Randomly Weighted Sums, Products in CEVM and Free Subexponentiality
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

International Congress of Mathematicians
International Congress of Mathematicians Hyderabad, August 19–27, 2010 Abstracts Plenary Lectures Invited Lectures Panel Discussions Editor Rajendra Bhatia Co-Editors Arup Pal G. Rangarajan V. Srinivas M. Vanninathan Technical Editor Pablo Gastesi Contents Plenary Lectures ................................................... .. 1 Emmy Noether Lecture................................. ................ 17 Abel Lecture........................................ .................... 18 Invited Lectures ................................................... ... 19 Section 1: Logic and Foundations ....................... .............. 21 Section 2: Algebra................................... ................. 23 Section 3: Number Theory.............................. .............. 27 Section 4: Algebraic and Complex Geometry............... ........... 32 Section 5: Geometry.................................. ................ 39 Section 6: Topology.................................. ................. 46 Section 7: Lie Theory and Generalizations............... .............. 52 Section 8: Analysis.................................. .................. 57 Section 9: Functional Analysis and Applications......... .............. 62 Section 10: Dynamical Systems and Ordinary Differential Equations . 66 Section 11: Partial Differential Equations.............. ................. 71 Section 12: Mathematical Physics ...................... ................ 77 Section 13: Probability and Statistics................. .................. 82 Section 14: Combinatorics........................... -

A Complete Bibliography of Publications in Statistics and Probability Letters: 2010–2019
A Complete Bibliography of Publications in Statistics and Probability Letters: 2010{2019 Nelson H. F. Beebe University of Utah Department of Mathematics, 110 LCB 155 S 1400 E RM 233 Salt Lake City, UT 84112-0090 USA Tel: +1 801 581 5254 FAX: +1 801 581 4148 E-mail: [email protected], [email protected], [email protected] (Internet) WWW URL: http://www.math.utah.edu/~beebe/ 24 April 2020 Version 1.24 Title word cross-reference (1; 2) [Yan19a]. (α, β)[Kay15].(1; 1) [BO19]. (k1;k2) [UK18]. (n − k +1) [MF15, ZY10a]. (q; d) [BG16]. (X + Y ) [AV13b]. 1 [Hel19, Red17, SC15, Sze10]. 1=2[Efr10].f2g [Sma15, Jac13, JKD15a, JKD15b, Kha14, LM17, MK10, Ose14a, WL11]. 2k [Lu16a, Lu16b]. 2n−p [Yan13]. 2 × 2 [BB12, MBTC13]. 2 × c [SB16]. 3 [CGLN17, HWB10]. 3x + 1 [DP16]. > [HB18]. > 1=2 [DO11a]. [0; 1] [LP19a]. L1 q (` ) [Ose15a]. k [BML14]. r [VCM14]. A [CDS17, MPA12, PPM18, KDW15]. A1 [Ose13a]. α [AH12b, hCyP15, GT14, LT19b, MY14, MU13, Mic11, MM14b, PP14b, Sre12, Yan17b, ZZT17, ZYS19, ZZ13b, ZLC18, ZZ19a]. AR(1) [CL10, Mar16, PPN10]. AR(p) [WN14b]. ARH(1) [RMAL19].´ β [EM10, JW16, Kre18, Poi19, RBY10, Su10, XXY17, YZ16]. β !1[JW16]. 1 C[0; 1] [Mor18]. C[0; 1] [KM19]. C [LL17c]. D [CDS17, DS15, Jac11, KHN12, Sin19, Sma14, ZP12, Dav12b, OA15,¨ Rez15]. 1 2 Ds [KHN12]. D \ L [BS12a]. δ [Ery12, PB15a]. d ≥ 3 [DH19]. DS [WZ17]. d × R [BS19b]. E [DS15, HR19a, JKD14, KDW15]. E(fNOD)[CKF17].`1 N [AH11]. `1 [Ose19]. `p [Zen14]. [BCD19]. exp(x)[BM11].F [MMM13]. -

Year 2010-11 Is Appended Below
