Mastering the Game of Go with Deep Neural Networks and Tree Search
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Backpropagation and Deep Learning in the Brain
Backpropagation and Deep Learning in the Brain Simons Institute -- Computational Theories of the Brain 2018 Timothy Lillicrap DeepMind, UCL With: Sergey Bartunov, Adam Santoro, Jordan Guerguiev, Blake Richards, Luke Marris, Daniel Cownden, Colin Akerman, Douglas Tweed, Geoffrey Hinton The “credit assignment” problem The solution in artificial networks: backprop Credit assignment by backprop works well in practice and shows up in virtually all of the state-of-the-art supervised, unsupervised, and reinforcement learning algorithms. Why Isn’t Backprop “Biologically Plausible”? Why Isn’t Backprop “Biologically Plausible”? Neuroscience Evidence for Backprop in the Brain? A spectrum of credit assignment algorithms: A spectrum of credit assignment algorithms: A spectrum of credit assignment algorithms: How to convince a neuroscientist that the cortex is learning via [something like] backprop - To convince a machine learning researcher, an appeal to variance in gradient estimates might be enough. - But this is rarely enough to convince a neuroscientist. - So what lines of argument help? How to convince a neuroscientist that the cortex is learning via [something like] backprop - What do I mean by “something like backprop”?: - That learning is achieved across multiple layers by sending information from neurons closer to the output back to “earlier” layers to help compute their synaptic updates. How to convince a neuroscientist that the cortex is learning via [something like] backprop 1. Feedback connections in cortex are ubiquitous and modify the -

Artificial Intelligence in Health Care: the Hope, the Hype, the Promise, the Peril
Artificial Intelligence in Health Care: The Hope, the Hype, the Promise, the Peril Michael Matheny, Sonoo Thadaney Israni, Mahnoor Ahmed, and Danielle Whicher, Editors WASHINGTON, DC NAM.EDU PREPUBLICATION COPY - Uncorrected Proofs NATIONAL ACADEMY OF MEDICINE • 500 Fifth Street, NW • WASHINGTON, DC 20001 NOTICE: This publication has undergone peer review according to procedures established by the National Academy of Medicine (NAM). Publication by the NAM worthy of public attention, but does not constitute endorsement of conclusions and recommendationssignifies that it is the by productthe NAM. of The a carefully views presented considered in processthis publication and is a contributionare those of individual contributors and do not represent formal consensus positions of the authors’ organizations; the NAM; or the National Academies of Sciences, Engineering, and Medicine. Library of Congress Cataloging-in-Publication Data to Come Copyright 2019 by the National Academy of Sciences. All rights reserved. Printed in the United States of America. Suggested citation: Matheny, M., S. Thadaney Israni, M. Ahmed, and D. Whicher, Editors. 2019. Artificial Intelligence in Health Care: The Hope, the Hype, the Promise, the Peril. NAM Special Publication. Washington, DC: National Academy of Medicine. PREPUBLICATION COPY - Uncorrected Proofs “Knowing is not enough; we must apply. Willing is not enough; we must do.” --GOETHE PREPUBLICATION COPY - Uncorrected Proofs ABOUT THE NATIONAL ACADEMY OF MEDICINE The National Academy of Medicine is one of three Academies constituting the Nation- al Academies of Sciences, Engineering, and Medicine (the National Academies). The Na- tional Academies provide independent, objective analysis and advice to the nation and conduct other activities to solve complex problems and inform public policy decisions. -

