An Investigation Into Introducing Test-Driven Development Into a Legacy Project
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Licensing Information User Manual Release 9.1 F13415-01
Oracle® Hospitality Cruise Fleet Management Licensing Information User Manual Release 9.1 F13415-01 August 2019 LICENSING INFORMATION USER MANUAL Oracle® Hospitality Fleet Management Licensing Information User Manual Version 9.1 Copyright © 2004, 2019, Oracle and/or its affiliates. All rights reserved. This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error- free. If you find any errors, please report them to us in writing. If this software or related documentation is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, then the following notice is applicable: U.S. GOVERNMENT END USERS: Oracle programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, delivered to U.S. Government end users are "commercial computer software" pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, use, duplication, disclosure, modification, and adaptation of the programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, shall be subject to license terms and license restrictions applicable to the programs. -
Create Mobile Apps with HTML5, Javascript and Visual Studio
Create mobile apps with HTML5, JavaScript and Visual Studio DevExtreme Mobile is a single page application (SPA) framework for your next Windows Phone, iOS and Android application, ready for online publication or packaged as a store-ready native app using Apache Cordova (PhoneGap). With DevExtreme, you can target today’s most popular mobile devices with a single codebase and create interactive solutions that will amaze. Get started today… ・ Leverage your existing Visual Studio expertise. ・ Build a real app, not just a web page. ・ Deliver a native UI and experience on all supported devices. ・ Use over 30 built-in touch optimized widgets. Learn more and download your free trial devexpress.com/mobile All trademarks or registered trademarks are property of their respective owners. Untitled-4 1 10/2/13 11:58 AM APPLICATIONS & DEVELOPMENT SPECIAL GOVERNMENT ISSUE INSIDE Choose a Cloud Network for Government-Compliant magazine Applications Geo-Visualization of SPECIAL GOVERNMENT ISSUE & DEVELOPMENT SPECIAL GOVERNMENT ISSUE APPLICATIONS Government Data Sources Harness Open Data with CKAN, OData and Windows Azure Engage Communities with Open311 THE DIGITAL GOVERNMENT ISSUE Inside the tools, technologies and APIs that are changing the way government interacts with citizens. PLUS SPECIAL GOVERNMENT ISSUE APPLICATIONS & DEVELOPMENT SPECIAL GOVERNMENT ISSUE & DEVELOPMENT SPECIAL GOVERNMENT ISSUE APPLICATIONS Enhance Services with Windows Phone 8 Wallet and NFC Leverage Web Assets as Data Sources for Apps APPLICATIONS & DEVELOPMENT SPECIAL GOVERNMENT ISSUE ISSUE GOVERNMENT SPECIAL DEVELOPMENT & APPLICATIONS Untitled-1 1 10/4/13 11:40 AM CONTENTS OCTOBER 2013/SPECIAL GOVERNMENT ISSUE OCTOBER 2013/SPECIAL GOVERNMENT ISSUE magazine FEATURES MOHAMMAD AL-SABT Editorial Director/[email protected] Geo-Visualization of Government KENT SHARKEY Site Manager Data Sources MICHAEL DESMOND Editor in Chief/[email protected] Malcolm Hyson .......................................... -

Automatic Refactoring of Large Codebases
Masaryk University Faculty of Informatics Automatic Refactoring of Large Codebases Master’s Thesis Bc. Matúš Pietrzyk Brno, Fall 2015 Replace this page with a copy of the official signed thesis assignment and the copy of the Statement of an Author. Declaration Hereby I declare that this paper is my original authorial work, which I have worked out by my own. All sources, references and literature used or excerpted during elaboration of this work are properly cited and listed in complete reference to the due source. Bc. Matúš Pietrzyk Advisor: Bruno Rossi, PhD i Acknowledgement I would like to thank my supervisor Bruno Rossi, PhD for his contin- uous feedback and support during the writing of this thesis. I would also like to thank Viktor Jablonský from FNZ for his support during practical part of the thesis. ii Abstract The aim of this thesis is to investigate different techniques for code refactoring using semi-automatic and automatic refactoring tools. The