Machine Learning Models for Educational Platforms
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Staff Guide to Google Classroom
Staff Guide to Google Classroom Preston Lodge High School March 2018 Preston Lodge High School Connected Learning Contents Logging in 3 Setting up Google Classroom on your mobile device 4 Google Classroom main pages 5 Creating a class 6 Invite other teachers to a class 6 Archiving and deleting classes 7 Adding students to your class 8 Making an announcement 9 Sharing resources with your classes 10 Creating Assignments 13 Marking assignments 14 Annotating pupil assignments on mobile devices 15 Creating a Question 16 Using Google forms for surveys and assignments 18 Checking responses from Google Forms 21 Reuse a post 22 Communicating with guardians / parents 23 Using Google classroom as a markbook 24 Getting more help 25 Gareth Evans Staff Guide to Google Classroom Page 2 / 26 Preston Lodge High School Connected Learning Logging in To make use of Google Classroom, you need to login to Google using your Edubuzz account. Personal Google Accounts (such as your home @gmail.com account) will not have access to GApps for Education, which includes Google Classroom. Most browsers are compatible with Google Classroom, although Google Chrome is highly recommend. You will find this in the Applications folder on the Desktop of your school computer. Once opened, you can pin it to the taskbar (bar at the bottom of a Windows PC) by right clicking on the icon as selecting Pin this program to taskbar. Internet Explorer, the default browser on school PCs, isn’t the best browser for Google Apps. You can login to Google by visiting http://www.google.com and selecting the Sign in button at the top right of the screen. -

What Is Google Classroom? Google Classroom Is a Class-Organization
What is Google Classroom? Google Classroom is a class-organization platform that incorporates Google's core G Suite (Google Docs, Sheets, Slides, Drive, and other Google products) so students can access everything they need for a class, including assignments, projects, and files. Can my child use a mobile device or tablet to access Google classroom? Absolutely. Like all the other Google apps available, your student can access the full functionality of Google Classroom from virtually any device. How tech savvy do I need to be to help my kid with Google Classroom? If your kids are younger, it's probably a good idea to have some familiarity with Google's G Suite so you can help your kid upload documents, check the calendar, and do other tasks. It also helps to know how the programs work so you can at least describe the problem to a teacher if anything goes wrong. Older kids may not need any help. Google Classroom is designed to be easy to use, and there's lots of online help. How do we get started? The process for setting up your child's account is pretty simple. BCCS sets up the classrooms and invites all students to the right classes. All they have to do is accept the invite. Your child can get into their classroom anytime by going to classroom.google.com. Students may have multiple classrooms for different classes. From their dashboard, they can choose the class they want to view. Once they enter a classroom, students find four tabs at the top of the page. -

Social Studies Classroom Google Maps and Apps to Improve Student Learning
Social Studies Classroom Google Maps and Apps to Improve Student Learning Andrew San Angelo Newtown Middle School Newtown Connecticut Today’s Agenda O Google Classroom O Google Slides and Classroom O Google Map Investigation O Peardeck and Google Classroom O Questions O Making of ... Please join my Google Classroom h8wpad Google Slides How to Analyze Political Cartoons Observe Reflect Question How to Analyze Political Cartoons Observe Reflect Question The Star Spangled Banner Oh, say, can you see, by the dawn's early light, What so proudly we hailed at the twilight's last gleaming? Whose broad stripes and bright stars, thro' the perilous fight; O'er the ramparts we watched, were so gallantly streaming. And the rockets red glare, the bombs bursting in air, Gave proof through the night that our flag was still there. Oh, say, does that star-spangled banner yet wave O'er the land of the free and the home of the brave? The Star Spangled Banner Oh, say, can you see, by the _______, What so happy we met at the ______________? Whose wide stripes and _______, thro' the ____ fight; O'er the walls we watched, were so boldly flowing? And the rockets red flash, the bombs exploding in sky, Gave evidence through the evening that our flag was still there. Oh, say, does that colored flag yet flap O'er the land of the free and the house of the heroic? The Star Spangled Banner Oh, say, can you see, by the dawn's early light, What so proudly we hailed at the twilight's last gleaming? Whose broad stripes and bright stars, thro' the perilous fight; O'er the ramparts we watched, were so gallantly streaming. -