Monte-Carlo Tree Search Solver
Monte-Carlo Tree Search Solver Mark H.M. Winands1, Yngvi BjÄornsson2, and Jahn-Takeshi Saito1 1 Games and AI Group, MICC, Universiteit Maastricht, Maastricht, The Netherlands fm.winands,[email protected] 2 School of Computer Science, Reykjav¶³kUniversity, Reykjav¶³k,Iceland [email protected] Abstract. Recently, Monte-Carlo Tree Search (MCTS) has advanced the ¯eld of computer Go substantially. In this article we investigate the application of MCTS for the game Lines of Action (LOA). A new MCTS variant, called MCTS-Solver, has been designed to play narrow tacti- cal lines better in sudden-death games such as LOA. The variant di®ers from the traditional MCTS in respect to backpropagation and selection strategy. It is able to prove the game-theoretical value of a position given su±cient time. Experiments show that a Monte-Carlo LOA program us- ing MCTS-Solver defeats a program using MCTS by a winning score of 65%. Moreover, MCTS-Solver performs much better than a program using MCTS against several di®erent versions of the world-class ®¯ pro- gram MIA. Thus, MCTS-Solver constitutes genuine progress in using simulation-based search approaches in sudden-death games, signi¯cantly improving upon MCTS-based programs. 1 Introduction For decades ®¯ search has been the standard approach used by programs for playing two-person zero-sum games such as chess and checkers (and many oth- ers). Over the years many search enhancements have been proposed for this framework. However, in some games where it is di±cult to construct an accurate positional evaluation function (e.g., Go) the ®¯ approach was hardly success- ful. -

AI Computer Wraps up 4-1 Victory Against Human Champion Nature Reports from Alphago's Victory in Seoul
The Go Files: AI computer wraps up 4-1 victory against human champion Nature reports from AlphaGo's victory in Seoul. Tanguy Chouard 15 March 2016 SEOUL, SOUTH KOREA Google DeepMind Lee Sedol, who has lost 4-1 to AlphaGo. Tanguy Chouard, an editor with Nature, saw Google-DeepMind’s AI system AlphaGo defeat a human professional for the first time last year at the ancient board game Go. This week, he is watching top professional Lee Sedol take on AlphaGo, in Seoul, for a $1 million prize. It’s all over at the Four Seasons Hotel in Seoul, where this morning AlphaGo wrapped up a 4-1 victory over Lee Sedol — incidentally, earning itself and its creators an honorary '9-dan professional' degree from the Korean Baduk Association. After winning the first three games, Google-DeepMind's computer looked impregnable. But the last two games may have revealed some weaknesses in its makeup. Game four totally changed the Go world’s view on AlphaGo’s dominance because it made it clear that the computer can 'bug' — or at least play very poor moves when on the losing side. It was obvious that Lee felt under much less pressure than in game three. And he adopted a different style, one based on taking large amounts of territory early on rather than immediately going for ‘street fighting’ such as making threats to capture stones. This style – called ‘amashi’ – seems to have paid off, because on move 78, Lee produced a play that somehow slipped under AlphaGo’s radar. David Silver, a scientist at DeepMind who's been leading the development of AlphaGo, said the program estimated its probability as 1 in 10,000. -

Αβ-Based Play-Outs in Monte-Carlo Tree Search
αβ-based Play-outs in Monte-Carlo Tree Search Mark H.M. Winands Yngvi Bjornsson¨ Abstract— Monte-Carlo Tree Search (MCTS) is a recent [9]. In the context of game playing, Monte-Carlo simulations paradigm for game-tree search, which gradually builds a game- were first used as a mechanism for dynamically evaluating tree in a best-first fashion based on the results of randomized the merits of leaf nodes of a traditional αβ-based search [10], simulation play-outs. The performance of such an approach is highly dependent on both the total number of simulation play- [11], [12], but under the new paradigm MCTS has evolved outs and their quality. The two metrics are, however, typically into a full-fledged best-first search procedure that replaces inversely correlated — improving the quality of the play- traditional αβ-based search altogether. MCTS has in the past outs generally involves adding knowledge that requires extra couple of years substantially advanced the state-of-the-art computation, thus allowing fewer play-outs to be performed in several game domains where αβ-based search has had per time unit. The general practice in MCTS seems to be more towards using relatively knowledge-light play-out strategies for difficulties, in particular computer Go, but other domains the benefit of getting additional simulations done. include General Game Playing [13], Amazons [14] and Hex In this paper we show, for the game Lines of Action (LOA), [15]. that this is not necessarily the best strategy. The newest version The right tradeoff between search and knowledge equally of our simulation-based LOA program, MC-LOAαβ , uses a applies to MCTS. -

