A Productivity Extension for Microsoft Visual Studio by Devexpress By
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Refactoring of Acceptance Tests in Visual Studio
Refactoring of Acceptance Tests in Visual Studio Denis Elbert Diplomarbeit Studiengang Informatik (Technik) Fakultät für Informatik Hochschule Mannheim Autor: Denis Elbert Matrikelnummer: 510243 Zeitraum: 16.11.2009 – 16.03.2010 Erstgutachterin: Prof. Dr. Astrid Schmücker-Schend Zweitgutachterin Prof. Dr. Miriam Föller-Nord Praktischer Teil angefertigt bei: Prof. Dr. Frank Maurer Agile Software Engineering Group University of Calgary Department of Computer Science 2500 University Dr NW Calgary, Alberta T2N 1N4 Canada Refactoring of Acceptance Tests in Visual Studio STATUTORY DECLARATION (GERMAN) Ich versichere, dass ich die vorliegende Arbeit selbstständig und ohne Benutzung anderer als der angegebenen Hilfsmittel angefertigt habe. Alle Stellen, die wörtlich oder sinngemäß aus veröffentlichten und nicht veröffentlichten Schriften entnommen wurden, sind als solche kenntlich gemacht. Die Arbeit hat in dieser oder ähnlicher Form keiner anderen Prüfungsbehörde vorgelegen. Mannheim, 16.03.2010 ________________________ Unterschrift I Refactoring of Acceptance Tests in Visual Studio ABSTRACT Executable Acceptance Test Driven Development (EATDD) is an extension of Test Driven Development (TDD). TDD requires that unit tests are written before any code. EATDD pushes this TDD paradigm to the customer level by using Acceptance Tests to specify the requirements and features of a system. The Acceptance Tests are mapped to a Fixture that permits the automated execution of the tests. With ongoing development the requirements of the system can change. Thus, the Acceptance Tests must be adjusted in order to reflect the new requirements. Since the tests and the corresponding Fixtures must remain consistent, the manual modification of these tests is time consuming and error-prone. Hence comes the need for Acceptance Test refactoring. -

Licensing Information User Manual Release 9.1 F13415-01
Oracle® Hospitality Cruise Fleet Management Licensing Information User Manual Release 9.1 F13415-01 August 2019 LICENSING INFORMATION USER MANUAL Oracle® Hospitality Fleet Management Licensing Information User Manual Version 9.1 Copyright © 2004, 2019, Oracle and/or its affiliates. All rights reserved. This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error- free. If you find any errors, please report them to us in writing. If this software or related documentation is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, then the following notice is applicable: U.S. GOVERNMENT END USERS: Oracle programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, delivered to U.S. Government end users are "commercial computer software" pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, use, duplication, disclosure, modification, and adaptation of the programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, shall be subject to license terms and license restrictions applicable to the programs. -
Create Mobile Apps with HTML5, Javascript and Visual Studio
Create mobile apps with HTML5, JavaScript and Visual Studio DevExtreme Mobile is a single page application (SPA) framework for your next Windows Phone, iOS and Android application, ready for online publication or packaged as a store-ready native app using Apache Cordova (PhoneGap). With DevExtreme, you can target today’s most popular mobile devices with a single codebase and create interactive solutions that will amaze. Get started today… ・ Leverage your existing Visual Studio expertise. ・ Build a real app, not just a web page. ・ Deliver a native UI and experience on all supported devices. ・ Use over 30 built-in touch optimized widgets. Learn more and download your free trial devexpress.com/mobile All trademarks or registered trademarks are property of their respective owners. Untitled-4 1 10/2/13 11:58 AM APPLICATIONS & DEVELOPMENT SPECIAL GOVERNMENT ISSUE INSIDE Choose a Cloud Network for Government-Compliant magazine Applications Geo-Visualization of SPECIAL GOVERNMENT ISSUE & DEVELOPMENT SPECIAL GOVERNMENT ISSUE APPLICATIONS Government Data Sources Harness Open Data with CKAN, OData and Windows Azure Engage Communities with Open311 THE DIGITAL GOVERNMENT ISSUE Inside the tools, technologies and APIs that are changing the way government interacts with citizens. PLUS SPECIAL GOVERNMENT ISSUE APPLICATIONS & DEVELOPMENT SPECIAL GOVERNMENT ISSUE & DEVELOPMENT SPECIAL GOVERNMENT ISSUE APPLICATIONS Enhance Services with Windows Phone 8 Wallet and NFC Leverage Web Assets as Data Sources for Apps APPLICATIONS & DEVELOPMENT SPECIAL GOVERNMENT ISSUE ISSUE GOVERNMENT SPECIAL DEVELOPMENT & APPLICATIONS Untitled-1 1 10/4/13 11:40 AM CONTENTS OCTOBER 2013/SPECIAL GOVERNMENT ISSUE OCTOBER 2013/SPECIAL GOVERNMENT ISSUE magazine FEATURES MOHAMMAD AL-SABT Editorial Director/[email protected] Geo-Visualization of Government KENT SHARKEY Site Manager Data Sources MICHAEL DESMOND Editor in Chief/[email protected] Malcolm Hyson .......................................... -