PRESIDENT OF THE INSTITUTE, CHAIRMAN AND OTHER MEMBERS OF THE COUNCIL AS ON MARCH 31, 2011 President: Prof. M.G.K. Menon, FRS 1. Chairman: Shri Pranab Mukherjee, Hon’ble Finance Minister, Government of India. 2. Director: Prof. Bimal K. Roy. Representatives of Government of India 3. Dr. S.K. Das, DG, CSO, Government of India, Ministry of Statistics & Programme Implementation, New Delhi. 4. Dr. K.L. Prasad, Adviser, Government of India, Ministry of Finance, New Delhi. 5. Dr. Rajiv Sharma, Scientist ‘G’ & Adviser, (International Cooperation), Department of Science & Technology, Government of India, New Delhi. 6. Shri Deepak K. Mohanty, Executive Director, Reserve Bank of India, Mumbai. 7. Shri Anant Kumar Singh, Joint Secretary (HE), Government of India, Ministry of Human Resource Development, Department of Higher Education. Representative of ICSSR 8. Dr. Ranjit Sinha, Member Secretary, Indian Council of Social Science Research, New Delhi. Representatives of INSA 9. Prof. V.D. Sharma, FNA, Department of Mathematics, Indian Institute of Technology, Mumbai. 10. Prof. B.L.S. Prakasa Rao, FNA, Dr. Homi J Bhabha Chair Professor, Department of Mathematics and Statistics, University of Hyderabad, Hyderabad. 11. Prof. T.P. Singh, FNA, DBT Distinguished Biotechnologist, Department of Biophysics, All India Institute of Medical Sciences, New Delhi. 12. Prof. Somnath Dasgupta, FNA, Director, National Centre of Experimental Mineralogy & Petrology, University of Allahabad, Uttar Pradesh. Representative of the Planning Commission 13. Shri B.D. Virdi, Adviser, Perspective Planning Division of Planning Commission, New Delhi. Representative of the University Grants Commission 14. Prof. S. Mahendra Dev, Director, Indira Gandhi Institute of Development Research, Mumbai. Scientists co-opted by the Council 15. -
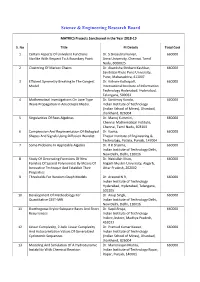
List of MATRICS Projects Funded by SERB During 2018-19
Science & Engineering Research Board MATRICS Projects Sanctioned in the Year 2018-19 S. No Title PI Details Total Cost 1 Certain Aspects Of Univalent Functions Dr. S Sivasubramanian, 660000 Starlike With Respect To A Boundary Point Anna University, Chennai, Tamil Nadu, 6000025 2 Clustering Of Markov Chains Dr. Akanksha Shrikant Kashikar, 660000 Savitribai Phule Pune University, Pune, Maharashtra, 411007 3 Efficient Symmetry Breaking In The Congest Dr. Kishore Kothapalli, 660000 Model International Institute of Information Technology Hyderabad, Hyderabad, Telangana, 500032 4 Mathematical Investigations On Love Type Dr. Santimoy Kundu, 660000 Wave Propagation In Anisotropic Media. Indian Institute of Technology (Indian School of Mines), Dhanbad, Jharkhand, 826004 5 Singularities Of Rees Algebras Dr. Manoj Kummini, 660000 Chennai Mathematical Institute, Chennai, Tamil Nadu, 603103 6 Compression And Representation Of Biological Dr. Kavita, 660000 Shapes And Signals Using Diffusion Wavelet. Thapar Institute of Engineering & Technology, Patiala, Punjab, 147004 7 Some Problems In Applicable Algebra Dr. R K Sharma, 660000 Indian Institute of Technology Delhi, New Delhi, Delhi, 110016 8 Study Of Generating Functions Of New Dr. Nabiullah Khan, 660000 Families Of Special Polynomials By Means Of Aligarh Muslim University, Aligarh, Innovative Technique And Establish Their Uttar Pradesh, 202002 Properties 9 Thresholds For Random Graph Models Dr. Aravind N R, 660000 Indian Institute of Technology Hyderabad, Hyderabad, Telangana, 502205 10 Development Of Methodology For Dr. Anup Singh, 660000 Quantitative CEST-MRI Indian Institute of Technology Delhi, New Delhi, Delhi, 110016 11 Biorthogonal Krylov Subspace Bases And Short Dr. Kapil Ahuja, 660000 Recurrences Indian Institute of Technology Indore, Indore, Madhya Pradesh, 452011 12 Linear Complexity, 2-Adic Linear Complexity Dr. -

Annual Report 2016-17 of the Indian Statistical Institute