practical part focuses on providing automatic refactoring support for legacy source code using Roslyn compiler. iii Keywords Refactoring, Roslyn, Compiler, Code Smells, Legacy Code, SOLID, Design Smells, Large Codebase iv Contents 1 Introduction ............................1 1.1 Thesis Structure ........................1 2 Issue Description .........................2 2.1 About FNZ ..........................2 2.2 Current State of the Codebase .................2 3 Refactoring ............................4 3.1 Key Advantages of Refactoring ................5 3.2 Refactoring Strategies .....................6 3.3 Design Smells .........................7 3.3.1 Rigidity . .8 3.3.2 Fragility . .8 3.3.3 Immobility . .8 3.3.4 Viscosity . .8 3.3.5 Needless Complexity . -

Test-Driving ASP.NET MVC Dino Esposito, Page 6 Keith Burnell
Untitled-10 1 6/6/12 11:32 AM THE MICROSOFT JOURNAL FOR DEVELOPERS JULY 2012 VOL 27 NO 7 Pragmatic Tips for Building Better COLUMNS Windows Phone Apps CUTTING EDGE Andrew Byrne .......................................................................... 24 Mobile Site Development, Part 2: Design Test-Driving ASP.NET MVC Dino Esposito, page 6 Keith Burnell ............................................................................ 36 DATA POINTS Create and Consume Writing a Compass Application JSON-Formatted OData for Windows Phone Julie Lerman, page 10 Donn Morse ............................................................................ 48 FORECAST: CLOUDY Mixing Node.js into Your Hadoop on Windows Azure Windows Azure Solution Joseph Fultz, page 16 Lynn Langit .............................................................................. 54 TEST RUN How to Handle Relational Data Classifi cation and Prediction Using Neural Networks in a Distributed Cache James McCaffrey, page 74 Iqbal Khan ............................................................................... 60 THE WORKING A Smart Thermostat on the Service Bus PROGRAMMER The Science of Computers Clemens Vasters ....................................................................... 66 Ted Neward and Joe Hummel, page 80 TOUCH AND GO Windows Phone Motion and 3D Views Charles Petzold, page 84 DON’T GET ME STARTED The Patient Knows What’s Wrong With Him David Platt, page 88 Start a Revolution Refuse to choose between desktop and mobile. With the brand new NetAdvantage for .NET, you can create awesome apps with killer data visualization today, on any platform or device. Get your free, fully supported trial today! www.infragistics.com/NET Infragistics Sales US 800 231 8588 • Europe +44 (0) 800 298 9055 • India +91 80 4151 8042 • APAC (+61) 3 9982 4545 Copyright 1996-2012 Infragistics, Inc. All rights reserved. Infragistics and NetAdvantage are registered trademarks of Infragistics, Inc. The Infragistics logo is a trademark of Infragistics, Inc. -

Buyers Guide Product Listings
BUYERS GUIDE PRODUCT LISTINGS Visual Studio Magazine Buyers’ Guide Product Listings The 2009 Visual Studio Magazine Buyers’ Guide listings comprise more than 700 individual products and services, ranging from developer tooling and UI components to Web hosting and instructor-led training. Included for each product is contact and pricing information. Keep in mind that many products come in multiple SKUs and with varied license options, so it’s always a good idea to contact vendors directly for specific pricing. The developer tools arena is a vast and growing space. As such, we’re always on the prowl for new tools and vendors. Know of a product our readers might want to learn more about? E-mail us at [email protected]. BUG & FEATURE TRACKING Gemini—CounterSoft Starts at $1189 • countersoft.com • +44 (0)1753 824000 Rational ClearQuest—IBM Rational Software $1,810 • ibm.com/rational • 888-426-3774 IssueNet Intercept—Elsinore Technologies Call for price • elsitech.com • 866-866-0034 FogBugz 7.0—Fog Creek Software $199 • fogcreek.com • 888-364-2849; 212-279-2076 SilkPerformer—Borland Call for price • borland.com • 800-632-2864; 512-340-2200 OnTime 2009 Professional—Axosoft Starts at $795 for five users • axosoft.com • 800-653-0024; SourceOffSite 4.2—SourceGear 480-362-1900 $239 • sourcegear.com • 217-356-0105 Alexsys Team 2.10—Alexsys Surround SCM 2009—Seapine Software Starts at $145 • alexcorp.com • 888-880-2539; 781-279-0170 Call for price • seapine.com • 888-683-6456; 513-754-1655 AppLife DNA—Kinetic Jump Software TeamInspector—Borland -
