An Analysis of Indexing Consistency and Quality by Y
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

SCONUL Focus Number 38 Summer/Autumn 2006
SCONUL Focus Number 38 Summer/Autumn 2006 Contents ISSN 1745-5782 (print) ISSN 1745-5790 (online) 3 The 3Ss 4 The Learning Grid at the University of Warwick: a library innovation to support learning in higher education Rachel Edwards 8 The Learning Gateway: opening the doors to a new generation of learners at St Martin’s College, Carlisle campus Margaret Weaver 11 Middlesex University: the impressive rejuvenation of Hendon campus Paul Beaty-Pownall 14 Poor design equals poor health questionnaire: the final results Jim Jackson 20 Human resourcing in academic libraries: the ‘lady librarian’, the call for flexible staff and the need to be counted A. D. B. MacLean, N. C. Joint 26 Taking steps that make you feel dizzy: personal reflections on module 1 of the Future Leaders programme John Cox, Annie Kilner, Dilys Young 30 Evolution: the Oxford trainee scheme Gill Powell, Katie Robertson 34 A week in the life Kim McGowan 36 Got the knowledge? Focusing on the student: Manchester Metropolitan University’s (MMU) library welcome campaign David Matthews, Emily Shields, Rosie Jones, Karen Peters 41 Ask the audience: e-voting at the University of Leeds Lisa Foggo, Susan Mottram, Sarah Taylor 44 Information literacy, the link between second and tertiary education: project origins and current developments Christine Irving 47 Review of how libraries are currently supporting the research process Ruth Stubbings, Joyce Bartlett, Sharon Reid 51 Researchers, information and libraries: the CONUL national research support survey John Cox 55 Creating a new Social Science Library at Oxford University based on reader consultation Louise Clarke 58 The use of personal scanners and digital cameras within OULS reading rooms Steve Rose, Gillian Evison 60 Copyright, digital resources and IPR at Brunel University Monique Ritchie 64 Secure electronic delivery: ‘get the world’s knowledge with less waiting’ Alison E. -

SCONUL Focus Number 41 Summer/Autumn 2007
SCONUL Focus Number 41 Summer/Autumn 2007 Contents ISSN 1745-5782 (print) ISSN 1745-5790 (online) 3 Widening your networking 4 The future of librarianship: Lorna Dodd 8 From librarian to lecturer: Helen Fallon, Mairead McQuaid 12 Subject liaison at Lincoln Philippa Dyson 15 A new ERA? Marketing and delivering a user-education event for academic staff Darren Taylor 19 Making more of your coffee time – just add hot water Susan O’Sullivan 21 Evaluating the Cephalonia method of library induction Lisa Peters, Judith Brown, Eric Davies, Sue Hultum, Pam Thomas, Marion Thompson and Anne Williams 23 Catalyst for change: everyday learning Alan Seatwo 26 The Irish Working Group on Information Literacy: a cross-sectoral approach Terry O’Brien, Philip Russell 30 Supporting research – why you should give more thought to CCM Sally Curry 34 Collaborative collection management of monographs: the White Rose experience Christopher M. Senior 37 In 2007 should we be loaning journals? Steve Lee 40 Digitisation at the University of Lincoln Faye Cleminson 42 Institutional repository ‘GTI’: establishing and populating a research repository for the University of Wolverhampton Frances Hal, John Rule 47 Sussex Research Online Adrian Hale 50 ‘What tangled webs …’: redesigning the University of Warwick Library website Simon Speight, Hannah Perkins 54 From years of experience …building a better annual report for the library Sally Faith 55 Introducing England’s newest university – the University of Cumbria Margaret Weaver 58 Fanfare for the Conservatoire Robert Allan 59 Work-based learning at Newman College of Higher Education Chris Porter 62 Masterclasses at UCE Birmingham library services Janice Bell 64 Grant funding for Irish academic libraries – some opportunities Terry O’Brien, Kieran Cronin, Ted Lynch 70 Skills for today’s information professional Lis Parcell SCONUL Focus 41 Summer/Autumn 2007 1 72 Developing the workforce: the introduction of behavioural competencies at the University of Huddersfield Sue White 74 A week in the life of Bodley’s Librarian Sarah E. -
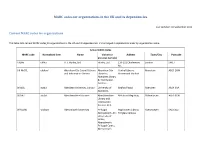
MARC Codes for Organizations in the UK and Its Dependencies
MARC codes for organizations in the UK and its dependencies Last updated: 02 September 2019 Current MARC codes for organizations This table lists current MARC codes for organizations in the UK and its dependencies. It is arranged in alphabetical order by organization name. Active MARC Codes MARC code Normalised form Name Variant or Address Town/City Postcode previous name(s) UkLHu uklhu A. J. Hurley, Ltd. Hurley, Ltd. 119-121 Charlemont London SW17 Rd. UK-AbCCL ukabccl Aberdeen City Council Library Aberdeen City Central Library, Aberdeen AB25 1GW and Information Service Libraries; Rosemount Viaduct Aberdeen Library & Information Services StAbUL stabul Aberdeen University, Library University of Bedford Road Aberdeen AB24 3AA Aberdeen StOlALI stolali Aberdeenshire Libraries Aberdeenshire Meldrum Meg Way Oldmeldrum AB51 0GN Library and Information Service; ALIS WlAbUW wlabuw Aberystwyth University Prifysgol Hugh Owen Library, Aberystwyth SY23 3DZ Aberystwyth, AU; Penglais Campus University of Wales, Aberystwyth; Prifysgol Cymru, Aberystwyth UK-LoALL ukloall Academic Library Limited 20 Cambridge Dr. London SE12 8AJ UkAc ukac Accrington Public Library Accrington UkMbAM-D ukmbamd Adam Matthew Digital Ltd Pelham House, London Malborough SN8 2AA Road UkMbAM ukmbam Adam Matthew Publications Pelham House, London Malborough SN8 2AA Ltd Road StEdAL stedal Advocates Library Parliament House Edinburgh EH1 1RF UkLoJL uklojl Aga Khan Library IIS-ISMC Joint 10 Handyside Street London N1C 4DN Library; Library of the Institute of Ismaili Studies and the Institute for the Study of Muslim Civilisations (Aga Khan University) StEdALDL stedaldl Agency for the Legal Deposit ALDL 33, Salisbury Place Edinburgh EH9 1SL Libraries UkLiAHC ukliahc Alder Hey Children’s NHS FT Education Centre, Liverpool L12 2AP Eaton Road UkLAC uklac American College in London, 110 Marylebone High London W1M 3DB Library St. -

