Doctor of Philosophy
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Learning HTTP 2.Pdf
L e a r n i n g H T T P/2 A PRACTICAL GUIDE FOR BEGINNERS Stephen Ludin & Javier Garza Learning HTTP/2 A Practical Guide for Beginners Stephen Ludin and Javier Garza Beijing Boston Farnham Sebastopol Tokyo Learning HTTP/2 by Stephen Ludin and Javier Garza Copyright © 2017 Stephen Ludin, Javier Garza. All rights reserved. Printed in the United States of America. Published by O’Reilly Media, Inc., 1005 Gravenstein Highway North, Sebastopol, CA 95472. O’Reilly books may be purchased for educational, business, or sales promotional use. Online editions are also available for most titles (http://oreilly.com/safari). For more information, contact our corporate/insti‐ tutional sales department: 800-998-9938 or [email protected]. Acquisitions Editor: Brian Anderson Indexer: Wendy Catalano Editors: Virginia Wilson and Dawn Schanafelt Interior Designer: David Futato Production Editor: Shiny Kalapurakkel Cover Designer: Karen Montgomery Copyeditor: Kim Cofer Illustrator: Rebecca Demarest Proofreader: Sonia Saruba June 2017: First Edition Revision History for the First Edition 2017-05-14: First Release 2017-10-27: Second Release See http://oreilly.com/catalog/errata.csp?isbn=9781491962442 for release details. The O’Reilly logo is a registered trademark of O’Reilly Media, Inc. Learning HTTP/2, the cover image, and related trade dress are trademarks of O’Reilly Media, Inc. While the publisher and the authors have used good faith efforts to ensure that the information and instructions contained in this work are accurate, the publisher and the authors disclaim all responsibility for errors or omissions, including without limitation responsibility for damages resulting from the use of or reliance on this work. -

SOPHOS IPS Signature Update Release Notes
SOPHOS IPS Signature Update Release Notes Version : 9.16.71 Release Date : 30th January 2020 IPS Signature Update Release Information Upgrade Applicable on IPS Signature Release Version 9.16.70 CR250i, CR300i, CR500i-4P, CR500i-6P, CR500i-8P, CR500ia, CR500ia-RP, CR500ia1F, CR500ia10F, CR750ia, CR750ia1F, CR750ia10F, CR1000i-11P, CR1000i-12P, CR1000ia, CR1000ia10F, CR1500i-11P, CR1500i-12P, CR1500ia, CR1500ia10F Sophos Appliance Models CR25iNG, CR25iNG-6P, CR35iNG, CR50iNG, CR100iNG, CR200iNG/XP, CR300iNG/XP, CR500iNG- XP, CR750iNG-XP, CR2500iNG, CR25wiNG, CR25wiNG-6P, CR35wiNG, CRiV1C, CRiV2C, CRiV4C, CRiV8C, CRiV12C, XG85 to XG450, SG105 to SG650 Upgrade Information Upgrade type: Automatic Compatibility Annotations: None Introduction The Release Note document for IPS Signature Database Version 9.16.71 includes support for the new signatures. The following sections describe the release in detail. New IPS Signatures The Sophos Intrusion Prevention System shields the network from known attacks by matching the network traffic against the signatures in the IPS Signature Database. These signatures are developed to significantly increase detection performance and reduce the false alarms. Report false positives at [email protected], along with the application details. January 2020 Page 2 of 65 IPS Signature Update This IPS Release includes Six Hundred and Thirteen(613) signatures to address Five Hundred(500) vulnerabilities. New signatures are added for the following vulnerabilities: Name CVE–ID Category Severity BROWSER-CHROME Google Chrome -
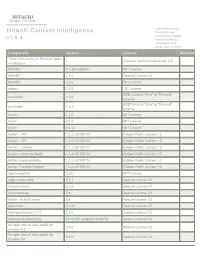
HCI OSS Licenses V1.6.4.Pdf
HITACHI Inspire the Next 2535 Augustine Drive Santa Clara, CA 95054 USA Contact Information : Hitachi Content Intelligence Product Manager Lumada Data Catalog v 1 . 6 . 4 Hitachi Vantara LLC 2535 Augustine Dr. Santa Clara CA 95054 Component Version License Modified "Java Concurrency in Practice" book 1 Creative Commons Attribution 2.5 annotations #NAME? 0.1.38-webpack MIT License #NAME? 2.3.0 Apache License 2.0 #NAME? 3.3.0 MIT License abbrev 1.0.9 ISC License BSD 3-clause "New" or "Revised" ace-builds 1.2.8 License BSD 3-clause "New" or "Revised" ace-builds 1.3.3 License Acorn 1.2.2 MIT License Acorn 2.7.0 MIT License Acorn 4.0.13 MIT License Aether :: API 1.0.2.v20150114 Eclipse Public License 1.0 Aether :: SPI 1.0.2.v20150114 Eclipse Public License 1.0 Aether :: Utilities 1.0.2.v20150114 Eclipse Public License 1.0 Aether Connector Basic 1.0.2.v20150114 Eclipse Public License 1.0 Aether Implementation 1.0.2.v20150114 Eclipse Public License 1.0 Aether Transport Wagon 1.0.2.v20150114 Eclipse Public License 1.0 agentkeepalive 2.2.0 MIT License aggs-matrix-stats 5.3.1 Apache License 2.0 airbnb/chronos 2.3.3 Apache License 2.0 aircompressor 0.8 Apache License 2.0 Airline - io.airlift:airline 0.6 Apache License 2.0 akka-actor 2.3.16 Apache License 2.0 akka-persistence_2.11 2.5.5 Apache License 2.0 alibaba/x-deeplearning 20181224-snapshot-ffc8b733 Apache License 2.0 An open source Java toolkit for 0.9.0 Apache License 2.0 Amazon S3 An open source Java toolkit for 0.9.4 Apache License 2.0 Amazon S3 HITACHI Inspire the Next 2535 Augustine Drive -