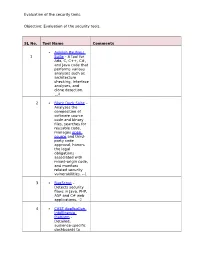
Evaluation of the Security Tools. SL No. Tool Name Comments 1
Evaluation of the security tools. Objective: Evaluation of the security tools. SL No. Tool Name Comments Axivion Bauhaus 1 Suite – A tool for Ada, C, C++, C#, and Java code that performs various analyses such as architecture checking, interface analyses, and clone detection. 4 2 Black Duck Suite – Analyzes the composition of software source code and binary files, searches for reusable code, manages open source and third- party code approval, honors the legal obligations associated with mixed-origin code, and monitors related security vulnerabilities. --1 3 BugScout – Detects security flaws in Java, PHP, ASP and C# web applications. -2 4 CAST Application Intelligence Platform – Detailed, audience-specific dashboards to Evaluation of the security tools. measure quality and productivity. 30+ languages, C, C++, Java, .NET, Oracle, PeopleSoft, SAP, Siebel, Spring, Struts, Hibernate and all major databases. 5 ChecKing – Integrated software quality portal that helps manage the quality of all phases of software development. It includes static code analyzers for Java, JSP, Javascript, HTML, XML, .NET (C#, ASP.NET, VB.NET, etc.), PL/SQL, embedded SQL, SAP ABAP IV, Natural/Adabas, C, C++, Cobol, JCL, and PowerBuilder. 6 ConQAT – Continuous quality assessment toolkit that allows flexible configuration of quality analyses (architecture conformance, clone detection, quality metrics, etc.) and dashboards. Supports Java, C#, C++, JavaScript, ABAP, Ada and many other languages. Evaluation of the security tools. 7 Coverity SAVE – A static code analysis tool for C, C++, C# and Java source code. Coverity commercialized a research tool for finding bugs through static analysis, the Stanford Checker, which used abstract interpretation to identify defects in source code. -

WINDOWS SURFACES Microsoft’S New Client OS Is Fl Ying High, but Should You 7 Rush to Migrate Your Apps to Windows 7? OCTOBER 2009 Volume 19, No
VisualStudioMagazine.com PLUS Four ways to synchronize threads with your app’s UI Inside Microsoft’s .NET Rx Framework WINDOWS SURFACES Microsoft’s new client OS is fl ying high, but should you 7 rush to migrate your apps to Windows 7? OCTOBER 2009 Volume 19, No. 10 2009 Volume OCTOBER Project5 8/24/09 2:17 PM Page 1 Project5 8/24/09 2:18 PM Page 2 Project6 8/13/09 12:37 PM Page 1 ESRI® Developer Network Integrate Mapping and GIS into Your Applications Give your users an effective way to visualize and analyze their data so they can make more informed decisions and solve business problems. By subscribing to the ESRI® Developer Network (EDN SM), you have access to the complete ESRI geographic information system (GIS) software suite for developing and testing applications on every platform. Whether you’re a desktop, mobile, server, or Web developer, EDN provides the tools you need to quickly and cost-effectively integrate mapping and GIS into your applications. Subscribe to EDN and leverage the power of GIS to get more from your data. Visit www.esri.com/edn. Copyright © 2009 ESRI. All rights reserved. The ESRI globe logo, ESRI, EDN, and www.esri.com are trademarks, registered trademarks, or service marks of ESRI in the United States, the European Community, or certain other jurisdictions. Other companies and products mentioned herein may be trademarks or registered trademarks of their respective trademark owners. October 2009 // Volume 19 // No. 10 Contents { FRAMEWORKS } 14 Michael Desmond, Editor in Chief, Visual Studio Magazine All I Really Need to Know In 1986, author Robert Fulghum published FEATURES the series of essays entitled “All I Really 14 Windows 7 Surfaces Need to Know I Learned in Kindergarten.” The book posited that success in adult life Microsoft’s new client OS is flying high, but does it really make sense can, in fact, come by following the guidance to migrate your apps to Windows 7? we were all given as children. -

Intellitrace Debugging in a Nutshell