Intute Was Launched in July 2006 As the New Face of The
Intute: Law – the What? Why? How? Where? and Who? Steve Whittle, Information Systems Manager, Institute of Advanced Legal Studies Steve Whittle is the Information Systems Manager in the Library at the Institute of Advanced Legal Studies, School of Advanced Study in the University of London. He also works as Project Manager for IALS participation in the development of Intute: Law. He has more than 23 years experience in the UK Higher Education environment and has been actively involved in the planning and introduction of automated systems and services. He has written for a number of journals including Amicus Curiae, Directions in Legal Education (UKCLE Newsletter), International Journal of Legal Information, JILT Journal of Information Law and Technology, Legal Information Management and LLRX. Summary This paper describes Intute: Law, part of the UK’s national Internet service, providing access to the best of the web for law through an Internet resource catalogue of international scope and relevance, specialist site evaluation and interactive online training resources. The paper looks at the What, Why, How, Where and Who of Intute and aims to answer the questions: What is Intute: Law? Why has it been developed? How does it work? How can you use it? Where is it going? and Who is involved in its development? Table of Contents What is Intute: Law? Service aims, components and contents Why was Intute created? Internet information Quality issues and Internet research skills How Intute works and can help support legal research? Using Intute: -

Weaver, Margaret (2007) Introducing England's Newest University
Weaver, Margaret (2007) Introducing England’s newest university: the University of Cumbria. Sconul Focus, 41 . pp. 55-57. Downloaded from: http://insight.cumbria.ac.uk/id/eprint/397/ Usage of any items from the University of Cumbria’s institutional repository ‘Insight’ must conform to the following fair usage guidelines. Any item and its associated metadata held in the University of Cumbria’s institutional repository Insight (unless stated otherwise on the metadata record) may be copied, displayed or performed, and stored in line with the JISC fair dealing guidelines (available here) for educational and not-for-profit activities provided that • the authors, title and full bibliographic details of the item are cited clearly when any part of the work is referred to verbally or in the written form • a hyperlink/URL to the original Insight record of that item is included in any citations of the work • the content is not changed in any way • all files required for usage of the item are kept together with the main item file. You may not • sell any part of an item • refer to any part of an item without citation • amend any item or contextualise it in a way that will impugn the creator’s reputation • remove or alter the copyright statement on an item. The full policy can be found here. Alternatively contact the University of Cumbria Repository Editor by emailing [email protected]. SCONUL Focus Number 41 Summer/Autumn 2007 Contents ISSN 1745-5782 (print) ISSN 1745-5790 (online) 3 Widening your networking 4 The future of librarianship: Lorna -

Intute Was Launched in July 2006 As the New Face of The
Intute: Law – finding the best of the Web for Law Heather Memess, Intute Law Project Officer, Institute of Advanced Legal Studies and Steve Whittle, Information Systems Manager, Institute of Advanced Legal Studies Intute http://www.intute.ac.uk/ is the UK’s gateway to high quality information sources on the Internet. The service was launched in July 2006 as the new face of the Resource Discovery Network (RDN) a free online service many librarians and researchers will remember as the national gateway to learning, teaching and research resources on the Internet. The name ‘Intute’ is a combination of ‘Internet’ and ‘tutorial’ and is intended to convey the experiences of guided learning and online resource discovery. Background and development Intute continues the work of the RDN, providing access to the best web resources, but additionally offers a range of value-added services. Intute is hosted by MIMAS at The University of Manchester, and is a consortium involving 7 UK universities: the University of Birmingham, the University of Bristol, Heriot Watt University, the University of Manchester, Manchester Metropolitan University, the University of Nottingham and the University of Oxford, supported by 70 partner institutions providing subject expertise and advice (including for Law, the Institute of Advanced Legal Studies, University of London). The service is funded by the Joint Information Systems Committee (JISC), with support from the Arts and Humanities Research Council (AHRC), and the Economic and Social Research Council (ESRC). The RDN was organised into eight subject-based information gateways (or hubs) each maintained on separate databases and servers, these included: Artifact (arts and creative industries), EEVL (engineering, maths and computing), BIOME (health, medicine and life sciences), Humbul (humanities) and SOSIG (social science, business and law) - familiar to librarians and researchers in these fields.