Automated Elastic Pipelining for Distributed Training of Transformers
PipeTransformer: Automated Elastic Pipelining for Distributed Training of Transformers Chaoyang He 1 Shen Li 2 Mahdi Soltanolkotabi 1 Salman Avestimehr 1 Abstract the-art convolutional networks ResNet-152 (He et al., 2016) and EfficientNet (Tan & Le, 2019). To tackle the growth in The size of Transformer models is growing at an model sizes, researchers have proposed various distributed unprecedented rate. It has taken less than one training techniques, including parameter servers (Li et al., year to reach trillion-level parameters since the 2014; Jiang et al., 2020; Kim et al., 2019), pipeline paral- release of GPT-3 (175B). Training such models lel (Huang et al., 2019; Park et al., 2020; Narayanan et al., requires both substantial engineering efforts and 2019), intra-layer parallel (Lepikhin et al., 2020; Shazeer enormous computing resources, which are luxu- et al., 2018; Shoeybi et al., 2019), and zero redundancy data ries most research teams cannot afford. In this parallel (Rajbhandari et al., 2019). paper, we propose PipeTransformer, which leverages automated elastic pipelining for effi- T0 (0% trained) T1 (35% trained) T2 (75% trained) T3 (100% trained) cient distributed training of Transformer models. In PipeTransformer, we design an adaptive on the fly freeze algorithm that can identify and freeze some layers gradually during training, and an elastic pipelining system that can dynamically Layer (end of training) Layer (end of training) Layer (end of training) Layer (end of training) Similarity score allocate resources to train the remaining active layers. More specifically, PipeTransformer automatically excludes frozen layers from the Figure 1. Interpretable Freeze Training: DNNs converge bottom pipeline, packs active layers into fewer GPUs, up (Results on CIFAR10 using ResNet). -

In-Datacenter Performance Analysis of a Tensor Processing Unit
In-Datacenter Performance Analysis of a Tensor Processing Unit Presented by Josh Fried Background: Machine Learning Neural Networks: ● Multi Layer Perceptrons ● Recurrent Neural Networks (mostly LSTMs) ● Convolutional Neural Networks Synapse - each edge, has a weight Neuron - each node, sums weights and uses non-linear activation function over sum Propagating inputs through a layer of the NN is a matrix multiplication followed by an activation Background: Machine Learning Two phases: ● Training (offline) ○ relaxed deadlines ○ large batches to amortize costs of loading weights from DRAM ○ well suited to GPUs ○ Usually uses floating points ● Inference (online) ○ strict deadlines: 7-10ms at Google for some workloads ■ limited possibility for batching because of deadlines ○ Facebook uses CPUs for inference (last class) ○ Can use lower precision integers (faster/smaller/more efficient) ML Workloads @ Google 90% of ML workload time at Google spent on MLPs and LSTMs, despite broader focus on CNNs RankBrain (search) Inception (image classification), Google Translate AlphaGo (and others) Background: Hardware Trends End of Moore’s Law & Dennard Scaling ● Moore - transistor density is doubling every two years ● Dennard - power stays proportional to chip area as transistors shrink Machine Learning causing a huge growth in demand for compute ● 2006: Excess CPU capacity in datacenters is enough ● 2013: Projected 3 minutes per-day per-user of speech recognition ○ will require doubling datacenter compute capacity! Google’s Answer: Custom ASIC Goal: Build a chip that improves cost-performance for NN inference What are the main costs? Capital Costs Operational Costs (power bill!) TPU (V1) Design Goals Short design-deployment cycle: ~15 months! Plugs in to PCIe slot on existing servers Accelerates matrix multiplication operations Uses 8-bit integer operations instead of floating point How does the TPU work? CISC instructions, issued by host. -

