Predicting Vulnerabilities in Computer-Supported Inferential Analysis Under Data Overload (Accepted for Publication in Cognition, Technology, and Work)
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Ariane-5 Completes Flawless Third Test Flight
r bulletin 96 — november 1998 Ariane-5 Completes Flawless Third Test Flight A launch-readiness review conducted on Friday engine shut down and Maqsat-3 was 16 and Monday 19 October had given the go- successfully injected into GTO. The orbital ahead for the final countdown for a launch just parameters at that point were: two days later within a 90-minute launch Perigee: 1027 km, compared with the window between 13:00 to 14:30 Kourou time. 1028 ± 3 km predicted The launcher’s roll-out from the Final Assembly Apogee: 35 863 km, compared with the Building to the Launch Zone was therefore 35 898 ± 200 km predicted scheduled for Tuesday 20 October at 09:30 Inclination: 6.999 deg, compared with the Kourou time. 6.998 ± 0.05 deg predicted. On 21 October, Europe reconfirmed its lead in providing space Speaking in Kourou immediately after the flight, transportation systems for the 21st Century. Ariane-5, on its third Fredrik Engström, ESA’s Director of Launchers qualification flight, left no doubts as to its ability to deliver payloads and the Ariane-503 Flight Director, confirmed reliably and accurately to Geostationary Transfer Orbit (GTO). The new that: “The third Ariane-5 flight has been a heavy-lift launcher lifted off in glorious sunshine from the Guiana complete success. It qualifies Europe’s new Space Centre, Europe’s spaceport in Kourou, French Guiana, at heavy-lift launcher and vindicates the 13:37:21 local time (16:37:21 UT). technological options chosen by the European Space Agency.” This third Ariane-5 test flight was intended ESA’s Director -

Call for M5 Missions
ESA UNCLASSIFIED - For Official Use M5 Call - Technical Annex Prepared by SCI-F Reference ESA-SCI-F-ESTEC-TN-2016-002 Issue 1 Revision 0 Date of Issue 25/04/2016 Status Issued Document Type Distribution ESA UNCLASSIFIED - For Official Use Table of contents: 1 Introduction .......................................................................................................................... 3 1.1 Scope of document ................................................................................................................................................................ 3 1.2 Reference documents .......................................................................................................................................................... 3 1.3 List of acronyms ..................................................................................................................................................................... 3 2 General Guidelines ................................................................................................................ 6 3 Analysis of some potential mission profiles ........................................................................... 7 3.1 Introduction ............................................................................................................................................................................. 7 3.2 Current European launchers ........................................................................................................................................... -

6. the INTELSAT 17 Satellite
TWO COMMUNICATIONS SATELLITES READY FOR LAUNCH Arianespace will orbit two communications satellite on its fifth launch of the year: INTELSAT 17 for the international satellite operator Intelsat, and HYLAS 1 for the European operator Avanti Communications. The choice of Arianespace by leading space communications operators and manufacturers is clear international recognition of the company’s excellence in launch services. Based on its proven reliability and availability, Arianespace continues to confirm its position as the world’s benchmark launch system. Ariane 5 is the only commercial satellite launcher now on the market capable of simultaneously launching two payloads. Arianespace and Intelsat have built up a long-standing relationship based on mutual trust. Since 1983, Arianespace has launched 48 satellites for Intelsat. Positioned at 66 degrees East, INTELSAT 17 will deliver a wide range of communication services for Europe, the Middle East, Russia and Asia. Built by Space Systems/Loral of the United States, this powerful satellite will weigh 5,540 kg at launch. It will also enable Intelsat to expand its successful Asian video distrubution neighborhood. INTELSAT 17 will replace INTELSAT 702. HYLAS 1 is Avanti Communications’ first satellite. A new European satellite operator, Avanti Communications also chose Arianespace to orbit its HYLAS 2 satellite, scheduled for launch in the first half of 2012. HYLAS 1 was built by an industrial consortium formed by EADS Astrium and the Indian Space Research Organisation (ISRO), using a I-2K platform. Fitted with Ka-band and Ku-band transponders, the satellite will be positioned at 33.5 degrees West, and will be the first European satellite to offer high-speed broadband services across all of Europe. -

