the declared required at runtime when these features are combined. parameter types. To show applicability for a generic function we need to find an instantiation that witnesses the applicability and the type safety of the function call so that it can be used by the code. Formally, given 1. Introduction 1. a function signature f X <: τX (y : τy): τr, J K Symmetric multiple dispatch brings with it several benefits for 2. -

Parallel Functional Programming with APL
Parallel Functional Programming, APL Lecture 1 Parallel Functional Programming with APL Martin Elsman Department of Computer Science University of Copenhagen DIKU December 19, 2016 Martin Elsman (DIKU) Parallel Functional Programming, APL Lecture 1 December 19, 2016 1 / 18 Outline 1 Outline Course Outline 2 Introduction to APL What is APL APL Implementations and Material APL Scalar Operations APL (1-Dimensional) Vector Computations Declaring APL Functions (dfns) APL Multi-Dimensional Arrays Iterations Declaring APL Operators Function Trains Examples Reading Martin Elsman (DIKU) Parallel Functional Programming, APL Lecture 1 December 19, 2016 2 / 18 Outline Course Outline Teachers Martin Elsman (ME), Ken Friis Larsen (KFL), Andrzej Filinski (AF), and Troels Henriksen (TH) Location Lectures in Small Aud, Universitetsparken 1 (UP1); Labs in Old Library, UP1 Course Description See http://kurser.ku.dk/course/ndak14009u/2016-2017 Course Outline Week 47 48 49 50 51 1–3 Mon 13–15 Intro, Futhark Parallel SNESL APL (ME) Project Futhark (ME) Haskell (AF) (ME) (KFL) Mon 15–17 Lab Lab Lab Lab Project Wed 13–15 Futhark Parallel SNESL Invited APL Project (ME) Haskell (AF) Lecture (ME) / (KFL) (John Projects Reppy) Martin Elsman (DIKU) Parallel Functional Programming, APL Lecture 1 December 19, 2016 3 / 18 Introduction to APL What is APL APL—An Ancient Array Programming Language—But Still Used! Pioneered by Ken E. Iverson in the 1960’s. E. Dijkstra: “APL is a mistake, carried through to perfection.” There are quite a few APL programmers around (e.g., HIPERFIT partners). Very concise notation for expressing array operations. Has a large set of functional, essentially parallel, multi- dimensional, second-order array combinators. -

Artificial Intelligence Research For
Charles Xie ([email protected]) is a senior scientist who works at the inter- section between computational science and learning science. Artificial Intelligence research for engineering design By Charles Xie Imagine a high school classroom in 2030. AI is one of the three most promising areas for which Bill Gates Students are challenged to design an said earlier this year he would drop out of college again if he were a young student today. The victory of Google’s AlphaGo against engineering system that meets the needs of a top human Go player in 2016 was a landmark in the history of their community. They work with advanced AI. The game of Go is considered a difficult challenge because computer-aided design (CAD) software that the number of legal positions on a 19×19 grid is estimated to be leverages the power of scientific simulation, 2×10170, far more than the total number of atoms in the observ- mixed reality, and cloud computing. Every able universe combined (1082). While AlphaGo may be only a cool tool needed to complete an engineering type of weak AI that plays Go at present, scientists believe that its development will engender technologies that eventually find design project is seamlessly integrated into applications in other fields. the CAD platform to streamline the learning process. But the most striking capability of Performance modeling the software is its ability to act like a mentor (e.g., simulation-based analysis) who has all the knowledge about the design project to answer questions, learns from all the successful or unsuccessful solutions ever Evaluator attempted by human designers or computer agents, adapts to the needs of each student based on experience interacting with all sorts of designers, inspires students to explore creative ideas, and, most importantly, remains User Ideator responsive all the time without ever running out of steam. -

