BCFA: Bespoke Control Flow Analysis for CFA at Scale
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Talend Open Studio for Big Data Release Notes
Talend Open Studio for Big Data Release Notes 6.0.0 Talend Open Studio for Big Data Adapted for v6.0.0. Supersedes previous releases. Publication date July 2, 2015 Copyleft This documentation is provided under the terms of the Creative Commons Public License (CCPL). For more information about what you can and cannot do with this documentation in accordance with the CCPL, please read: http://creativecommons.org/licenses/by-nc-sa/2.0/ Notices Talend is a trademark of Talend, Inc. All brands, product names, company names, trademarks and service marks are the properties of their respective owners. License Agreement The software described in this documentation is licensed under the Apache License, Version 2.0 (the "License"); you may not use this software except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0.html. Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. This product includes software developed at AOP Alliance (Java/J2EE AOP standards), ASM, Amazon, AntlR, Apache ActiveMQ, Apache Ant, Apache Avro, Apache Axiom, Apache Axis, Apache Axis 2, Apache Batik, Apache CXF, Apache Cassandra, Apache Chemistry, Apache Common Http Client, Apache Common Http Core, Apache Commons, Apache Commons Bcel, Apache Commons JxPath, Apache -

SVG-Based Knowledge Visualization
MASARYK UNIVERSITY FACULTY}w¡¢£¤¥¦§¨ OF I !"#$%&'()+,-./012345<yA|NFORMATICS SVG-based Knowledge Visualization DIPLOMA THESIS Miloš Kaláb Brno, spring 2012 Declaration Hereby I declare, that this paper is my original authorial work, which I have worked out by my own. All sources, references and literature used or excerpted during elaboration of this work are properly cited and listed in complete reference to the due source. Advisor: RNDr. Tomáš Gregar Ph.D. ii Acknowledgement I would like to thank RNDr. Tomáš Gregar Ph.D. for supervising the thesis. His opinions, comments and advising helped me a lot with accomplishing this work. I would also like to thank to Dr. Daniel Sonntag from DFKI GmbH. Saarbrücken, Germany, for the opportunity to work for him on the Medico project and for his supervising of the thesis during my erasmus exchange in Germany. Big thanks also to Jochen Setz from Dr. Sonntag’s team who worked on the server background used by my visualization. Last but not least, I would like to thank to my family and friends for being extraordinary supportive. iii Abstract The aim of this thesis is to analyze the visualization of semantic data and sug- gest an approach to general visualization into the SVG format. Afterwards, the approach is to be implemented in a visualizer allowing user to customize the visualization according to the nature of the data. The visualizer was integrated as an extension of Fresnel Editor. iv Keywords Semantic knowledge, SVG, Visualization, JavaScript, Java, XML, Fresnel, XSLT v Contents Introduction . .3 1 Brief Introduction to the Related Technologies ..........5 1.1 XML – Extensible Markup Language ..............5 1.1.1 XSLT – Extensible Stylesheet Lang. -
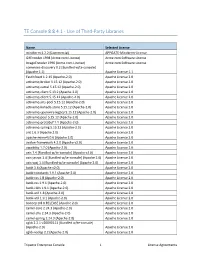
TE Console 8.8.4.1 - Use of Third-Party Libraries
TE Console 8.8.4.1 - Use of Third-Party Libraries Name Selected License mindterm 4.2.2 (Commercial) APPGATE-Mindterm-License GifEncoder 1998 (Acme.com License) Acme.com Software License ImageEncoder 1996 (Acme.com License) Acme.com Software License commons-discovery 0.2 [Bundled w/te-console] (Apache 1.1) Apache License 1.1 FastInfoset 1.2.15 (Apache-2.0) Apache License 2.0 activemQ-broker 5.15.12 (Apache-2.0) Apache License 2.0 activemQ-camel 5.15.12 (Apache-2.0) Apache License 2.0 activemQ-client 5.13.2 (Apache-2.0) Apache License 2.0 activemQ-client 5.15.12 (Apache-2.0) Apache License 2.0 activemQ-jms-pool 5.15.12 (Apache-2.0) Apache License 2.0 activemQ-kahadb-store 5.15.12 (Apache-2.0) Apache License 2.0 activemQ-openwire-legacy 5.15.12 (Apache-2.0) Apache License 2.0 activemQ-pool 5.15.12 (Apache-2.0) Apache License 2.0 activemQ-protobuf 1.1 (Apache-2.0) Apache License 2.0 activemQ-spring 5.15.12 (Apache-2.0) Apache License 2.0 ant 1.6.3 (Apache 2.0) Apache License 2.0 apache-mime4j 0.6 (Apache 2.0) Apache License 2.0 avalon-framework 4.2.0 (Apache v2.0) Apache License 2.0 awaitility 1.7.0 (Apache-2.0) Apache License 2.0 axis 1.4 [Bundled w/te-console] (Apache v2.0) Apache License 2.0 axis-jaxrpc 1.4 [Bundled w/te-console] (Apache 2.0) Apache License 2.0 axis-saaj 1.4 [Bundled w/te-console] (Apache 2.0) Apache License 2.0 batik 1.6 (Apache v2.0) Apache License 2.0 batik-constants 1.9.1 (Apache-2.0) Apache License 2.0 batik-css 1.8 (Apache-2.0) Apache License 2.0 batik-css 1.9.1 (Apache-2.0) Apache License 2.0 batik-i18n 1.9.1 (Apache-2.0) -

Full-Graph-Limited-Mvn-Deps.Pdf
org.jboss.cl.jboss-cl-2.0.9.GA org.jboss.cl.jboss-cl-parent-2.2.1.GA org.jboss.cl.jboss-classloader-N/A org.jboss.cl.jboss-classloading-vfs-N/A org.jboss.cl.jboss-classloading-N/A org.primefaces.extensions.master-pom-1.0.0 org.sonatype.mercury.mercury-mp3-1.0-alpha-1 org.primefaces.themes.overcast-${primefaces.theme.version} org.primefaces.themes.dark-hive-${primefaces.theme.version}org.primefaces.themes.humanity-${primefaces.theme.version}org.primefaces.themes.le-frog-${primefaces.theme.version} org.primefaces.themes.south-street-${primefaces.theme.version}org.primefaces.themes.sunny-${primefaces.theme.version}org.primefaces.themes.hot-sneaks-${primefaces.theme.version}org.primefaces.themes.cupertino-${primefaces.theme.version} org.primefaces.themes.trontastic-${primefaces.theme.version}org.primefaces.themes.excite-bike-${primefaces.theme.version} org.apache.maven.mercury.mercury-external-N/A org.primefaces.themes.redmond-${primefaces.theme.version}org.primefaces.themes.afterwork-${primefaces.theme.version}org.primefaces.themes.glass-x-${primefaces.theme.version}org.primefaces.themes.home-${primefaces.theme.version} org.primefaces.themes.black-tie-${primefaces.theme.version}org.primefaces.themes.eggplant-${primefaces.theme.version} org.apache.maven.mercury.mercury-repo-remote-m2-N/Aorg.apache.maven.mercury.mercury-md-sat-N/A org.primefaces.themes.ui-lightness-${primefaces.theme.version}org.primefaces.themes.midnight-${primefaces.theme.version}org.primefaces.themes.mint-choc-${primefaces.theme.version}org.primefaces.themes.afternoon-${primefaces.theme.version}org.primefaces.themes.dot-luv-${primefaces.theme.version}org.primefaces.themes.smoothness-${primefaces.theme.version}org.primefaces.themes.swanky-purse-${primefaces.theme.version} -

Running Apache FOP
Running Apache FOP $Revision: 533992 $ Table of contents 1 System Requirements...............................................................................................................2 2 Installation................................................................................................................................2 2.1 Instructions.......................................................................................................................... 2 2.2 Problems..............................................................................................................................2 3 Starting FOP as a Standalone Application...............................................................................3 3.1 Using the fop script or batch file......................................................................................... 3 3.2 Writing your own script.......................................................................................................5 3.3 Running with java's -jar option............................................................................................5 3.4 FOP's dynamical classpath construction............................................................................. 5 4 Using Xalan to Check XSL-FO Input......................................................................................5 5 Memory Usage.........................................................................................................................6 6 Problems................................................................................................................................. -