Astronomy & Astrophysics a Hipparcos Study of the Hyades
A&A 367, 111–147 (2001) Astronomy DOI: 10.1051/0004-6361:20000410 & c ESO 2001 Astrophysics A Hipparcos study of the Hyades open cluster Improved colour-absolute magnitude and Hertzsprung{Russell diagrams J. H. J. de Bruijne, R. Hoogerwerf, and P. T. de Zeeuw Sterrewacht Leiden, Postbus 9513, 2300 RA Leiden, The Netherlands Received 13 June 2000 / Accepted 24 November 2000 Abstract. Hipparcos parallaxes fix distances to individual stars in the Hyades cluster with an accuracy of ∼6per- cent. We use the Hipparcos proper motions, which have a larger relative precision than the trigonometric paral- laxes, to derive ∼3 times more precise distance estimates, by assuming that all members share the same space motion. An investigation of the available kinematic data confirms that the Hyades velocity field does not contain significant structure in the form of rotation and/or shear, but is fully consistent with a common space motion plus a (one-dimensional) internal velocity dispersion of ∼0.30 km s−1. The improved parallaxes as a set are statistically consistent with the Hipparcos parallaxes. The maximum expected systematic error in the proper motion-based parallaxes for stars in the outer regions of the cluster (i.e., beyond ∼2 tidal radii ∼20 pc) is ∼<0.30 mas. The new parallaxes confirm that the Hipparcos measurements are correlated on small angular scales, consistent with the limits specified in the Hipparcos Catalogue, though with significantly smaller “amplitudes” than claimed by Narayanan & Gould. We use the Tycho–2 long time-baseline astrometric catalogue to derive a set of independent proper motion-based parallaxes for the Hipparcos members. -

Atlas Launch System Mission Planner's Guide, Atlas V Addendum
ATLAS Atlas Launch System Mission Planner’s Guide, Atlas V Addendum FOREWORD This Atlas V Addendum supplements the current version of the Atlas Launch System Mission Plan- ner’s Guide (AMPG) and presents the initial vehicle capabilities for the newly available Atlas V launch system. Atlas V’s multiple vehicle configurations and performance levels can provide the optimum match for a range of customer requirements at the lowest cost. The performance data are presented in sufficient detail for preliminary assessment of the Atlas V vehicle family for your missions. This guide, in combination with the AMPG, includes essential technical and programmatic data for preliminary mission planning and spacecraft design. Interface data are in sufficient detail to assess a first-order compatibility. This guide contains current information on Lockheed Martin’s plans for Atlas V launch services. It is subject to change as Atlas V development progresses, and will be revised peri- odically. Potential users of Atlas V launch service are encouraged to contact the offices listed below to obtain the latest technical and program status information for the Atlas V development. For technical and business development inquiries, contact: COMMERCIAL BUSINESS U.S. GOVERNMENT INQUIRIES BUSINESS INQUIRIES Telephone: (691) 645-6400 Telephone: (303) 977-5250 Fax: (619) 645-6500 Fax: (303) 971-2472 Postal Address: Postal Address: International Launch Services, Inc. Commercial Launch Services, Inc. P.O. Box 124670 P.O. Box 179 San Diego, CA 92112-4670 Denver, CO 80201 Street Address: Street Address: International Launch Services, Inc. Commercial Launch Services, Inc. 101 West Broadway P.O. Box 179 Suite 2000 MS DC1400 San Diego, CA 92101 12999 Deer Creek Canyon Road Littleton, CO 80127-5146 A current version of this document can be found, in electronic form, on the Internet at: http://www.ilslaunch.com ii ATLAS LAUNCH SYSTEM MISSION PLANNER’S GUIDE ATLAS V ADDENDUM (AVMPG) REVISIONS Revision Date Rev No. -

