Timetable of Events
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

International Business Research and Risky Investments, an Analysis of FDI in Conflict Zones Nigel Driffieldª , Chris Jonesª &A
International business research and risky investments, an analysis of FDI in conflict zones Nigel Driffieldª, Chris Jonesª & Jo Crottyb ªAston Business School, Aston University, Aston Triangle, Birmingham, B4 7ET, UK b Salford Business School, M225 Maxwell Building, University of Salford,43 The Crescent, Manchester, M5 4WT, UK A B S T R A C T The purpose of this paper is to examine the determinants of a firm’s strategy to invest in a conflict location. To the best of our knowledge, this has not been done before. We examine this using a standard model of international business, overlaid with the fundamental approach to corporate social responsibility. We start with the population of multinationals who have chosen to invest in low income countries with weak institutions. We then split this sample in order to distinguish between firms that have invested in conflict regions compared to those that haven’t. Our analysis then proceeds to explain the decision of those firms to invest in conflict locations by using a simple Probit model. We find that countries with weaker institutions and less concern about corporate social responsibility (CSR) are more likely to invest in conflict regions. Finally, firms with more concentrated ownership are more likely to invest in such locations. Keywords: Conflict, Corporate Social Responsibility, FDI, Institutions. 1. Introduction The purpose of this paper is to examine investments by largely western firms into areas of conflict. The previous literature that we discuss below focuses on the extent to which FDI into such locations may impact on the instability of the region, or subsequently, Corresponding author at: Aston Business School, Aston University, Aston Triangle, Birmingham, B4 7ET, UK. -

Open Research Online Oro.Open.Ac.Uk
Open Research Online The Open University’s repository of research publications and other research outputs Beyond ecosystem services: valuing the invaluable Journal Item How to cite: Gunton, Richard M.; van Asperen, Eline; Basden, Andrew; Bookless, David; Araya, Yoseph; Hanson, David R.; Goddard, Mark A.; Otieno, George and Jones, Gareth O. (2017). Beyond ecosystem services: valuing the invaluable. Trends in Ecology and Evolution, 32(4) pp. 249–257. For guidance on citations see FAQs. c [not recorded] https://creativecommons.org/licenses/by-nc-nd/4.0/ Version: Accepted Manuscript Link(s) to article on publisher’s website: http://dx.doi.org/doi:10.1016/j.tree.2017.01.002 Copyright and Moral Rights for the articles on this site are retained by the individual authors and/or other copyright owners. For more information on Open Research Online’s data policy on reuse of materials please consult the policies page. oro.open.ac.uk Opinion piece for Trends in Ecology & Evolution Beyond ecosystem services: valuing the invaluable Authors: Richard M. Gunton1,2, Eline van Asperen3, Andrew Basden4, David Bookless5,6, Yoseph Araya7, David R. Hanson2, Mark A. Goddard8, George Otieno9, Gareth O. Jones2 1 School of Biology, University of Leeds, LS2 9JT, UK 2 West Yorkshire School of Christian Studies, Outwood House, Leeds, LS18 4JN, UK 3 Department of Anthropology, Durham University, DH1 3LA, UK 4 Salford Business School, University of Salford, M5 4WT, UK 5 A Rocha International, 89 Worship Street, London, EC2A 2BF, UK 6 Faculty of Divinity, University of Cambridge, CB3 9BS, UK 7School of Environment Earth & Ecosystems, Open University, Milton Keynes, MK7 6AA, UK 8School of Civil Engineering & Geosciences, Newcastle University, NE1 7RU, UK 9School of Arts & Communication, Leeds Trinity University, Horsforth, LS18 5HD, UK Corresponding author: Gunton, R. -

