Data Compression Does Not Take Into Account the Type of Data Which Is Being Compressed and Is Lossless
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Optimizing and Protecting Hard Drives ‐ Chapter # 9
Optimizing and Protecting Hard Drives ‐ Chapter # 9 Amy Hissom Key Terms antivirus (AV) software — Utility programs that prevent infection or scan a system to detect and remove viruses. McAfee Associates’ VirusScan and Norton AntiVirus are two popular AV packages. backup — An extra copy of a file, used in the event that the original becomes damaged or destroyed. boot sector virus — An infectious program that can replace the boot program with a modified, infected version of the boot command utilities, often causing boot and data retrieval problems. buffer — A temporary memory area where data is kept before being written to a hard drive or sent to a printer, thus reducing the number of writes to the devices. chain — A group of clusters used to hold a single file. child, parent, grandparent backup method — A plan for backing up and reusing tapes or removable disks by rotating them each day (child), week (parent), and month (grandparent). cross-linked clusters — Errors caused when more than one file points to a cluster, and the files appear to share the same disk space, according to the file allocation table. defragment — To “optimize” or rewrite a file to a disk in one contiguous chain of clusters, thus speeding up data retrieval. differential backup — Backup method that backs up only files that have changed or have been created since the last full backup. When recovering data, only two backups are needed: the full backup and the last differential backup. disk cache — A method whereby recently retrieved data and adjacent data are read into memory in advance, anticipating the next CPU request. -

MX2 Reference Guide, Rev A
MX2 Reference Guide MX2A137REFGD October 2000 E-EQ-MX2RG-A-ARC Copyright © 2000 by LXE Inc. An EMS Technologies Company All Rights Reserved MX2A1 3 7REFGD REV I S I ON A REGULATORY NOTICES Notice: LXE Inc. reserves the right to make improvements or changes in the products described in this manual at any time without notice. While reasonable efforts have been made in the preparation of this document to assure its accuracy, LXE assumes no liability resulting from any errors or omissions in this document, or from the use of the information contained herein. Copyright Notice: This manual is copyrighted. All rights are reserved. This document may not, in whole or in part, be copied, photocopied, reproduced, translated or reduced to any electronic medium or machine-readable form without prior consent, in writing, from LXE Inc. Copyright © 2000 by LXE Inc., An EMS Technologies Company 125 Technology Parkway, Norcross, GA 30092, U.S.A. (770) 447-4224 LXE is a registered trademark of LXE Inc. All other brand or product names are trademarks or registered trademarks of their respective companies or organizations. Note: The original equipment’s Reference Manual is copyrighted by PSC® Inc. This manual has been amended by LXE® Inc., for the MX2 and Docking Stations with PSC’s express permission. Notice: The long term characteristics or the possible physiological effects of radio frequency electromagnetic fields have not been investigated by UL. FCC Information: This device complies with FCC Rules, part 15. Operation is subject to the following conditions: 1. This device may not cause harmful interference and 2. -

Install Guide
THIS BOX CONTAINS: • (1) CD (your game!) • Install Guide (16 pp.) with quick installation instructions, directions for creating a floppy boot disk, configurations for a variety of memory management systems and Troubleshooting answers to possible problems. • Playguide (24 pp.) covering movement, fighting, interaction and so on. • Reference Card lists keyboard commands for a single-glance reminder. • Top Line — news brief, courtesy of the World Economic Consortium. • Anti-Terrorist Site Security — guide to keeping your WEC installation safe from armored, gun-toting turncoats and other menaces, annotated by General Maxis. • Resistance Handbook — written briefing for new rebel recruits. • Registration Card — please tell us who you are! CRUSADER: NO REMORSE ™ INSTALL GUIDE Welcome to Crusader: No Remorse. This guide includes quick installation instructions for users more familiar with the process, and a detailed, step-by- step guide to installing the game. If you experience any difficulty, consult Troubleshooting (page 9). To avoid compatibility or memory problems, please take a moment to confirm that your machine matches the System Require- ments described on page 2. Remember, you may safely stop at any time during installation and return to DOS with q, except when files are being copied. QUICK INSTALLATION Note: If you are running a disk cache such as SMARTDrive, you need to disable it to ensure a clean installation. (This only affects the installation of the game. SMARTDrive will work normally during gameplay.) Refer to your SMARTDrive documentation or make a system boot disk as described in Boot Disks (page 4) to disable this cache. 1. Turn on your computer and wait for the DOS prompt. -