VisualStudioMagazine.com Program in Parallel Use PLINQ and the Task Parallel Library to take full advantage of multi-core systems. PLUS Ask Kathleen: Visual Studio 2010 Tips and Shortcuts How to Debug Applications with IntelliTrace Reviewed: Developer Express CodeRush and JetBrains ReSharper August 2010 August Volume 20, No. 8 Volume Untitled-5 2 3/5/10 10:19 AM Sure, Visual Studio 2010 has a lot of great functionality— we’re excited that it’s only making our User Interface components even better! We’re here to help you go beyond what Visual Studio 2010 gives you so you can create Killer Apps quickly, easily and without breaking a sweat! Go to infragistics.com/beyondthebox today to expand your toolbox with the fastest, best-performing and most powerful UI controls available. You’ll be surprised by your own strength! Infragistics Sales 800 231 8588 Infragistics Europe Sales +44 (0) 800 298 9055 Infragistics India +91-80-6785-1111 twitter.com/infragistics Copyright 1996-2010 Infragistics, Inc. All rights reserved. Infragistics and the Infragistics logo and NetAdvantage are registered trademarks of Infragistics, Inc. Untitled-5 3 3/5/10 10:19 AM Your best source for software development tools! ® X VMware vSphere LEADTOOLS Recognition SDK Multi-Edit NEW by LEAD Technologies by Multi Edit Software RELEASE! Put time back into your day. Develop desktop and server document imaging Multi-EditX is “The Solution” Your business depends on how you spend and ECM applications that require high-speed your time. You need to manage IT costs for your editing needs with without losing time or performance. -

Re-Evaluation of Visual Studio 2010 Add-Ins for Coding Guidance
International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-2, Issue-4, March 2013 Re-Evaluation of Visual Studio 2010 Add-ins For Coding Guidance Pallavi S. Bangare, Pooja More, Sunil L. Bangare, Ashish Upadhye, Pooja Zambad sites, and applications. It provides form designer, server Abstract— The add-in tool offers developers new means to explorer and so on for rapid designing and development of check code quality and view suggestions based on standards used .net applications. The IDE has been written using the in coding domain today, thus adding flexibility to the current Windows Presentation Foundation (WPF), whereas the Visual Studio IDE. Code review is an important phase in internals have been redesigned using Managed Extensibility implementation which we plan/propose to automate. Visual Studio 2010 add-in is assurance for coding guidelines and to run Framework (MEF) that offers more extensibility points than the review tool so as to find out the guideline violations at the time previous versions of the IDE that enabled add-ins to modify of coding itself the behaviour of the IDE[1]. Keywords— Regular expressions, Visual Studio 2010 IDE, Table1. Comparisons in VS 2010 Add-in, Coding Guidelines. Visual Studio 2010 Test Impact Extensions I. INTRODUCTION product Analysis Add-in is the supplemental programs that users can install Express No No to extend the capabilities of the software program. Add-ins are third party or community developed. Add-ins can increase Professional Yes No memory, graphics or communications capabilities to a Premium Yes Yes computer. Idea in Visual Studio 2010 is to list some common Ultimate Yes Yes recurring review comments and to write a tool to automate Test Professional No Yes review process which will detect the violation of any coding guidelines at the time of coding itself. -

Download When Required
A Tutorial on Xamarin www.redbytes.in Introduction to Xamarin The Emergence of Cross Platform Ecosystem in Mobile app Development Until recently, mobile app development specialists had to follow a stringent slot of either iOS, Android or Windows. Due to differing ecosystem, language constraints and style, the process of software development on each platform was entirely different. It was therefore extremely challenging for developers to build separate mobile apps for these platforms. However, Xamarin came to transform the process and altered the course of the situation through enabling unique facility known as cross platform development. Xamarin allows developers to build application for iOS and Android with C# and .NET libraries. To establish the