1 Distances and Metric Spaces
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Metric Geometry in a Tame Setting
University of California Los Angeles Metric Geometry in a Tame Setting A dissertation submitted in partial satisfaction of the requirements for the degree Doctor of Philosophy in Mathematics by Erik Walsberg 2015 c Copyright by Erik Walsberg 2015 Abstract of the Dissertation Metric Geometry in a Tame Setting by Erik Walsberg Doctor of Philosophy in Mathematics University of California, Los Angeles, 2015 Professor Matthias J. Aschenbrenner, Chair We prove basic results about the topology and metric geometry of metric spaces which are definable in o-minimal expansions of ordered fields. ii The dissertation of Erik Walsberg is approved. Yiannis N. Moschovakis Chandrashekhar Khare David Kaplan Matthias J. Aschenbrenner, Committee Chair University of California, Los Angeles 2015 iii To Sam. iv Table of Contents 1 Introduction :::::::::::::::::::::::::::::::::::::: 1 2 Conventions :::::::::::::::::::::::::::::::::::::: 5 3 Metric Geometry ::::::::::::::::::::::::::::::::::: 7 3.1 Metric Spaces . 7 3.2 Maps Between Metric Spaces . 8 3.3 Covers and Packing Inequalities . 9 3.3.1 The 5r-covering Lemma . 9 3.3.2 Doubling Metrics . 10 3.4 Hausdorff Measures and Dimension . 11 3.4.1 Hausdorff Measures . 11 3.4.2 Hausdorff Dimension . 13 3.5 Topological Dimension . 15 3.6 Left-Invariant Metrics on Groups . 15 3.7 Reductions, Ultralimits and Limits of Metric Spaces . 16 3.7.1 Reductions of Λ-valued Metric Spaces . 16 3.7.2 Ultralimits . 17 3.7.3 GH-Convergence and GH-Ultralimits . 18 3.7.4 Asymptotic Cones . 19 3.7.5 Tangent Cones . 22 3.7.6 Conical Metric Spaces . 22 3.8 Normed Spaces . 23 4 T-Convexity :::::::::::::::::::::::::::::::::::::: 24 4.1 T-convex Structures . -

Analysis in Metric Spaces Mario Bonk, Luca Capogna, Piotr Hajłasz, Nageswari Shanmugalingam, and Jeremy Tyson
Analysis in Metric Spaces Mario Bonk, Luca Capogna, Piotr Hajłasz, Nageswari Shanmugalingam, and Jeremy Tyson study of quasiconformal maps on such boundaries moti- The authors of this piece are organizers of the AMS vated Heinonen and Koskela [HK98] to axiomatize several 2020 Mathematics Research Communities summer aspects of Euclidean quasiconformal geometry in the set- conference Analysis in Metric Spaces, one of five ting of metric measure spaces and thereby extend Mostow’s topical research conferences offered this year that are work beyond the sub-Riemannian setting. The ground- focused on collaborative research and professional breaking work [HK98] initiated the modern theory of anal- development for early-career mathematicians. ysis on metric spaces. Additional information can be found at https://www Analysis on metric spaces is nowadays an active and in- .ams.org/programs/research-communities dependent field, bringing together researchers from differ- /2020MRC-MetSpace. Applications are open until ent parts of the mathematical spectrum. It has far-reaching February 15, 2020. applications to areas as diverse as geometric group the- ory, nonlinear PDEs, and even theoretical computer sci- The subject of analysis, more specifically, first-order calcu- ence. As a further sign of recognition, analysis on met- lus, in metric measure spaces provides a unifying frame- ric spaces has been included in the 2010 MSC classifica- work for ideas and questions from many different fields tion as a category (30L: Analysis on metric spaces). In this of mathematics. One of the earliest motivations and ap- short survey, we can discuss only a small fraction of areas plications of this theory arose in Mostow’s work [Mos73], into which analysis on metric spaces has expanded. -