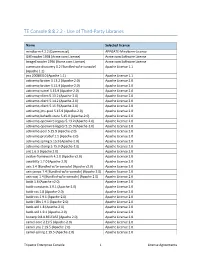
TE Console 8.8.2.2 - Use of Third-Party Libraries
TE Console 8.8.2.2 - Use of Third-Party Libraries Name Selected License mindterm 4.2.2 (Commercial) APPGATE-Mindterm-License GifEncoder 1998 (Acme.com License) Acme.com Software License ImageEncoder 1996 (Acme.com License) Acme.com Software License commons-discovery 0.2 [Bundled w/te-console] Apache License 1.1 (Apache 1.1) jrcs 20080310 (Apache 1.1) Apache License 1.1 activemQ-broker 5.13.2 (Apache-2.0) Apache License 2.0 activemQ-broker 5.15.9 (Apache-2.0) Apache License 2.0 activemQ-camel 5.15.9 (Apache-2.0) Apache License 2.0 activemQ-client 5.13.2 (Apache-2.0) Apache License 2.0 activemQ-client 5.14.2 (Apache-2.0) Apache License 2.0 activemQ-client 5.15.9 (Apache-2.0) Apache License 2.0 activemQ-jms-pool 5.15.9 (Apache-2.0) Apache License 2.0 activemQ-kahadb-store 5.15.9 (Apache-2.0) Apache License 2.0 activemQ-openwire-legacy 5.13.2 (Apache-2.0) Apache License 2.0 activemQ-openwire-legacy 5.15.9 (Apache-2.0) Apache License 2.0 activemQ-pool 5.15.9 (Apache-2.0) Apache License 2.0 activemQ-protobuf 1.1 (Apache-2.0) Apache License 2.0 activemQ-spring 5.15.9 (Apache-2.0) Apache License 2.0 activemQ-stomp 5.15.9 (Apache-2.0) Apache License 2.0 ant 1.6.3 (Apache 2.0) Apache License 2.0 avalon-framework 4.2.0 (Apache v2.0) Apache License 2.0 awaitility 1.7.0 (Apache-2.0) Apache License 2.0 axis 1.4 [Bundled w/te-console] (Apache v2.0) Apache License 2.0 axis-jaxrpc 1.4 [Bundled w/te-console] (Apache 2.0) Apache License 2.0 axis-saaj 1.4 [Bundled w/te-console] (Apache 2.0) Apache License 2.0 batik 1.6 (Apache v2.0) Apache License 2.0 batik-constants -

Installation Guide for GIS Portal Toolkit 3.1
Installation Guide for GIS Portal Toolkit 3.1 October 2007 ESRI 380 New York Street Redlands, CA 92373-8100 Copyright © 2007 ESRI All rights reserved. Printed in the United States of America. The information contained in this document is the exclusive property of ESRI. This work is protected under United States copyright law and other international copyright treaties and conventions. No part of this work may be reproduced or transmitted in any form or by any means, electronic or mechanical, including photocopying and recording, or by any information storage or retrieval system, except as expressly permitted in writing by ESRI. All requests should be sent to Attention: Contracts and Legal Services Manager, ESRI, 380 New York Street, Redlands, CA 92373-8100 USA. The information contained in this document is subject to change without notice. U.S. GOVERNMENT RESTRICTED/LIMITED RIGHTS Any software, documentation, and/or data delivered hereunder is subject to the terms of the License Agreement. In no event shall the U.S. Government acquire greater than RESTRICTED/LIMITED RIGHTS. At a minimum, use, duplication, or disclosure by the U.S. Government is subject to restrictions as set forth in FAR §52.227-14 Alternates I, II, and III (JUN 1987); FAR §52.227-19 (JUN 1987) and/or FAR §12.211/12.212 (Commercial Technical Data/Computer Software); and DFARS §252.227-7015 (NOV 1995) (Technical Data) and/or DFARS §227.7202 (Computer Software), as applicable. Contractor/Manufacturer is ESRI, 380 New York Street, Redlands, CA 92373- 8100 USA. @esri.com, -
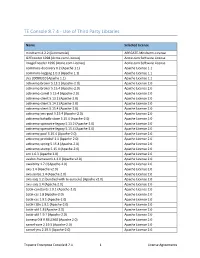
TE Console 8.7.4 - Use of Third Party Libraries
