An Evaluation of Tensorflow As a Programming Framework for HPC Applications
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Foundations of Computational Science August 29-30, 2019
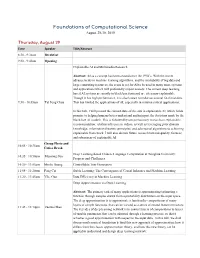
Foundations of Computational Science August 29-30, 2019 Thursday, August 29 Time Speaker Title/Abstract 8:30 - 9:30am Breakfast 9:30 - 9:40am Opening Explainable AI and Multimedia Research Abstract: AI as a concept has been around since the 1950’s. With the recent advancements in machine learning algorithms, and the availability of big data and large computing resources, the scene is set for AI to be used in many more systems and applications which will profoundly impact society. The current deep learning based AI systems are mostly in black box form and are often non-explainable. Though it has high performance, it is also known to make occasional fatal mistakes. 9:30 - 10:05am Tat Seng Chua This has limited the applications of AI, especially in mission critical applications. In this talk, I will present the current state-of-the arts in explainable AI, which holds promise to helping humans better understand and interpret the decisions made by the black-box AI models. This is followed by our preliminary research on explainable recommendation, relation inference in videos, as well as leveraging prior domain knowledge, information theoretic principles, and adversarial algorithms to achieving explainable framework. I will also discuss future research towards quality, fairness and robustness of explainable AI. Group Photo and 10:05 - 10:35am Coffee Break Deep Learning-based Chinese Language Computation at Tsinghua University: 10:35 - 10:50am Maosong Sun Progress and Challenges 10:50 - 11:05am Minlie Huang Controllable Text Generation 11:05 - 11:20am Peng Cui Stable Learning: The Convergence of Causal Inference and Machine Learning 11:20 - 11:45am Yike Guo Data Efficiency in Machine Learning Deep Approximation via Deep Learning Abstract: The primary task of many applications is approximating/estimating a function through samples drawn from a probability distribution on the input space. -

Computational Science and Engineering
Computational Science and Engineering, PhD College of Engineering Graduate Coordinator: TBA Email: Phone: Department Chair: Marwan Bikdash Email: [email protected] Phone: 336-334-7437 The PhD in Computational Science and Engineering (CSE) is an interdisciplinary graduate program designed for students who seek to use advanced computational methods to solve large problems in diverse fields ranging from the basic sciences (physics, chemistry, mathematics, etc.) to sociology, biology, engineering, and economics. The mission of Computational Science and Engineering is to graduate professionals who (a) have expertise in developing novel computational methodologies and products, and/or (b) have extended their expertise in specific disciplines (in science, technology, engineering, and socioeconomics) with computational tools. The Ph.D. program is designed for students with graduate and undergraduate degrees in a variety of fields including engineering, chemistry, physics, mathematics, computer science, and economics who will be trained to develop problem-solving methodologies and computational tools for solving challenging problems. Research in Computational Science and Engineering includes: computational system theory, big data and computational statistics, high-performance computing and scientific visualization, multi-scale and multi-physics modeling, computational solid, fluid and nonlinear dynamics, computational geometry, fast and scalable algorithms, computational civil engineering, bioinformatics and computational biology, and computational physics. Additional Admission Requirements Master of Science or Engineering degree in Computational Science and Engineering (CSE) or in science, engineering, business, economics, technology or in a field allied to computational science or computational engineering field. GRE scores Program Outcomes: Students will demonstrate critical thinking and ability in conducting research in engineering, science and mathematics through computational modeling and simulations. -