Metric Spaces We Have Talked About the Notion of Convergence in R
Mathematics Department Stanford University Math 61CM – Metric spaces We have talked about the notion of convergence in R: Definition 1 A sequence an 1 of reals converges to ` R if for all " > 0 there exists N N { }n=1 2 2 such that n N, n N implies an ` < ". One writes lim an = `. 2 ≥ | − | With . the standard norm in Rn, one makes the analogous definition: k k n n Definition 2 A sequence xn 1 of points in R converges to x R if for all " > 0 there exists { }n=1 2 N N such that n N, n N implies xn x < ". One writes lim xn = x. 2 2 ≥ k − k One important consequence of the definition in either case is that limits are unique: Lemma 1 Suppose lim xn = x and lim xn = y. Then x = y. Proof: Suppose x = y.Then x y > 0; let " = 1 x y .ThusthereexistsN such that n N 6 k − k 2 k − k 1 ≥ 1 implies x x < ", and N such that n N implies x y < ". Let n = max(N ,N ). Then k n − k 2 ≥ 2 k n − k 1 2 x y x x + x y < 2" = x y , k − kk − nk k n − k k − k which is a contradiction. Thus, x = y. ⇤ Note that the properties of . were not fully used. What we needed is that the function d(x, y)= k k x y was non-negative, equal to 0 only if x = y,symmetric(d(x, y)=d(y, x)) and satisfied the k − k triangle inequality. -

Distance Metric Learning, with Application to Clustering with Side-Information
Distance metric learning, with application to clustering with side-information Eric P. Xing, Andrew Y. Ng, Michael I. Jordan and Stuart Russell University of California, Berkeley Berkeley, CA 94720 epxing,ang,jordan,russell ¡ @cs.berkeley.edu Abstract Many algorithms rely critically on being given a good metric over their inputs. For instance, data can often be clustered in many “plausible” ways, and if a clustering algorithm such as K-means initially fails to find one that is meaningful to a user, the only recourse may be for the user to manually tweak the metric until sufficiently good clusters are found. For these and other applications requiring good metrics, it is desirable that we provide a more systematic way for users to indicate what they con- sider “similar.” For instance, we may ask them to provide examples. In this paper, we present an algorithm that, given examples of similar (and, if desired, dissimilar) pairs of points in ¢¤£ , learns a distance metric over ¢¥£ that respects these relationships. Our method is based on posing met- ric learning as a convex optimization problem, which allows us to give efficient, local-optima-free algorithms. We also demonstrate empirically that the learned metrics can be used to significantly improve clustering performance. 1 Introduction The performance of many learning and datamining algorithms depend critically on their being given a good metric over the input space. For instance, K-means, nearest-neighbors classifiers and kernel algorithms such as SVMs all need to be given good metrics that -

Inner Product Spaces Isaiah Lankham, Bruno Nachtergaele, Anne Schilling (March 2, 2007)
MAT067 University of California, Davis Winter 2007 Inner Product Spaces Isaiah Lankham, Bruno Nachtergaele, Anne Schilling (March 2, 2007) The abstract definition of vector spaces only takes into account algebraic properties for the addition and scalar multiplication of vectors. For vectors in Rn, for example, we also have geometric intuition which involves the length of vectors or angles between vectors. In this section we discuss inner product spaces, which are vector spaces with an inner product defined on them, which allow us to introduce the notion of length (or norm) of vectors and concepts such as orthogonality. 1 Inner product In this section V is a finite-dimensional, nonzero vector space over F. Definition 1. An inner product on V is a map ·, · : V × V → F (u, v) →u, v with the following properties: 1. Linearity in first slot: u + v, w = u, w + v, w for all u, v, w ∈ V and au, v = au, v; 2. Positivity: v, v≥0 for all v ∈ V ; 3. Positive definiteness: v, v =0ifandonlyifv =0; 4. Conjugate symmetry: u, v = v, u for all u, v ∈ V . Remark 1. Recall that every real number x ∈ R equals its complex conjugate. Hence for real vector spaces the condition about conjugate symmetry becomes symmetry. Definition 2. An inner product space is a vector space over F together with an inner product ·, ·. Copyright c 2007 by the authors. These lecture notes may be reproduced in their entirety for non- commercial purposes. 2NORMS 2 Example 1. V = Fn n u =(u1,...,un),v =(v1,...,vn) ∈ F Then n u, v = uivi. -