How to Cheat at Windows System Administration Using Command Line Scripts
www.dbebooks.com - Free Books & magazines 405_Script_FM.qxd 9/5/06 11:37 AM Page i How to Cheat at Windows System Administration Using Command Line Scripts Pawan K. Bhardwaj 405_Script_FM.qxd 9/5/06 11:37 AM Page ii Syngress Publishing, Inc., the author(s), and any person or firm involved in the writing, editing, or produc- tion (collectively “Makers”) of this book (“the Work”) do not guarantee or warrant the results to be obtained from the Work. There is no guarantee of any kind, expressed or implied, regarding the Work or its contents.The Work is sold AS IS and WITHOUT WARRANTY.You may have other legal rights, which vary from state to state. In no event will Makers be liable to you for damages, including any loss of profits, lost savings, or other incidental or consequential damages arising out from the Work or its contents. Because some states do not allow the exclusion or limitation of liability for consequential or incidental damages, the above limitation may not apply to you. You should always use reasonable care, including backup and other appropriate precautions, when working with computers, networks, data, and files. Syngress Media®, Syngress®,“Career Advancement Through Skill Enhancement®,”“Ask the Author UPDATE®,” and “Hack Proofing®,” are registered trademarks of Syngress Publishing, Inc.“Syngress:The Definition of a Serious Security Library”™,“Mission Critical™,” and “The Only Way to Stop a Hacker is to Think Like One™” are trademarks of Syngress Publishing, Inc. Brands and product names mentioned in this book are trademarks or service marks of their respective companies. -

Thank You for Purchasing the Elder Scrolls: Arena. Dedicated Rpgers
The Elder Scrolls ARENA hank you for purchasing The Elder Scrolls: Arena. Dedicated RPGers have invested an incredible amount of effort into creating this detailed simulation. If you enjoy the game, please pass the word! There is no better advertising than a satisfied customer. TYou can also purchase the second chapter of The Elder Scrolls, entitled Daggerfall, in Fall 1996. TES: Daggerfall will feature the same open-endedness and breadth as Arena, but will feature increased NPC (Non-Player-Character) interaction, a faster, more sophisticated 3-D engine, and a more extensive storyline. With all the planned enhancements, Daggerfall will give you even more of an opportunity to role-play your character as you choose. We are very excited about Daggerfall and what it will mean to the role-playing community. On our part, we promise to keep bringing you the best in computer simulation software and welcome any suggestions you may have for how we can serve you better. Journey well, and peace be with you. —The Bethesda Team Installing the Game Place the CD into your computer’s CD-ROM drive. Type the drive letter followed by a colon (Ex: D: for most CD-ROM drives) and hit <ENTER>. Next type INSTALL and hit <ENTER>. If you are installing Arena from floppy disks, select ‘Install Game’ and follow the prompts. Because you are installing from the CDROM, 5 megabytes of data will be copied to your hard drive when you select ‘Exit’. The next step is to configure your game (see below). Configuring Arena to your System To configure any Sound FX and Music drivers once Arena has successfully installed (if you wish to play the game with sound and/or music), choose the ‘Configure Game’ option. -

Windows 95 & NT
Windows 95 & NT Configuration Help By Marc Goetschalckx Version 1.48, September 19, 1999 Copyright 1995-1999 Marc Goetschalckx. All rights reserved Version 1.48, September 19, 1999 Marc Goetschalckx 4031 Bradbury Drive Marietta, GA 30062-6165 tel. (770) 565-3370 fax. (770) 578-6148 Contents Chapter 1. System Files 1 MSDOS.SYS..............................................................................................................................1 WIN.COM..................................................................................................................................2 Chapter 2. Windows Installation 5 Setup (Windows 95 only)...........................................................................................................5 Internet Services Manager (Windows NT Only)........................................................................6 Dial-Up Networking and Scripting Tool....................................................................................6 Direct Cable Connection ..........................................................................................................16 Fax............................................................................................................................................17 Using Device Drivers of Previous Versions.............................................................................18 Identifying Windows Versions.................................................................................................18 User Manager (NT Only) .........................................................................................................19 -