PRESIDENT OF THE INSTITUTE, CHAIRMAN AND OTHER MEMBERS OF THE COUNCIL AS ON MARCH 31, 2017 President: Dr. Vijay Kelkar, Padma Vibhushan 1. Chairman: Prof. Goverdhan Mehta, FNA, FRS, Dr. Kallam Anji Reddy Chair School of Chemistry, University of Hyderabad, Central University, Gachibowli, Hyderabad - 500 046, Telangana. 2. Director: Prof. Sanghamitra Bandyopadhyay. Representatives of the Government of India 3. Shri S.K. Singh, Additional Secretary and Financial Advisor, Govt. of India, Ministry of Statistics and Programme Implementation, New Delhi. 4. Dr. G.C. Manna, DG, CSO, Govt. of India, Ministry of Statistics & P.I., New Delhi. 5. Shri Pramod Kumar Das, Additional Secretary, Govt. of India, Ministry of Finance, Department of Expenditure, New Delhi. 6. Dr. Praveer Asthana, Adviser/Scientist-G, Head (AI and Mega Science Divisions), Govt. of India, Ministry of Science and Technology, New Delhi. 7. Dr. M.D. Patra, Executive Director, Reserve Bank of India, Mumbai. 8. Shri R. Subrahmanyam, Additional Secretary (T), Govt. of India, Ministry of Human Resource Development, New Delhi. Representative of the ICSSR 9. Dr. V.K. Malhotra, Member-Secretary, Indian Council of Social Science Research, New Delhi. Representatives of the INSA 10. Dr. Manindra Agrawal, Indian Institute of Technology, Kanpur. 11. Prof. B.L.S. Prakasa Rao, Ph. D, FNA, FASc, FNASc., FAPAS, Former Director ISI, Ramanujan Chair Prof., CR Rao Advance Institute of Mathematics, Statistics and Computer Science, Hyderabad. 12. Dr. Baldev Raj, President, PSG Institutions, Tamil Nadu. 13. Prof. Yadati Narahari, Department of Computer Science and Automation, Indian Institute of Science, Bangalore. Representative of the NITI Aayog/ Planning Commission 14. -

Year 2011-12 Involve Exploring the Relation Between the Euler Class Group of a Ring and That of Its Polynomial Extension
PRESIDENT OF THE INSTITUTE, CHAIRMAN AND OTHER MEMBERS OF THE COUNCIL AS ON MARCH 31, 2012 President: Prof. M.G.K. Menon, FRS 1. Chairman: Shri Pranab Mukherjee, Hon’ble Finance Minister, Government of India. 2. Director: Prof. Bimal K. Roy. Representatives of Government of India 3. Shri S.K. Das, DG, CSO, Govt. of India, Ministry of Statistics & Programme Implementation, New Delhi. 4. Dr. K.L. Prasad, Adviser, Govt. of India, Ministry of Finance, New Delhi. 5. Dr. Rajiv Sharma, Scientist ‘G’ & Adviser, (International Cooperation), Department of Science & Technology, Govt. of India, New Delhi. 6. Shri Deepak K. Mohanty, Executive Director, Reserve Bank of India, Mumbai. 7. Shri Anant Kumar Singh, Joint Secretary (HE), Government of India, Ministry of Human Resource Development, Department of Higher Education, New Delhi. Representative of ICSSR 8. Dr. Ranjit Sinha, Member Secretary, Indian Council of Social Science Research, New Delhi. Representatives of INSA 9. Prof. V.D. Sharma, FNA, Department of Mathematics, Indian Institute of Technology, Mumbai. 10. Prof. B.L.S. Prakasa Rao, FNA, Dr. Homi J Bhabha Chair Professor, Department of Mathematics and Statistics, University of Hyderabad, Hyderabad. 11. Prof. T.P. Singh, FNA, DBT Distinguished Biotechnologist, Department of Biophysics, All India Institute of Medical Sciences, New Delhi. 12. Prof. Somnath Dasgupta, FNA, Department of Earth Sciences, Indian Institute of Science Education & Research, West Bengal. Representative of the Planning Commission 13. Shri B.D. Virdi, Adviser, Perspective Planning Division of Planning Commission, New Delhi. Representative of the University Grants Commission 14. Prof. S. Mahendra Dev, Director, Indira Gandhi Institute of Development Research, Mumbai. -
