Natural Language Processing with Pandas Dataframes
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Sagemath and Sagemathcloud
Viviane Pons Ma^ıtrede conf´erence,Universit´eParis-Sud Orsay [email protected] { @PyViv SageMath and SageMathCloud Introduction SageMath SageMath is a free open source mathematics software I Created in 2005 by William Stein. I http://www.sagemath.org/ I Mission: Creating a viable free open source alternative to Magma, Maple, Mathematica and Matlab. Viviane Pons (U-PSud) SageMath and SageMathCloud October 19, 2016 2 / 7 SageMath Source and language I the main language of Sage is python (but there are many other source languages: cython, C, C++, fortran) I the source is distributed under the GPL licence. Viviane Pons (U-PSud) SageMath and SageMathCloud October 19, 2016 3 / 7 SageMath Sage and libraries One of the original purpose of Sage was to put together the many existent open source mathematics software programs: Atlas, GAP, GMP, Linbox, Maxima, MPFR, PARI/GP, NetworkX, NTL, Numpy/Scipy, Singular, Symmetrica,... Sage is all-inclusive: it installs all those libraries and gives you a common python-based interface to work on them. On top of it is the python / cython Sage library it-self. Viviane Pons (U-PSud) SageMath and SageMathCloud October 19, 2016 4 / 7 SageMath Sage and libraries I You can use a library explicitly: sage: n = gap(20062006) sage: type(n) <c l a s s 'sage. interfaces .gap.GapElement'> sage: n.Factors() [ 2, 17, 59, 73, 137 ] I But also, many of Sage computation are done through those libraries without necessarily telling you: sage: G = PermutationGroup([[(1,2,3),(4,5)],[(3,4)]]) sage : G . g a p () Group( [ (3,4), (1,2,3)(4,5) ] ) Viviane Pons (U-PSud) SageMath and SageMathCloud October 19, 2016 5 / 7 SageMath Development model Development model I Sage is developed by researchers for researchers: the original philosophy is to develop what you need for your research and share it with the community. -

Mastering Machine Learning with Scikit-Learn
www.it-ebooks.info Mastering Machine Learning with scikit-learn Apply effective learning algorithms to real-world problems using scikit-learn Gavin Hackeling BIRMINGHAM - MUMBAI www.it-ebooks.info Mastering Machine Learning with scikit-learn Copyright © 2014 Packt Publishing All rights reserved. No part of this book may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, without the prior written permission of the publisher, except in the case of brief quotations embedded in critical articles or reviews. Every effort has been made in the preparation of this book to ensure the accuracy of the information presented. However, the information contained in this book is sold without warranty, either express or implied. Neither the author, nor Packt Publishing, and its dealers and distributors will be held liable for any damages caused or alleged to be caused directly or indirectly by this book. Packt Publishing has endeavored to provide trademark information about all of the companies and products mentioned in this book by the appropriate use of capitals. However, Packt Publishing cannot guarantee the accuracy of this information. First published: October 2014 Production reference: 1221014 Published by Packt Publishing Ltd. Livery Place 35 Livery Street Birmingham B3 2PB, UK. ISBN 978-1-78398-836-5 www.packtpub.com Cover image by Amy-Lee Winfield [email protected]( ) www.it-ebooks.info Credits Author Project Coordinator Gavin Hackeling Danuta Jones Reviewers Proofreaders Fahad Arshad Simran Bhogal Sarah -

Tuto Documentation Release 0.1.0
Tuto Documentation Release 0.1.0 DevOps people 2020-05-09 09H16 CONTENTS 1 Documentation news 3 1.1 Documentation news 2020........................................3 1.1.1 New features of sphinx.ext.autodoc (typing) in sphinx 2.4.0 (2020-02-09)..........3 1.1.2 Hypermodern Python Chapter 5: Documentation (2020-01-29) by https://twitter.com/cjolowicz/..................................3 1.2 Documentation news 2018........................................4 1.2.1 Pratical sphinx (2018-05-12, pycon2018)...........................4 1.2.2 Markdown Descriptions on PyPI (2018-03-16)........................4 1.2.3 Bringing interactive examples to MDN.............................5 1.3 Documentation news 2017........................................5 1.3.1 Autodoc-style extraction into Sphinx for your JS project...................5 1.4 Documentation news 2016........................................5 1.4.1 La documentation linux utilise sphinx.............................5 2 Documentation Advices 7 2.1 You are what you document (Monday, May 5, 2014)..........................8 2.2 Rédaction technique...........................................8 2.2.1 Libérez vos informations de leurs silos.............................8 2.2.2 Intégrer la documentation aux processus de développement..................8 2.3 13 Things People Hate about Your Open Source Docs.........................9 2.4 Beautiful docs.............................................. 10 2.5 Designing Great API Docs (11 Jan 2012)................................ 10 2.6 Docness................................................. -