Artificial Intelligence Research For
Charles Xie ([email protected]) is a senior scientist who works at the inter- section between computational science and learning science. Artificial Intelligence research for engineering design By Charles Xie Imagine a high school classroom in 2030. AI is one of the three most promising areas for which Bill Gates Students are challenged to design an said earlier this year he would drop out of college again if he were a young student today. The victory of Google’s AlphaGo against engineering system that meets the needs of a top human Go player in 2016 was a landmark in the history of their community. They work with advanced AI. The game of Go is considered a difficult challenge because computer-aided design (CAD) software that the number of legal positions on a 19×19 grid is estimated to be leverages the power of scientific simulation, 2×10170, far more than the total number of atoms in the observ- mixed reality, and cloud computing. Every able universe combined (1082). While AlphaGo may be only a cool tool needed to complete an engineering type of weak AI that plays Go at present, scientists believe that its development will engender technologies that eventually find design project is seamlessly integrated into applications in other fields. the CAD platform to streamline the learning process. But the most striking capability of Performance modeling the software is its ability to act like a mentor (e.g., simulation-based analysis) who has all the knowledge about the design project to answer questions, learns from all the successful or unsuccessful solutions ever Evaluator attempted by human designers or computer agents, adapts to the needs of each student based on experience interacting with all sorts of designers, inspires students to explore creative ideas, and, most importantly, remains User Ideator responsive all the time without ever running out of steam. -

Advanced Model Deployments with Tensorflow Serving Presentation.Pdf
Most models don’t get deployed. Hi, I’m Hannes. An inefficient model deployment import json from flask import Flask from keras.models import load_model from utils import preprocess model = load_model('model.h5') app = Flask(__name__) @app.route('/classify', methods=['POST']) def classify(): review = request.form["review"] preprocessed_review = preprocess(review) prediction = model.predict_classes([preprocessed_review])[0] return json.dumps({"score": int(prediction)}) Simple Deployments @app.route('/classify', methods=['POST']) Why Flask is insufficient def classify(): review = request.form["review"] ● No consistent APIs ● No consistent payloads preprocessed_review = preprocess(review) ● No model versioning prediction = model.predict_classes( ● No mini-batching support [preprocessed_review])[0] ● Inefficient for large models return json.dumps({"score": int(prediction)}) Image: Martijn Baudoin, Unsplash TensorFlow Serving TensorFlow Serving Production ready Model Serving ● Part of the TensorFlow Extended Ecosystem ● Used internally at Google ● Highly scalable model serving solution ● Works well for large models up to 2GB TensorFlow 2.0 ready! * * With small exceptions Deploy your models in 90s ... Export your Model import tensorflow as tf TensorFlow 2.0 Export tf.saved_model.save( ● Consistent model export model, ● Using Protobuf format export_dir="/tmp/saved_model", ● Export of graphs and signatures=None estimators possible ) $ tree saved_models/ Export your Model saved_models/ └── 1555875926 ● Exported model as Protobuf ├── assets (Saved_model.pb) -

A Brief Introduction to Mathematical Optimization in Julia (Part 1) What Is Julia? and Why Should I Care?
A Brief Introduction to Mathematical Optimization in Julia (Part 1) What is Julia? And why should I care? Carleton Coffrin Advanced Network Science Initiative https://lanl-ansi.github.io/ Managed by Triad National Security, LLC for the U.S. Department of Energy’s NNSA LA-UR-21-20278 Warning: This is not a technical talk! 9/25/2019 Julia_prog_language.svg What is Julia? • A “new” programming language developed at MIT • nearly 10 years old (appeared around 2012) • Julia is a high-level, high-performance, dynamic programming language • free and open source • The Creator’s Motivation • build the next-generation of programming language for numerical analysis and computational science • Solve the “two-language problem” (you havefile:///Users/carleton/Downloads/Julia_prog_language.svg to choose between 1/1 performance and implementation simplicity) Who is using Julia? Julia is much more than an academic curiosity! See https://juliacomputing.com/ Why Julia? Application9/25/2019 Julia_prog_language.svg Needs Data Scince Numerical Scripting Computing Automation 9/25/2019 Thin-Border-Logo-Text Julia Data Differential Equations file:///Users/carleton/Downloads/Julia_prog_language.svg 1/1 Deep Learning Mathematical Optimization High Performance https://camo.githubusercontent.com/31d60f762b44d0c3ea47cc16b785e042104a6e03/68747470733a2f2f7777772e6a756c69616f70742e6f72672f696d616765732f6a7… 1/1 -