Review NTFS Basics
Australian Journal of Basic and Applied Sciences, 6(7): 325-338, 2012 ISSN 1991-8178 Review NTFS Basics Behzad Mahjour Shafiei, Farshid Iranmanesh, Fariborz Iranmanesh Bardsir Branch, Islamic Azad University, Bardsir, Iran Abstract: The Windows NT file system (NTFS) provides a combination of performance, reliability, and compatibility not found in the FAT file system. It is designed to quickly perform standard file operations such as read, write, and search - and even advanced operations such as file-system recovery - on very large hard disks. Key words: Format, NTFS, Volume, Fat, Partition INTRODUCTION Formatting a volume with the NTFS file system results in the creation of several system files and the Master File Table (MFT), which contains information about all the files and folders on the NTFS volume. The first information on an NTFS volume is the Partition Boot Sector, which starts at sector 0 and can be up to 16 sectors long. The first file on an NTFS volume is the Master File Table (MFT). The following figure illustrates the layout of an NTFS volume when formatting has finished. Fig. 5-1: Formatted NTFS Volume. This chapter covers information about NTFS. Topics covered are listed below: NTFS Partition Boot Sector NTFS Master File Table (MFT) NTFS File Types NTFS File Attributes NTFS System Files NTFS Multiple Data Streams NTFS Compressed Files NTFS & EFS Encrypted Files . Using EFS . EFS Internals . $EFS Attribute . Issues with EFS NTFS Sparse Files NTFS Data Integrity and Recoverability The NTFS file system includes security features required for file servers and high-end personal computers in a corporate environment. -
Microsoft Windows for MS
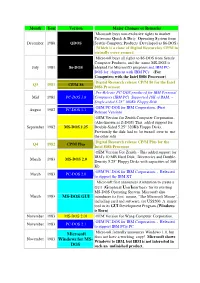
Month Year Version Major Changes or Remarks Microsoft buys non-exclusive rights to market Pattersons Quick & Dirty Operating System from December 1980 QDOS Seattle Computer Products (Developed as 86-DOS) (Which is a clone of Digital Researches C P/M in virtually every respect) Microsoft buys all rights to 86-DOS from Seattle Computer Products, and the name MS-DOS is July 1981 86-DOS adopted for Microsoft's purposes and IBM PC- DOS for shipment with IBM PCs (For Computers with the Intel 8086 Processor) Digital Research release CP/M 86 for the Intel Q3 1981 CP/M 86 8086 Processer Pre-Release PC-DOS produced for IBM Personal Mid 1981 PC-DOS 1.0 Computers (IBM PC) Supported 16K of RAM, ~ Single-sided 5.25" 160Kb Floppy Disk OEM PC-DOS for IBM Corporation. (First August 1982 PC-DOS 1.1 Release Version) OEM Version for Zenith Computer Corporation.. (Also known as Z-DOS) This added support for September 1982 MS-DOS 1.25 Double-Sided 5.25" 320Kb Floppy Disks. Previously the disk had to be turned over to use the other side Digital Research release CP/M Plus for the Q4 1982 CP/M Plus Intel 8086 Processer OEM Version For Zenith - This added support for IBM's 10 MB Hard Disk, Directories and Double- March 1983 MS-DOS 2.0 Density 5.25" Floppy Disks with capacities of 360 Kb OEM PC-DOS for IBM Corporation. - Released March 1983 PC-DOS 2.0 to support the IBM XT Microsoft first announces it intention to create a GUI (Graphical User Interface) for its existing MS-DOS Operating System. -

Guide to Computer Forensics and Investigations Fourth Edition
Guide to Computer Forensics and Investigations Fourth Edition Chapter 6 Working with Windows and DOS Systems Objectives • Explain the purpose and structure of file systems • Describe Microsoft file structures • Explain the structure of New Technology File System (NTFS) disks • List some options for decrypting drives encrypted with whole disk encryption Guide to Computer Forensics and Investigations 2 Objectives (continued) • Explain how the Windows Registry works • Describe Microsoft startup tasks • Describe MS-DOS startup tasks • Explain the purpose of a virtual machine Guide to Computer Forensics and Investigations 3 Understanding File Systems • File system – Gives OS a road map to data on a disk • Type of file system an OS uses determines how data is stored on the disk • A file system is usually directly related to an OS • When you need to access a suspect’s computer to acquire or inspect data – You should be familiar with the computer’s platform Guide to Computer Forensics and Investigations 4 Understanding the Boot Sequence • Complementary Metal Oxide Semiconductor (CMOS) – Computer stores system configuration and date and time information in the CMOS • When power to the system is off • Basic Input/Output System (BIOS) – Contains programs that perform input and output at the hardware level Guide to Computer Forensics and Investigations 5 Understanding the Boot Sequence (continued) • Bootstrap process – Contained in ROM, tells the computer how to proceed – Displays the key or keys you press to open the CMOS setup screen • CMOS should -