Installing Python Ø Basics of Programming • Data Types • Functions • List Ø Numpy Library Ø Pandas Library What Is Python?
Python in Data Science Programming Ha Khanh Nguyen Agenda Ø What is Python? Ø The Python Ecosystem • Installing Python Ø Basics of Programming • Data Types • Functions • List Ø NumPy Library Ø Pandas Library What is Python? • “Python is an interpreted high-level general-purpose programming language.” – Wikipedia • It supports multiple programming paradigms, including: • Structured/procedural • Object-oriented • Functional The Python Ecosystem Source: Fabien Maussion’s “Getting started with Python” Workshop Installing Python • Install Python through Anaconda/Miniconda. • This allows you to create and work in Python environments. • You can create multiple environments as needed. • Highly recommended: install Python through Miniconda. • Are we ready to “play” with Python yet? • Almost! • Most data scientists use Python through Jupyter Notebook, a web application that allows you to create a virtual notebook containing both text and code! • Python Installation tutorial: [Mac OS X] [Windows] For today’s seminar • Due to the time limitation, we will be using Google Colab instead. • Google Colab is a free Jupyter notebook environment that runs entirely in the cloud, so you can run Python code, write report in Jupyter Notebook even without installing the Python ecosystem. • It is NOT a complete alternative to installing Python on your local computer. • But it is a quick and easy way to get started/try out Python. • You will need to log in using your university account (possible for some schools) or your personal Google account. Basics of Programming Indentations – Not Braces • Other languages (R, C++, Java, etc.) use braces to structure code. # R code (not Python) a = 10 if (a < 5) { result = TRUE b = 0 } else { result = FALSE b = 100 } a = 10 if (a < 5) { result = TRUE; b = 0} else {result = FALSE; b = 100} Basics of Programming Indentations – Not Braces • Python uses whitespaces (tabs or spaces) to structure code instead. -

An Introduction to Numpy and Scipy
An introduction to Numpy and Scipy Table of contents Table of contents ............................................................................................................................ 1 Overview ......................................................................................................................................... 2 Installation ...................................................................................................................................... 2 Other resources .............................................................................................................................. 2 Importing the NumPy module ........................................................................................................ 2 Arrays .............................................................................................................................................. 3 Other ways to create arrays............................................................................................................ 7 Array mathematics .......................................................................................................................... 8 Array iteration ............................................................................................................................... 10 Basic array operations .................................................................................................................. 11 Comparison operators and value testing .................................................................................... -
Cheat Sheet Pandas Python.Indd
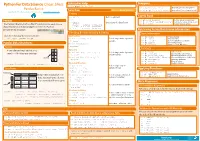
Python For Data Science Cheat Sheet Asking For Help Dropping >>> help(pd.Series.loc) Pandas Basics >>> s.drop(['a', 'c']) Drop values from rows (axis=0) Selection Also see NumPy Arrays >>> df.drop('Country', axis=1) Drop values from columns(axis=1) Learn Python for Data Science Interactively at www.DataCamp.com Getting Sort & Rank >>> s['b'] Get one element -5 Pandas >>> df.sort_index() Sort by labels along an axis Get subset of a DataFrame >>> df.sort_values(by='Country') Sort by the values along an axis The Pandas library is built on NumPy and provides easy-to-use >>> df[1:] Assign ranks to entries Country Capital Population >>> df.rank() data structures and data analysis tools for the Python 1 India New Delhi 1303171035 programming language. 2 Brazil Brasília 207847528 Retrieving Series/DataFrame Information Selecting, Boolean Indexing & Setting Basic Information Use the following import convention: By Position (rows,columns) Select single value by row & >>> df.shape >>> import pandas as pd >>> df.iloc[[0],[0]] >>> df.index Describe index Describe DataFrame columns 'Belgium' column >>> df.columns Pandas Data Structures >>> df.info() Info on DataFrame >>> df.iat([0],[0]) Number of non-NA values >>> df.count() Series 'Belgium' Summary A one-dimensional labeled array a 3 By Label Select single value by row & >>> df.sum() Sum of values capable of holding any data type b -5 >>> df.loc[[0], ['Country']] Cummulative sum of values 'Belgium' column labels >>> df.cumsum() >>> df.min()/df.max() Minimum/maximum values c 7 Minimum/Maximum index -