Salford Student Becomes Double Gold Medallist at Rio Paralympics Salford Successes a Round up of Our Achievements Throughout the Past Semester
SPRING 2017 Salford Successes Salford Stories: Supporting Care Leavers Introducing: New Patient Simulation Suites Sport at Salford Work with US Salford student becomes double gold medallist at Rio Paralympics Salford Successes A round up of our achievements throughout the past semester... more detailed information about the zone’s animal life. Their findings have contributed to high-level debate about the potential creation of a Chernobyl nature reserve and garnered a huge amount of press coverage. The judges said that the research project was impressive in the way that it used “ground-breaking radiological methods to explore the impact of nuclear radiation on wildlife in the Chernobyl area”. On collecting the award, Dr Wood said: “I am absolutely delighted. What a journey this has been. To have the opportunity to undertake ecological research in the Chernobyl Exclusion Zone is an amazing privilege. To have the excellence of that research recognised through such a prestigious award is just fantastic. To undertake such work requires excellent Salford wins Research collaboration, with colleagues in the Ukraine, France and in Salford, I clearly accept this Project of the Year award on behalf of all of them. I also want to back of an ambulance transporting patients thank the University of Salford for providing Salford launches new between hospitals to a nightclub in which a such a fantastic environment in which research patient has collapsed. In November, academics from Salford collected the can truly flourish.” Patient Simulation Suites Special ‘touch spots’ on the wall and floor Research Project of the Year award at the esteemed Huge congratulations to Dr Wood can enable patients to interact with the Times Higher Education Awards in London. -

University Fair at Sci-Tech Daresbury
University Fair at Sci-Tech Daresbury Friday 21st November 2014 09.30 – 12.30 The Cockcroft Institute Sci-Tech Daresbury INTRODUCTION Sci-Tech Daresbury was established in 2006 (formerly known as Daresbury Science and Innovation Campus) as one of the UK’s national science and innovation campuses and more recently in 2012 as a strategic Enterprise Zones. It is internationally-recognised for the world-class Location scientific facilities and expertise that is located on the site through the Science and Technology The event will take place in the The Cockcroft Facilities Council’s Daresbury Laboratory Institute at Sci-Tech Daresbury. For directions particularly in areas such as accelerator science, please go to http://www.sci-techdaresbury. high performance computing, modelling & com/location. Visitor parking is available in the simulation, big data analytics, sensors and Daresbury Laboratory car park adjacent to the detectors. reception building. It is also home to over 100 technology companies Registration in areas such as advanced engineering, digital/ ICT technologies, biomedical technologies and The Sci-Tech Daresbury University Fair is now services, and clean technologies. It is now widely- open for bookings. To book your place at the recognised for the business support it brings to event on please click here (you will be prompted the businesses to help companies accelerate their to login with your NewsHub user name and growth, innovate more effectively and more easily password in order to access the event page). identify and establish collaborative partnerships. If you aren’t already a member of the Sci-Tech A critical part of this is our relationships with the Daresbury network, click here to become a regional universities who we see as key partners member and then go to the webpage for the in bringing support and expertise to technology event to register. -

Downloaded From: Version: Accepted Version Publisher: SAGE Publications DOI
Cheetham, FC and McEachern, MG and Warnaby, GC (2018) A Kaleido- scopic View of the Territorialised Consumption of Place’. Marketing Theory. ISSN 1470-5931 Downloaded from: https://e-space.mmu.ac.uk/618970/ Version: Accepted Version Publisher: SAGE Publications DOI: https://doi.org/10.1177/1470593117724608 Please cite the published version https://e-space.mmu.ac.uk A Kaleidoscopic View of the Territorialised Consumption of Place Short title: Territorialised Consumption of Place Authors1: Fiona Cheetham, The Business School, University of Huddersfield, Queensgate, Huddersfield, HD1 3DH. Email: [email protected] Morven G McEachern2, Salford Business School, University of Salford, Salford, M5 4WT. Email: [email protected] Gary Warnaby, Institute of Place Management, Manchester Metropolitan University, Faculty of Business and Law, All Saints Campus, Oxford Road, Manchester, M15 6BH. Email: [email protected] 1Due to the equal input to the paper from all authors, the names are presented alphabetically. 2Corresponding author 1 Biographies Fiona Cheetham is a Senior Lecturer in Marketing in the Business School at the University of Huddersfield. Her research comprises of a number of streams, which diverge in terms of the consumer contexts studied (the socio-material practices that constitute the consumer collectables market, pet related consumption practices within the human-animal relationship and latterly the socio-material, temporal and spatial practices associated with the consumption of urban green space) but overlap in terms of her engagement with and development of ideas concerning the ontology of agency. Her work has been published in Consumption, Markets & Culture, the Journal of Consumer Behaviour and the International Journal of Consumer Studies. -