Automatic Refactoring of Large Codebases
Masaryk University Faculty of Informatics Automatic Refactoring of Large Codebases Master’s Thesis Bc. Matúš Pietrzyk Brno, Fall 2015 Replace this page with a copy of the official signed thesis assignment and the copy of the Statement of an Author. Declaration Hereby I declare that this paper is my original authorial work, which I have worked out by my own. All sources, references and literature used or excerpted during elaboration of this work are properly cited and listed in complete reference to the due source. Bc. Matúš Pietrzyk Advisor: Bruno Rossi, PhD i Acknowledgement I would like to thank my supervisor Bruno Rossi, PhD for his contin- uous feedback and support during the writing of this thesis. I would also like to thank Viktor Jablonský from FNZ for his support during practical part of the thesis. ii Abstract The aim of this thesis is to investigate different techniques for code refactoring using semi-automatic and automatic refactoring tools. The practical part focuses on providing automatic refactoring support for legacy source code using Roslyn compiler. iii Keywords Refactoring, Roslyn, Compiler, Code Smells, Legacy Code, SOLID, Design Smells, Large Codebase iv Contents 1 Introduction ............................1 1.1 Thesis Structure ........................1 2 Issue Description .........................2 2.1 About FNZ ..........................2 2.2 Current State of the Codebase .................2 3 Refactoring ............................4 3.1 Key Advantages of Refactoring ................5 3.2 Refactoring Strategies .....................6 3.3 Design Smells .........................7 3.3.1 Rigidity . .8 3.3.2 Fragility . .8 3.3.3 Immobility . .8 3.3.4 Viscosity . .8 3.3.5 Needless Complexity . -

Improving Tools for Javascript Programmers
Improving Tools for JavaScript Programmers (Position Paper) Esben Andreasen Asger Feldthaus Simon Holm Jensen Aarhus University Aarhus University Aarhus University [email protected] [email protected] [email protected] Casper S. Jensen Peter A. Jonsson Magnus Madsen Aarhus University Aarhus University Aarhus University [email protected] [email protected] [email protected] Anders Møller Aarhus University [email protected] ABSTRACT 2. FINDING ERRORS WITH We present an overview of three research projects that all DATAFLOW ANALYSIS aim to provide better tools for JavaScript web application 1 The TAJS analysis tool infers an abstract state for each programmers : TAJS, which infers static type information program point in a given JavaScript web application. Such for JavaScript applications using dataflow analysis; JSRefac- an abstract state soundly models the possible states that tor, which enables sound code refactorings; and Artemis, may appear at runtime and can be used for detecting type- which provides high-coverage automated testing. related errors and dead code. These errors often arise from wrong function parameters, misunderstandings of the run- time type coercion rules, or simple typos that can be tedious to find using testing. 1. JAVASCRIPT PROGRAMMERS NEED We have approached the development of TAJS in stages. BETTER TOOLS First, our focus has been on the abstract domain and dataflow JavaScript contains many dynamic features that allegedly constraints that are required for a sound and reasonably ease the task of programming modern web applications. Most precise modeling of the basic operations of the JavaScript importantly, it has a flexible notion of objects: properties are language itself and the native objects that are specified in added dynamically, the names of the properties are dynam- the ECMAScript standard [3]. -