5-7 the Pythagorean Theorem 5-7 the Pythagorean Theorem
55-7-7 TheThe Pythagorean Pythagorean Theorem Theorem Warm Up Lesson Presentation Lesson Quiz HoltHolt McDougal Geometry Geometry 5-7 The Pythagorean Theorem Warm Up Classify each triangle by its angle measures. 1. 2. acute right 3. Simplify 12 4. If a = 6, b = 7, and c = 12, find a2 + b2 2 and find c . Which value is greater? 2 85; 144; c Holt McDougal Geometry 5-7 The Pythagorean Theorem Objectives Use the Pythagorean Theorem and its converse to solve problems. Use Pythagorean inequalities to classify triangles. Holt McDougal Geometry 5-7 The Pythagorean Theorem Vocabulary Pythagorean triple Holt McDougal Geometry 5-7 The Pythagorean Theorem The Pythagorean Theorem is probably the most famous mathematical relationship. As you learned in Lesson 1-6, it states that in a right triangle, the sum of the squares of the lengths of the legs equals the square of the length of the hypotenuse. a2 + b2 = c2 Holt McDougal Geometry 5-7 The Pythagorean Theorem Example 1A: Using the Pythagorean Theorem Find the value of x. Give your answer in simplest radical form. a2 + b2 = c2 Pythagorean Theorem 22 + 62 = x2 Substitute 2 for a, 6 for b, and x for c. 40 = x2 Simplify. Find the positive square root. Simplify the radical. Holt McDougal Geometry 5-7 The Pythagorean Theorem Example 1B: Using the Pythagorean Theorem Find the value of x. Give your answer in simplest radical form. a2 + b2 = c2 Pythagorean Theorem (x – 2)2 + 42 = x2 Substitute x – 2 for a, 4 for b, and x for c. x2 – 4x + 4 + 16 = x2 Multiply. -

Geometry Ch 5 Exterior Angles & Triangle Inequality December 01, 2014
Geometry Ch 5 Exterior Angles & Triangle Inequality December 01, 2014 The “Three Possibilities” Property: either a>b, a=b, or a<b The Transitive Property: If a>b and b>c, then a>c The Addition Property: If a>b, then a+c>b+c The Subtraction Property: If a>b, then a‐c>b‐c The Multiplication Property: If a>b and c>0, then ac>bc The Division Property: If a>b and c>0, then a/c>b/c The Addition Theorem of Inequality: If a>b and c>d, then a+c>b+d The “Whole Greater than Part” Theorem: If a>0, b>0, and a+b=c, then c>a and c>b Def: An exterior angle of a triangle is an angle that forms a linear pair with an angle of the triangle. A In ∆ABC, exterior ∠2 forms a linear pair with ∠ACB. The other two angles of the triangle, ∠1 (∠B) and ∠A are called remote interior angles with respect to ∠2. 1 2 B C Theorem 12: The Exterior Angle Theorem An Exterior angle of a triangle is greater than either remote interior angle. Find each of the following sums. 3 4 26. ∠1+∠2+∠3+∠4 2 1 6 7 5 8 27. ∠1+∠2+∠3+∠4+∠5+∠6+∠7+ 9 12 ∠8+∠9+∠10+∠11+∠12 11 10 28. ∠1+∠5+∠9 31. What does the result in exercise 30 indicate about the sum of the exterior 29. ∠3+∠7+∠11 angles of a triangle? 30. ∠2+∠4+∠6+∠8+∠10+∠12 1 Geometry Ch 5 Exterior Angles & Triangle Inequality December 01, 2014 After proving the Exterior Angle Theorem, Euclid proved that, in any triangle, the sum of any two angles is less than 180°. -