From Computational Science to Science Discovery
FromComputationalSciencetoScienceDiscovery:The NextComputingLandscape GiladShainer,BrianSparks,ScotSchultz,EricLantz,WilliamLiu,TongLiu,GoldiMisra HPCAdvisoryCouncil {Gilad,Brian,Scot,Eric,William,Tong,[email protected]} Computationalscienceisthefieldofstudyconcernedwithconstructingmathematicalmodelsand numericaltechniquesthatrepresentscientific,socialscientificorengineeringproblemsandemploying thesemodelsoncomputers,orclustersofcomputerstoanalyze,exploreorsolvethesemodels. Numericalsimulationenablesthestudyofcomplexphenomenathatwouldbetooexpensiveor dangeroustostudybydirectexperimentation.Thequestforeverhigherlevelsofdetailandrealismin suchsimulationsrequiresenormouscomputationalcapacity,andhasprovidedtheimpetusfor breakthroughsincomputeralgorithmsandarchitectures.Duetotheseadvances,computational scientistsandengineerscannowsolvelargeͲscaleproblemsthatwereoncethoughtintractableby creatingtherelatedmodelsandsimulatethemviahighͲperformancecomputeclustersor supercomputers.Simulationisbeingusedasanintegralpartofthemanufacturing,designanddecisionͲ makingprocesses,andasafundamentaltoolforscientificresearch.ProblemswherehighͲperformance simulationplayapivotalroleincludeforexampleweatherandclimateprediction,nuclearandenergy research,simulationanddesignofvehiclesandaircrafts,electronicdesignautomation,astrophysics, quantummechanics,biology,computationalchemistryandmore. Computationalscienceiscommonlyconsideredthethirdmodeofscience,wherethepreviousmodesor paradigmswereexperimentation/observationandtheory.Inthepast,sciencewasperformedby -

From XML to Flat Buffers: Markup in the Twenty-Teens Warning! the Contenders
Elliotte Rusty Harold [email protected] August 2018 From XML to Flat Buffers: Markup in the Twenty-teens Warning! The Contenders ● XML ● JSON ● YAML ● EXI ● Protobufs ● Flat Protobufs XML JSON YAML EXI Protobuf Flat Buffers App Engine X X Standard Java App Engine X Flex What Uses What Kubernetes X X From technology, tools, and systems Eclipse X I use frequently. There are many others. Maven X Ant X Google X X X X X “APIs” Publishing X XML XML ● Very well defined standard ● By far the most general format: ○ Mixed content ○ Attributes and elements ● By far the best tool support. Nothing else is close: ○ XSLT ○ XPath ○ Many schema languages: ■ W3C XSD ■ RELAX NG More Reasons to Choose XML ● Most composable for mixing and matching markup; e.g. MathML+SVG in HTML ● Does not require a schema. ● Streaming support: very large documents ● Better for interchange amongst unrelated parties ● The deeper your needs the more likely you’ll end up here. Why Not XML? ● Relatively complex for simple tasks ● Limited to no support for non-string programming types: ○ Numbers, booleans, dates, money, etc. ○ Lists, maps, sets ○ You can encode all these but APIs don’t necessarily recognize or support them. ● Lots of sharp edges to surprise the non-expert: ○ 9/10 are namespace related ○ Attribute value normalization ○ White space ● Some security issues if you’re not careful (Billion laughs) JSON ● Simple for object serialization and program data. If your data is a few basic types (int, string, boolean, float) and data structures (list, map) this works well. ● More or less standard (7-8 of them in fact) ● Consumption libraries for essentially all significant languages Why Not JSON? ● It is surprising how fast needs grow past a few basic types and data structures. -