Google-Classsroom-FAQ.Pdf
FAQ’s Install Google Classroom on Android devices To use Classroom on your Android device, download the Classroom app from Google Play. 1. On your device, tap Google Play Store. 2. Find and install the Google Classroom app. Install Google Classroom on an iPhone To use Classroom on your iPhone® or iPad®, download the Classroom app from the App Store. 1. On your device, tap App Store. 2. Find and install the Google Classroom app. FAQ’s Sign in for the first time 1. Tap Classroom 2. Tap Get Started. 3. Tap Add account. 4. Enter your students email address and password (Passwords cannot be changed) 5. Enter your password and tap Next. 6. If there is a welcome message, read it and tap Accept. FAQ’s 7. Once logged into Google Classroom you will see a screen, similar to the below, that will list the classes your child has and grade level announcements. 8. To access homework for a particular class just click in that particular classroom. FAQ’s Sign in daily 1. Tap Classroom 2. To log into Google Classroom to check your student’s progress daily, enter your students email address and password (Passwords will be provided to you by your teacher and CANNOT be changed) 3. Once logged into Google Classroom you will see a screen, similar to the below, that will list the classes your child has and grade level announcements. 4. To access homework for a particular class just click in that particular classroom. FAQ’s How to log on from your home computer 1. -
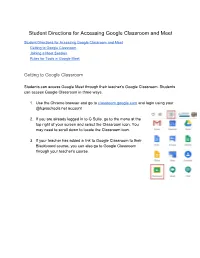
Student Directions for Accessing Google Classroom and Meet
Student Directions for Accessing Google Classroom and Meet Student Directions for Accessing Google Classroom and Meet Getting to Google Classroom Joining a Meet Session Rules for Tools in Google Meet Getting to Google Classroom Students can access Google Meet through their teacher’s Google Classroom. Students can access Google Classroom in three ways. 1. Use the Chrome browser and go to classroom.google.com and login using your @fcpsschools.net account 2. If you are already logged in to G Suite, go to the menu at the top right of your screen and select the Classroom icon. You may need to scroll down to locate the Classroom icon. 3. If your teacher has added a link to Google Classroom to their Blackboard course, you can also go to Google Classroom through your teacher’s course. Joining a Meet Session Once logged into your teacher’s Google Classroom, there are two ways to join a Meet Session 1. Click the link in the Course Banner 2. Go to the Classwork tab and click the Meet icon. If you do not see the above options, your teacher has not enabled Google Meet in their Google Classroom. Rules for Tools in Google Meet Audio: ● Enter Meet with your audio turned off. ● Turn on the microphone when called on and turn it off when you finish speaking. Chat: ● Use kind and appropriate language and images. Video: ● Enter Meet with your video off. ● Follow your teacher’s directions on whether to turn on your video; however, students always have the option to keep their camera turned off. -

STEM School Approved Apps & Websites
Last Updated 8/22/2020 Resource Name Privacy Policy Terms of Service Notes For school-based activities, teachers and school administrators can act in the place of parents to provide consent for the collection of personal data from children. Schools should always notify parents about these activities. 3DS Max (Autodesk) Privacy Policy Children's Privacy 7zip Terms no need to register or enter personal info to use Abcya Privacy Policy Terms The Platform does not require Children to provide their name, address, or other contact information in order to play games. Ableton Music Software Privacy Policy Trial requires account/some personal details Schools that participate in the primary and secondary education named user offering may issue a child under 13 an enterprise-level Adobe ID, Adobe products Privacy Policy [1] Terms [2] but only after obtaining express parental consent. The personal information you provide will be used for the purpose for which it was provided - to contact you, to process an order, to Advanced IP Scanner Privacy Policy register your product Advanced Port Scanner Privacy Policy Advent of code Terms "uses OAuth to confirm your identity through other services, this reveals no information about you beyond what is already public" Affinity Photo & Designer Privacy Policy Terms Affinity Privacy Letter If you are a teacher interested in using Albert with children under 13, please contact us at [email protected] and we will work with albert.io Privacy Policy Terms you toward a school license and collecting the necessary parental consents. allsides.org Privacy Policy Terms Website directed at 13 and older. -