5.2. Inner Product Spaces 1 5.2
5.2. Inner Product Spaces 1 5.2. Inner Product Spaces Note. In this section, we introduce an inner product on a vector space. This will allow us to bring much of the geometry of Rn into the infinite dimensional setting. Definition 5.2.1. A vector space with complex scalars hV, Ci is an inner product space (also called a Euclidean Space or a Pre-Hilbert Space) if there is a function h·, ·i : V × V → C such that for all u, v, w ∈ V and a ∈ C we have: (a) hv, vi ∈ R and hv, vi ≥ 0 with hv, vi = 0 if and only if v = 0, (b) hu, v + wi = hu, vi + hu, wi, (c) hu, avi = ahu, vi, and (d) hu, vi = hv, ui where the overline represents the operation of complex conju- gation. The function h·, ·i is called an inner product. Note. Notice that properties (b), (c), and (d) of Definition 5.2.1 combine to imply that hu, av + bwi = ahu, vi + bhu, wi and hau + bv, wi = ahu, wi + bhu, wi for all relevant vectors and scalars. That is, h·, ·i is linear in the second positions and “conjugate-linear” in the first position. 5.2. Inner Product Spaces 2 Note. We can also define an inner product on a vector space with real scalars by requiring that h·, ·i : V × V → R and by replacing property (d) in Definition 5.2.1 with the requirement that the inner product is symmetric: hu, vi = hv, ui. Then Rn with the usual dot product is an example of a real inner product space. -
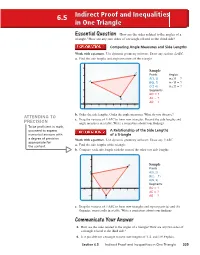
Indirect Proof and Inequalities in One Triangle
6.5 Indirect Proof and Inequalities in One Triangle EEssentialssential QQuestionuestion How are the sides related to the angles of a triangle? How are any two sides of a triangle related to the third side? Comparing Angle Measures and Side Lengths Work with a partner. Use dynamic geometry software. Draw any scalene △ABC. a. Find the side lengths and angle measures of the triangle. 5 Sample C 4 Points Angles A(1, 3) m∠A = ? A 3 B(5, 1) m∠B = ? C(7, 4) m∠C = ? 2 Segments BC = ? 1 B AC = ? AB = 0 ? 01 2 34567 b. Order the side lengths. Order the angle measures. What do you observe? ATTENDING TO c. Drag the vertices of △ABC to form new triangles. Record the side lengths and PRECISION angle measures in a table. Write a conjecture about your fi ndings. To be profi cient in math, you need to express A Relationship of the Side Lengths numerical answers with of a Triangle a degree of precision Work with a partner. Use dynamic geometry software. Draw any △ABC. appropriate for the content. a. Find the side lengths of the triangle. b. Compare each side length with the sum of the other two side lengths. 4 C Sample 3 Points A A(0, 2) 2 B(2, −1) C 1 (5, 3) Segments 0 BC = ? −1 01 2 3456 AC = ? −1 AB = B ? c. Drag the vertices of △ABC to form new triangles and repeat parts (a) and (b). Organize your results in a table. Write a conjecture about your fi ndings. -