Trifacta Data Preparation for Amazon Redshift and S3 Must Be Deployed Into an Existing Virtual Private Cloud (VPC)
Install Guide for Data Preparation for Amazon Redshift and S3 Version: 7.1 Doc Build Date: 05/26/2020 Copyright © Trifacta Inc. 2020 - All Rights Reserved. CONFIDENTIAL These materials (the “Documentation”) are the confidential and proprietary information of Trifacta Inc. and may not be reproduced, modified, or distributed without the prior written permission of Trifacta Inc. EXCEPT AS OTHERWISE PROVIDED IN AN EXPRESS WRITTEN AGREEMENT, TRIFACTA INC. PROVIDES THIS DOCUMENTATION AS-IS AND WITHOUT WARRANTY AND TRIFACTA INC. DISCLAIMS ALL EXPRESS AND IMPLIED WARRANTIES TO THE EXTENT PERMITTED, INCLUDING WITHOUT LIMITATION THE IMPLIED WARRANTIES OF MERCHANTABILITY, NON-INFRINGEMENT AND FITNESS FOR A PARTICULAR PURPOSE AND UNDER NO CIRCUMSTANCES WILL TRIFACTA INC. BE LIABLE FOR ANY AMOUNT GREATER THAN ONE HUNDRED DOLLARS ($100) BASED ON ANY USE OF THE DOCUMENTATION. For third-party license information, please select About Trifacta from the Help menu. 1. Quick Start . 4 1.1 Install from AWS Marketplace . 4 1.2 Upgrade for AWS Marketplace . 7 2. Configure . 8 2.1 Configure for AWS . 8 2.1.1 Configure for EC2 Role-Based Authentication . 14 2.1.2 Enable S3 Access . 16 2.1.2.1 Create Redshift Connections 28 3. Contact Support . 30 4. Legal 31 4.1 Third-Party License Information . 31 Page #3 Quick Start Install from AWS Marketplace Contents: Product Limitations Internet access Install Desktop Requirements Pre-requisites Install Steps - CloudFormation template SSH Access Troubleshooting SELinux Upgrade Documentation Related Topics This guide steps through the requirements and process for installing Trifacta® Data Preparation for Amazon Redshift and S3 through the AWS Marketplace. -

Julia: a Fresh Approach to Numerical Computing∗
SIAM REVIEW c 2017 Society for Industrial and Applied Mathematics Vol. 59, No. 1, pp. 65–98 Julia: A Fresh Approach to Numerical Computing∗ Jeff Bezansony Alan Edelmanz Stefan Karpinskix Viral B. Shahy Abstract. Bridging cultures that have often been distant, Julia combines expertise from the diverse fields of computer science and computational science to create a new approach to numerical computing. Julia is designed to be easy and fast and questions notions generally held to be \laws of nature" by practitioners of numerical computing: 1. High-level dynamic programs have to be slow. 2. One must prototype in one language and then rewrite in another language for speed or deployment. 3. There are parts of a system appropriate for the programmer, and other parts that are best left untouched as they have been built by the experts. We introduce the Julia programming language and its design|a dance between special- ization and abstraction. Specialization allows for custom treatment. Multiple dispatch, a technique from computer science, picks the right algorithm for the right circumstance. Abstraction, which is what good computation is really about, recognizes what remains the same after differences are stripped away. Abstractions in mathematics are captured as code through another technique from computer science, generic programming. Julia shows that one can achieve machine performance without sacrificing human con- venience. Key words. Julia, numerical, scientific computing, parallel AMS subject classifications. 68N15, 65Y05, 97P40 DOI. 10.1137/141000671 Contents 1 Scientific Computing Languages: The Julia Innovation 66 1.1 Julia Architecture and Language Design Philosophy . 67 ∗Received by the editors December 18, 2014; accepted for publication (in revised form) December 16, 2015; published electronically February 7, 2017. -