Download (644Kb)
This is an Open Access document downloaded from ORCA, Cardiff University's institutional repository: http://orca.cf.ac.uk/136861/ This is the author’s version of a work that was submitted to / accepted for publication. Citation for final published version: Hosseini, Farhad Zahedi, Syntetos, Aris A. and Scarf, Philip A. 2018. Optimisation of inspection policy for multi-line production systems. European Journal of Industrial Engineering 12 (2) , pp. 233-251. 10.1504/EJIE.2018.090616 file Publishers page: http://dx.doi.org/10.1504/EJIE.2018.090616 <http://dx.doi.org/10.1504/EJIE.2018.090616> Please note: Changes made as a result of publishing processes such as copy-editing, formatting and page numbers may not be reflected in this version. For the definitive version of this publication, please refer to the published source. You are advised to consult the publisher’s version if you wish to cite this paper. This version is being made available in accordance with publisher policies. See http://orca.cf.ac.uk/policies.html for usage policies. Copyright and moral rights for publications made available in ORCA are retained by the copyright holders. Optimisation of inspection policy for multi-line production systems Farhad Zahedi-Hosseini School of Computing, Science and Engineering, University of Salford, Manchester, UK E-mail: [email protected] Aris A. Syntetos Cardiff Business School Cardiff University Cardiff, UK E-mail: [email protected] Philip A. Scarf* Salford Business School, University of Salford, Manchester, UK E-mail: [email protected] *Corresponding author Abstract: This paper develops a simulation model to determine the cost- optimum inspection policy for a multi-line production system taking account of simultaneous downtime. -

Current Full College Members by Name
Current EPSRC Full College Members List Generated: 28 June 2021 Name OrganisationName: DepartmentName: Professor DGA Aarts University of Oxford Oxford Chemistry Dr Q Abbasi University of Glasgow School of Engineering Professor A Abbott University of Leicester Chemistry Mr J Abbott Arup (Ove Arup and Partners Ltd) (UK) Leeds Office Professor SJ Abbott Private Address Private Address Professor A ABDOLVAND University of Dundee Mechanical and Electronic Engineering Dr C Abhayaratne University of Sheffield Electronic and Electrical Engineering Professor M Acar Loughborough University Wolfson Sch of Mech, Elec & Manufac Eng Professor GJ Ackland University of Edinburgh Sch of Physics and Astronomy Professor AE Adam Sheffield Hallam University College of Social Sciences and Arts Professor A Adamatzky University of the West of England Faculty of Environment and Technology Dr B Adams University of Bath Mathematical Sciences Professor CS Adams Durham University Physics Professor DJ Adams University of Glasgow School of Chemistry Professor M Adams University of Essex Computer Sci and Electronic Engineering Professor MJ Adams University of Birmingham Chemical Engineering Professor GA Adebayo Federal University of Agriculture Physics Professor G Adesso University of Nottingham Sch of Mathematical Sciences Professor S Adhikari Swansea University College of Engineering Professor CS Adjiman Imperial College London Chemical Engineering Dr A A Adumitroaie University of Girona Unlisted Professor L Agapito University College London Computer Science Dr A Aggarwal -