CS261 - Optimization Paradigms Lecture Notes for 2013-2014 Academic Year
CS261 - Optimization Paradigms Lecture Notes for 2013-2014 Academic Year ⃝c Serge Plotkin January 2014 1 Contents 1 Steiner Tree Approximation Algorithm 6 2 The Traveling Salesman Problem 10 2.1 General TSP . 10 2.1.1 Definitions . 10 2.1.2 Example of a TSP . 10 2.1.3 Computational Complexity of General TSP . 11 2.1.4 Approximation Methods of General TSP? . 11 2.2 TSP with triangle inequality . 12 2.2.1 Computational Complexity of TSP with Triangle Inequality . 12 2.2.2 Approximation Methods for TSP with Triangle Inequality . 13 3 Matchings, Edge Covers, Node Covers, and Independent Sets 22 3.1 Minumum Edge Cover and Maximum Matching . 22 3.2 Maximum Independent Set and Minimum Node Cover . 24 3.3 Minimum Node Cover Approximation . 24 4 Intro to Linear Programming 27 4.1 Overview . 27 4.2 Transformations . 27 4.3 Geometric interpretation of LP . 29 4.4 Existence of optimum at a vertex of the polytope . 30 4.5 Primal and Dual . 32 4.6 Geometric view of Linear Programming duality in two dimensions . 33 4.7 Historical comments . 35 5 Approximating Weighted Node Cover 37 5.1 Overview and definitions . 37 5.2 Min Weight Node Cover as an Integer Program . 37 5.3 Relaxing the Linear Program . 37 2 5.4 Primal/Dual Approach . 38 5.5 Summary . 40 6 Approximating Set Cover 41 6.1 Solving Minimum Set Cover . 41 7 Randomized Algorithms 46 7.1 Maximum Weight Crossing Edge Set . 46 7.2 The Wire Routing Problem . 48 7.2.1 Overview . -

Learning a Distance Metric from Relative Comparisons
Learning a Distance Metric from Relative Comparisons Matthew Schultz and Thorsten Joachims Department of Computer Science Cornell University Ithaca, NY 14853 schultz,tj @cs.cornell.edu Abstract This paper presents a method for learning a distance metric from rel- ative comparison such as “A is closer to B than A is to C”. Taking a Support Vector Machine (SVM) approach, we develop an algorithm that provides a flexible way of describing qualitative training data as a set of constraints. We show that such constraints lead to a convex quadratic programming problem that can be solved by adapting standard meth- ods for SVM training. We empirically evaluate the performance and the modelling flexibility of the algorithm on a collection of text documents. 1 Introduction Distance metrics are an essential component in many applications ranging from supervised learning and clustering to product recommendations and document browsing. Since de- signing such metrics by hand is difficult, we explore the problem of learning a metric from examples. In particular, we consider relative and qualitative examples of the form “A is closer to B than A is to C”. We believe that feedback of this type is more easily available in many application setting than quantitative examples (e.g. “the distance between A and B is 7.35”) as considered in metric Multidimensional Scaling (MDS) (see [4]), or absolute qualitative feedback (e.g. “A and B are similar”, “A and C are not similar”) as considered in [11]. Building on the study in [7], search-engine query logs are one example where feedback of the form “A is closer to B than A is to C” is readily available for learning a (more semantic) similarity metric on documents. -

Use the Converse of the Pythagorean Theorem
Use the Converse of the Pythagorean Theorem Goal • Use the Converse of the Pythagorean Theorem to determine if a triangle is a right triangle. Your Notes THEOREM 7.2: CONVERSE OF THE PYTHAGOREAN THEOREM If the square of the length of the longest side of a triangle is equal aI to the sum of the squares of the c A lengths of the other two sides, then the triangle is a triangle. If c2 = a 2 + b2, then AABC is a triangle. Verify right triangles Tell whether the given triangle is a right triangle. a. b. 24 6 9 Solution Let c represent the length of the longest side of the triangle. Check to see whether the side lengths satisfy the equation c 2 = a 2 + b 2. a. ( )2 ? 2 + 2 • The triangle a right triangle. b. 2? 2 + 2 The triangle a right triangle. 174 Lesson 7.2 • Geometry Notetaking Guide Copyright @ McDougal Littell/Houghton Mifflin Company. Your Notes THEOREM 7.3 A If the square of the length of the longest b c side of a triangle is less than the sum of B the squares of the lengths of the other C a two sides, then the triangle ABC is an triangle. If c 2 < a 2 + b2 , then the triangle ABC is THEOREM 7.4 A If the square of the length of the longest bN side of a triangle is greater than the sum of C B the squares of the lengths of the other two a sides, then the triangle ABC is an triangle.