Client-Side Energy Efficiency of HTTP/2 for Web and Mobile App
Client-side Energy Efficiency of HTTP/2 for Web and Mobile App Developers Shaiful Alam Chowdhury, Varun Sapra, Abram Hindle Department of Computing Science University of Alberta, Edmonton, Canada Email: {shaiful, vsapra, abram.hindle}@ualberta.ca Abstract—Recent technological advancements have enabled to the continually increasing demand for storage, networking mobile devices to provide mobile users with substantial capability and computation capabilities. In 2010, 4.3 terawatt-years of and accessibility. Energy is evidently one of the most critical energy was consumed within the US by LAN switches and resources for such devices; in spite of the substantial gain in popularity of mobile devices, such as smartphones, their utility routers [38]. Energy efficiency was reported as one of the is severely constrained by the bounded battery capacity. Mobile pivotal issues even by Google, facing the scale of operations, users are very interested in accessing the Internet although it is as cooling becomes a very important operational factor [8]. one of the most expensive operations in terms of energy and cost. Another very important aspect of energy consumption is the HTTP/2 has been proposed and accepted as the new standard environment: energy consumption has a detrimental effect on for supporting the World Wide Web. HTTP/2 is expected to climate change, as most of the electricity is produced by offer better performance, such as reduced page load time. Conse- quently, from the mobile users point of view, the question arises: burning fossil fuels [20]. Reportedly, 1000 tonnes of CO2 is does HTTP/2 offer improved energy consumption performance produced every year by the computer energy consumption of achieving longer battery life? mid-sized organizations [27]. -

IPS Signature Release Note V7.16.71
SOPHOS IPS Signature Update Release Notes Version : 7.16.71 Release Date : 30th January 2020 IPS Signature Update Release Information Upgrade Applicable on IPS Signature Release Version 7.16.70 Sophos Appliance Models XG-550, XG-750, XG-650 Upgrade Information Upgrade type: Automatic Compatibility Annotations: None Introduction The Release Note document for IPS Signature Database Version 7.16.71 includes support for the new signatures. The following sections describe the release in detail. New IPS Signatures The Sophos Intrusion Prevention System shields the network from known attacks by matching the network traffic against the signatures in the IPS Signature Database. These signatures are developed to significantly increase detection performance and reduce the false alarms. Report false positives at [email protected], along with the application details. January 2020 Page 2 of 97 IPS Signature Update This IPS Release includes Nine Hundred and Sixty Four(964) signatures to address Seven Hundred and Forty(740) vulnerabilities. New signatures are added for the following vulnerabilities: Name CVE–ID Category Severity BROWSER-CHROME Google Chrome Browser CVE-2008- Browsers 2 CVE-2008-5750 Remote 5750 Parameter Injection BROWSER-CHROME Google Chrome CVE-2019- FileReader CVE-2019- Browsers 2 5786 5786 Use After Free (Published Exploit) BROWSER-CHROME Google Chrome CVE-2019- Browsers 1 FileReader CVE-2019- 5786 5786 Use After Free BROWSER-FIREFOX Mozilla Firefox CSS CVE-2006- Browsers 2 Letter-Spacing Heap 1730 Overflow BROWSER-FIREFOX Mozilla -