Google Classroom Is a Class-Organization Platform That
What is Google Classroom? Google Classroom is a class-organization platform that incorporates Google's core G Suite (Google Docs, Sheets, Slides, Drive, and other Google application) so students can access everything they need for a class, assignments, group projects, files, and Google Hangouts Meet with the teacher or the entire class. Why we use Google Classroom? ● Google Classroom allows for assignments to be shared with individuals, groups of students, or whole classes to allow for personalization and differentiation within the one classroom page. ● Families will only have ONE platform to locate assignments for all their K-12 students. Families have indicated that the number of emails for their students and families have been overwhelming. In some cases, students are receiving multiple emails from multiple educators in different places. ● Students can “turn in” assignments virtually, and teachers can provide feedback to their students individually. ● Google Classroom protects student privacy because it is linked to Melrose Public Schools accounts. Platforms must be COPPA and PPRA compliant by federal law. ● Google Classroom can be easily translated for students and families. (You can either use the Google Translate extension or just alt-click on the actual page to choose the language-there are dozens!) What about students in grades K-2? ● All students including those in grades K-2 have successfully learned to navigate the use of Google Classroom this year in their Digital Literacy classrooms. Students have shown proficiency in opening the platform and navigating multiple assignments. As we progress, we will adjust and support students and families to navigate the platform. -
Google Classroom Assignment Template
LINK TO YOUTUBE PLAYLIST CLICK HERE FOR MY ASSIGNMENT TEMPLATE - File → Make a Copy to save to your drive! TEMPLATE: Accomodation Summary Spreadsheet File → Make a Copy to save to your drive! Tutorials for Students ● Logging into Google Classroom ● Joining a Class Using Google Classroom ● Completing Assignments on Google Classroom ● Google Docs: Basic Editing and Inserting Pictures Day Time Topic Zoom Link YouTube Links Introduction Video Using your Recording of Training Part I Using Multiple Google Accounts on 10:00 AM Chromebook and the Same Device Setting Up "Master" Recording of Training Part II Folders in Shared Setting Up and Using Shared Drives Drive https://zoom.us/j/392656912 (Master Copies) Monday Google Classroom: Set-Up (BASIC) Recording of Training Part I Google Classroom: Creating 2:00 PM Setting Up Google Assignments (BASIC) Classroom and Recording of Training Part II Creating Basic Google Classroom: Creating Assignments https://zoom.us/j/304697809 Materials (BASIC) Google Classroom: Adding a Co-Teacher (BASIC) Google Classroom: Assigning Different Versions of Assessments Within the Same Class (BASIC) Google Classroom: Assigning Different Versions of Assessments 10:00 AM Within the Same Class (ADVANCED) Tuesday Setting Up and Using Shared Drives (Master Copies) TEMPLATE: Accommodation Collaboration and Summary Spreadsheet Differentiation Using Google Classroom https://zoom.us/j/333119649 Assessments and Google Classroom: Grading (BASIC) 2:00 PM Google Classroom: Types of https://zoom.us/j/962156283 Google Classroom: -

Family Guide to Google Classroom
Family Guide to Google Classroom What is Google Classroom Google Classroom is a secure platform that teachers will use to organize and send schoolwork to your children during this time of remote education. You also can send work back to teachers on the same platform. Use this guide to learn how to get into Google Classroom and submit assignments. If you have trouble logging in to Google Classroom, you can use this website https://theveeya.com/GreatHeartsFamilyHelp/ to submit questions. For questions about individual classes, reach out to your student’s teacher. Table of Contents Setting Up Google Classroom for the First Time ........................................................................................... 2 Navigating Google Classroom ........................................................................................................................ 3 Submitting an Assignment from Your Computer .......................................................................................... 4 Submitting an Assignment from Google Classroom App .............................................................................. 5 Scanning/Saving Paper Worksheets Using a Mobile Device ......................................................................... 6 Using Android or iPhone (using Google Classroom app) ........................................................................... 6 Using iPhone/iPad (using iCloud app) ....................................................................................................... 7 Using iPhone/iPad -