Bioimage Analysis Fundamentals in Python with Scikit-Image, Napari, & Friends
Bioimage analysis fundamentals in Python with scikit-image, napari, & friends Tutors: Juan Nunez-Iglesias ([email protected]) Nicholas Sofroniew ([email protected]) Session 1: 2020-11-30 17:30 UTC – 2020-11-30 22:00 UTC Session 2: 2020-12-01 07:30 UTC – 2020-12-01 12:00 UTC ## Information about the tutors Juan Nunez-Iglesias is a Senior Research Fellow at Monash Micro Imaging, Monash University, Australia. His work on image segmentation in connectomics led him to contribute to the scikit-image library, of which he is now a core maintainer. He has since co-authored the book Elegant SciPy and co-created napari, an n-dimensional image viewer in Python. He has taught image analysis and scientific Python at conferences, university courses, summer schools, and at private companies. Nicholas Sofroniew leads the Imaging Tech Team at the Chan Zuckerberg Initiative. There he's focused on building tools that provide easy access to reproducible, quantitative bioimage analysis for the research community. He has a background in mathematics and systems neuroscience research, with a focus on microscopy and image analysis, and co-created napari, an n-dimensional image viewer in Python. ## Title and abstract of the tutorial. Title: **Bioimage analysis fundamentals in Python** **Abstract** The use of Python in science has exploded in the past decade, driven by excellent scientific computing libraries such as NumPy, SciPy, and pandas. In this tutorial, we will explore some of the most critical Python libraries for scientific computing on images, by walking through fundamental bioimage analysis applications of linear filtering (aka convolutions), segmentation, and object measurement, leveraging the napari viewer for interactive visualisation and processing. -

Pandas: Powerful Python Data Analysis Toolkit Release 0.25.3
pandas: powerful Python data analysis toolkit Release 0.25.3 Wes McKinney& PyData Development Team Nov 02, 2019 CONTENTS i ii pandas: powerful Python data analysis toolkit, Release 0.25.3 Date: Nov 02, 2019 Version: 0.25.3 Download documentation: PDF Version | Zipped HTML Useful links: Binary Installers | Source Repository | Issues & Ideas | Q&A Support | Mailing List pandas is an open source, BSD-licensed library providing high-performance, easy-to-use data structures and data analysis tools for the Python programming language. See the overview for more detail about whats in the library. CONTENTS 1 pandas: powerful Python data analysis toolkit, Release 0.25.3 2 CONTENTS CHAPTER ONE WHATS NEW IN 0.25.2 (OCTOBER 15, 2019) These are the changes in pandas 0.25.2. See release for a full changelog including other versions of pandas. Note: Pandas 0.25.2 adds compatibility for Python 3.8 (GH28147). 1.1 Bug fixes 1.1.1 Indexing • Fix regression in DataFrame.reindex() not following the limit argument (GH28631). • Fix regression in RangeIndex.get_indexer() for decreasing RangeIndex where target values may be improperly identified as missing/present (GH28678) 1.1.2 I/O • Fix regression in notebook display where <th> tags were missing for DataFrame.index values (GH28204). • Regression in to_csv() where writing a Series or DataFrame indexed by an IntervalIndex would incorrectly raise a TypeError (GH28210) • Fix to_csv() with ExtensionArray with list-like values (GH28840). 1.1.3 Groupby/resample/rolling • Bug incorrectly raising an IndexError when passing a list of quantiles to pandas.core.groupby. DataFrameGroupBy.quantile() (GH28113). -

Scipy and Numpy
www.it-ebooks.info SciPy and NumPy Eli Bressert Beijing • Cambridge • Farnham • Koln¨ • Sebastopol • Tokyo www.it-ebooks.info 9781449305468_text.pdf 1 10/31/12 2:35 PM SciPy and NumPy by Eli Bressert Copyright © 2013 Eli Bressert. All rights reserved. Printed in the United States of America. Published by O’Reilly Media, Inc., 1005 Gravenstein Highway North, Sebastopol, CA 95472. O’Reilly books may be purchased for educational, business, or sales promotional use. Online editions are also available for most titles (http://my.safaribooksonline.com). For more information, contact our corporate/institutional sales department: (800) 998-9938 or [email protected]. Interior Designer: David Futato Project Manager: Paul C. Anagnostopoulos Cover Designer: Randy Comer Copyeditor: MaryEllen N. Oliver Editors: Rachel Roumeliotis, Proofreader: Richard Camp Meghan Blanchette Illustrators: EliBressert,LaurelMuller Production Editor: Holly Bauer November 2012: First edition Revision History for the First Edition: 2012-10-31 First release See http://oreilly.com/catalog/errata.csp?isbn=0636920020219 for release details. Nutshell Handbook, the Nutshell Handbook logo, and the O’Reilly logo are registered trademarks of O’Reilly Media, Inc. SciPy and NumPy, the image of a three-spined stickleback, and related trade dress are trademarks of O’Reilly Media, Inc. Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and O’Reilly Media, Inc., was aware of a trademark claim, the designations have been printed in caps or initial caps. While every precaution has been taken in the preparation of this book, the publisher and authors assume no responsibility for errors or omissions, or for damages resulting from the use of the information contained herein. -