Locationseurope Excl
Istanbul, Turkey Global Conference 2019 13-15 May 2019 4% 2% 3% Job role 14% Director, Associate Director North America/3% UK/15% LocationsEurope excl. UK/36% Dean, Associate Dean Other President, Vice President, Chairman, Chief, Rector Manager Head 32% 45% Oceania/3% Countries Schools 49 179 Africa/6% Latin America/10% Asia & Middle Attending Schools East/27% Aberdeen Business School, Robert Chongqing University Essex Business School Henley Business School, University of Reading International Management Institute (MIM-Kyiv) Leeds University Business School Paris School of Business Sheffield University Management School Universidad Adolfo Ibañez University of Science and Technology of China Gordon University School of Management Chuo University Graduate School of Facultdad de Economia y Negocios, Higher Business School, State International Management Institute of Maastricht School of Management Peking University HSBC Business School SKEMA Business School Universidad de Los Andes Adam Smith Business School, Strategic Management Universidad Andres Bello University of Management St. Petersburg (IMISP) University of South Pacific Graduate School University of Glasgow of Business Maastricht University School of Porto Business School Southwest Jiaotong University, School of Universidad EAFIT CITY College, International Faculty of the Faculty of Economics & Business, Higher School of Business, Kazan International University of Monaco Business and Economics Economics and Management ALBA Graduate Business School University of Sheffield University -

The Executive MBA Catalogue SHEFFIELD
International Faculty CITY College. The Executive MBA Educating Business Leaders Εxecutive MBA at the International Faculty, CITY College is accredited by AACSB, AMBA & CMI Contents 1 Welcome Messages 2 - 3 The University of Sheffield International Faculty, CITY College 4 Global Recognition of the University of Sheffield 5 Accreditation & Recognition 6 - 7 The University of Sheffield Executive MBA: a holistic approach to business management education 8 - 9 The Executive MBA Programme 10 - 11 The Study Weeks in Sheffield & Thessaloniki 12 The EMBA Student Profile 13 Testimonials 14 - 15 The University of Sheffield International Faculty, CITY College Benefits to Students 16 The University of Sheffield International Faculty, CITY College Benefits to Companies 17 Participating Companies 18 The Faculty 19 EDI Executive Development Institute 20 Applying for the Executive MBA Welcome Messages Message from the Director of the Executive Education Centre More than ever, during times of great uncertainty and in an increasingly complex world, managers need cutting edge skills and knowledge to assist in making informed decisions. Our MBA programme gives its students the tools to compete, to succeed and be pioneers in their field. We build curricula delivered by world class lecturers who balance theoretical knowledge with management and consulting experience. We deliver classes enhancing deep understanding of concepts, and promoting in depth discussion of practices. We are honored that you are considering our accredited truly international Executive MBA programme to enhance your knowledge and boost your career. Mr. George Efstathiadis Message from the Academic Director of EMBA We pride ourselves on the education we offer to our students which is premised on a comprehensive blending of cutting edge academics and practical application. -

Integrated Report 2020 Financial Statements for the Year Ended 31 July 2020
INTEGRATED REPORT 2020 FINANCIAL STATEMENTS FOR THE YEAR ENDED 31 JULY 2020 Nathan Harrison: student nurse on front line fight against Covid-19 2 Welcome to our Integrated Annual Report. This report summarises the activity of the University of Salford for the year ended 31 July 2020 and shows the impact of our response to Covid-19. It provides an overview of our business model and strategic objectives as well as our performance against our core indicators. There is detail on our leadership and governance structures and an insight in to the decisions that are made in INTEGRATED REPORT 2020 order to meet our commercial and wider responsibilities. CONTENTS 04 / OUR VISION AND MISSION 06 / IN DISCUSSION WITH THE VC 10 / OPERATING ENVIRONMENT 14 / STRATEGY AND OPERATIONAL REVIEW 14 Value creation 16 Growing and diversifying our income 20 Student experience and outcomes 26 Research and industry connectedness 30 Enablers 36 / STRIVING FOR ENVIRONMENTAL SUSTAINABILITY 40 / RISK 44 / PUBLIC BENEFIT 48 / FINANCIAL PERFORMANCE 52 / GOVERNANCE 62 / STATEMENT OF COUNCIL RESPONSIBILITIES IN RESPECT OF INTEGRATED REPORT AND THE FINANCIAL STATEMENTS 64 / INDEPENDENT AUDITOR’S REPORT TO THE COUNCIL OF UNIVERSITY OF SALFORD 66 / CONSOLIDATED AND INSTITUTION STATEMENT OF COMPREHENSIVE INCOME & EXPENDITURE 68 / CONSOLIDATED STATEMENT OF CHANGE IN RESERVES 69 / INSTITUTION STATEMENT OF CHANGE IN RESERVES 70 / CONSOLIDATED AND INSTITUTION STATEMENT OF FINANCIAL POSITION 71 / CONSOLIDATED STATEMENT OF CASH FLOWS 72 / STATEMENT OF ACCOUNTING POLICIES 78 / ACCOUNTING ESTIMATES AND JUDGEMENTS SALFORD OF UNIVERSITY 80 / NOTES TO THE ACCOUNTS 3 4 OUR PURPOSE Through teaching, learning, research OUR VISION and enterprise, we harness the skills, imagination and enthusiasm of our students INTEGRATED REPORT 2020 and staff to work in partnership to change people and communities and deliver lasting AND MISSION economic and social benefit. -