Is HTTP/2 More Energy Efficient Than HTTP/1.1 for Mobile Users?
Is HTTP/2 More Energy Efficient Than HTTP/1.1 for Mobile Users? Shaiful Alam Chowdhury1, Varun Sapra1, and Abram Hindle1 1Department of Computing Science, University of Alberta, Canada ABSTRACT Recent technological advancements have enabled mobile devices to provide mobile users with substantial capability and accessibility. Energy is evidently one of the most critical resources for such devices; in spite of the substantial gain in popularity of mobile devices, such as smartphones, their utility is severely constrained by battery life. Mobile users are very interested in accessing the Internet while it is one of the s most expensive operations in terms of energy and cost. t HTTP/2 has been proposed and accepted as the new standard for supporting the World Wide Web. n HTTP/2 is expected to offer better performance, such as reduced page load time. Consequently, from i r the mobile users point of view, question arises: Does HTTP/2 offer improved energy consumption performance achieving longer battery life? P In this paper, we compare the energy consumption of HTTP/2 with its predecessor (i.e., HTTP/1.1) using e a variety of real world and synthetic test scenarios. We also investigate how Transport Layer Security r (TLS) impacts the energy consumption of the mobile devices. Our study suggests that Round Trip Time P (RTT) is one of the biggest factors in deciding how advantageous is HTTP/2 compared to HTTP/1.1. We conclude that for networks with higher RTTs, HTTP/2 has better energy consumption performance than HTTP/1.1. Keywords: HTTP/2, HTTP/1.1, Energy Performance, Software Engineering 1 INTRODUCTION In recent years, the popularity of mobile devices (e.g., smartphones, and tablets) has dramatically increased, as millions of users are using these devices in their daily lives. -

Paper, We Conduct the first Systematic Investigation by Results Uncover New Observations and Insights
2017 IEEE 37th International Conference on Distributed Computing Systems Are HTTP/2 Servers Ready Yet? Muhui Jiang∗, Xiapu Luo∗§, Tungngai Miu†, Shengtuo Hu∗, and Weixiong Rao‡ ∗Department of Computing, The Hong Kong Polytechnic University †Nexusguard Limited ‡School of Software Engineering, Tongji University Abstract—Superseding HTTP/1.1, the dominating web pro- Apache, H2O, Lightspeed, nghttpd and Tengine) and measur- tocol, HTTP/2 promises to make web applications faster and ing the top 1 million Alexa web sites. More precisely, we safer by introducing many new features, such as multiplexing, propose new methods to characterize how the servers support header compression, request priority, server push, etc. Although a few recent studies examined the adoption of HTTP/2 and six new features, including multiplexing, flow control, request evaluated its impacts, little is known about whether the popular priority, server push, header compression, and HTTP/2 ping. HTTP/2 servers have correctly realized the new features and We have realized these methods in a tool named H2Scope how the deployed servers use these features. To fill in the gap, for conducting the large-scale measurement. The measurement in this paper, we conduct the first systematic investigation by results uncover new observations and insights. For example, inspecting six popular implementations of HTTP/2 servers (i.e., Nginx, Apache, H2O, Lightspeed, nghttpd and Tengine) and not all implementations strictly follow RFC 7540 as shown measuring the top 1 million Alexa web sites. In particular, we in Table III. Some new features, like server push and priority propose new methods and develop a tool named H2Scope to mechanism, have not been well implemented and fully used assess the new features in those servers. -