Planned Yet Uncontrolled Re-Entries of the Cluster-Ii Spacecraft
PLANNED YET UNCONTROLLED RE-ENTRIES OF THE CLUSTER-II SPACECRAFT Stijn Lemmens(1), Klaus Merz(1), Quirin Funke(1) , Benoit Bonvoisin(2), Stefan Löhle(3), Henrik Simon(1) (1) European Space Agency, Space Debris Office, Robert-Bosch-Straße 5, 64293 Darmstadt, Germany, Email:[email protected] (2) European Space Agency, Materials & Processes Section, Keplerlaan 1, 2201 AZ Noordwijk, Netherlands (3) Universität Stuttgart, Institut für Raumfahrtsysteme, Pfaffenwaldring 29, 70569 Stuttgart, Germany ABSTRACT investigate the physical connection between the Sun and Earth. Flying in a tetrahedral formation, the four After an in-depth mission analysis review the European spacecraft collect detailed data on small-scale changes Space Agency’s (ESA) four Cluster II spacecraft in near-Earth space and the interaction between the performed manoeuvres during 2015 aimed at ensuring a charged particles of the solar wind and Earth's re-entry for all of them between 2024 and 2027. This atmosphere. In order to explore the magnetosphere was done to contain any debris from the re-entry event Cluster II spacecraft occupy HEOs with initial near- to southern latitudes and hence minimise the risk for polar with orbital period of 57 hours at a perigee altitude people on ground, which was enabled by the relative of 19 000 km and apogee altitude of 119 000 km. The stability of the orbit under third body perturbations. four spacecraft have a cylindrical shape completed by Small differences in the highly eccentric orbits of the four long flagpole antennas. The diameter of the four spacecraft will lead to various different spacecraft is 2.9 m with a height of 1.3 m. -

Design by Contract: the Lessons of Ariane
. Editor: Bertrand Meyer, EiffelSoft, 270 Storke Rd., Ste. 7, Goleta, CA 93117; voice (805) 685-6869; [email protected] several hours (at least in earlier versions of Ariane), it was better to let the computa- tion proceed than to stop it and then have Design by to restart it if liftoff was delayed. So the SRI computation continues for 50 seconds after the start of flight mode—well into the flight period. After takeoff, of course, this com- Contract: putation is useless. In the Ariane 5 flight, Object Technology however, it caused an exception, which was not caught and—boom. The exception was due to a floating- point error during a conversion from a 64- The Lessons bit floating-point value, representing the flight’s “horizontal bias,” to a 16-bit signed integer: In other words, the value that was converted was greater than what of Ariane can be represented as a 16-bit signed inte- ger. There was no explicit exception han- dler to catch the exception, so it followed the usual fate of uncaught exceptions and crashed the entire software, hence the onboard computers, hence the mission. This is the kind of trivial error that we Jean-Marc Jézéquel, IRISA/CNRS are all familiar with (raise your hand if you Bertrand Meyer, EiffelSoft have never done anything of this sort), although fortunately the consequences are usually less expensive. How in the world everal contributions to this made up of respected experts from major department have emphasized the European countries, which produced a How in the world could importance of design by contract report in hardly more than a month. -