Artificial Intelligence and Big Data – Innovation Landscape Brief
ARTIFICIAL INTELLIGENCE AND BIG DATA INNOVATION LANDSCAPE BRIEF © IRENA 2019 Unless otherwise stated, material in this publication may be freely used, shared, copied, reproduced, printed and/or stored, provided that appropriate acknowledgement is given of IRENA as the source and copyright holder. Material in this publication that is attributed to third parties may be subject to separate terms of use and restrictions, and appropriate permissions from these third parties may need to be secured before any use of such material. ISBN 978-92-9260-143-0 Citation: IRENA (2019), Innovation landscape brief: Artificial intelligence and big data, International Renewable Energy Agency, Abu Dhabi. ACKNOWLEDGEMENTS This report was prepared by the Innovation team at IRENA’s Innovation and Technology Centre (IITC) with text authored by Sean Ratka, Arina Anisie, Francisco Boshell and Elena Ocenic. This report benefited from the input and review of experts: Marc Peters (IBM), Neil Hughes (EPRI), Stephen Marland (National Grid), Stephen Woodhouse (Pöyry), Luiz Barroso (PSR) and Dongxia Zhang (SGCC), along with Emanuele Taibi, Nadeem Goussous, Javier Sesma and Paul Komor (IRENA). Report available online: www.irena.org/publications For questions or to provide feedback: [email protected] DISCLAIMER This publication and the material herein are provided “as is”. All reasonable precautions have been taken by IRENA to verify the reliability of the material in this publication. However, neither IRENA nor any of its officials, agents, data or other third- party content providers provides a warranty of any kind, either expressed or implied, and they accept no responsibility or liability for any consequence of use of the publication or material herein. -
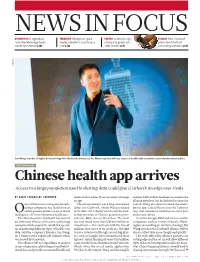
Chinese Health App Arrives Access to a Large Population Used to Sharing Data Could Give Icarbonx an Edge Over Rivals
NEWS IN FOCUS ASTROPHYSICS Legendary CHEMISTRY Deceptive spice POLITICS Scientists spy ECOLOGY New Zealand Arecibo telescope faces molecule offers cautionary chance to green UK plans to kill off all uncertain future p.143 tale p.144 after Brexit p.145 invasive predators p.148 ICARBONX Jun Wang, founder of digital biotechnology firm iCarbonX, showcases the Meum app that will use reams of health data to provide customized medical advice. BIOTECHNOLOGY Chinese health app arrives Access to a large population used to sharing data could give iCarbonX an edge over rivals. BY DAVID CYRANOSKI, SHENZHEN medical advice directly to consumers through another $400 million had been invested in the an app. alliance members, but he declined to name the ne of China’s most intriguing biotech- The announcement was a long-anticipated source. Wang also demonstrated the smart- nology companies has fleshed out an debut for iCarbonX, which Wang founded phone app, called Meum after the Latin for earlier quixotic promise to use artificial in October 2015 shortly after he left his lead- ‘my’, that customers would use to enter data Ointelligence (AI) to revolutionize health care. ership position at China’s genomics pow- and receive advice. The Shenzhen firm iCarbonX has formed erhouse, BGI, also in Shenzhen. The firm As well as Google, IBM and various smaller an ambitious alliance with seven technology has now raised more than US$600 million in companies, such as Arivale of Seattle, Wash- companies from around the world that special- investment — this contrasts with the tens of ington, are working on similar technology. But ize in gathering different types of health-care millions that most of its rivals are thought Wang says that the iCarbonX alliance will be data, said the company’s founder, Jun Wang, to have invested (although several big play- able to collect data more cheaply and quickly. -