Scikit-Learn
Scikit-Learn i Scikit-Learn About the Tutorial Scikit-learn (Sklearn) is the most useful and robust library for machine learning in Python. It provides a selection of efficient tools for machine learning and statistical modeling including classification, regression, clustering and dimensionality reduction via a consistence interface in Python. This library, which is largely written in Python, is built upon NumPy, SciPy and Matplotlib. Audience This tutorial will be useful for graduates, postgraduates, and research students who either have an interest in this Machine Learning subject or have this subject as a part of their curriculum. The reader can be a beginner or an advanced learner. Prerequisites The reader must have basic knowledge about Machine Learning. He/she should also be aware about Python, NumPy, Scipy, Matplotlib. If you are new to any of these concepts, we recommend you take up tutorials concerning these topics, before you dig further into this tutorial. Copyright & Disclaimer Copyright 2019 by Tutorials Point (I) Pvt. Ltd. All the content and graphics published in this e-book are the property of Tutorials Point (I) Pvt. Ltd. The user of this e-book is prohibited to reuse, retain, copy, distribute or republish any contents or a part of contents of this e-book in any manner without written consent of the publisher. We strive to update the contents of our website and tutorials as timely and as precisely as possible, however, the contents may contain inaccuracies or errors. Tutorials Point (I) Pvt. Ltd. provides no guarantee regarding the accuracy, timeliness or completeness of our website or its contents including this tutorial. -

Image Processing with Scikit-Image Emmanuelle Gouillart
Image processing with scikit-image Emmanuelle Gouillart Surface, Glass and Interfaces, CNRS/Saint-Gobain Paris-Saclay Center for Data Science Image processing Manipulating images in order to retrieve new images or image characteristics (features, measurements, ...) Often combined with machine learning Principle Some features The world is getting more and more visual Image processing Manipulating images in order to retrieve new images or image characteristics (features, measurements, ...) Often combined with machine learning Principle Some features The world is getting more and more visual Image processing Manipulating images in order to retrieve new images or image characteristics (features, measurements, ...) Often combined with machine learning Principle Some features The world is getting more and more visual Image processing Manipulating images in order to retrieve new images or image characteristics (features, measurements, ...) Often combined with machine learning Principle Some features The world is getting more and more visual Image processing Manipulating images in order to retrieve new images or image characteristics (features, measurements, ...) Often combined with machine learning Principle Some features The world is getting more and more visual Principle Some features The world is getting more and more visual Image processing Manipulating images in order to retrieve new images or image characteristics (features, measurements, ...) Often combined with machine learning Principle Some features scikit-image http://scikit-image.org/ A module of the Scientific Python stack Language: Python Core modules: NumPy, SciPy, matplotlib Application modules: scikit-learn, scikit-image, pandas, ... A general-purpose image processing library open-source (BSD) not an application (ImageJ) less specialized than other libraries (e.g. OpenCV for computer vision) 1 Principle Principle Some features 1 First steps from skimage import data , io , filter image = data . -

Sphinx As a Tool for Documenting Technical Projects 1
SPHINX AS A TOOL FOR DOCUMENTING TECHNICAL PROJECTS 1 Sphinx as a Tool for Documenting Technical Projects Javier García-Tobar Abstract—Documentation is a vital part of a technical project, yet is sometimes overlooked because of its time-consuming nature. A successful documentation system can therefore benefit relevant organizations and individuals. The focus of this paper is to summarize the main features of Sphinx: an open-source tool created to generate Python documentation formatted into standard files (HTML, PDF and ePub). Based on its results, this research recommends the use of Sphinx for the more efficient writing and managing of a project’s technical documentation. Keywords—project, documentation, Python, Sphinx. —————————— —————————— 1 INTRODUCTION In a technologically advanced and fast-paced modern socie- tation is encouraged in the field of programming because it ty, computer-stored data is found in immense quantities. gives the programmer a copy of their previous work. Fur- Writers, researchers, journalists and teachers – to name but a thermore, it helps other programmers to modify their coding, few relevant fields – have acknowledged the issue of and it benefits the pooling of information within an organi- dealing with ever-increasing quantities of data. The data can zation. appear in many forms. Therefore, most computer-literate, Software documentation should be focused on transmit- modern professionals welcome software (or hardware) that ting information that is useful and meaningful rather than aids them in managing and collating substantial amounts of information that is precise and exact (Forward and Leth- data formats. bridge, 2002). Software tools are used to document a pro- All technical projects produce a large quantity of docu- gram’s source code.