TE Console 8.7.4 - Use of Third Party Libraries Name Selected License mindterm 4.2.2 (Commercial) APPGATE-Mindterm-License GifEncoder 1998 (Acme.com License) Acme.com Software License ImageEncoder 1996 (Acme.com License) Acme.com Software License commons-discovery 0.2 (Apache 1.1) Apache License 1.1 commons-logging 1.0.3 (Apache 1.1) Apache License 1.1 jrcs 20080310 (Apache 1.1) Apache License 1.1 activemq-broker 5.13.2 (Apache-2.0) Apache License 2.0 activemq-broker 5.15.4 (Apache-2.0) Apache License 2.0 activemq-camel 5.15.4 (Apache-2.0) Apache License 2.0 activemq-client 5.13.2 (Apache-2.0) Apache License 2.0 activemq-client 5.14.2 (Apache-2.0) Apache License 2.0 activemq-client 5.15.4 (Apache-2.0) Apache License 2.0 activemq-jms-pool 5.15.4 (Apache-2.0) Apache License 2.0 activemq-kahadb-store 5.15.4 (Apache-2.0) Apache License 2.0 activemq-openwire-legacy 5.13.2 (Apache-2.0) Apache License 2.0 activemq-openwire-legacy 5.15.4 (Apache-2.0) Apache License 2.0 activemq-pool 5.15.4 (Apache-2.0) Apache License 2.0 activemq-protobuf 1.1 (Apache-2.0) Apache License 2.0 activemq-spring 5.15.4 (Apache-2.0) Apache License 2.0 activemq-stomp 5.15.4 (Apache-2.0) Apache License 2.0 ant 1.6.3 (Apache 2.0) Apache License 2.0 avalon-framework 4.2.0 (Apache v2.0) Apache License 2.0 awaitility 1.7.0 (Apache-2.0) Apache License 2.0 axis 1.4 (Apache v2.0) Apache License 2.0 axis-jaxrpc 1.4 (Apache 2.0) Apache License 2.0 axis-saaj 1.2 [bundled with te-console] (Apache v2.0) Apache License 2.0 axis-saaj 1.4 (Apache 2.0) Apache License 2.0 batik-constants -

ECX Third Party Notices
ECX ™ ECX Release 2.4 Third Party Software Information The accompanying program and the related media, documentation and materials (“Software”) are protected by copyright law and international treaties. Unauthorized reproduction or distribution of the Software, or any portion of it, may result in severe civil and criminal penalties, and will be prosecuted to the maximum extent possible under the law. Copyright (c) Catalogic Software, Inc., 2016. All rights reserved. The Software contains proprietary and confidential material, and is only for use by the lessees of the ECX proprietary software system. The Software may not be reproduced in whole or in part, in any form, except with written permission from Catalogic Software, Inc. The Software is provided under the accompanying Software License Agreement (“SLA”) ECX is a registered trademark of Catalogic Software, Inc. All other third-party brand names and product names used in this documentation are trade names, service marks, trademarks, or registered trademarks of their respective owners. The Software is a proprietary product of Catalogic Software, Inc., but incorporates certain third-party components that are subject to separate licenses and/or notice requirements. (Note, however, that while these separate licenses cover the corresponding third-party components, they do not modify or form any part of Catalogic Software’s SLA.) Links to third-party license agreements referenced in this product are listed below. Third Party Software License or Agreement Reference to License or Agreement -

Informatica® Informatica 10.2 Hotfix 1
Informatica® Informatica 10.2 HotFix 1 Notas de la versión Informatica Informatica Notas de la versión 10.2 HotFix 1 Agosto 2018 © Copyright Informatica LLC 1998, 2018 Fecha de publicación: 2018-09-25 Tabla de contenido Resumen....................................................................... vi Capítulo 1: Instalación y actualización........................................ 7 Rutas de actualización de Informatica......................................... 7 Cambios en la compatibilidad.............................................. 8 Cambios en la compatibilidad - Distribuciones de Hadoop para Big Data Management....... 9 Cambios en la compatibilidad - Distribuciones de Intelligent Streaming Hadoop.......... 10 Migración a una base de datos diferente....................................... 10 Actualización a la nueva configuración........................................ 