Spinrite 5.0 Literature
SpinRite 5.0 Personal Computing’s Premier Hard Disk Maintenance & Recovery Tool What does SpinRite do? When SpinRite™1.0 was released into the market SpinRite is easy to use, and easy to explain, because it does just one thing really in March of 1988, the well: It fixes hard disk drives to make them work perfectly. It’s as simple as that. nature of hard disk SpinRite scrubs drive surfaces, finding and fixing any problems it encounters. utilities was redefined It recovers data that has become unreadable by the operating system or any other overnight. SpinRite won a utilites and makes that data readable again. By providing both preventive place in Personal maintenance and data recovery, this single utility is everything most people will Computing history by ever need to maintain the health of their disk drives and the safety of their data. winning a place in the hearts and minds of Key Features of SpinRite 5.0: Personal Computer users. l Operates on DOS/Windows 12-bit, 16-bit, and 32-bit File Allocation Table (FAT) partitions of any size. Today’s SpinRite 5.0, is l Exceedingly simple operation – technical knowledge is not required. the result of over ten years of SpinRite l Direct hardware-level operation with hard disk controllers and advanced evolution. It incorporates support for IDE, EIDE, and SCSI hard disk drives. Aware of the latest many key advances to hard disk drive technologies including Iomega ZIP and JAZ. the state of the art in l New “Flux Synthesis”™super-sensitive surface analysis defect detection. -

EZ-Drive Quick Installation
EZ-Drive Quick Installation Installation Software for WD Caviar 3.5-Inch EIDE Hard Drives (EZ-Drive 9.06W or later) EZ-DRIVE SOFTWARE OVERVIEW formats the hard drive; it does not install EZ-BIOS. If it does not, EZ- Drive partitions and formats the hard drive and installs EZ-BIOS on EZ-Drive is a software utility that quickly and easily partitions and the boot sector of the hard drive. formats your new hard drive. If needed, EZ-Drive installs added code in the boot sector of your hard drive if it determines that your system BIOS does not support the full capacity of your hard drive. EZ-Drive Partitioning and Formatting software is included with the Western Digital hard drive to: EZ-Drive automatically partitions and formats your hard drive. You ■ Overcome the 8.4 GB, 2.1 GB, and 528 MB system BIOS can accept the EZ-Drive default partition sizes or create custom limitations. partitions. See Frequently Asked Questions on page 5 before ■ Partition and format your new hard drive. partitioning your hard drive. ■ Copy system files needed to boot your new hard drive. Since it is difficult to determine if your system BIOS supports 8.4 GB ■ Copy the contents of an existing hard drive onto your new hard or larger hard drives, we recommend using EZ-Drive 9.06W or later drive (optional). versions. It is a fast and easy way to partition and format your new If you did not receive EZ-Drive software, you can download it from hard drive. the Western Digital web site at www.westerndigital.com. -

Smaller Flight Data Recorders{
Available online at http://docs.lib.purdue.edu/jate Journal of Aviation Technology and Engineering 2:2 (2013) 45–55 Smaller Flight Data Recorders{ Yair Wiseman and Alon Barkai Bar-Ilan University Abstract Data captured by flight data recorders are generally stored on the system’s embedded hard disk. A common problem is the lack of storage space on the disk. This lack of space for data storage leads to either a constant effort to reduce the space used by data, or to increased costs due to acquisition of additional space, which is not always possible. File compression can solve the problem, but carries with it the potential drawback of the increased overhead required when writing the data to the disk, putting an excessive load on the system and degrading system performance. The author suggests the use of an efficient compressed file system that both compresses data in real time and ensures that there will be minimal impact on the performance of other tasks. Keywords: flight data recorder, data compression, file system Introduction A flight data recorder is a small line-replaceable computer unit employed in aircraft. Its function is recording pilots’ inputs, electronic inputs, sensor positions and instructions sent to any electronic systems on the aircraft. It is unofficially referred to as a "black box". Flight data recorders are designed to be small and thoroughly fabricated to withstand the influence of high speed impacts and extreme temperatures. A flight data recorder from a commercial aircraft can be seen in Figure 1. State-of-the-art high density flash memory devices have permitted the solid state flight data recorder (SSFDR) to be implemented with much larger memory capacity.