Instructions for Google Classroom, Google Meet, Organizing Email, and Taking Pictures
Instructions for Google Classroom, Google Meet, Organizing Email, and Taking Pictures How to log into Google and Google Classroom from your home computer or laptop 1. Click on the Chrome icon on your computer. 2. If you have not signed into your Google account, go to the upper right hand corner and click sign in. If you are already signed in, make sure it is your school account - not your personal account by clicking on the circle in the top right corner. 3. Sign in with your school email. You should be able to use your password from last year. If you are new to the district or have a new account, use your lunch code the first time you log in. Your username should be your first initial, last name, and graduation year followed by @k12.catskillcsd.org. 4. Once you are logged into Google, click the waffle. 5. Click on the Google Classroom icon. 6. Once you are in Google Classroom you will see your classes as your teachers add them. How to log into Google Classroom on your Chromebook 1. Log into the Chromebook using your school email and password. Your username should be your first initial, last name, and graduation year followed by @k12.catskillcsd.org. If you are new to the district or have a new account, use your lunch code the first time you log in. 2. Once you have logged into your Chromebook, click on the Google Classroom icon on the bottom of the screen. 3. Once you are in Google Classroom you will see your classes as your teachers add them. -

Going Google Means Adopting a Culture That Extends
“Going Google means adopting a culture that extends beyond the classroom: it’s about openness, curiosity, and working together.“ —Jim Sill - Educator & Trainer, Visalia, California google.com/edu Table of Contents Google Apps for Education Overview . 5 Classroom Overview . 7 Chromebooks for Education Overview . 9 Chromebooks for Education Management Console Overview . 10 Android tablets for education . 11 Google Play for Education . 13 Google Apps Case Studies Littleton Public Schools uses Google AppsColorado as a modern learning engine . Colorado . 17 St . Albans City School builds connectionsVermont between students and community using Google for Education . Vermont . .. 19 Fontbonne Hall Academy empowers teachers with Classroom, a new product in Google Apps for Education . New York . 22 Chromebooks Case Studies Edmonton Public Schools improves collaboration and writing skills with Google for Education tools . Canada . 24 Milpitas Unified School District helps students take charge of learning using Google for Education tools . California . 27 Huntsville Independent School District helps close the digital divide with Google Chromebooks and Apps . Texas . 30 Android Tablets Case Studies Challenge to Excellence Charter School students explore the world using Android tablets with Google Play for Education . Colorado . 31 Upper Grand School District turns to Android tablets and Google Play for Education to teach students anytime anywhere . Vermont . .. 34 Mounds View schools boost student preparedness with all-day kindergarten using Android tablets with Google Play for Education . Minnesota . 37 Google Apps for Education Tools that build teamwork and enhance learning Google Apps for Education is a free set of communication and collaboration tools that includes email, calendar, and documents. More than 40 million students, teachers, and administrators in schools around the world use Google Apps for Education. -

Using Google Classroom on a Phone
School City of Hobart eLearning Using Google Classroom on a Phone Know you'll be assigned something in Google Classroom and want to use your phone to access it and submit? There’s an app for that. Here’s how it works! Step 1: Download the Google Classroom App! As a teacher or student, you can install the Classroom app on an Android, Apple® iOS®, or Chrome OS mobile device. The Classroom app is not available on Windows® mobile devices. On your computer’s browser, you can just sign in to Classroom Android iOs ChromeOS To use Classroom on your To use Classroom on your The Classroom app for iPhone® or iPad®, download the Android device, download the Classroom app from the App Chrome OS works like a Classroom app from Google Store. bookmark to the web version Play. of Classroom. 1. On your device, tap 1. On your device, tap 1. You can download it App Store. Google Play Store. 2. Find and install the from the Chrome Web 2. Find and install the Store. Google Classroom Google Classroom app. app. All my life I want to be a Brickie. Work! Work! Work! Step 2: Open the app and click “Get Started” to login to your account. Students will need to sign in with the school-provided gmail account. Your screen will look similar to this one: Step 3: Students will see all of their classes on the screen. A student can click on a class to go to it, or a student can click on the 4 vertical lines in the top right hand corner to see a list of the classes they’re enrolled in - these will automatically transfer over if the same school gmail account is used.