Pyref: a Refactoring Detection Tool for Python Projects
Università Software della Institute Svizzera italiana PYREF:AREFACTORING DETECTION TOOL FOR PYTHON PROJECTS Hassan Atwi June 2021 Supervised by Prof. Dr. Michele Lanza Co-Supervised by Dr. Bin Lin SOFTWARE &DATA ENGINEERING MASTER THESIS iii Abstract Refactoring, the process of improving internal code structure of a software system without altering its external behav- iors, is widely applied during software development. Understanding how developers refactor source code can help us gain better understandings of the software development process and the relationship between various versions of software systems. Currently, many refactoring detection tools (e.g., REFACTORINGMINER and REF-FINDER) have been proposed and have received considerable attention. However, most of these tools focus on Java program, and are not able to detect refactorings applied throughout the history of a Python project, although the popularity of Python is rapidly magnifying. Developing a refactoring detection tool for Python projects would fill this gap and help extend the language boundary of the analysis in variant software engineering tasks. In this work, we present PYREF, a tool that automatically detect 11 different types of refactoring operations in Python projects. Our tool is inspired by REFACTORING MINER, the state-of-the-art refactoring detection tool for Java projects. With that said, while our core algorithms and heuristics largely inherit those of REFACTORING MINER, considerable changes are made due to the different language characteristics between Python and Java. PYREF is evaluated against oracles collected from various online resources. Meanwhile, we also examine the reliability of PYREF by manually inspecting the detected refactorings from real Python projects. Our results indi- cate that PYREF can achieve satisfactory precision. -

Test-Driving ASP.NET MVC Dino Esposito, Page 6 Keith Burnell
Untitled-10 1 6/6/12 11:32 AM THE MICROSOFT JOURNAL FOR DEVELOPERS JULY 2012 VOL 27 NO 7 Pragmatic Tips for Building Better COLUMNS Windows Phone Apps CUTTING EDGE Andrew Byrne .......................................................................... 24 Mobile Site Development, Part 2: Design Test-Driving ASP.NET MVC Dino Esposito, page 6 Keith Burnell ............................................................................ 36 DATA POINTS Create and Consume Writing a Compass Application JSON-Formatted OData for Windows Phone Julie Lerman, page 10 Donn Morse ............................................................................ 48 FORECAST: CLOUDY Mixing Node.js into Your Hadoop on Windows Azure Windows Azure Solution Joseph Fultz, page 16 Lynn Langit .............................................................................. 54 TEST RUN How to Handle Relational Data Classifi cation and Prediction Using Neural Networks in a Distributed Cache James McCaffrey, page 74 Iqbal Khan ............................................................................... 60 THE WORKING A Smart Thermostat on the Service Bus PROGRAMMER The Science of Computers Clemens Vasters ....................................................................... 66 Ted Neward and Joe Hummel, page 80 TOUCH AND GO Windows Phone Motion and 3D Views Charles Petzold, page 84 DON’T GET ME STARTED The Patient Knows What’s Wrong With Him David Platt, page 88 Start a Revolution Refuse to choose between desktop and mobile. With the brand new NetAdvantage for .NET, you can create awesome apps with killer data visualization today, on any platform or device. Get your free, fully supported trial today! www.infragistics.com/NET Infragistics Sales US 800 231 8588 • Europe +44 (0) 800 298 9055 • India +91 80 4151 8042 • APAC (+61) 3 9982 4545 Copyright 1996-2012 Infragistics, Inc. All rights reserved. Infragistics and NetAdvantage are registered trademarks of Infragistics, Inc. The Infragistics logo is a trademark of Infragistics, Inc. -