Introduction to Ggplot2
Introduction to ggplot2 Dawn Koffman Office of Population Research Princeton University January 2014 1 Part 1: Concepts and Terminology 2 R Package: ggplot2 Used to produce statistical graphics, author = Hadley Wickham "attempt to take the good things about base and lattice graphics and improve on them with a strong, underlying model " based on The Grammar of Graphics by Leland Wilkinson, 2005 "... describes the meaning of what we do when we construct statistical graphics ... More than a taxonomy ... Computational system based on the underlying mathematics of representing statistical functions of data." - does not limit developer to a set of pre-specified graphics adds some concepts to grammar which allow it to work well with R 3 qplot() ggplot2 provides two ways to produce plot objects: qplot() # quick plot – not covered in this workshop uses some concepts of The Grammar of Graphics, but doesn’t provide full capability and designed to be very similar to plot() and simple to use may make it easy to produce basic graphs but may delay understanding philosophy of ggplot2 ggplot() # grammar of graphics plot – focus of this workshop provides fuller implementation of The Grammar of Graphics may have steeper learning curve but allows much more flexibility when building graphs 4 Grammar Defines Components of Graphics data: in ggplot2, data must be stored as an R data frame coordinate system: describes 2-D space that data is projected onto - for example, Cartesian coordinates, polar coordinates, map projections, ... geoms: describe type of geometric objects that represent data - for example, points, lines, polygons, ... aesthetics: describe visual characteristics that represent data - for example, position, size, color, shape, transparency, fill scales: for each aesthetic, describe how visual characteristic is converted to display values - for example, log scales, color scales, size scales, shape scales, .. -

Introduction to GNU Octave
Introduction to GNU Octave Hubert Selhofer, revised by Marcel Oliver updated to current Octave version by Thomas L. Scofield 2008/08/16 line 1 1 0.8 0.6 0.4 0.2 0 -0.2 -0.4 8 6 4 2 -8 -6 0 -4 -2 -2 0 -4 2 4 -6 6 8 -8 Contents 1 Basics 2 1.1 What is Octave? ........................... 2 1.2 Help! . 2 1.3 Input conventions . 3 1.4 Variables and standard operations . 3 2 Vector and matrix operations 4 2.1 Vectors . 4 2.2 Matrices . 4 1 2.3 Basic matrix arithmetic . 5 2.4 Element-wise operations . 5 2.5 Indexing and slicing . 6 2.6 Solving linear systems of equations . 7 2.7 Inverses, decompositions, eigenvalues . 7 2.8 Testing for zero elements . 8 3 Control structures 8 3.1 Functions . 8 3.2 Global variables . 9 3.3 Loops . 9 3.4 Branching . 9 3.5 Functions of functions . 10 3.6 Efficiency considerations . 10 3.7 Input and output . 11 4 Graphics 11 4.1 2D graphics . 11 4.2 3D graphics: . 12 4.3 Commands for 2D and 3D graphics . 13 5 Exercises 13 5.1 Linear algebra . 13 5.2 Timing . 14 5.3 Stability functions of BDF-integrators . 14 5.4 3D plot . 15 5.5 Hilbert matrix . 15 5.6 Least square fit of a straight line . 16 5.7 Trapezoidal rule . 16 1 Basics 1.1 What is Octave? Octave is an interactive programming language specifically suited for vectoriz- able numerical calculations. -

Programming Language
Programming language A programming language is a formal language, which comprises a set of instructions that produce various kinds of output. Programming languages are used in computer programming to implement algorithms. Most programming languages consist of instructions for computers. There are programmable machines that use a set of specific instructions, rather than general programming languages. Early ones preceded the invention of the digital computer, the first probably being the automatic flute player described in the 9th century by the brothers Musa in Baghdad, during the Islamic Golden Age.[1] Since the early 1800s, programs have been used to direct the behavior of machines such as Jacquard looms, music boxes and player pianos.[2] The programs for these The source code for a simple computer program written in theC machines (such as a player piano's scrolls) did not programming language. When compiled and run, it will give the output "Hello, world!". produce different behavior in response to different inputs or conditions. Thousands of different programming languages have been created, and more are being created every year. Many programming languages are written in an imperative form (i.e., as a sequence of operations to perform) while other languages use the declarative form (i.e. the desired result is specified, not how to achieve it). The description of a programming language is usually split into the two components ofsyntax (form) and semantics (meaning). Some languages are defined by a specification document (for example, theC programming language is specified by an ISO Standard) while other languages (such as Perl) have a dominant implementation that is treated as a reference.