COMPUTATIONAL SCIENCE 2017-2018 College of Engineering and Computer Science BACHELOR of SCIENCE Computer Science
COMPUTATIONAL SCIENCE 2017-2018 College of Engineering and Computer Science BACHELOR OF SCIENCE Computer Science *The Computational Science program offers students the opportunity to acquire a knowledge in computing integrated with knowledge in one of the following areas of study: (a) bioinformatics, (b) computational physics, (c) computational chemistry, (d) computational mathematics, (e) environmental science informatics, (f) health informatics, (g) digital forensics and cyber security, (h) business informatics, (i) biomedical informatics, (j) computational engineering physics, and (k) computational engineering technology. Graduates of this program major in computational science with a concentration in one of the above areas of study. (Amended for clarification 12/5/2018). *Previous UTRGV language: Computational science graduates develop emphasis in two major fields, one in computer science and one in another field, in order to integrate an interdisciplinary computing degree applied to a number of emerging areas of study such as biomedical-informatics, digital forensics, computational chemistry, and computational physics, to mention a few examples. Graduates of this program are prepared to enter the workforce or to continue a graduate studies either in computer science or in the second major. A – GENERAL EDUCATION CORE – 42 HOURS Students must fulfill the General Education Core requirements. The courses listed below satisfy both degree requirements and General Education core requirements. Required 020 - Mathematics – 3 hours For all -

Cloud Native Communication Patterns with Grpc
Cloud Native Communication Patterns with gRPC Kasun Indrasiri Author “gRPC Up and Running” and “Microservices for Enterprise” About Me ● Author “gRPC Up & Running”, “Microservices for Enterprise” ● Product Manager/Senior Director at WSO2. ● Committer and PMC member at Apache Software Foundation. ● Founder “Bay area Microservices, APIs and Integration” meetup group. What is gRPC? ● Modern Inter-process communication technology. ● Invoking remote functions as easy as making a local function invocation. ● Contract-first. ● Binary messaging on the wire on top of HTTP2 ● Polyglot. Fundamentals of gRPC - Service Definition syntax = "proto3"; ● Defines the business capabilities of package ecommerce; your service. service ProductInfo { rpc addProduct(Product) returns (ProductID); ● Protocol Buffers used as the IDL for rpc getProduct(ProductID) returns (Product); define services. } message Product { ● Protocol Buffers : string id = 1; ○ A language-agnostic, platform-neutral, string name = 2; extensible mechanism to serializing string description = 3; float price = 4; structured data. } ● Defines service, remote methods, and message ProductID { data types. string value = 1; } ProductInfo.proto Fundamentals of gRPC - gRPC Service // AddProduct implements ecommerce.AddProduct ● gRPC service implements the func (s *server) AddProduct(ctx context.Context, in *pb.Product) (*pb.ProductID, business logic. error) { ● Generate server side skeleton from // Business logic } service definition. // GetProduct implements ecommerce.GetProduct func (s *server) GetProduct(ctx -

Machine Learning for Synchronized Swimming
Machine Learning for Synchronised Swimming Siddhartha Verma, Guido Novati Petros Koumoutsakos FSIM 2017 May 25, 2017 CSElab Computational Science & Engineering Laboratory http://www.cse-lab.ethz.ch Motivation • Why do fish swim in groups? • Social behaviour? • Anti-predator benefits • Better foraging/reproductive opportunities • Better problem-solving capability • Propulsive advantage? Credit: Artbeats • Classical works on schooling: Breder (1965), Weihs (1973,1975), … • Based on simplified inviscid models (e.g., point vortices) • More recent simulations: consider pre-assigned and fixed formations Hemelrijk et al. (2015), Daghooghi & Borazjani (2015) • But: actual formations evolve dynamically Breder (1965) Weihs (1973), Shaw (1978) • Essential question: Possible to swim autonomously & energetically favourable? Hemelrijk et al. (2015) Vortices in the wake • Depending on Re and swimming- kinematics, double row of vortex rings in the wake • Our goal: exploit the flow generated by these vortices Numerical methods 0 in 2D • Remeshed vortex methods (2D) @! 2 + u ! = ! u + ⌫ ! + λ (χ (us u)) • Solve vorticity form of incompressible Navier-Stokes @t ·r ·r r r⇥ − Advection Diffusion Penalization • Brinkman penalization • Accounts for fluid-solid interaction Angot et al., Numerische Mathematik (1999) • 2D: Wavelet-based adaptive grid • Cost-effective compared to uniform grids Rossinelli et al., J. Comput. Phys. (2015) • 3D: Uniform grid Finite Volume solver Rossinelli et al., SC'13 Proc. Int. Conf. High Perf. Comput., Denver, Colorado Interacting swimmers