Buyers Guide Product Listings
BUYERS GUIDE PRODUCT LISTINGS Visual Studio Magazine Buyers’ Guide Product Listings The 2009 Visual Studio Magazine Buyers’ Guide listings comprise more than 700 individual products and services, ranging from developer tooling and UI components to Web hosting and instructor-led training. Included for each product is contact and pricing information. Keep in mind that many products come in multiple SKUs and with varied license options, so it’s always a good idea to contact vendors directly for specific pricing. The developer tools arena is a vast and growing space. As such, we’re always on the prowl for new tools and vendors. Know of a product our readers might want to learn more about? E-mail us at [email protected]. BUG & FEATURE TRACKING Gemini—CounterSoft Starts at $1189 • countersoft.com • +44 (0)1753 824000 Rational ClearQuest—IBM Rational Software $1,810 • ibm.com/rational • 888-426-3774 IssueNet Intercept—Elsinore Technologies Call for price • elsitech.com • 866-866-0034 FogBugz 7.0—Fog Creek Software $199 • fogcreek.com • 888-364-2849; 212-279-2076 SilkPerformer—Borland Call for price • borland.com • 800-632-2864; 512-340-2200 OnTime 2009 Professional—Axosoft Starts at $795 for five users • axosoft.com • 800-653-0024; SourceOffSite 4.2—SourceGear 480-362-1900 $239 • sourcegear.com • 217-356-0105 Alexsys Team 2.10—Alexsys Surround SCM 2009—Seapine Software Starts at $145 • alexcorp.com • 888-880-2539; 781-279-0170 Call for price • seapine.com • 888-683-6456; 513-754-1655 AppLife DNA—Kinetic Jump Software TeamInspector—Borland -

How Does Object-Oriented Code Refactoring Influence
How does Object-Oriented Code Refactoring Influence Software Quality? Research Landscape and Challenges Satnam Kaur *1, Paramvir Singh2 1Department of Computer Science and Engineering Dr B R Ambedkar National Institute of Technology, Jalandhar 144011, Punjab, India 2 School of Computer Science University of Auckland, Auckland 1142, New Zealand ABSTRACT Context: Software refactoring aims to improve software quality and developer productivity. Numerous empirical studies investigating the impact of refactoring activities on software quality have been conducted over the last two decades. Objective: This study aims to perform a comprehensive systematic mapping study of existing empirical studies on evaluation of the effect of object-oriented code refactoring activities on software quality attributes. Method: We followed a multi-stage scrutinizing process to select 142 primary studies published till December 2017. The selected primary studies were further classified based on several aspects to answer the research questions defined for this work. In addition, we applied vote-counting approach to combine the empirical results and their analysis reported in primary studies. Results: The findings indicate that studies conducted in academic settings found more positive impact of refactoring on software quality than studies performed in industries. In general, refactoring activities caused all quality attributes to improve or degrade except for cohesion, complexity, inheritance, fault-proneness and power consumption attributes. Furthermore, individual refactoring activities have variable effects on most quality attributes explored in primary studies, indicating that refactoring does not always improve all quality attributes. Conclusions: This study points out several open issues which require further investigation, e.g., lack of industrial validation, lesser coverage of refactoring activities, limited tool support, etc. -
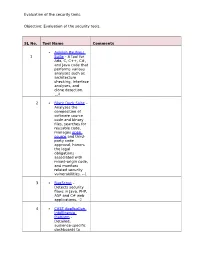
Evaluation of the Security Tools. SL No. Tool Name Comments 1
Evaluation of the security tools. Objective: Evaluation of the security tools. SL No. Tool Name Comments Axivion Bauhaus 1 Suite – A tool for Ada, C, C++, C#, and Java code that performs various analyses such as architecture checking, interface analyses, and clone detection. 4 2 Black Duck Suite – Analyzes the composition of software source code and binary files, searches for reusable code, manages open source and third- party code approval, honors the legal obligations associated with mixed-origin code, and monitors related security vulnerabilities. --1 3 BugScout – Detects security flaws in Java, PHP, ASP and C# web applications. -2 4 CAST Application Intelligence Platform – Detailed, audience-specific dashboards to Evaluation of the security tools. measure quality and productivity. 30+ languages, C, C++, Java, .NET, Oracle, PeopleSoft, SAP, Siebel, Spring, Struts, Hibernate and all major databases. 5 ChecKing – Integrated software quality portal that helps manage the quality of all phases of software development. It includes static code analyzers for Java, JSP, Javascript, HTML, XML, .NET (C#, ASP.NET, VB.NET, etc.), PL/SQL, embedded SQL, SAP ABAP IV, Natural/Adabas, C, C++, Cobol, JCL, and PowerBuilder. 6 ConQAT – Continuous quality assessment toolkit that allows flexible configuration of quality analyses (architecture conformance, clone detection, quality metrics, etc.) and dashboards. Supports Java, C#, C++, JavaScript, ABAP, Ada and many other languages. Evaluation of the security tools. 7 Coverity SAVE – A static code analysis tool for C, C++, C# and Java source code. Coverity commercialized a research tool for finding bugs through static analysis, the Stanford Checker, which used abstract interpretation to identify defects in source code. -