CSC321 Lecture 23: Go
CSC321 Lecture 23: Go Roger Grosse Roger Grosse CSC321 Lecture 23: Go 1 / 22 Final Exam Monday, April 24, 7-10pm A-O: NR 25 P-Z: ZZ VLAD Covers all lectures, tutorials, homeworks, and programming assignments 1/3 from the first half, 2/3 from the second half If there's a question on this lecture, it will be easy Emphasis on concepts covered in multiple of the above Similar in format and difficulty to the midterm, but about 3x longer Practice exams will be posted Roger Grosse CSC321 Lecture 23: Go 2 / 22 Overview Most of the problem domains we've discussed so far were natural application areas for deep learning (e.g. vision, language) We know they can be done on a neural architecture (i.e. the human brain) The predictions are inherently ambiguous, so we need to find statistical structure Board games are a classic AI domain which relied heavily on sophisticated search techniques with a little bit of machine learning Full observations, deterministic environment | why would we need uncertainty? This lecture is about AlphaGo, DeepMind's Go playing system which took the world by storm in 2016 by defeating the human Go champion Lee Sedol Roger Grosse CSC321 Lecture 23: Go 3 / 22 Overview Some milestones in computer game playing: 1949 | Claude Shannon proposes the idea of game tree search, explaining how games could be solved algorithmically in principle 1951 | Alan Turing writes a chess program that he executes by hand 1956 | Arthur Samuel writes a program that plays checkers better than he does 1968 | An algorithm defeats human novices at Go 1992 -

Fml-Based Dynamic Assessment Agent for Human-Machine Cooperative System on Game of Go
Accepted for publication in International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems in July, 2017 FML-BASED DYNAMIC ASSESSMENT AGENT FOR HUMAN-MACHINE COOPERATIVE SYSTEM ON GAME OF GO CHANG-SHING LEE* MEI-HUI WANG, SHENG-CHI YANG Department of Computer Science and Information Engineering, National University of Tainan, Tainan, Taiwan *[email protected], [email protected], [email protected] PI-HSIA HUNG, SU-WEI LIN Department of Education, National University of Tainan, Tainan, Taiwan [email protected], [email protected] NAN SHUO, NAOYUKI KUBOTA Dept. of System Design, Tokyo Metropolitan University, Japan [email protected], [email protected] CHUN-HSUN CHOU, PING-CHIANG CHOU Haifong Weiqi Academy, Taiwan [email protected], [email protected] CHIA-HSIU KAO Department of Computer Science and Information Engineering, National University of Tainan, Tainan, Taiwan [email protected] Received (received date) Revised (revised date) Accepted (accepted date) In this paper, we demonstrate the application of Fuzzy Markup Language (FML) to construct an FML- based Dynamic Assessment Agent (FDAA), and we present an FML-based Human–Machine Cooperative System (FHMCS) for the game of Go. The proposed FDAA comprises an intelligent decision-making and learning mechanism, an intelligent game bot, a proximal development agent, and an intelligent agent. The intelligent game bot is based on the open-source code of Facebook’s Darkforest, and it features a representational state transfer application programming interface mechanism. The proximal development agent contains a dynamic assessment mechanism, a GoSocket mechanism, and an FML engine with a fuzzy knowledge base and rule base. -

Residual Networks for Computer Go Tristan Cazenave
Residual Networks for Computer Go Tristan Cazenave To cite this version: Tristan Cazenave. Residual Networks for Computer Go. IEEE Transactions on Games, Institute of Electrical and Electronics Engineers, 2018, 10 (1), 10.1109/TCIAIG.2017.2681042. hal-02098330 HAL Id: hal-02098330 https://hal.archives-ouvertes.fr/hal-02098330 Submitted on 12 Apr 2019 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. IEEE TCIAIG 1 Residual Networks for Computer Go Tristan Cazenave Universite´ Paris-Dauphine, PSL Research University, CNRS, LAMSADE, 75016 PARIS, FRANCE Deep Learning for the game of Go recently had a tremendous success with the victory of AlphaGo against Lee Sedol in March 2016. We propose to use residual networks so as to improve the training of a policy network for computer Go. Training is faster than with usual convolutional networks and residual networks achieve high accuracy on our test set and a 4 dan level. Index Terms—Deep Learning, Computer Go, Residual Networks. I. INTRODUCTION Input EEP Learning for the game of Go with convolutional D neural networks has been addressed by Clark and Storkey [1]. It has been further improved by using larger networks [2].