Rumba, Salsa, Smaba and Tango in the Magnetosphere
ESCOUBET 24-08-2001 13:29 Page 2 r bulletin 107 — august 2001 42 ESCOUBET 24-08-2001 13:29 Page 3 the cluster quartet’s first year in space Rumba, Salsa, Samba and Tango in the Magnetosphere - The Cluster Quartet’s First Year in Space C.P. Escoubet & M. Fehringer Solar System Division, Space Science Department, ESA Directorate of Scientific Programmes, Noordwijk, The Netherlands P. Bond Cranleigh, Surrey, United Kingdom Introduction Launch and commissioning phase Cluster is one of the two missions – the other When the first Soyuz blasted off from the being the Solar and Heliospheric Observatory Baikonur Cosmodrome on 16 July 2000, we (SOHO) – constituting the Solar Terrestrial knew that Cluster was well on the way to Science Programme (STSP), the first recovery from the previous launch setback. ‘Cornerstone’ of ESA’s Horizon 2000 However, it was not until the second launch on Programme. The Cluster mission was first 9 August 2000 and the proper injection of the proposed in November 1982 in response to an second pair of spacecraft into orbit that we ESA Call for Proposals for the next series of knew that the Cluster mission was truly back scientific missions. on track (Fig. 1). In fact, the experimenters said that they knew they had an ideal mission only The four Cluster spacecraft were successfully launched in pairs by after switching on their last instruments on the two Russian Soyuz rockets on 16 July and 9 August 2000. On 14 fourth spacecraft. August, the second pair joined the first pair in highly eccentric polar orbits, with an apogee of 19.6 Earth radii and a perigee of 4 Earth radii. -

Study of a 100Kwe Space Reactor for Exploration Missions
Preliminary study of a 100 kWe space reactor concept for exploration missions Elisa CLIQUET, Jean-Marc RUAULT 1), Jean-Pierre ROUX, Laurent LAMOINE, Thomas RAMEE 2), Christine POINOT-SALANON, Alexey LOKHOV, Serge PASCAL 3) 1) CNES Launchers Directorate,Evry, France 2) AREVA TA, Aix en Provence, France 3) CEA DEN/DM2S, F-91191 Gif-sur-Yvette, France NETS 2011 Overview ■ General context of the study ■ Requirements ■ Methodology of the study ■ Technologies selected for final trade-off ■ Reactor trade-off ■ Conversion trade-off ■ Critical technologies and development philosophy ■ Conclusion and perspectives CNES Directorate of Launchers Space transportation division of the French space agency ■ Responsible for the development of DIAMANT, ARIANE 1 to 4, ARIANE 5, launchers ■ System Architect for the Soyuz at CSG program ■ Development of VEGA launcher first stage (P80) ■ Future launchers preparation activities Multilateral and ESA budgets • To adapt the current launchers to the needs for 2015-2020 • To prepare launcher evolutions for 2025 - 2030, if needed • To prepare the new generation of expandable launchers (2025-2030) • To prepare the long future after 2030 with possible advanced launch vehicles ■ Future space transportation prospective activities, such as Exploration needs (including in particular OTV missions) Advanced propulsion technologies investigation General context ■ Background Last French studies on space reactors : • ERATO (NEP) in the 80’s, • MAPS (NTP) in the 90’s • OPUS (NEP) 2002-2004 ■ Since then Nuclear safe orbit -
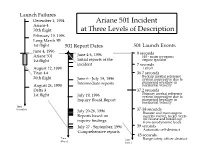
Ariane 501 Incident at Three Levels of Description
Launch Failures! December 1, 1994! Ariane 501 Incident " Ariane 4 ! 70th flight! at Three Levels of Description! February 19, 1996! Long March 3B ! 1st flight! 501 Report Dates! 501 Launch Events! June 4, 1996! 0 seconds! Ariane 501 ! June 4-6, 1996! H0 - main cryogenic ! 1st flight! Initial reports of the ! engine ignition! incident! 7 seconds! August 12, 1998! Liftoff! Titan 4A ! 36.7 seconds! Backup inertial reference ! 20th flight! June 6 - July 19, 1996! system inoperative due to ! Intermediate reports! numerical overflow in ! August 26, 1998! horizontal velocity! Delta 3 ! 37.2 seconds! Primary inertial reference ! 1st flight ! July 19, 1996! system inoperative due to ! Inquiry Board Report! numerical overflow in ! horizontal velocity! Time! (months)! 37-38 seconds! July 20-26, 1996! Booster and main engine ! Reports based on ! nozzles swivel, rocket veers ! off course and breaks up ! inquiry findings! from aerodynamic loads ! July 27 - September, 1996! 39 seconds! Automatic self-destruct ! Comprehensive reports ! 45 seconds! Time! Time! Range safety officer destruct ! (days)! (secs.)! “High Profit” Documents! Ariane 5 Flight 501 Failure: Report by the Inquiry Board (July 19, 1996)! Inertial Reference Software Error Blamed for Ariane 5 Failure; Defense !Daily (July 24, 1996) ! !!! Software Design Flaw Destroyed Ariane 5; next flight in 1997; ! !Aerospace Daily (July 24, 1996) ! !! Ariane 5 Rocket Faces More Delay; The Financial Times Limited ! !(July 24, 1996) ! Flying Blind: Inadequate Testing led to the Software Breakdown that !Doomed Ariane -