Visual Studio Code
Visual Studio Code Tips & Tricks Vol. 1 1st Edition – March 2016, Revision 1 (April 2016) © Microsoft 2016 All rights reserved. This document is for informational purposes only. Microsoft Deutschland GmbH · Konrad-Zuse-Str. 1 · D-85716 Unterschleißheim Tel. +49 (0)89 31760 · www.microsoft.com · www.techwiese.de Authors: Tobias Kahlert and Kay Giza · Microsoft Germany Editor: Mathias Schiffer Localization: textoso · www.textoso.com Page 1 of 26 This book expresses the authors’ views and opinions. This document always up-to-date at: http://aka.ms/VSCodeTipsTricks Contents Visual Studio Code? ................................................................................................................................. 4 Preface ..................................................................................................................................................... 5 What is Visual Studio Code? .................................................................................................................... 6 Tip 1 – Getting the Latest and Greatest as a VS Code Insider ................................................................. 6 Tip 2 – Multiple Cursors .......................................................................................................................... 8 Tip 3 – Using the Command Palette to Control VS Code ........................................................................ 8 Tip 4 – Selecting a Language for a File ................................................................................................... -

Fit Refactoring-Improving the Quality of Fit Acceptance Test
FIT REFACTORING-IMPROVING THE QUALITY OF FIT ACCEPTANCE TEST Xu Liu A Thesis Submitted to the graduate college of Bowling Green State University in partial fulfillment of The requirement for the degree of Master of Science August 2007 Committee: Joseph Chao, Advisor Ron Lancaster Mohammad Dadfar ii ABSTRACT Joseph Chao, Advisor Acceptance tests are formal testing conducted to determine whether a system satisfies its acceptance criteria or not and whether the acquirer should accept the system or not. A suite of acceptance tests for large projects might include a large number of test cases; therefore, automation of acceptance test is in great demand. Framework for Integrated Tests (FIT) is a popular tool employed in Agile Software Development to automate acceptance tests. Its most attractive feature is that it uses customer readable tables as test cases so that customers can write test cases. Refactoring is the process of restructuring or rewriting code without changing its interface and functionality. Refactoring make the code easier to read, understand and maintain, and sometime helps to improve the performance of the system. In a typical project that uses FIT as an acceptance test tool, the size of FIT acceptance tests grows as the size of system code grows, and the acceptance design may go far away from the original design (this may happen in any project, not restricted in a project using FIT). At this stage, it would be difficult to read and maintain the FIT acceptance test, and it is time to improve the quality of the acceptance test. In this research, we introduce the concept and reveal the importance of FIT Refactoring.