![Arxiv:2007.14821V2 [Math.PR] 3 Aug 2020 5.4](https://docslib.b-cdn.net/cover/6276/arxiv-2007-14821v2-math-pr-3-aug-2020-5-4-12716276.webp)
Arxiv:2007.14821V2 [Math.PR] 3 Aug 2020 5.4
GROUP MEASURE SPACE CONSTRUCTION, ERGODICITY AND W ∗-RIGIDITY FOR STABLE RANDOM FIELDS PARTHANIL ROY Dedicated to the memory of Professor Jayanta Kumar Ghosh ABSTRACT. This work discovers a new link between probability theory (of stable random fields) and von Neumann algebras. It is established that the group measure space construction corresponding to a minimal representation is an invariant of a stationary symmetric a-stable (SaS) random field d indexed by any countable group G. When G = Z , we characterize ergodicity (and also absolute non- ergodicity) of stationary SaS fields in terms of the central decomposition of this crossed product von Neumann algebra coming from any (not necessarily minimal) Rosinski´ representation. This shows that ergodicity (or the complete absence of it) is a W ∗-rigid property (in a suitable sense) for this class of fields. All our results have analogues for stationary max-stable random fields as well. CONTENTS 1. Introduction2 2. Ergodic Theory of Nonsingular Actions5 2.1. Ergodic and Neveu Decompositions6 2.2. Conjugacy and Orbit Equivalence6 3. von Neumann Algebras7 3.1. Factors and Central Decomposition7 3.2. Group Measure Space Construction8 3.3. W ∗-rigidity 10 4. Stationary SaS Random Fields 11 4.1. Integral Representation 11 4.2. Minimal Representation 12 4.3. The Stationary Case: Rosinski´ Representation 12 5. Linking Stable Fields with von Neumann Algebras 13 5.1. Minimal Representations, Conjugacy and the Crossed Product Invariant 13 5.2. Weak Mixing, Ergodicity and Complete Non-ergodicity 15 ∗ ∗ 5.3. Wm- and WR -rigidities 20 arXiv:2007.14821v2 [math.PR] 3 Aug 2020 5.4. -

Final Voter List of Scientific & Non-Scientific Workers
INDIAN STATISTICAL INSTITUTE 203 B.T. ROAD, KOLKATA 700 108 ELECTION/URGENT No.CAF/Elec/10-3/13 3rd April, 2020 OFFICE CIRCULAR Subject : Final list of Scientific and Non-Scientific Workers in connection with the ensuing Election to various offices of the Council in terms of the regulations and Bye-laws of the Institute for next two-year term with effect from 18 September 2020. 1. Provisional lists of Scientific and Non-Scientific Workers in connection with the above subject, circulated under reference No.CAF/Elec/10-3/09 dated 12th March, 2020 have been revised after the correction of errors, omission etc. to the extent brought to the notice of the undersigned. 1.1 Final lists of Scientific Workers (Annexure-I) and Non-Scientific Workers (Annexure-II) are published herewith. It may be mentioned that the mark ‘A’ as exists in the list of Scientific Workers (Annexure-I) indicates the Workers from the level of Scientific Assistant ‘C’ or equivalent but below the rank of Associate Professors or equivalent of the Scientific Divisions. 2. Steps required for the conduct of the elections had already been described in the circular No.CAF/Elec/10-3/07 dated 6th March, 2020. For the sake of convenience of the Workers (voters), salient points of the same are reiterated below :- 2.1 Professor-in-Charge : A Professor-in-Charge will be elected for a period of two years from amongst Associate Professor (or equivalent) and above, from each of the following Divisions : (i) Theoretical Statistics and Mathematics (ii) Applied Statistics (iii) Social Sciences (iv) Physics and Earth Sciences (v) Computer and Communication Sciences (vi) Biological Sciences All members of the D.C.S.W.