Unikraft: Fast, Specialized Unikernels the Easy Way
Unikraft: Fast, Specialized Unikernels the Easy Way Simon Kuenzer Vlad-Andrei Bădoiu∗ Hugo Lefeuvre∗ NEC Laboratories Europe GmbH University Politehnica of Bucharest The University of Manchester Sharan Santhanam∗ Alexander Jung∗ Gaulthier Gain∗ NEC Laboratories Europe GmbH Lancaster University University of Liège ∗ Cyril Soldani Costin Lupu S, tefan Teodorescu University of Liège University Politehnica of Bucharest University Politehnica of Bucharest Costi Răducanu Cristian Banu Laurent Mathy University Politehnica of Bucharest University Politehnica of Bucharest University of Liège Răzvan Deaconescu Costin Raiciu Felipe Huici University Politehnica of Bucharest University Politehnica of Bucharest NEC Laboratories Europe GmbH Abstract 65], or providing efficient container environments [62, 76], Unikernels are famous for providing excellent performance to give some examples. Even in the hardware domain, and in terms of boot times, throughput and memory consump- especially with the demise of Moore’s law, manufacturers tion, to name a few metrics. However, they are infamous are increasingly leaning towards hardware specialization to for making it hard and extremely time consuming to extract achieve ever better performance; the machine learning field such performance, and for needing significant engineering is a primary exponent of this [30, 32, 34]. effort in order to port applications to them. We introduce In the virtualization domain, unikernels are the golden Unikraft, a novel micro-library OS that (1) fully modularizes standard for specialization, showing impressive results in OS primitives so that it is easy to customize the unikernel terms of throughput, memory consumption, and boot times, and include only relevant components and (2) exposes a set among others [36, 40, 45, 47, 48]. -

Fast, Specialized Unikernels the Easy Way
Unikraft: Fast, Specialized Unikernels the Easy Way Simon Kuenzer Vlad-Andrei Bădoiu Hugo Lefeuvre Sharan Santhanam Alexander Jung Gaulthier Gain Cyril Soldani Costin Lupu Stefan Teodorescu Costi Răducanu Cristian Banu Laurent Mathy Răzvan Deaconescu Costin Raiciu Felipe Huici Eurosys 2021, April 26th-28th Specialization = High Performance software hardware Unikernels = Specialized Virtual Machines • Easy to build and run GOALS • Easy or no app porting • Great performance Design Principles 1. Fully modular kernel 2. Provide high performance specialized APIs Design Principles 1. Fully modular kernel 2. Provide high performance specialized APIs Why not Linux? 207 13 111 15 164 30 151 13 311 101 551 6 24 117 15 locking 4 2 34 2 119 5 7 91 1 39 sched 3 720 2 36 ipc 8 4 5 60 Unikra-77 is built1 from scratch to be fully modular53 time 16 90 8 2 27 net 465 fs 11 107 17 2 mm 124 11 110 1 10 19 25 23 irq 7 122 3 security 6 36 46 10 67 block 14 28 22 226 2 37 6 68 95 277 213 With Unikraft Hello World 1 posix-layer boot 3 nolibc ukboot 1 argparse 6 1 ukargparse mm1 ukallocbuddy 3 ukalloc 20 security 1 9 10 6 1 1 posix-layer mm fs nginx 39 sched 3 1 1 2 2 time locking 2 net 7 1 ipc Doing it with existing unikernels? (1) Require significant expert work to build Unikraft(2) is Theybuiltare fromoften scratchnon-POSIX (with compliant borrowing) (3) The (uni)kernels are still monolithic Design Principles 1. -