European Space Agency Announces Contest to Name the Cluster Quartet
European Space Agency Announces Contest to Name the Cluster Quartet. 1. Contest rules The European Space Agency (ESA) is launching a public competition to find the most suitable names for its four Cluster II space weather satellites. The quartet, which are currently known as flight models 5, 6, 7 and 8, are scheduled for launch from Baikonur Space Centre in Kazakhstan in June and July 2000. Professor Roger Bonnet, ESA Director of Science Programme, announced the competition for the first time to the European Delegations on the occasion of the Science Programme Committee (SPC) meeting held in Paris on 21-22 February 2000. The competition is open to people of all the ESA member states. Each entry should include a set of FOUR names (places, people, or things from his- tory, mythology, or fiction, but NOT living persons). Contestants should also describe in a few sentences why their chosen names would be appropriate for the four Cluster II satellites. The winners will be those which are considered most suitable and relevant for the Cluster II mission. The names must not have been used before on space missions by ESA, other space organizations or individual countries. One winning entry per country will be selected to go to the Finals of the competition. The prize for each national winner will be an invitation to attend the first Cluster II launch event in mid-June 2000 with their family (4 persons) in a 3-day trip (including excursions to tourist sites) to one of these ESA establishments: ESRIN (near Rome, Italy): winners from France, Ireland, United King- dom, Belgium. -

Building and Maintaining the International Space Station (ISS)
/ Building and maintaining the International Space Station (ISS) is a very complex task. An international fleet of space vehicles launches ISS components; rotates crews; provides logistical support; and replenishes propellant, items for science experi- ments, and other necessary supplies and equipment. The Space Shuttle must be used to deliver most ISS modules and major components. All of these important deliveries sustain a constant supply line that is crucial to the development and maintenance of the International Space Station. The fleet is also responsible for returning experiment results to Earth and for removing trash and waste from the ISS. Currently, transport vehicles are launched from two sites on transportation logistics Earth. In the future, the number of launch sites will increase to four or more. Future plans also include new commercial trans- ports that will take over the role of U.S. ISS logistical support. INTERNATIONAL SPACE STATION GUIDE TRANSPORTATION/LOGISTICS 39 LAUNCH VEHICLES Soyuz Proton H-II Ariane Shuttle Roscosmos JAXA ESA NASA Russia Japan Europe United States Russia Japan EuRopE u.s. soyuz sL-4 proton sL-12 H-ii ariane 5 space shuttle First launch 1957 1965 1996 1996 1981 1963 (Soyuz variant) Launch site(s) Baikonur Baikonur Tanegashima Guiana Kennedy Space Center Cosmodrome Cosmodrome Space Center Space Center Launch performance 7,150 kg 20,000 kg 16,500 kg 18,000 kg 18,600 kg payload capacity (15,750 lb) (44,000 lb) (36,400 lb) (39,700 lb) (41,000 lb) 105,000 kg (230,000 lb), orbiter only Return performance