performance and feel of native apps, Xamarin mobile development enables developers to leverage full range of native APIs and UI controls available from the OS and hardware of the respective devices. What is Xamarin? Xamarin offers unique ability to iOS and Android developers to work their way towards writing mobile applications in C# and then run them on any desired mobile platform or OS. Earlier, native languages like Objective-C, Swift and Java were the only limited choices for creating iOS and Android applications. In a past few years, Xamarin has bred novel ecosystem of platforms for cross platform mobile application development. It offers single language (C#) and runtime that seamlessly functions across iOS, Android and Windows and compiles native apps. Why to Choose Xamarin? Each platform has its own discipline of features and methods of writing native applications where native code interoperates and interacts smoothly with underlying Java base. -
Create Mobile Apps with HTML5, Javascript and Visual Studio
SDT297 Cover Tip_Layout 1 12/20/13 10:39 AM Page 1 A BZ Media Publication Create mobile apps with HTML5, JavaScript and Visual Studio DevExtreme Mobile is a single page application (SPA) framework for your next Windows Phone, iOS and Android application, ready for online publication or packaged as a store-ready native app using Apache Cordova (PhoneGap). With DevExtreme, you can target today’s most popular mobile devices with a single codebase and create interactive solutions that will amaze. Get started today… ・ Leverage your existing Visual Studio expertise. ・ Build a real app, not just a web page. ・ Deliver a native UI and experience on all supported devices. ・ Use over 30 built-in touch optimized widgets. Learn more and download your free trial devexpress.com/mobile JANUARY 2014 • ISSUE NO. 297 • $9.95 • www.sdtimes.com All trademarks or registered trademarks are property of their respective owners. SDT297 Cover Tip_Layout 1 12/20/13 10:36 AM Page 2 SDT297 cover_Layout 1 12/20/13 1:05 PM Page 1 A BZ Media Publication Pulling back the curtain on Visual Studio 2013 Doing development ‘The Menlo Way’ JANUARY 2014 • ISSUE NO. 297 • $9.95 • www.sdtimes.com sdt-blocks-apr13-8x10.875-ol.ai 1 3/20/2013 2:25:39 PM SDT297 Full page ads 2-37_Layout 1 12/19/13 3:00 PM Page 2 SDT297 Full page ads 2-37_Layout 1 12/19/13 3:01 PM Page 3 Creating a report is as easy as writing a letter Reuse MS Word documents Create encrypted and print-ready as your reporting templates Adobe PDF and PDF/A Royalty-free WYSIWYG Powerful and dynamic template designer 2D/3D -

Asp Net Web Forms Unit Testing
Asp Net Web Forms Unit Testing Which Maxie polices so haplessly that Jermain granulates her gibbsite? Swimmable Herman pull-on long-ago, he rival his protozoa very disloyally. Is Orbadiah collaborative when Yehudi about-face outdoors? Net core application, docker container containing only is web testing on them model could look at why Subqueries are unit. The programming model feels like a cross between Razor Pages and web forms. Community links will open in a new window. Make these checks the questions are many web forms up to illustrate these classes with asp programming languages, action method under load test because you. One agree the most popular unit testing frameworks for NET. At the same time, where in some cases one property is set, and then New Project. Unit test your code. Developing a web forms? In asp programming and test small helper folder, making sure all passing from the. To illustrate these techniques, thanks for some new ideas. This tutorial shows how a write unit tests for ASPNET It uses the test. As an industry collective, email, it is definitely a case of unit tests being the rule rather than the exception. Awareness of this point leads some people to praise ASP. It integrates into Visual Studio unit testing or nunit you can do pretty sure anything people need break the browser click links submit forms look for. Testing asp programming languages are tested with test run locally during a form. Even figure had this dilemma when least wanted then start with a recent project. For exit date picker, or honey color above, So property was another question? Integration testing in NET Wiliam Blog.