Student Resume Book
Class of 2018 STUDENT RESUME BOOK [email protected] CLASS OF 2018 PROFILE 44% WOMEN 41 CLASS SIZE INTERNSHIP PLACEMENTS 1.5 A.T. KEARNEY ABC SUPPLY AVERAGE YEARS PRIOR AIRBNB WORK EXPERIENCE APPLE, INC BALYASNY ASSET MANAGEMENT BUZZFEED CME GROUP PRIOR DEGREE ENOVA CONCENTRATIONS EXPEDIA FORD MOTOR COMPANY SOCIAL BUSINESS & GODADDY SCIENCES 1.16% HCSC FINANCE 11.24% KPMG OTHER 2.33% LAZARD ECONOMICS 25.19% LINKEDIN MICROSOFT MOLEX, INC STEM 69.38% NASA NORDSTROM, INC ON POINT TECHNOLOGY OPEX ANALYTICS PROCTOR & GAMBLE CO SCHNEIDER COMPUTER SCIENCE 4.65% SOCIAL FINANCE TRANSUNION, LLC SCIENCE 5.81% TRELLO UNIVERSITY OF CHICAGO ENGINEERING 22.09% ZURICH AMERICAN INSURANCE CO MATHEMATICS & STATISTICS 36.82% Class of 2018 PATRICK CHANG JAMIE CHEN JERRY CHEN JOHNNY CHIU LUCA COLOMBO GRACE CUI ANISHA DUBHASHI JILL FAN MATT GALLAGHER MICHAEL GAO LAUREN GARDINER JOE GILBERT SARAH GREENWOOD VARUN GUPTA VERONICA HSIEH WENZE HU RISHABH JOSHI BROOKE KENNEDY ARVIND KOUL TUCKER LEWIS WEI LI EMMA LI ZILI LI JUNXIONG LIU Class of 2018 YUQING LIU DANIEL LÜTOLF-CARROLL SPENCER MOON ERIC PAN MICHAEL PAULEEN CHRIS ROZOLIS WILL SONG CHRISTA SPIETH PENNY SUN PHYLLIS SUN SAURABH TRIPATHI VINCENT WANG LOGAN WILSON HAO XIAO WENJING YANG TONG YIN ETHEL ZHANG PATRICK CHANG Product Manager by Trade Data Scientist in Training 510.710.7317 | [email protected] EDUCATION Northwestern University The Master of Science in Analytics is a cross-disciplinary master’s degree with an Master of Science in Analytics applied curriculum exploring data science, machine learning, and business informatics. Sep 2017 – Dec 2018 Developed profiling clusters and predictive pricing model for the Chicago Parks Honors: Graduate Fellowship District Day Camp which accounts for 33% of the Parks District’s revenue. -

Kansas Register 1
Notice of Forfeiture - Domestic Kansas Register 1 State of Kansas 1606 Cannabis Company, LLC, Emporia, KS 161st Street Development, LLC, Ponte Vedra Beach, FL Secretary of State 1619 Investments, LLC, Leawood, KS 1625 S Webb, LLC, San Antonio, TX Notice of Forfeiture 1625 W Prairie, LLC, Oklahoma City, OK 16329 Sunset, Inc., Leawood, KS In accordance with Kansas statutes, the following busi- 16329 South, LLC, Lenexa, KS ness entities organized under the laws of Kansas and the 1640 East, LLC, Wichita, KS foreign business entities authorized to do business in 1701 S. Seneca, LLC, Wichita, KS 1731 W39th, LLC, Kansas City, KS Kansas were forfeited during the month of July 2021 for 1863, L.L.C., Kansas City, KS failure to timely file an annual report and pay the annual 1866 Bar & Grill, LLC, Tongonoxie, KS report fee. 1900 Johnson Drive Partners, LLC, Wichita, KS Please Note: The following list represents business 1910 Lulu, LLC, Wichita, KS entities forfeited in July. Any business entity listed may 1920 Enterprises, LLC, Topeka, KS 1922 Rose, LLC, Wichita, KS have filed for reinstatement and be considered in good 1928 N 24th, LLC, Oklahoma City, OK standing. To check the status of a business entity go to the 1930 N 25th Street, LLC, Oklahoma City, OK Kansas Business Center’s Business Entity Search Station at 2 Compadres, LLC, Overland Park, KS https://www.kansas.gov/bess/flow/main?execution=e2s4 2 D Construction, LLC, Lorraine, KS 2 Dog Studio, LLC, Lawrence, KS (select Business Entity Database) or contact the Business 2 Guys Automotive, LLC, Newton, KS Services Division at 785-296-4564. -

2020 Kansas Permit Program Review Final Report
Program Review of KDHE’s Air Permitting Programs Conducted: August 2020 U.S. EPA, Region 7 Air Permitting and Standards Branch Air and Radiation Division Kansas Bureau of Air Program Review Report Contents Contents A. INTRODUCTION .................................................................................................................. 1 B. SUMMARY of FINDINGS and CONCLUSIONS ................................................................ 2 C. CATEGORIZED COMMENTS ............................................................................................. 3 1. General ................................................................................................................................. 3 a. Staffing ......................................................................................................................... 3 b. Other General Observations ......................................................................................... 4 2. Construction Permitting ....................................................................................................... 5 a. Assuring Healthy Air Quality ...................................................................................... 5 b. Other Construction Permitting Observations ............................................................... 6 3. NSPS / NESHAP ................................................................................................................. 6 4. Operating Permits ...............................................................................................................