An Investigation of Systemic Stress and Interdependencies Within the Eurozone and Euro Area Countries
This is an Open Access document downloaded from ORCA, Cardiff University's institutional repository: http://orca.cf.ac.uk/105787/ This is the author’s version of a work that was submitted to / accepted for publication. Citation for final published version: MacDonald, Ronald, Sogiakas, Vasilios and Tsopanakis, Andreas 2015. An investigation of systemic stress and interdependencies within the Eurozone and Euro Area countries. Economic Modelling 48 , pp. 52-69. 10.1016/j.econmod.2014.10.023 file Publishers page: https://doi.org/10.1016/j.econmod.2014.10.023 <https://doi.org/10.1016/j.econmod.2014.10.023> Please note: Changes made as a result of publishing processes such as copy-editing, formatting and page numbers may not be reflected in this version. For the definitive version of this publication, please refer to the published source. You are advised to consult the publisher’s version if you wish to cite this paper. This version is being made available in accordance with publisher policies. See http://orca.cf.ac.uk/policies.html for usage policies. Copyright and moral rights for publications made available in ORCA are retained by the copyright holders. An Investigation of Systemic Stress and Interdependencies within the Eurozone and Euro Area Countries Ronald MacDonald# Vasilios Sogiakas& Andreas Tsopanakis§ University of Glasgow University of Glasgow University of Salford Abstract One of the most challenging issues that economists are dealing with is the investigation of the financial turmoil in Eurozone economies. Particularly, the issue of exposing the potential crisis transmission channels has attracted considerable interest. Aiming to contribute to this literature, we construct financial stress indices on a country level and explore further the potential inter-reactions between the source causes of systemic risk. -
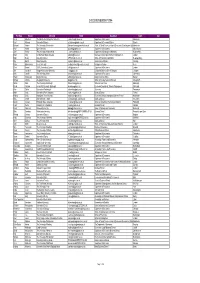
Chude Member¾ 嗖
CHUDE MEMBERSHIP 2014 First Name Surname University E-Mail Department Town Sign Kevin Albertson The Manchester Metropolitan University [email protected] Department of Economics Manchester Paul Allanson University of Dundee [email protected] Department of Economic Studies Dundee Edmund Amann The University of Manchester [email protected] School of Social Sciences, Head of Economics (Teaching and Operations)Manchester Paul Anand Open University [email protected] Department of Economics Milton Keynes John Anchor The University of Huddersfield [email protected] Department of Strategy and Marketing Huddersfield Brian Ardy London South Bank University [email protected] Business, Computing & Information Management. London Mark Bailey University of Ulster [email protected] School of Economics and Politics Newtownabbey Ray Barrell Brunel University [email protected] Economics and Finance Uxbridge Robin Bladen-Hovell Keele University [email protected] Management School Keele Chris Bramall SOAS, University of London [email protected] Department of Economics London Jim Campbell Glasgow Caledonian University [email protected] Caledonian Business School Glasgow Glasgow Alan Carruth The University of Kent [email protected] Department of Economics Canterbury Shanti Chakravarty Bangor University [email protected] Bangor Business School Bangor Michael Christie Aberystywth University [email protected] School of Management and Business Aberystwyth Simon Clark The University of Edinburgh [email protected]