10 Actualización desde la versión 10.1.1 HotFix 2................................... 11 Actualizar desde la versión 9.6.1............................................ 11 Vulnerabilidades solucionadas de bibliotecas de otros fabricantes...................... 12 Instalación y reversión de la revisión......................................... 21 Tareas previas a la instalación.......................................... 21 Aplicación o reversión del HotFix en modo gráfico............................. 22 Aplicación o reversión del HotFix en modo de consola........................... 23 Aplicación o reversión del HotFix en modo silencioso........................... 24 Aplicación -

Stat Release Notes
Quest® Stat® 6.3.0 Release Notes April 2020 These release notes provide information about the Quest® Stat® release. • About Stat 6.3 • New features • Enhancements • Resolved issues • System requirements • Upgrade and compatibility • Product licensing • Upgrade and installation instructions • Additional resources • Globalization • About us • Third-party contributions About Stat 6.3 Quest® Stat® is a change lifecycle solution optimized for PeopleSoft® Enterprise and Oracle® E-Business Suite applications. Stat makes organizations more responsive to change and increases visibility into, and control over, the change management process. Stat dramatically reduces the time required to deploy patches and critical changes throughout the various instances of a packaged application, resulting in lower total cost of ownership. New features New features in Stat® 6.3.0: • Support PeopleTools 8.58 • Ability to add files to a CSR from VCM branch • Automatically generate Migration Path for CSR • Added the ability to associate default VCM with Workflow • Added Pre filter option for AOL objects • Ability to search the Support Portal Knowledge Base Quest Stat 6.3.0 1 Release Notes • Removed Java dependency on Windows Client • Removed Oracle Developer dependency for Oracle E-Business Object Comparison See also: • Enhancements • Resolved issues Enhancements The following is a list of enhancements implemented in Stat® 6.3.0. Table 1. General enhancements Enhancement Issue ID Added source information for Migration History reports 1630 Added an optional Pre-Filter -

Code Smell Prediction Employing Machine Learning Meets Emerging Java Language Constructs"
Appendix to the paper "Code smell prediction employing machine learning meets emerging Java language constructs" Hanna Grodzicka, Michał Kawa, Zofia Łakomiak, Arkadiusz Ziobrowski, Lech Madeyski (B) The Appendix includes two tables containing the dataset used in the paper "Code smell prediction employing machine learning meets emerging Java lan- guage constructs". The first table contains information about 792 projects selected for R package reproducer [Madeyski and Kitchenham(2019)]. Projects were the base dataset for cre- ating the dataset used in the study (Table I). The second table contains information about 281 projects filtered by Java version from build tool Maven (Table II) which were directly used in the paper. TABLE I: Base projects used to create the new dataset # Orgasation Project name GitHub link Commit hash Build tool Java version 1 adobe aem-core-wcm- www.github.com/adobe/ 1d1f1d70844c9e07cd694f028e87f85d926aba94 other or lack of unknown components aem-core-wcm-components 2 adobe S3Mock www.github.com/adobe/ 5aa299c2b6d0f0fd00f8d03fda560502270afb82 MAVEN 8 S3Mock 3 alexa alexa-skills- www.github.com/alexa/ bf1e9ccc50d1f3f8408f887f70197ee288fd4bd9 MAVEN 8 kit-sdk-for- alexa-skills-kit-sdk- java for-java 4 alibaba ARouter www.github.com/alibaba/ 93b328569bbdbf75e4aa87f0ecf48c69600591b2 GRADLE unknown ARouter 5 alibaba atlas www.github.com/alibaba/ e8c7b3f1ff14b2a1df64321c6992b796cae7d732 GRADLE unknown atlas 6 alibaba canal www.github.com/alibaba/ 08167c95c767fd3c9879584c0230820a8476a7a7 MAVEN 7 canal 7 alibaba cobar www.github.com/alibaba/